








生成式对抗网络(GAN, Generative Adversarial Networks)是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。模型通过框架中(至少)两个模块:生成模型(Generative Model)和判别模型(Discriminative Model)的互相博弈学习产生相当好的输出。在本章的内容中,将详细讲解使用TensorFlow实现生成式对抗网络操作的知识。
6.1 生成对抗网络介绍
GAN是Ian Goodfellow提出的使用对抗过程来获得生成模型的新框架,生成对抗网络主要由两个部分组成,一个是生成模型(Generative Model),另一个是判别模型(Discriminative Model)。
6.1.1 生成模型和判别模型
生成模型(generative model)在机器学习的历史上一直占有举足轻重的地位,当我们拥有大量的数据,例如图像、语音、文本等,如果生成模型可以帮助我们模拟这些高维数据的分布,那么对很多应用将大有裨益。生成模型G的作用是尽量去拟合(cover)真实数据分布,生成以假乱真的图片。它的输入参数是一个随机噪声z,G(z)代表其生成的一个样本(fake data)。
判别模型D的作用是判断一张图片是否是“真实的”,即能判断出一张图片是真实数据(training data)还是生成模型G生成的样本(fake data)。它的输入参数是x,x代表一张图片,D(x)代表x是真实图片的概率。
针对数据量缺乏的场景,生成模型则可以帮助生成数据,提高数据数量,从而利用半监督学习提升学习效率。语言模型(language model)是生成模型被广泛使用的例子之一,通过合理建模,语言模型不仅可以帮助生成语言通顺的句子,还在机器翻译、聊天对话等研究领域有着广泛的辅助应用。
如果有数据集S={x1,…xn},如何建立一个关于这个类型数据的生成模型呢?最简单的方法就是:假设这些数据的分布P{X}服从g(x;θ),在观测数据上通过最大化似然函数得到θ的值,即最大似然法:
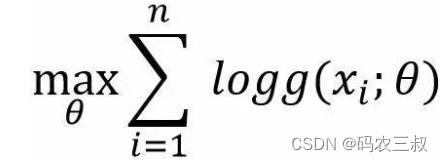
接下来我们举一个通俗易懂的例子,这个例子来源于知乎大神“微软亚洲研究院”:
一对情侣,一个是摄影师(男生),一个是摄影师的女朋友(女生)。男生一直试图拍出像众多优秀摄影师一样的好照片,而女生一直以挑剔的眼光找出“自己男朋友”拍的照片和“别人家的男朋友”拍的照片的区别。于是两者的交流过程类似于:男生拍一些照片 ->女生分辨男生拍的照片和自己喜欢的照片的区别->男生根据反馈改进自己的技术并拍新的照片->女生根据新的照片继续提出改进意见->……,这个过程直到均衡出现:即女生不能再分辨出“自己男朋友”拍的照片和“别人家的男朋友”拍的照片的区别,认可了男朋友的照片。
接下来继续讲生成模型,以图像生成模型进行举例:假设我们有一个图片生成模型(generator),它的目标是生成一张真实的图片。与此同时我们有一个图像判别模型(discriminator),它的目标是能够正确判别一张图片是生成出来的还是真实存在的。那么如果我们把刚才的场景映射成图片生成模型和判别模型之间的博弈,就变成了如下模式:生成模型生成一些图片->判别模型学习区分生成的图片和真实图片->生成模型根据判别模型改进自己,生成新的图片->……。在这个场景中,直至生成模型与判别模型无法提高自己,即判别模型无法判断一张图片是生成出来的还是真实的而结束,此时生成模型就会成为一个完美的模型。
上述这种相互学习的过程听非常有趣,在这种博弈式的训练过程中,如果采用神经网络作为模型类型,则被称为生成式对抗网络(GAN)。
6.1.2 对抗生成网络基本流程
使用对抗生成网络的的基本过程如下:
(1)对于从训练数据中取样出的真实图片x,判别模型D希望D(x)的输出值接近1,即判定训练数据为真实图片。
(2)给定一个随机噪声z,判别模型D希望D(G(z))的输出值接近0,即认定生成模型G生成的图片是假的;而生成模型G希望D(G(z))的输出值接近1,即G希望能够欺骗D,让D将生成模型G生成的样本误判为真实图片。这样G和D就构成了博弈的状态。
(3)在博弈的过程中,生成模型G和判别模型D都不断的提升自己的能力,最后达到一个平衡的状态。G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。这样我们的目的就达成了:我们得到了一个生成式的模型G,它可以用来生成真实图片。
下面举一个例子,例如使用生成对抗网络识别图像的流程如下:
- 判别模型:给定一张图,判断这张图里的动物是猫还是狗;
- 生成模型:给一系列猫的图片,生成一张新的猫咪(不在数据集里)。
假设我们有两个网络:G(Generator)和D(Discriminator),正如它的名字所暗示的那样,它们的功能分别是:
- G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。
- D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。最后博弈的结果是什么呢?在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。这样我们的目的就达成了:得到了一个生成式的模型G,它可以用来生成图片。

















 1052
1052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











