







初始模型预测控制
设篮球斜抛的角度为θ,斜抛初始速度为v,初始高度为y0
则篮球的斜抛运动(不考虑空气阻力)
由竖直方向的上抛运动和水平方向的匀速运动构成
这里的上抛运动式和水平方向的匀速运动式就是 模型(Model)
篮球能否按照预期投进球框就是 预测(Prediction)
通过调整初始点投球时的角度和速度就是 控制(Control)
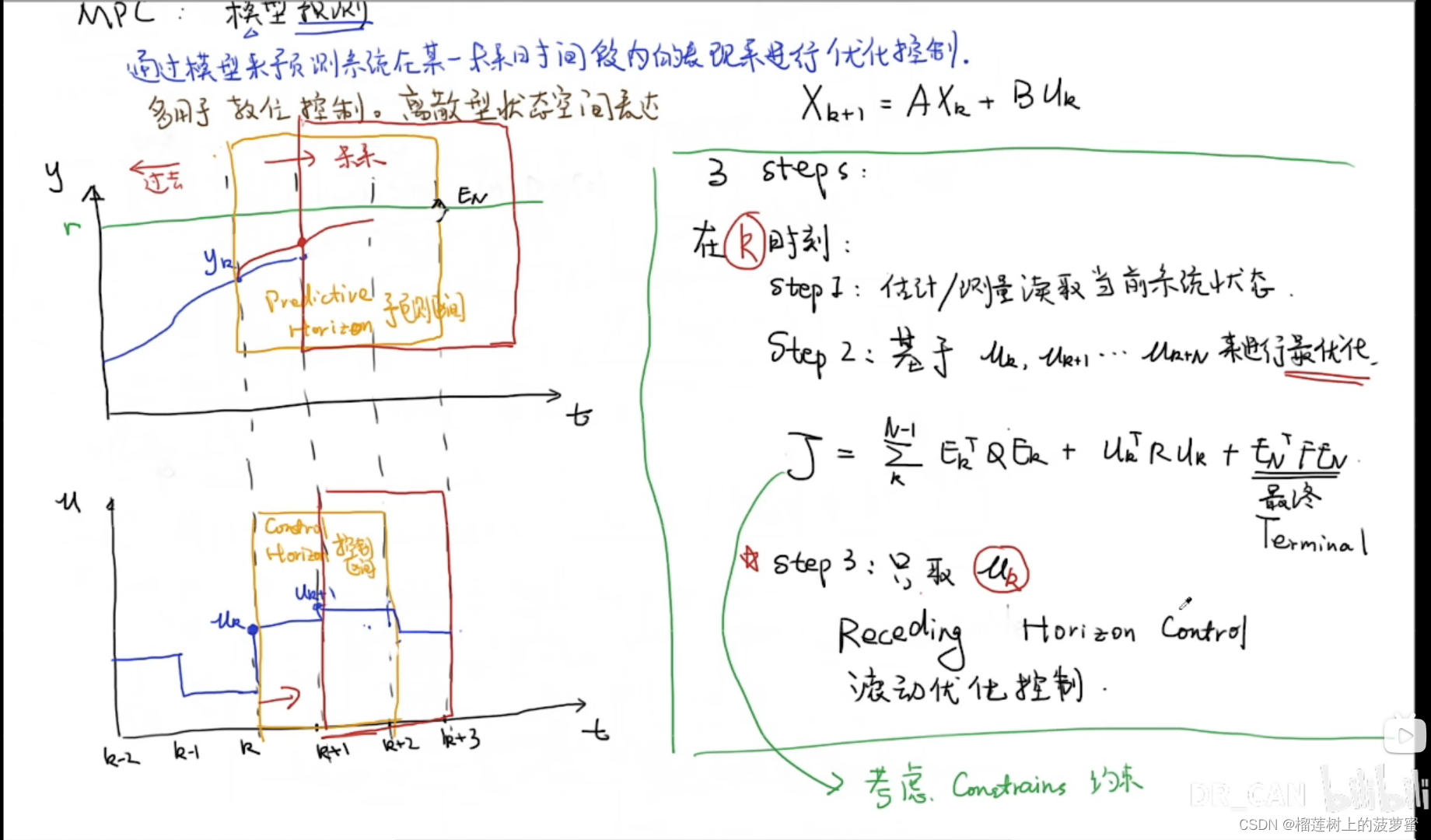
MPC的核心思想是在每个时间步上通过求解优化问题来确定最佳的控制策略。这个优化问题通常是在有限的预测时间范围内最小化一个性能指标,如系统的能耗、跟踪误差或任何其他用户定义的指标。优化问题的目标是找到最佳的控制输入序列,以最小化性能指标,并满足系统约束条件,如输入限制、状态限制、控制器响应时间等。
建模——>预测——>控制
MPC的求解过程包括以下几个步骤:
- 系统建模:建立系统的动态模型,用于预测系统的未来行为。模型可以是线性的或非线性的,取决于实际应用和问题的复杂性。
- 预测:在当前时间步上,利用系统模型和当前状态进行预测,得到未来状态的预测值。
- 优化问题建立:根据预测的未来状态,构建一个优化问题,定义性能指标和约束条件。
- 优化求解:利用数值优化方法,求解建立的优化问题,得到最佳的控制输入序列。
- 执行控制:将优化问题的解析结果应用到系统上,执行控制输入序列的第一个输入值,并将系统状态更新为下一个时间步的测量值。
- 循环迭代:重复执行上述步骤,不断更新控制策略,以实现对系统状态的优化控制。
step1 观测器设计——>估计/测量系统的状态值
step2 最优化——建立二次规划模型:

在K时刻预测,预测出k+1时刻的状态——X(k+1|k)
在K时刻预测,在k+1时刻输入——u(k+1)
关键点:(转换系统模型)
构建原有的代价函数——>通过中间矩阵——>变成只包含初始状态和输入向量的函数
b站up的代码参考学习,更推荐视频讲解
%% 清屏
clear ;
close all;
clc;
%% 加载 optim package,若使用matlab,则注释掉此行
pkg load optim;
%%%%%%%%%%%%%%%%%%%%%%%%%%
%% 第一步,定义状态空间矩阵
%% 定义状态矩阵 A, n x n 矩阵
A = [1 0.1; -1 2];
n= size (A,1);
%% 定义输入矩阵 B, n x p 矩阵
B = [ 0.2 1; 0.5 2];
p = size(B,2);
%% 定义Q矩阵,n x n 矩阵
Q=[100 0;0 1];
%% 定义F矩阵,n x n 矩阵
F=[100 0;0 1];
%% 定义R矩阵,p x p 矩阵
R=[1 0 ;0 .1];
%% 定义step数量k
k_steps=100;
%% 定义矩阵 X_K, n x k 矩 阵
X_K = zeros(n,k_steps);
%% 初始状态变量值, n x 1 向量
X_K(:,1) =[20;-20];
%% 定义输入矩阵 U_K, p x k 矩阵
U_K=zeros(p,k_steps);
%% 定义预测区间K
N=5;
%% Call MPC_Matrices 函数 求得 E,H矩阵
[E,H]=MPC_Matrices(A,B,Q,R,F,N);
%% 计算每一步的状态变量的值
for k = 1 : k_steps
%% 求得U_K(:,k)
U_K(:,k) = Prediction(X_K(:,k),E,H,N,p);
%% 计算第k+1步时状态变量的值
X_K(:,k+1)=(A*X_K(:,k)+B*U_K(:,k));
end
%% 绘制状态变量和输入的变化
subplot (2, 1, 1);
hold;
for i =1 :size (X_K,1)
plot (X_K(i,:));
end
legend("x1","x2")
hold off;
subplot (2, 1, 2);
hold;
for i =1 : size (U_K,1)
plot (U_K(i,:));
end
legend("u1","u2")
function [E , H]=MPC_Matrices(A,B,Q,R,F,N)
n=size(A,1); % A 是 n x n 矩阵, 得到 n
p=size(B,2); % B 是 n x p 矩阵, 得到 p
%%%%%%%%%%%%
M=[eye(n);zeros(N*n,n)]; % 初始化 M 矩阵. M 矩阵是 (N+1)n x n的,
% 它上面是 n x n 个 "I", 这一步先把下半部
% 分写成 0
C=zeros((N+1)*n,N*p); % 初始化 C 矩阵, 这一步令它有 (N+1)n x NP 个 0
% 定义M 和 C
tmp=eye(n); %定义一个n x n 的 I 矩阵
% 更新M和C
for i=1:N % 循环,i 从 1到 N
rows =i*n+(1:n); %定义当前行数,从i x n开始,共n行
C(rows,:)=[tmp*B,C(rows-n, 1:end-p)]; %将c矩阵填满
tmp= A*tmp; %每一次将tmp左乘一次A
M(rows,:)=tmp; %将M矩阵写满
end
% 定义Q_bar和R_bar
Q_bar = kron(eye(N),Q);
Q_bar = blkdiag(Q_bar,F);
R_bar = kron(eye(N),R);
% 计算G, E, H
G=M'*Q_bar*M; % G: n x n
E=C'*Q_bar*M; % E: NP x n
H=C'*Q_bar*C+R_bar; % NP x NP
function u_k= Prediction(x_k,E,H,N,p)
U_k = zeros(N*p,1); % NP x 1
U_k = quadprog(H,E*x_k);
u_k = U_k(1:p,1); % 取第一个结果
滚动优化控制(Rolling Horizon Optimization Control)是一种基于模型预测控制(MPC)的控制策略,用于实现动态系统的路径跟踪和优化。与传统的MPC方法不同,滚动优化控制将优化问题分为不同的时间步,并在每个时间步上重新优化控制策略。
滚动优化控制的基本思想是,在每个时间步上,根据当前的状态和环境信息,利用系统的动态模型进行预测,并通过优化算法求解一个有限时间范围内的优化问题。然后,只应用优化问题的前几个时间步的解作为实际控制输入,执行控制,并在下一个时间步上重新优化控制策略。
滚动优化控制的优点在于:
- 实时性更好:由于只在每个时间步上重新优化控制策略,滚动优化控制具有更好的实时性。不需要一次性求解整个问题,而是根据当前情况进行部分求解,从而降低计算复杂度。
- 鲁棒性更强:滚动优化控制只关注近期未来的状态和行为,而不需要预测较远的未来。这使得控制器对于环境的变化和模型的不完全准确性更具有鲁棒性。
- 适应性更好:滚动优化控制可以在每个时间步上进行调整和修正,以适应不断变化的系统和环境条件。
滚动优化控制的步骤可以简述如下:
- 初始化:根据当前的系统状态,初始化优化问题的约束和起始点。
- 预测:利用系统的动态模型,根据当前的状态和控制输入进行预测,得到未来一段时间的状态预测。
- 优化问题建立:根据预测的状态和目标要求,构建一个优化问题,定义性能指标和约束条件。
- 优化求解:利用数值优化方法,求解建立的优化问题,得到最优的控制输入序列。
- 执行控制:将优化问题的解析结果应用到系统上,执行控制输入序列的前几个输入值,并将系统状态更新为下一个时间步的测量值。
- 更新控制:在下一个时间步上,重复执行上述步骤,不断更新控制策略,以实现对系统状态的优化控制。

















 7548
7548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









