







✅ 博主简介:擅长数据搜集与处理、建模仿真、程序设计、仿真代码、论文写作与指导,毕业论文、期刊论文经验交流。
✅论文数据下载:工业工程毕业论文【数据集】
✅题目与创新点推荐:工业工业毕业论文【题目推荐】
(1) 基于价值流理论绘制现状价值流图并分析问题
在A公司电流互感器LB7-220型生产线上,通过全面收集生产线当前的运行数据,包括工序工时、物料流转时间、库存水平等,完成现状价值流图的绘制。现状价值流图直观展示了从客户需求到成品交付的全过程,揭示了生产线的主要问题。
通过对价值流图的分析,发现生产线存在以下问题:
-
流程不均衡:部分工序因资源不足或设备效率较低而成为瓶颈,导致生产周期延长。
-
物流距离过长:由于设备布局不合理,物流运输耗时较多,降低了整体生产效率。
-
库存积压:工序间未实现流动生产,导致在制品库存过高,增加了管理和资金占用成本。
-
非增值活动过多:在流程中发现了大量的等待、搬运和不必要的检查活动,这些活动无法为客户带来直接价值。
以上问题的存在直接影响了A公司对市场需求的响应速度和整体运营成本。
(2) 制定优化方案并实施生产线改善
针对上述问题,结合价值流理论和传统工业工程方法,制定了系统性的优化方案。
首先,采用SLP(系统布置规划)方法重新设计生产车间布局。在综合分析物流关系和非物流关系的基础上,将相关工序紧密安排在一起,显著缩短了物流距离。利用综合相关关系图对各工序间的物流频率和强度进行加权计算,并根据重新设计的面积规划图调整设备摆放。
其次,通过流程程序分析(PFA)识别出生产过程中存在的浪费,并应用ECRSI原则(消除、合并、重排、简化、改善)对工序进行改造。例如:
-
消除多余检查:通过引入自动化检测设备,减少人工检查环节的冗余。
-
简化搬运过程:使用AGV(自动导引车)取代人工搬运,实现精准物流分配。
-
改善瓶颈工序:在关键瓶颈工序增加设备数量或采用先进加工技术,提升工序效率。
再次,利用遗传算法对优化后的工序进行生产线平衡设计。通过构建数学模型,将生产平衡率和工位数作为目标函数,设计遗传算法程序对工序顺序进行优化。经过多次迭代,获得了最佳的工序分配方案,有效提高了生产平衡率。
(3) 优化效果验证与实施成果评估
为验证优化方案的实际效果,借助Flexsim仿真软件建立了优化前后生产线的数字模型,并对比分析以下关键指标:
-
生产效率:优化后生产周期缩短了30%以上,产量显著提升。
-
物流距离:由于布局调整,物流运输距离减少了40%,节省了大量时间和成本。
-
库存水平:通过减少工序间等待和在制品积压,优化后的平均库存水平下降了50%。
-
客户响应速度:交货时间显著缩短,客户满意度显著提高。
此外,通过仿真还发现,优化后的生产线在设备故障情况下表现出更高的鲁棒性,能够迅速调整资源分配,保证生产连续性。
优化实施后,A公司还完善了生产管理制度,包括:
-
定期监控关键绩效指标(KPI),如设备利用率、物流效率和生产平衡率,确保优化效果的持续性。
-
建立员工培训体系,通过定期技能培训提升员工素质,激发员工的工作积极性。
-
推广精益文化,将减少浪费、持续改进的理念融入日常管理,提升团队协作效率。
这些措施不仅提升了生产效率,还塑造了良好的企业文化氛围,为公司未来发展奠定了坚实基础。
import numpy as np
import random
def initialize_population(size, num_tasks):
"""初始化种群,每个个体表示一种工序排列"""
population = []
for _ in range(size):
individual = list(np.random.permutation(num_tasks))
population.append(individual)
return population
def fitness(individual, task_times, workstations, cycle_time):
"""计算适应度函数,基于生产平衡率和工位利用率"""
total_time = 0
workstation_time = [0] * workstations
for task in individual:
assigned = False
for i in range(workstations):
if workstation_time[i] + task_times[task] <= cycle_time:
workstation_time[i] += task_times[task]
assigned = True
break
if not assigned:
return float('inf') # 超出工位限制,罚值很大
balance_rate = max(workstation_time) / sum(task_times)
return 1 / balance_rate # 平衡率的倒数
def crossover(parent1, parent2):
"""单点交叉操作"""
point = random.randint(1, len(parent1) - 1)
child1 = parent1[:point] + [gene for gene in parent2 if gene not in parent1[:point]]
child2 = parent2[:point] + [gene for gene in parent1 if gene not in parent2[:point]]
return child1, child2
def mutate(individual, mutation_rate):
"""突变操作,交换两个随机任务"""
if random.random() < mutation_rate:
idx1, idx2 = random.sample(range(len(individual)), 2)
individual[idx1], individual[idx2] = individual[idx2], individual[idx1]
def genetic_algorithm(task_times, num_tasks, workstations, cycle_time, pop_size=50, generations=200, mutation_rate=0.1):
"""遗传算法主流程"""
population = initialize_population(pop_size, num_tasks)
best_solution = None
best_fitness = float('inf')
for generation in range(generations):
population.sort(key=lambda ind: fitness(ind, task_times, workstations, cycle_time))
if fitness(population[0], task_times, workstations, cycle_time) < best_fitness:
best_solution = population[0]
best_fitness = fitness(population[0], task_times, workstations, cycle_time)
new_population = population[:pop_size // 2]
while len(new_population) < pop_size:
parent1, parent2 = random.sample(population[:pop_size // 2], 2)
child1, child2 = crossover(parent1, parent2)
mutate(child1, mutation_rate)
mutate(child2, mutation_rate)
new_population += [child1, child2]
population = new_population
return best_solution, best_fitness
# 示例参数
task_times = [10, 15, 20, 5, 10, 15] # 每个任务的时间
total_tasks = len(task_times)
workstations = 3
cycle_time = 40
# 运行算法
best_sequence, best_rate = genetic_algorithm(task_times, total_tasks, workstations, cycle_time)
print("最佳工序顺序:", best_sequence)
print("最佳生产平衡率:", 1 / best_rate)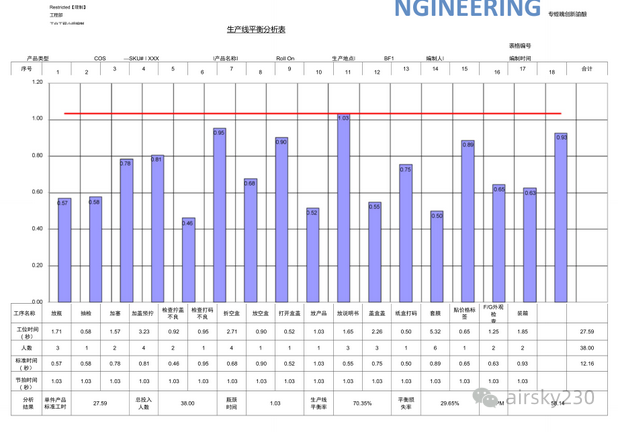


















 2138
2138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











