







本文来源公众号“3D视觉工坊”,仅用于学术分享,侵权删,干货满满。
原文链接:UC伯克利重磅开源HSfM:联合估计3D重建、相机位姿、3D人体姿态!
0. 论文信息
标题:Reconstructing People, Places, and Cameras
作者:Lea Müller, Hongsuk Choi, Anthony Zhang, Brent Yi, Jitendra Malik, Angjoo Kanazawa
机构:UC Berkeley
原文链接:https://arxiv.org/abs/2412.17806
代码链接:http://muelea.github.io/hsfm
1. 导读
我们提出了“运动中的人和结构”(HSfM),这是一种在公制世界坐标系中从一组稀疏的未校准的以人为特征的多视图图像中联合重建多个人体网格、场景点云和相机参数的方法。我们的方法将数据驱动的场景重建与传统的运动结构(SfM)框架相结合,以实现更准确的场景重建和相机估计,同时恢复人体网格。与缺乏度量尺度信息的现有场景重建和SfM方法相比,我们的方法通过利用人类统计模型来估计近似的度量尺度。此外,它在场景点云旁边的同一个世界坐标系中重建多个人体网格,有效地捕捉个体之间的空间关系及其在环境中的位置。我们使用健壮的基础模型初始化人、场景和摄像机的重建,并联合优化这些元素。这种联合优化协同提高了每个组件的精度。我们将我们的方法与现有方法在两个具有挑战性的基准EgoHumans和EgoExo4D上进行比较,证明了在世界坐标框架内人类定位精度的显著改善(在EgoHumans中将误差从3.51米减少到1.04米,在EgoExo4D中将误差从2.9m减少到0.56米)。值得注意的是,我们的结果表明,将人类数据纳入SfM管道可以改善相机姿态估计(例如,在EgoHumans上,RRA@15增加了20.3%)。此外,定性结果表明,我们的方法提高了整体场景重建质量。
2. 引言
近年来,将深度学习与多视图几何相结合,在3D人体重建和场景重建这两个关键领域取得了显著进展。然而,这些领域的进步在很大程度上是独立发展的。人体重建往往缺乏与其周围场景的关联锚点,而场景重建则通常排除了人物,并且无法恢复度量尺度。在本文中,我们提出了一个统一的框架,将这两个要素联系起来。
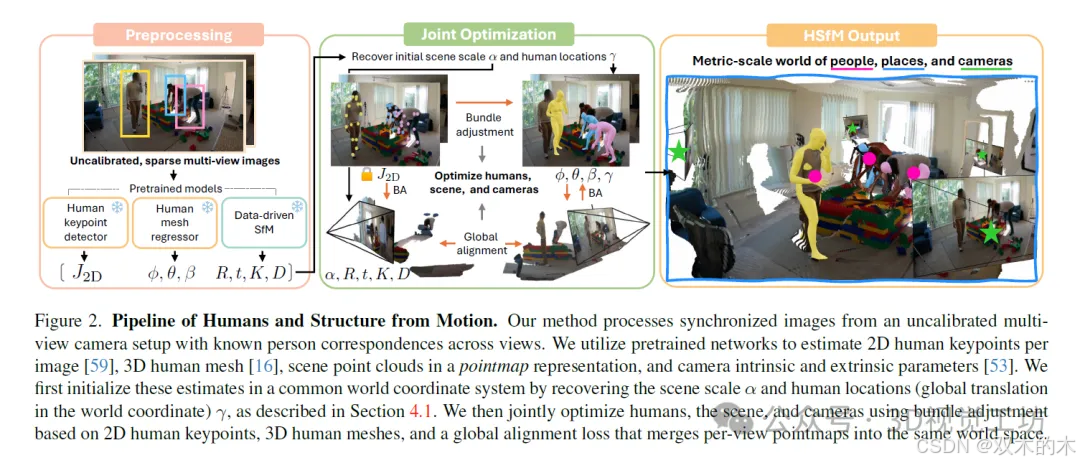
我们引入了“从运动中恢复人体和结构”(Humans and Structure from Motion, HSfM)这一新方法,它能够在相同的度量世界坐标系中联合重建多个人体网格、场景点云和相机参数。从包含人物的稀疏未校准多视图图像集合出发,我们的方法将数据驱动的场景重建与传统的从运动恢复结构(Structure-from-Motion, SfM)框架相结合,以提高场景和相机重建的准确性,同时估计人体网格。重建过程使用稳健的场景重建和人体重建基础模型进行初始化,并通过联合优化进一步细化。此优化结合了基于二维人体关键点预测的场景点图全局对齐损失和光束平差,显著提高了世界重建的三个组成部分(人体、场景和相机)的准确性。
与现有的多视图场景重建和人体姿态估计方法不同,HSfM在统一的世界坐标系中定位人体网格的同时,恢复了场景点云和相机姿态的度量尺度。HSfM的全面输出有助于捕获和评估个体之间的空间关系,确保与周围环境的一致性。此外,与以往依赖于精确相机校准[12, 20, 64]的多视图人体姿态估计方法不同,我们的方法对捕获设置的要求极低,并且不需要事先了解环境。
我们的方法基于两个关键见解。第一个见解是,基于深度学习的人体网格估计本身包含度量尺度信息,因为预测结果反映了训练数据集中存在的统计人体尺寸,从而限制了场景的尺度。第二个见解是,稳健的二维人体关键点预测和三维人体网格估计为光束平差提供了精确的对应关系和可靠的初始三维结构。请注意,为了本文的目的,我们假设跨相机视图的人员重识别是已知的。
3. 效果展示
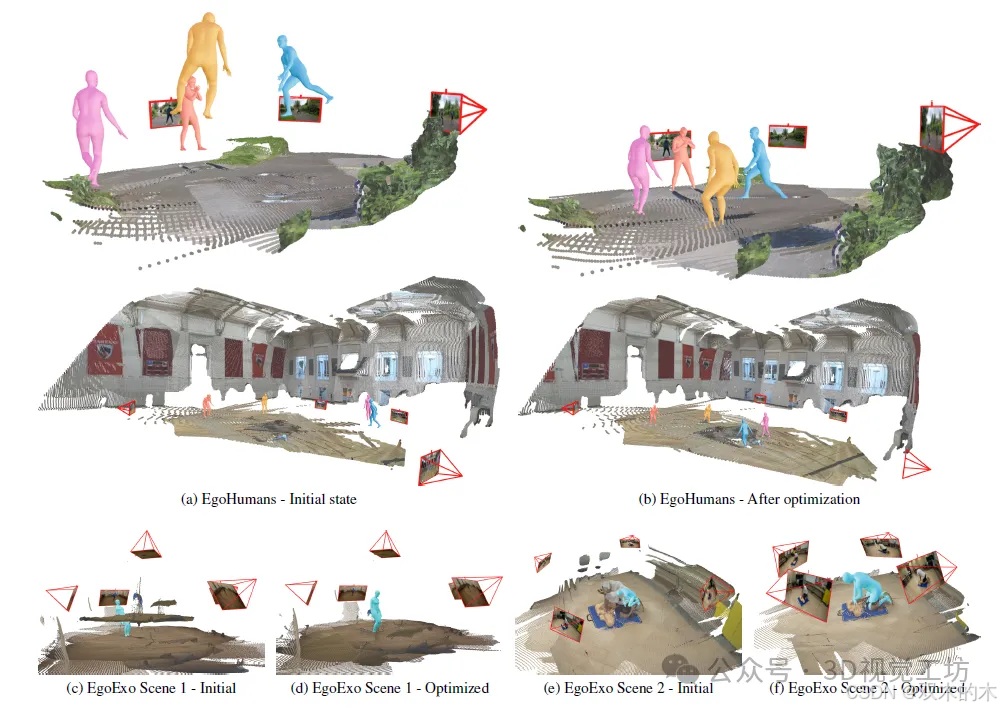
人类和运动结构HSM)。我们提出了一种方法,可以从描述人类的未校准、稀疏的图像集合中,联合重建人类、场景点云和相机。通过明确地将人类纳入传统的运动结构(SfM)框架,利用2D人类关键点对应和从现成的场景和相机重建模型中利用稳健的初始化,我们的方法表明,整合这三个元素--人类、场景和相机--可以协同提高每个组件的重建准确性。与先前的SfM和人体姿态估计工作不同,我们的方法在人体网格预测的基础上重建度量级场景点云和相机参数,同时将人体网格定位在与周围环境一致的连贯世界坐标中,而不需要任何明确的接触约束。

HSfM的定性结果。我们展示了我们在EgoHumans(顶部)和EgOEx04D(底部)序列上的优化结果。请注意,在初始状态(左侧)中,人们漂浮在空中(a),场景和人类比例不协调(e),场景看起来很嘈杂(c)。我们的方法通过使人在场景中定位(b),恢复合理的度量尺度(f) 和更好的相机估计()来解决这些问题。我们实现了这一点,假设最少,且没有场景接触约束。
4. 主要贡献
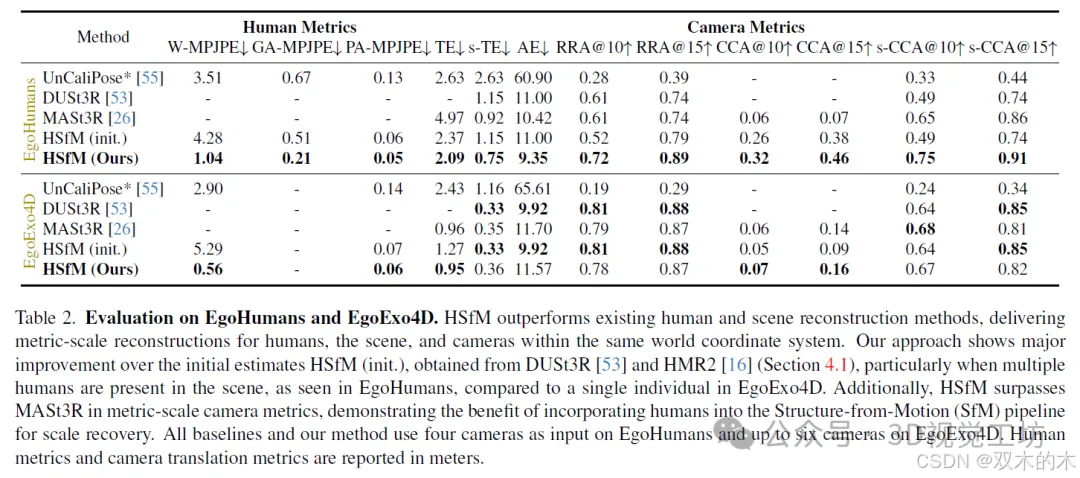
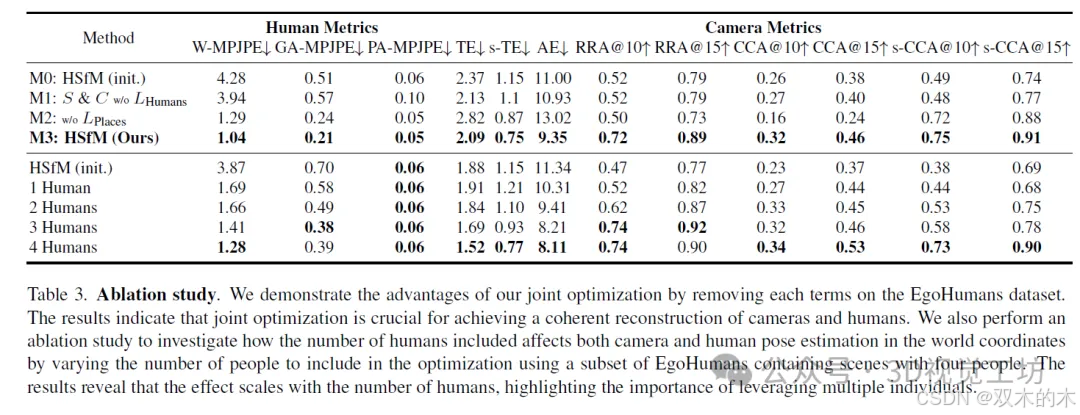
我们在两个具有挑战性的基准测试集EgoHumans和EgoExo4D上评估了我们的方法,这些测试集中的个体参与了不同环境中多种多样的室内和室外活动。我们通过将我们的方法与其他在世界坐标系中估计人体姿态的方法[56]进行比较,评估了人体网格重建的准确性。此外,我们还将相机姿态的准确性与学习型密集场景重建方法(如DUSt3R和MASt3R)进行了比较。与现有方法相比,我们的方法在相机姿态估计方面表现出显著改进,同时能够准确地将个体定位在场景中。具体而言,它在人体度量指标上实现了约3.5倍的提升,将EgoHumans上的人体世界位置误差从3.51米降低到1.04米,并且在与最相关基线的比较中,相机度量指标提升了约2.5倍。这些结果突显了我们方法的有效性,该方法通过稳健的人体和相机初始化,支持多个人体网格、场景点云和相机的联合重建。我们通过消融实验进一步验证了我们的设计,这些实验显示了人体、场景和相机之间的协同效应。
我们的定性结果表明,对人物(多个人)、地点(场景)和相机进行联合优化,不仅提高了人体定位的准确性,还改进了场景重建和相机姿态估计。
综上所述,我们提出了“从运动中恢复人体和结构”(HSfM),它提供了包含人物、地点和相机的世界综合表示,标志着在理解复杂现实世界环境方面迈出了一步。更多结果请访问项目网站:muelea.github.io/hsfm。
5. 方法
我们的方法以未校准的稀疏图像集作为输入,这些图像捕捉场景中某一时段内的人。给定这个输入,我们的目标是对每个人的人体参数、场景和相机参数进行联合估计。我们的关键见解是,对人物、场景结构和相机的联合推理可以改善重建的三个方面。为了实现这一目标,我们将最近场景重建方法的全局场景优化方法与传统的结构自运动(SfM)公式相结合。该集成利用2D人类关键点作为可靠的对应关系,并利用3D人类网格作为三维结构进行捆绑调整。请参阅图2。
我们的联合优化方法提供了几个关键优势通过结合人体网格预测,该方法将度量尺度引入到重建过程中,利用人体尺寸的统计信息。相机和2D人体关键点使得个体在世界坐标系中的精确定位成为可能,从而恢复他们的身高和相对距离。此外,2D人体关键点的对应关系增强了相机校准,从而改善了场景重建。场景结构进一步稳定了相机姿态注册,创建了一个反馈回路,以完善整个系统。结果是整个人类、场景和相机在全局范围内的统一重建,提供了对环境的全面理解。
由于这是一个欠定问题,我们利用数据驱动的3D人体和场景重建方法提供初始化。在以下部分中,我们描述如何将这些独立实体对齐到一个共同的世界坐标框架中,然后对人物、场景和相机进行联合优化。
6. 实验结果
7. 总结 & 未来工作
在这项工作中,我们提出了人类和运动结构,HSfM,它在一个联合框架中优化了人类、场景和相机。我们建立在两个平行领域--2D/3D人类重建和场景重建--数据驱动学习的成功基础上。然而,这两种方法都无法连贯地重建人类、场景和相机。我们的实验验证了这三个元素之间的协同作用--将人类重建整合到经典的运动结构任务中,不仅适当地将人放置在世界中,而且显著提高了相机姿态的准确性。虽然我们的方法给出了有希望的结果,但它是一个基于优化的框架,可能会对超参数敏感。在未来的工作中,探索这种协同作用的前馈框架将是有趣的。将这一见解扩展到视频也将是令人兴奋的。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 719
719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









