







论文链接:https://arxiv.org/pdf/2207.06674
代码链接:https://github.com/Chrystalii/CERec
1 动机
现有的反事实解释方法(Counterfactual Explanation)旨在通过最小化的修改(如改变用户或物品的某些属性)来解释推荐系统的决策过程。然而,现有的反事实可解释方法存在以下问题:
1:现有方法面对极其庞大的搜索空间,在此空间中很难高效找到合适的反事实解释。
2:传统的可解释方法多基于行为(例如,用户点击)或基于方面(如物品的属性),这些方法往往不够直观,难以帮助用户理解推荐系统的决策过程。
3:物品属性或用户行为对推荐结果的影响尚未得到充分且直观的解释。
2 贡献
1 提出了强化路径推理方法:该方法通过强化学习技术来引导路径推理,从而高效探索反事实解释。通过优化路径推理过程,能够在庞大的搜索空间中找到最佳的反事实解释。通过结合强化学习与路径推理,从而提出了一种可扩展的反事实推理方法
2 设计了基于物品属性的反事实解释:物品属性的解释比传统的行为或描述方式更直观。通过深入挖掘物品的属性信息,能够更有效地为用户提供推荐系统决策的可解释性。如下图所示:
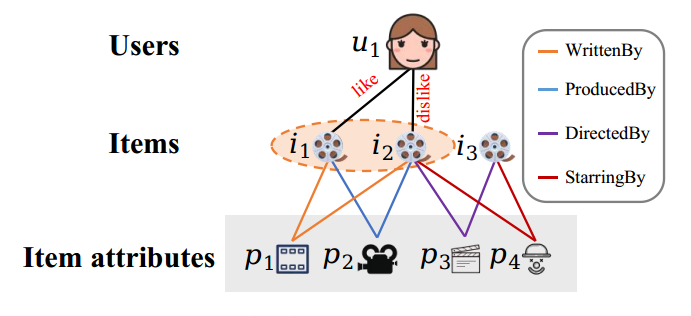
U1对属性为(p1-p4)的i2给出负反馈,那么可以推理出p1-p4的属性信息解释了用户的负面偏好,但是用户有喜欢属性为p1,p2的项目i1,因此p3和p4才真正可能引起用户的负反馈。
使用了属性信息+强化学习,类似于这一篇,总结部分会总结两篇论文的差异。TOIS24|推荐公平性的反事实解释_配送公平性分数的解释-CSDN博客
3 准备
3.1 推荐的反事实解释
反事实解释定义为原始样本的最小扰动集,如果应用该扰动集,将导致与样本相反的预测。通过寻找一个最小的项目属性集,其中最小扰动集被定义为一组项目属性,例如类型,品牌![]() 。使用推荐模型和属性集∆ui,优化目标是估计将∆ui应用于推荐项目i是否会导致用户u将i替换为不同的项目j。如果优化目标满足,则将属性集∆ui称为反转推荐结果的反事实解释。利用优化后的∆ui,可以生成向用户u推荐商品i的反事实解释,其形式为:
。使用推荐模型和属性集∆ui,优化目标是估计将∆ui应用于推荐项目i是否会导致用户u将i替换为不同的项目j。如果优化目标满足,则将属性集∆ui称为反转推荐结果的反事实解释。利用优化后的∆ui,可以生成向用户u推荐商品i的反事实解释,其形式为:

3.2 问题定义
在协作知识图G的基础上,构建一个反事实解释模型,利用协作知识图之间的丰富关系为原始推荐项目生成反事实项目。
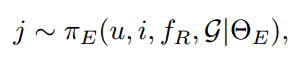
πE(·)为用ΘE参数化的反事实解释模型,fR为产生推荐结果的Top-K推荐模型。反事实解释模型在G中生成项目的经验分布,从而为推荐项目i生成反事实项目j,并且将反事实项目作为负样本,设计了成对排序学习策略:
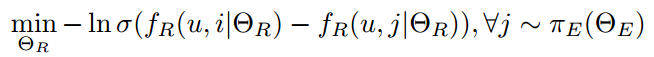
4 模型
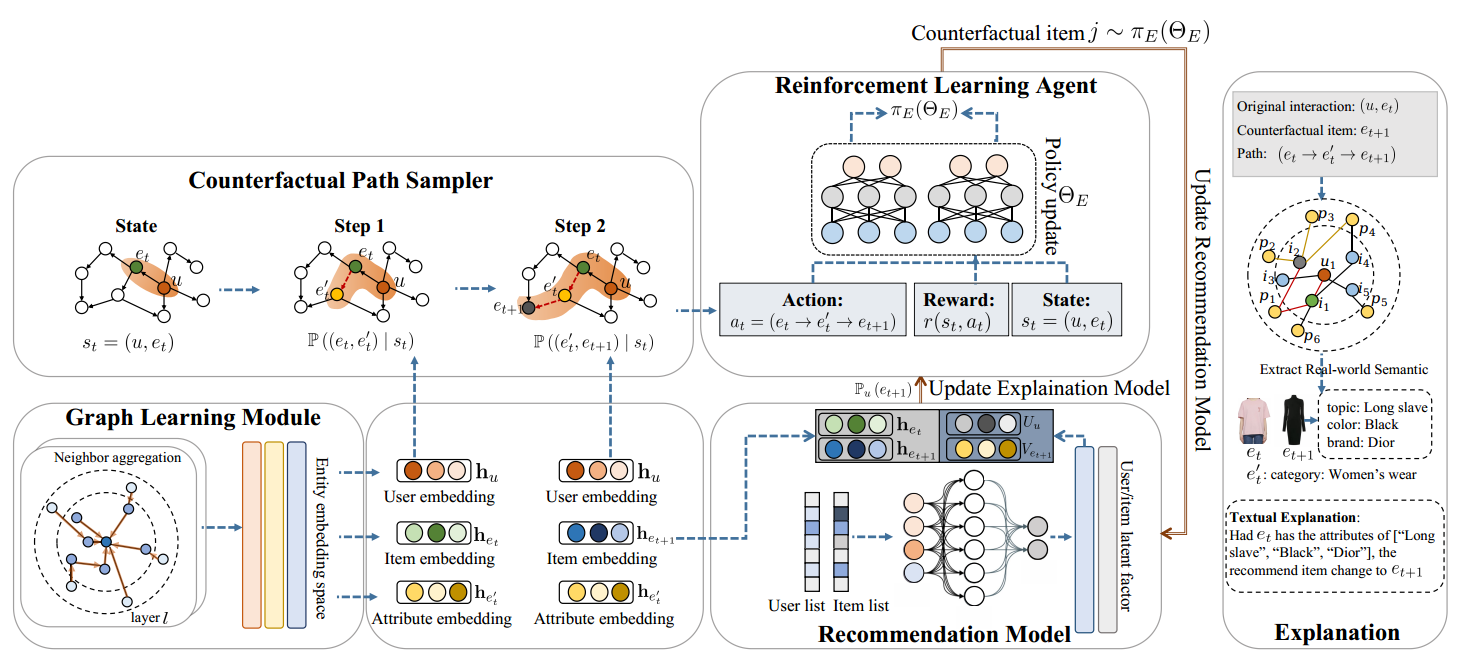
CERec由三个模块组成:一个推荐模型,一个图学习模块和提出的反事实解释模型。
推荐模型生成排名分数,并通过交互聚合生成的反事实项与反事实解释模型共同训练。
图学习模块在给定的CKG中嵌入用户、项目和属性实体作为嵌入向量。
反事实解释模型基于实体嵌入和分数排序进行有效路径抽样,发现高质量的反事实条目。主要包括两个部分:1)反事实路径采样器:使用实体嵌入对路径进行采样,作为强化学习代理的动作;2)强化学习代理:通过优化来自采样器的部署动作的累积反事实奖励来学习解释策略。
4.1 推荐模块
采用两两学习排序模型clif作为推荐模型。clif将用户和项目的id初始化为潜在因素,并通过直接优化Mean Reciprocal Rank (MRR)来更新潜在因素,预测用户对项目的排名分数。首先利用推荐模型将用户和商品映射为潜在因素:
![]()
损失函数:
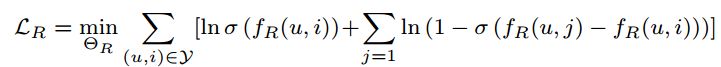
通过优化损失函数,可以根据u和V得到来自用户u的每个物品i的排名分数:
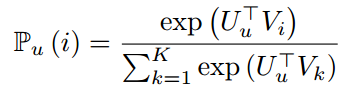
4.2 图学习模块
图学习模块(GLM)从给定的协作知识图g中使用GraphSage学习用户、项目和属性表示(即嵌入),将学习到的嵌入部署到反事实解释模型中:
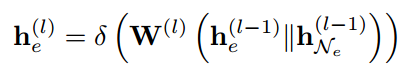
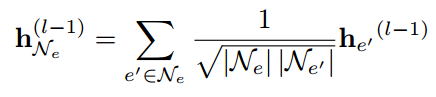
得到多层的嵌入后,采用层聚集机制将各层的嵌入连接成单个向量![]()
4.3 反事实解释
反事实解释包含两个主要部分:反事实路径采样器和强化学习代理。反事实路径采样器对来自GLM的用户、项目和属性嵌入执行两步走,以搜索每个状态st的高质量路径作为动作at,然后将动作at和状态st馈送到强化学习代理中以学习解释策略。基于推荐模型和项目嵌入产生的排名分数,强化学习代理学习奖励r(st;at)状态st,并相应更新解释策略πE(ΘE)。最后,基于学习到的解释策略πE和路径历史,生成基于属性的推荐反事实解释。
4.3.1 反事实路径采样器(CPS)
在CKG上进行路径探索,将采样路径视为后续解释策略学习中的一个动作。基本思想是:针对目标用户,从推荐的项目出发,沿着项目的属性进行导航,并通过采样路径生成潜在的反事实项目。为了减少候选动作空间,过滤掉不相关的路径并选择重要路径。使用注意力机制来计算目标实体在特定条件下对源实体的重要性,从而生成有效的采样路径。
在每个状态st,CPS产生给定CKG的路径作为动作![]()
从一个项目Et到另一个项目Et +1的路径,E't 是项目属性。通过两步路径采样生成Et +1
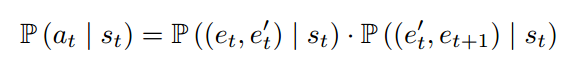
(1) 通过计算注意力来选择项目的一个属性;
(2) 根据属性选择项目作为反事实样本。
第一步路径采样![]() 计算项目Et不同属性E't 的重要性。在得到项目
计算项目Et不同属性E't 的重要性。在得到项目、属性
和用户
的嵌入后,计算项目属性
重要性得分并归一化:
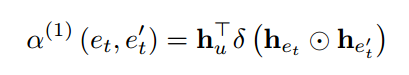
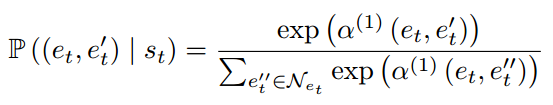
第二步在选择好项目属性后,使用注意力决定从相邻的项目中选出作为反事实的项目,并归一化,并筛选出不属于推荐列表Qu的项目:
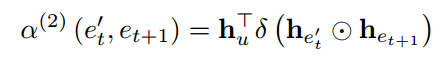
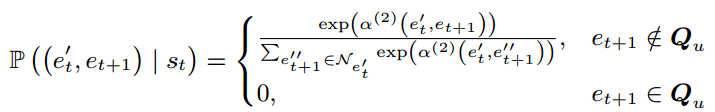
4.3.2 强化学习代理
将反事实解释模型作为基于路径的强化学习代理来发现高质量的反事实项目。每个动作都是通向候选反事实项目的路径。反事实解释模型获得反事实奖励r(st;at) 对于这个特定的状态-作用对。学习最终的解释策略以最大化预期累积反事实奖励:
S:是描述CKG中目标用户和当前访问项实体的连续状态空间。对于用户u,在步骤t,用户状态st定义为st = (u;et),其中u为特定用户,et为代理当前访问的项目实体。
•A:动作的离散空间。动作是从CPS 采样的路径
•P:是状态转移,吸收当前状态到下一状态的转移概率。(两个注意力机制,首先计算项目属性的重要程度,接下来依据项目属性的重要程度选择下一个项目作为反事实的项目)。
![]()
•R: ![]() 是反事实奖励,通过部署行动at来衡量项目et+1是否是有效的反事实项目。根据两个标准定义:1)合理性:与原始项目et相比,et+1应从当前用户u的推荐列表中删除的置信度应该很高;2)相似性:由于反事实解释要求反事实项目与原始项目之间的项目属性变化最小,因此et+1应尽可能与原始项目et相似:
是反事实奖励,通过部署行动at来衡量项目et+1是否是有效的反事实项目。根据两个标准定义:1)合理性:与原始项目et相比,et+1应从当前用户u的推荐列表中删除的置信度应该很高;2)相似性:由于反事实解释要求反事实项目与原始项目之间的项目属性变化最小,因此et+1应尽可能与原始项目et相似:
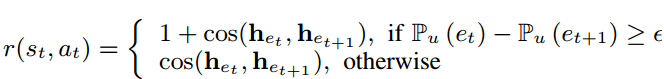
反事实解释模型寻求一个反事实解释策略πE,使累计奖励R(πE)在强化深度T上最大化:

Case study
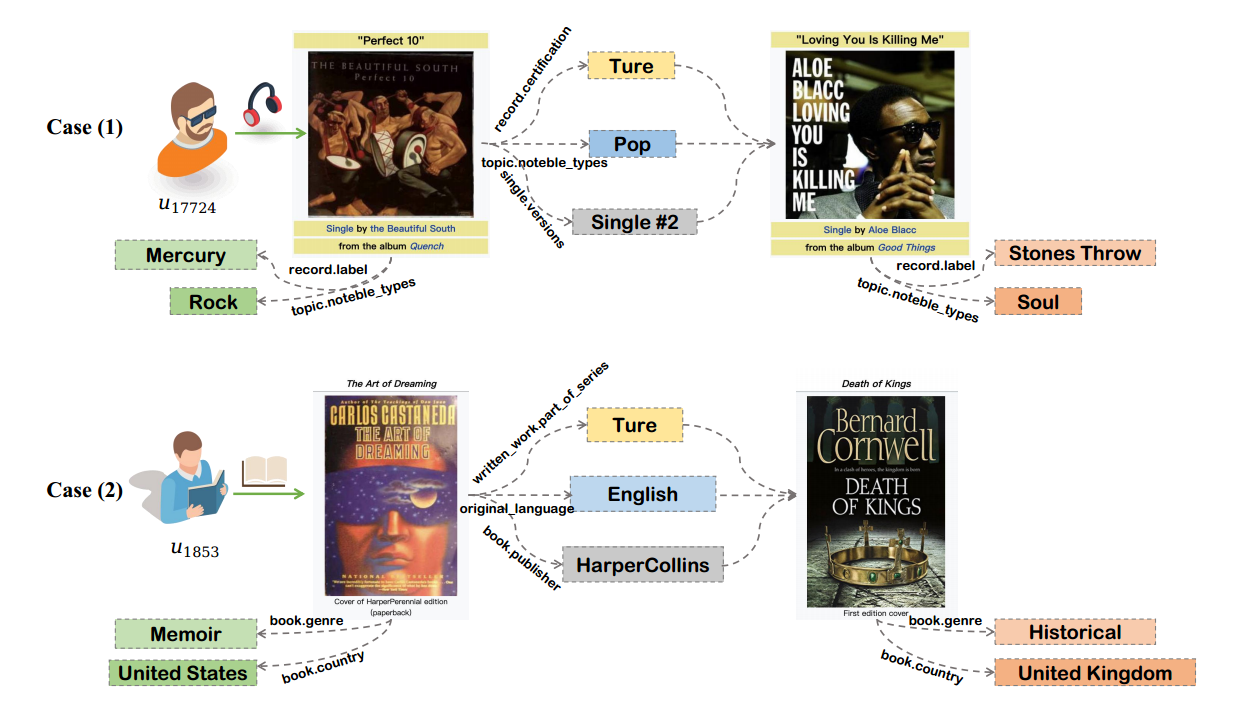
针对Last-FM数据集,其中用户u17724在他的收听记录中与“Perfect 10”进行了积极的交互。cerc选择了“爱你是在杀我”作为反事实项目,它与“完美10”有三个重叠的项目属性。传统的可解释推荐模型会选择这三个常见的项目属性来生成解释,比如“你喜欢完美10是因为你喜欢流行音乐”。然而,这个解释并不能解释为什么具有相同物品属性的“爱你要了我的命”实际上被从用户推荐列表中删除了。相比之下,CERec捕获了反事实的项目属性(即Stones Throw和Soul),并生成了反事实的解释,“如果完美10的标签为Stones Throw,类型为Soul,那么它将不再被推荐。”这种反事实的解释让我们对用户的真实偏好有了更深入的了解。
5 总结
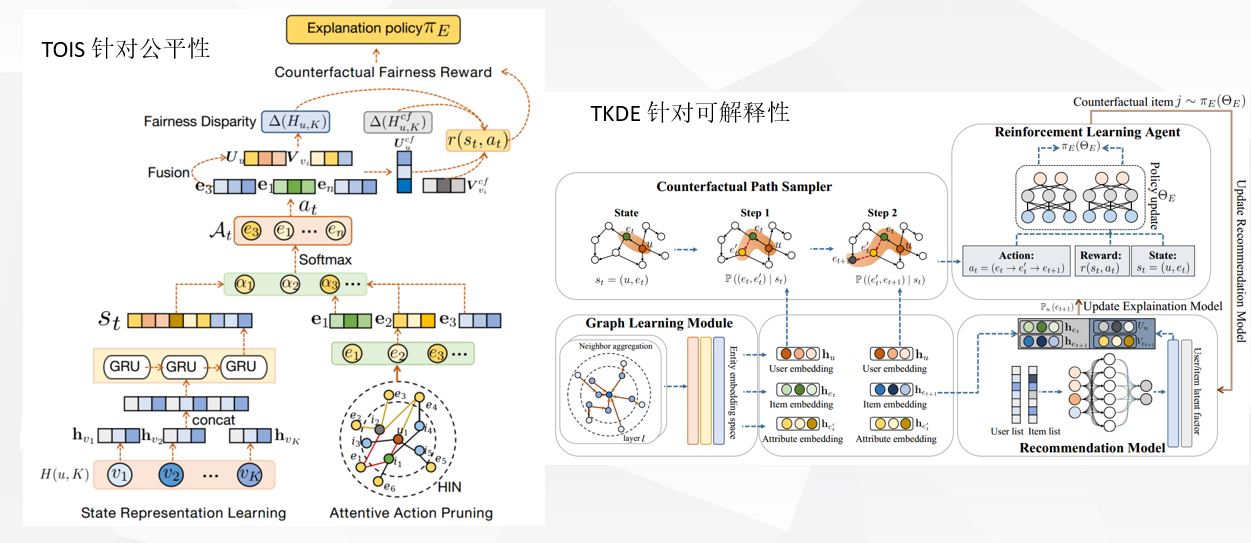
TOIS24|推荐公平性的反事实解释_配送公平性分数的解释-CSDN博客 (上图左 针对公平性的CFairER)和本文针对可解释性的CERec,都是来自于同一个团队的。也是分别针对公平性和可解释性来展开的工作,两个工作都用到了因果推理中的反事实来做,并且都是使用了属性信息。由上图可见其实都分为三个部分。1:嵌入学习:CFairER用的GRU编码时序讯息,CERec由于使用了协作图,使用了GraphSage 2:属性+注意力:CFairER使用注意力机制剔除无用的属性,将属性信息与用户项目嵌入融合生成反事实项目,CERec则使用了两个注意力去得到反事实项目。3:强化学习,指导下一阶段的动作。
两篇论文数据集使用了三个,有两个是重复的。那么本文的CERec由于不同点在于使用了CKG:
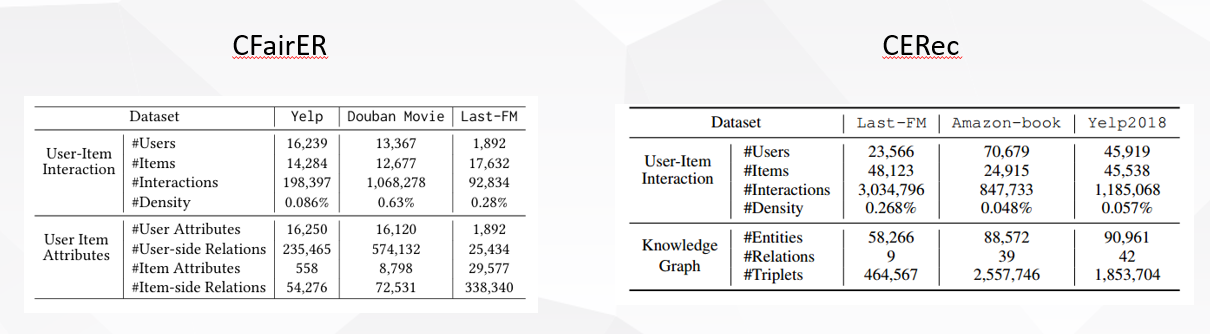
说到可解释性和公平性,两者的不同:
首先针对于公平性, CFairER定义了:公平性差异--衡量推荐结果的不公平程度。采用两种指标来评估推荐结果的公平性:(1)人口平价: 要求推荐系统对所有物品组(如热门组G0和长尾组G1)具有相同的曝光概率。(2)精确-K: 要求物品的曝光分布在统计上不超过预设的最大偏差 α。并使用理性准则:选择的动作应显著改善推荐结果的公平性:当动作 at 显著降低公平性差异时,![]() 奖励函数给出更高的奖励值。邻近性准则:选择的动作应尽量减少对用户和物品嵌入的改变。在得到反事实后,计算反事实推荐结果的公平性差异
奖励函数给出更高的奖励值。邻近性准则:选择的动作应尽量减少对用户和物品嵌入的改变。在得到反事实后,计算反事实推荐结果的公平性差异 ![]() 与原始推荐结果的公平性差异
与原始推荐结果的公平性差异![]() 的变化,验证反事实修改的有效性,体现了公平性。
的变化,验证反事实修改的有效性,体现了公平性。
其次针对可解释性:使用了反事实路径采样器,经过两次注意力的计算(首先计算属性的注意力,基于属性再去计算属性相邻的项目,从而生成反事实项目)。使用强化学习,并根据反事实解释策略πE,使累计奖励R(πE)在强化深度上最大化,来提升可解释性。

















 3815
3815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









