






线性注意力机制是一种改进传统自注意力(Self-Attention)的方法,旨在降低计算复杂度并提高效率。传统自注意力机制的计算复杂度是输入序列长度的二次方(O(n²)),这使得它在处理长序列时效率较低且计算成本高昂。
我还整理出了相关的论文+开源代码,以下是精选部分论文
更多论文料可以关注 :AI科技探寻,发送:111 领取更多[论文+开源码】
:AI科技探寻,发送:111 领取更多[论文+开源码】
论文1
标题:
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
Griffin:结合门控线性递归和局部注意力以提高语言模型效率
方法:
-
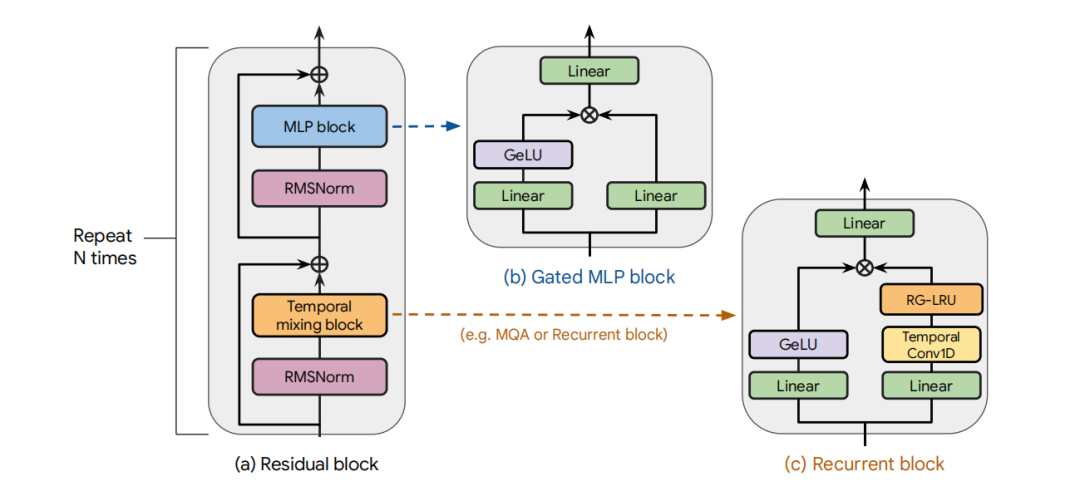
RG-LRU层:提出了一种新的门控线性递归层(RG-LRU),用于替代多查询注意力(MQA)。
-
混合模型架构:设计了两种模型——Hawk(纯递归模型)和Griffin(混合递归和局部注意力的模型)。
-
门控机制:在RG-LRU中引入了输入门和递归门,允许模型在保留历史信息的同时过滤不重要的输入。
创新点:
-
Griffin模型:在训练时使用的token数量比Llama-2少6倍的情况下,Griffin匹配了Llama-2的性能。
-
长序列推理:Griffin能够处理比训练时更长的序列,且在长序列任务上表现优于Transformer基线。
-
推理效率:在推理阶段,Griffin和Hawk的吞吐量比MQA Transformer高出14.8倍,延迟更低。
-
硬件效率:在训练时,Griffin与Transformer的硬件效率相当,且在推理时具有更低的延迟和更高的吞吐量。
论文2
标题:
Simple linear attention language models balance the recall-throughput tradeoff
简单的线性注意力语言模型平衡了回忆和吞吐量的权衡
方法:
-
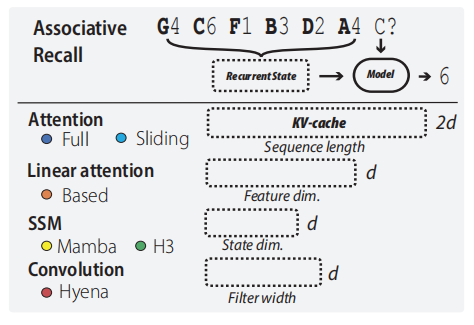
基于线性注意力的架构(Based):提出了一种结合线性注意力和滑动窗口注意力的混合架构。
-
Taylor线性注意力:使用二阶泰勒展开近似softmax函数,实现线性注意力的高效计算。
-
滑动窗口注意力优化:通过选择小窗口大小(如64或128),优化了滑动窗口注意力的硬件效率。
创新点:
-
回忆能力提升:Based模型在回忆任务上比Mamba等子二次模型高出6.22个准确度点。
-
吞吐量优化:在生成1024个token时,Based的吞吐量比FlashAttention-2高出24倍。
-
硬件效率:通过小窗口大小和硬件感知算法,Based在推理时的延迟比大窗口模型低1e-5倍。
-
平衡权衡:Based通过调整线性注意力的特征维度和滑动窗口大小,能够在回忆能力和吞吐量之间灵活权衡。
论文3
标题:
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
训练短序列,测试长序列:线性偏置注意力实现输入长度的外推
方法:
-
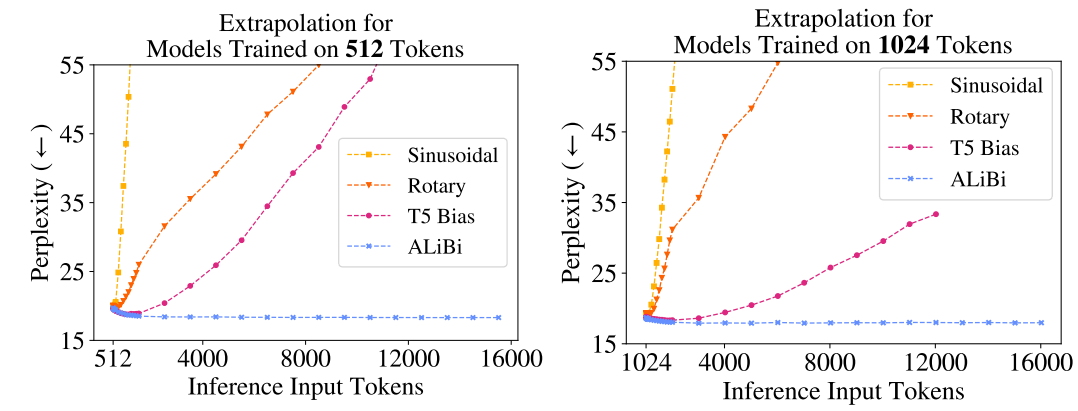
线性偏置注意力(ALiBi):提出了一种新的位置编码方法,通过在注意力分数中引入与距离成比例的线性偏置,而不是添加位置嵌入。
-
位置编码优化:ALiBi通过消除位置嵌入,直接在注意力分数中引入偏差,从而提高模型对序列长度的适应能力。
-
简单实现:ALiBi通过修改现有Transformer代码中的几行代码即可实现,无需额外的训练参数。
创新点:
-
性能提升:ALiBi在训练时使用的输入序列长度为1024,但在测试时能够处理长度为2048的序列,并且在困惑度上与训练长度为2048的正弦位置编码模型相当,同时训练速度提升11%,内存使用减少11%。
-
长序列外推:ALiBi能够有效外推到比训练时更长的序列,且在长序列任务上表现优于其他位置编码方法。
-
计算效率:ALiBi在训练和推理时的运行速度与正弦位置编码方法相当,且在某些情况下更快,同时内存使用略有增加(最多100MB)。
论文4
标题:
When Linear Attention Meets Autoregressive Decoding: Towards More Effective and Efficient Linearized Large Language Models
当线性注意力遇上自回归解码:迈向更高效、更有效的线性化大型语言模型
方法:
-
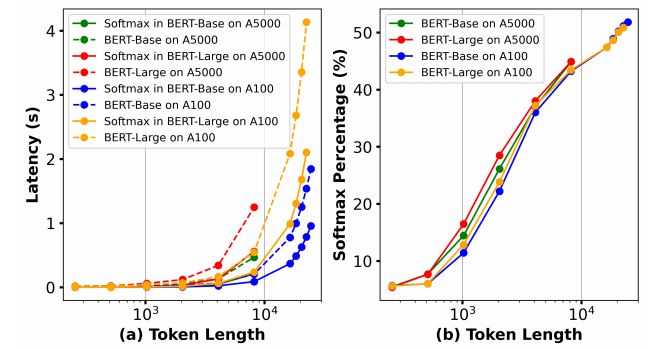
线性注意力增强:提出了一种新的线性注意力增强技术,通过引入因果掩码的深度可分离卷积(DWConv)来防止信息泄露。
-
分组线性注意力:将输入序列划分为非重叠组,通过局部注意力和分组注意力的结合提高效率。
-
与推测解码的兼容性:开发了一种与推测解码兼容的线性注意力方法,通过展开卷积核并结合树状注意力掩码,实现高效的并行生成。
创新点:
-
性能提升:在LLaMA模型上,使用增强的线性注意力方法实现了高达6.67倍的困惑度降低。
-
生成加速:与现有线性注意力方法相比,生成速度提升高达2倍。
-
长序列支持:通过增强的线性注意力,模型能够支持更长的序列长度(从8K扩展到32K),同时显著降低延迟和内存使用。
更多论文料可以关注:AI科技探寻,发送:111 领取更多[论文+开源码】

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









