







多数数据集中有蛋白质序列但不存储蛋白质ID,这使得PDB文件获取困难,如何找到蛋白质序列对应的ID,参考以下(还没有找到批处理方法,如果有知道的小伙伴评论区留言):
2. 高级搜索:
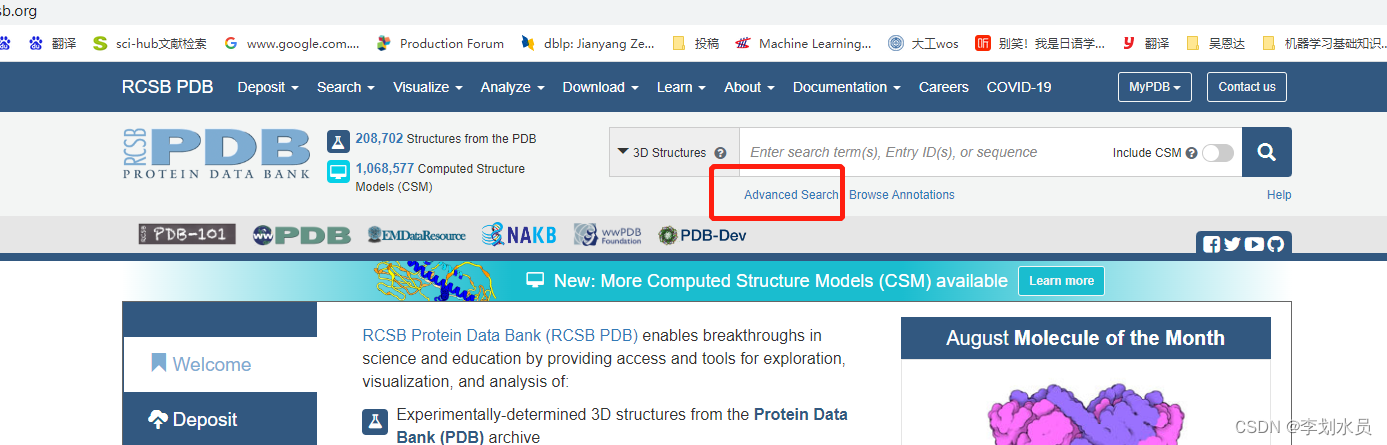
3. 输入目标序列
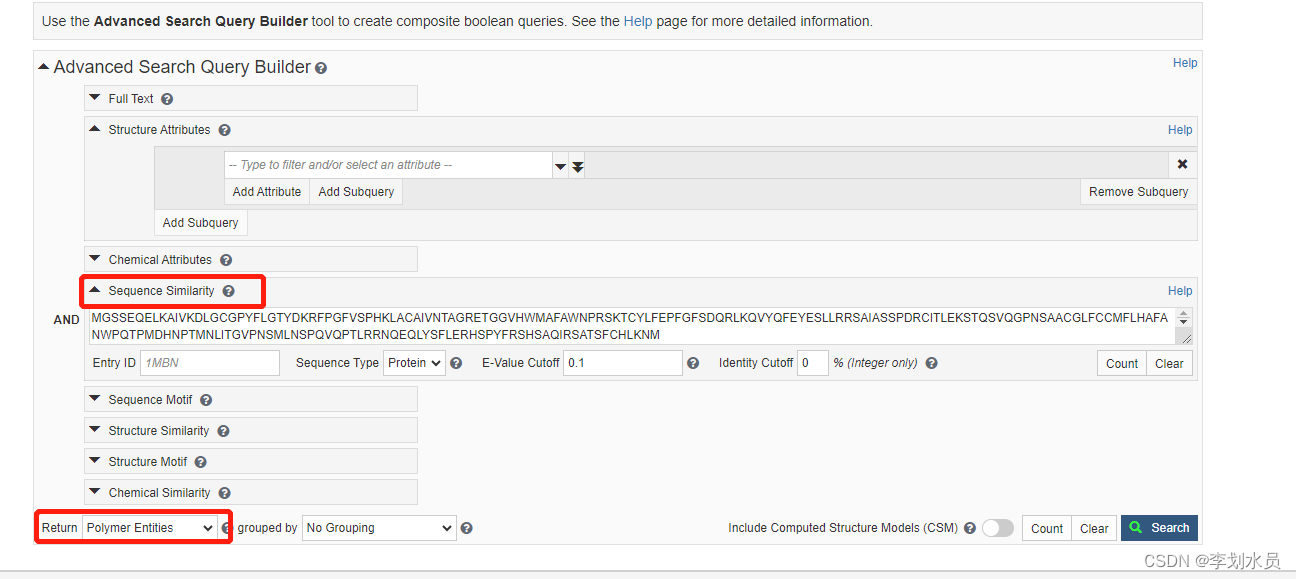
4. 筛选,左边有物种,0.98为score,取score最小的,原理不知。
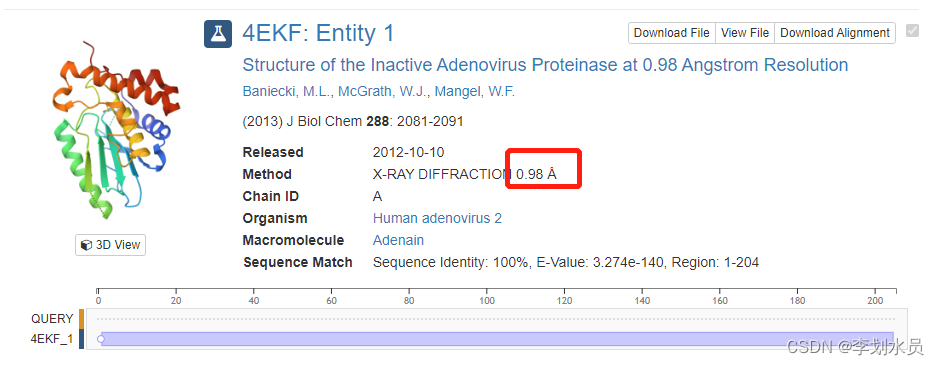
5. 可下载相关文件
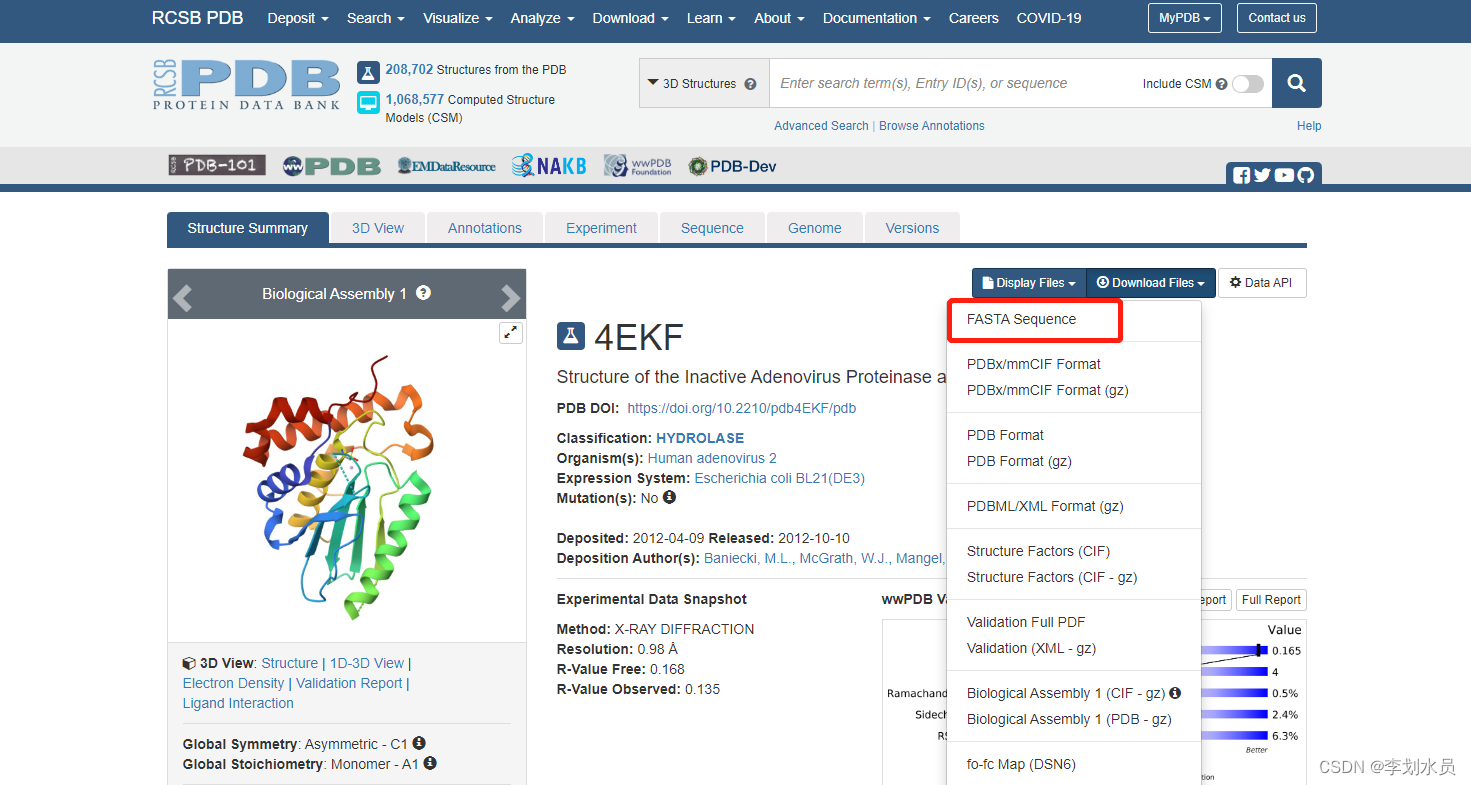
7. 验证结果:判断序列与找到的蛋白质ID序列是否一致
输出YES
多数数据集中有蛋白质序列但不存储蛋白质ID,这使得PDB文件获取困难,如何找到蛋白质序列对应的ID,参考以下(还没有找到批处理方法,如果有知道的小伙伴评论区留言):
2. 高级搜索:
3. 输入目标序列
4. 筛选,左边有物种,0.98为score,取score最小的,原理不知。
5. 可下载相关文件
7. 验证结果:判断序列与找到的蛋白质ID序列是否一致
输出YES
 1万+
916
1万+
916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言























