






前提:有一批基因(有基因名,转录本编号:NM_xxxx.x,UniprotID),需要下载这些基因(相应转录本)的蛋白质氨基酸序列。
过程:
一、下载单个基因(某个转录本)的蛋白质序列:
----- 找到指定转录本(NM_xxx)对应的蛋白质序列(NP_xxx)
a. 根据基因名在NCBI-Gene数据库中找到该基因,在该基因的详细页面中,通过ctrl+F 搜索NM编号,找到NM编号对应的NP编号,点击NP编号链接,转到下载氨基酸fasta序列页面。
b. 根据基因名在Uniprot数据库中搜索,在Uniprot页面中ctrl+F搜索"refseq",可看到该基因所有的转录本NM_编号及对应的蛋白NP_编号,点击NP_可转到下载序列页面
以CHD7基因为例,在Uniprot数据库中找到Human的Entry:
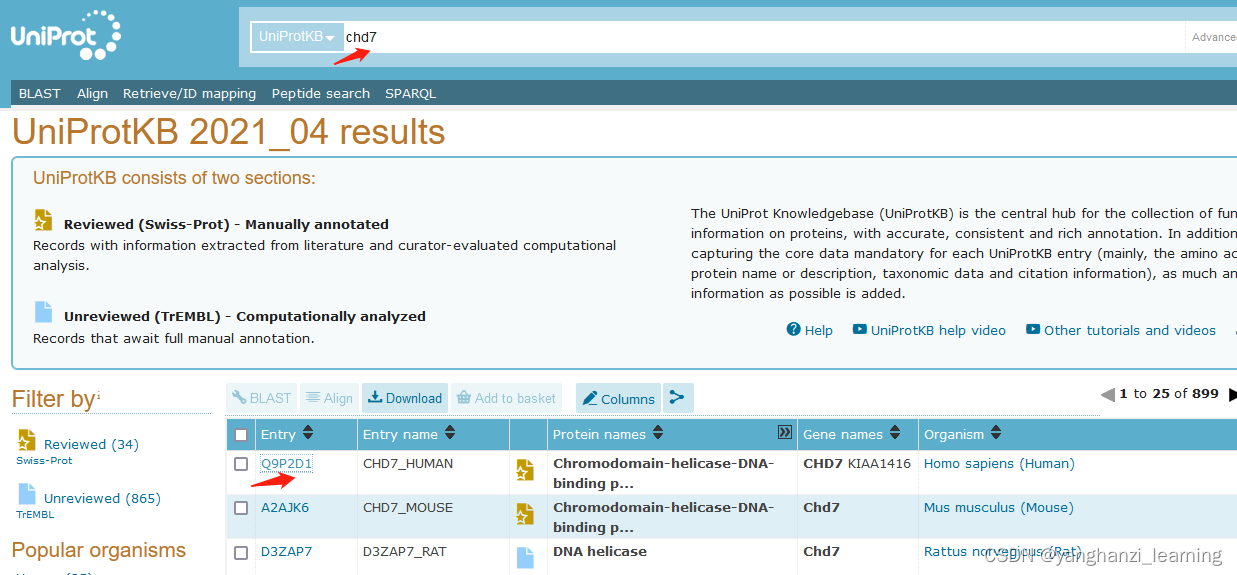
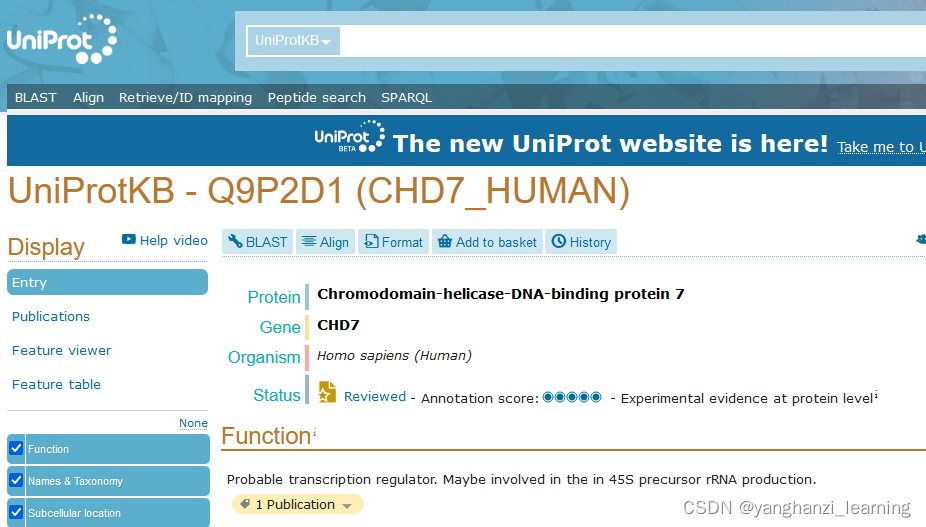
在CHD7_Human页面中,ctrl+F搜索"refseq",可看到该基因所有的转录本NM_及对应的蛋白NP_:
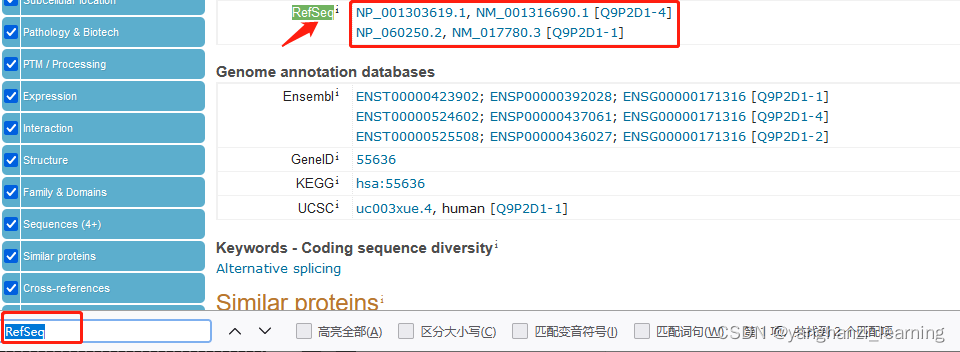
点击NP_xx即可转到下载蛋白序列页面。
二、获取这些基因指定转录本(NM_xxxx)对应的NP_xxx信息,再根据NP编号批量下载蛋白序列
1. 按照上面的方式,逐个查询并记录指定转录本的NP编号。
2. 是否有数据库能同时提供NM_xx及对应NP_xx信息?--批量获取
-------Uniprot数据库-Retrieve/ID mapping,可根据某一类型的identifier批量获取其他多种信息:
包括Gene name, Length, Sequence, PDB 等。
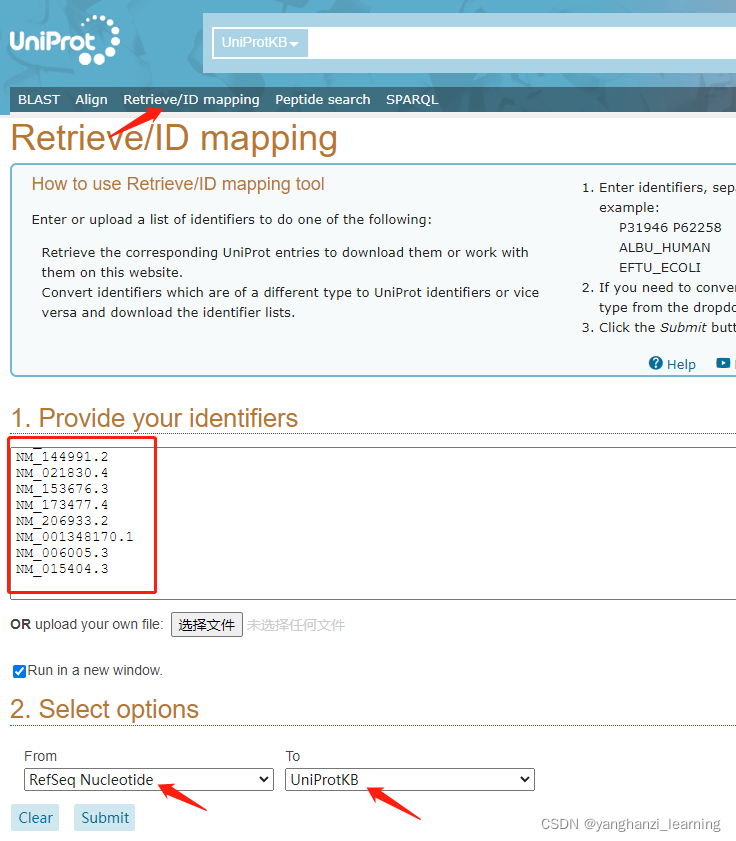
"Columns"设置需要展示的信息(Gene name, Length, Sequence, PDB 等),并可调整好column顺序后下载到本地:
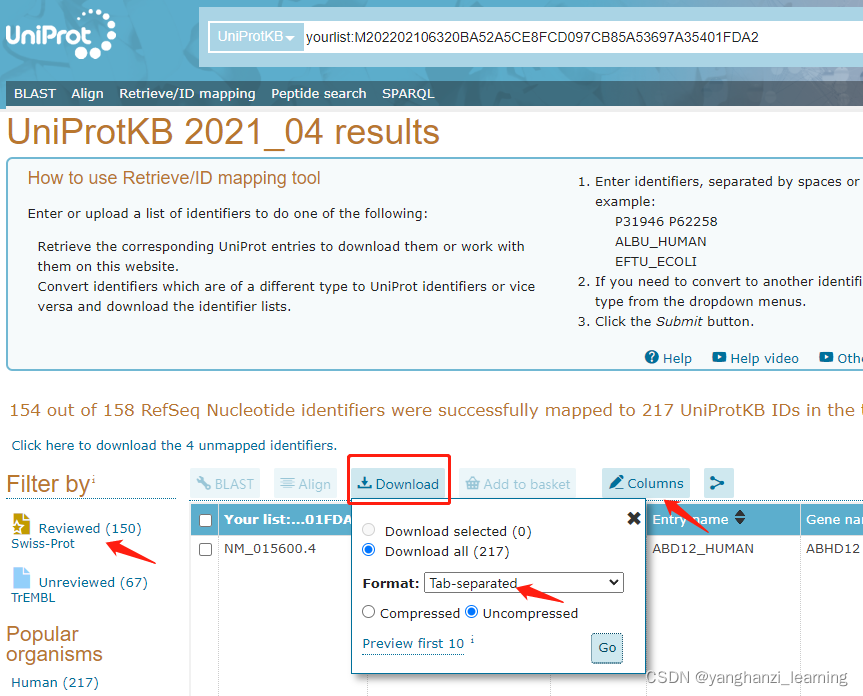
可在下载前选择Reviewed的部分,或者下载后在Status列筛选"reviewed"的内容。(一般用到的是reviewed的)

















 4005
4005

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









