










经过粉丝介绍发现,英国医学期刊 (British Medical Journal,简称BMJ)上有许多关于预测模型的文章,许多还有R语言代码,我整理后准备推出个系列教程。这是第一篇,关于计算开发临床预测模型所需的样本量。
作者指出:临床预测模型旨在预测个体的结果,为医疗保健的诊断或预后提供信息。许多预测模型是使用数据集开发的,而该数据集对于参与者或结果事件的总数来说太小了。
开发预测模型需要一个开发数据集,其中包含来自目标人群的个体样本的数据,其中包含他们观察到的预测变量值和观察到的结果。开发数据集的样本量必须足够大,才能开发一个预测模型方程,该方程在应用于目标人群中的新个体时是可靠的。然而,什么构成了足够大的样本量用于模型开发尚不清楚。
然后作者提出了一个自己的看法:
超越每个变量 10 个事件的经验法则经常被广泛的使用,在为二元或事件发生时间结果开发预测模型时,所需样本量的既定经验法则是确保每个预测变量参数(即回归方程中的每个β项)至少有 10 个事件被考虑包含在预测模型方程中。就是说每个协变量至少要有10个阳性的结果。但有些是变量是3分类变量,这样β项就会增加,导致样本量需要更加多。

接下来作者提出了他对预测模型样本量的看法:
- 样本量能否足够精确估计总体风险?
- 多大的样本量可以使预测的平均绝对误差较小?
- 多大的样本量可以将过拟合降至最小?
- 多大的样本量可以使模型拟合度达到较小的乐观程度?
作者给到了一些计算公式和依据,二分类这个其实就是从可信区间这里逆推样本量,但是默认阈值是0.5和可信区间小于5%。

还有很多公式,这里不一一展示了,这些计算公式相信大部分人不关心,我们只是关心怎么计算得到结果,咱们使用作者编写的R包来算一下,
作者分成了3种情况,第一种是:二分类逻辑回归的,第二种是生存分析,第三种,type参数,“c”指定了具有连续结果的预测模型的样本量计算,“b”指定具有二元结果的预测模型的样本量计算,“s”指定了具有生存期(事件发生时间)结果的预测模型的样本量计算
咱们先来展示二分类逻辑回归的
使用咱们的乳腺癌数据,公众号回复:乳腺癌,可以获得这个数据。
导入数据和R包
library(pmsampsize)
library(foreign)
library(scitb)
library(survival)
bc <- read.spss("E:/r/test/Breast cancer survival agec.sav",
use.value.labels=F, to.data.frame=T)
分类变量转成因子
bc$histgrad<-as.factor(bc$histgrad)
bc$er<-as.factor(bc$er)
bc$pr<-as.factor(bc$pr)
bc$ln_yesno<-as.factor(bc$ln_yesno)
建立逻辑回归模型
fit<-glm(status~ln_yesno+er+pr+histgrad,family = binomial(link = "logit"),data=bc)
先看下它的模型参数,大概就是下面这样的,parameters 协变量个数 , prevalence ,患病率 ,csrsquared:R方 ,type类型
pmsampsize(type = "b", csrsquared = csrsquared, parameters = 4, prevalence = prevalence)
其他都好说,就是csrsquared这个需要计算,作者提供了手动计算的公式,

不过咱们并不需要计算,我已经把公式编写金scitb包的Maddala.Cox.Snell函数了,咱们直接拿来用就可以了,下周scitb包更新的时候,咱们就可以直接用了
prevalence<-sum(bc[,"status"]==1)/1207
csrsquared<-Maddala.Cox.Snell(fit)
pmsampsize(type = "b", csrsquared = csrsquared, parameters = 4, prevalence = prevalence)

上图函数显示,需要195例样本数就可以了,接下来演示一下生存分析,和 逻辑回归差不多的,先生成一个模型,还是用乳腺癌这个数据
fit<-coxph(Surv(time,status)~er+histgrad+pr+age+ln_yesno,bc,x=TRUE,y=TRUE)
#rate 事件发生率 meanfup 平均随访时间 关注的事件时间点,例如2年的复发率
prevalence<-sum(bc[,"status"]==1)/1207
csrsquared<-Maddala.Cox.Snell(fit)
meanfup<-(sum(bc[,"time"])/1207)/12 #这里要转成年,不然会报错
pmsampsize(type = "s", csrsquared = csrsquared, parameters = 5, rate = prevalence,
timepoint = 60, meanfup = meanfup)
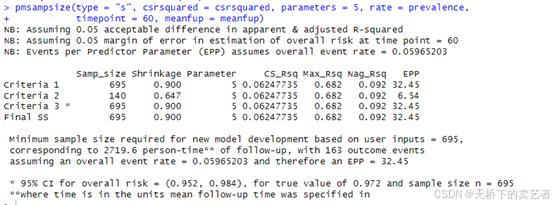
这里显示需要695例样本量,最后来做个连续变量的,使用的是我的臭氧数据
be <- read.spss("E:/r/test/ozone.sav",
use.value.labels=F, to.data.frame=T)
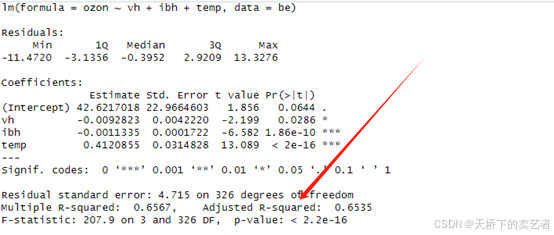
fit <- lm(ozon ~ vh +ibh+temp,data=be)
线性回归有点不一样,我们来看下公式,intercept 均值,sd标准差,rsquared这个R方要在模型里面找,我们看下模型,我们使用调整R方就行
summary(fit)
##intercept 均值 sd标准差
intercept<-mean(be$ozon)
sd<-sd(be$ozon)
pmsampsize(type = "c", rsquared = 0.6535 , parameters = 3, intercept = intercept, sd = sd)
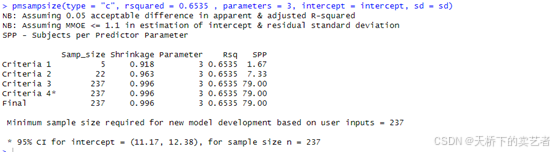
最后显示需要237例数据。不会的还可以看下面视频
跟着BMJ玩转预测模型系列(1)--计算开发临床预测模型所需的样本量


















 5635
5635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











