






 本文深入探讨了MATLAB中的各种数据类型,包括整型、浮点型、逻辑型、字符型、结构体、单元格数组及函数句柄,详细解析了每种类型的特点和应用场景,同时比较了不同数据类型在存储和访问效率上的差异。
本文深入探讨了MATLAB中的各种数据类型,包括整型、浮点型、逻辑型、字符型、结构体、单元格数组及函数句柄,详细解析了每种类型的特点和应用场景,同时比较了不同数据类型在存储和访问效率上的差异。
Matlab中有15种基本数据类型,主要是整型、浮点、逻辑、字符、日期和时间、结构数组、单元格数组以及函数句柄等。
文章目录
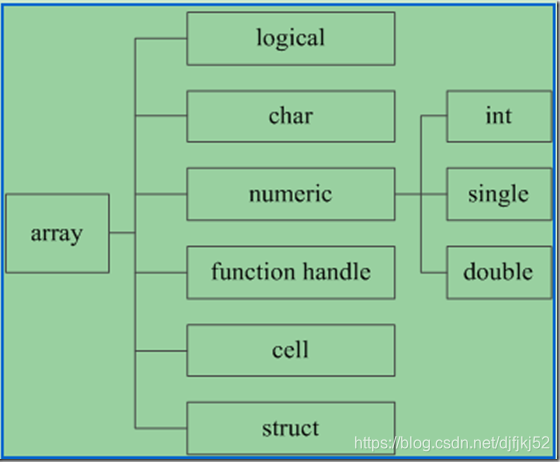
常用的MATLAB数据类型有逻辑型(logical)、字符型(char)、数值型(numeric)、函数句柄型(function handle)、元胞型(cell)和结构体型(struct)。其中数值型是我们最为常用的类型,包括整型(int)、单精度型(single)和双精度型(double)。而整形根据是否是有符号数以及位数的不同分为很多种,可参考下表。
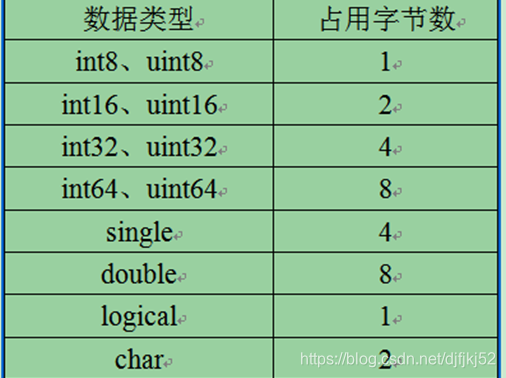
与C/C++不同的是,char类型在MATLAB中占用2个字节,除此之外,MATLAB中还有一类特殊的类型:复数(complex)。复数类型的变量,占用的内存为对应实部和虚部的内存和。
整型
整型:(int8;uint8;int16;uint16;int32;uint32;int64;uint64)通过intmax(class)和intmin(class)函数返回该类整型的最大值和最小值,例如 intmax(‘int8’)=127;
int8()有符号,占用1个字节。向无穷大方向取整:正数向正无穷大方向,负数向负无穷大方向取整。
int16():有符号,占用2个字节。向无穷大方向取整:正数向正无穷大方向,负数向负无穷大方向取整。
int32():有符号,占用4个字节。向无穷大方向取整:正数向正无穷大方向,负数向负无穷大方向取整。
int64():有符号,占用8个字节。向无穷大方向取整:正数向正无穷大方向,负数向负无穷大方向取整。
uint8():无符号,占用1个字节。向0方向取整。
uint16():无符号,占用2个字节。向0方向取整。
uint32():无符号,占用4个字节。向0方向取整。
uint64():无符号,占用8个字节。向0方向取整。
用whos观察变量的数据类型
浮点:(single;double)
浮点数:REALMAX(‘double’)和REALMAX(‘single’)分别返回双精度浮点和单精度浮点的最大值,REALMIN(‘double’)和REALMIN (‘single’)分别返回双精度浮点和单精度浮点的最小值。
Matlab 取整函数有: fix, floor, ceil, round.
fix 朝零方向取整, fix(-1.3)=-1; fix(1.3)=1;
floor 朝负无穷方向取整,floor(-1.3)=-2; floor(1.3)=1;
ceil 朝正无穷方向取整, ceil(-1.3)=-1; ceil(1.3)=2;
round 四舍五入到最近的整数, round(-1.3)=-1;round(-1.52)=-2;
1.000 处理成 1 用 floor round fix 都行 但如果是去掉尾巴的取整,用 floor
逻辑:(logical)
函数logical()将数值型数据转换成逻辑型数据。
下例是逻辑索引在矩阵操作中的应用,将5*5矩阵中大于0.5的元素设定为0: A = rand(5); A(A>0.5)=0;
字符: (char)
Matlab中的输入字符需使用单引号。字符串存储为字符数组,每个元素占用一个ASCII字符。如日期字符:DateString=’9/16/2001’实际上是一个1行9列向量。构成矩阵或向量的行字符串长度必须相同。
可以使用char函数构建字符数组,使用strcat函数连接字符。
例如,命令name = [‘abc’ ; ‘abcd’] 将触发错误警告,因为两个字符串的长度不等,
- 此时可以通过空字符凑齐如:name = ['abc ’ ; ‘abcd’],
- 更简单的办法是使用char函数:char(‘abc’,’abcd’),Matlab自动填充空字符以使长度相等,因此字符串矩阵的列纬总是等于最长字符串的字符数.
例如size(char(‘abc’,’abcd’)) 返回结果[2,4],即字符串’abc’实际存在的是’abc ’,此时如需提取矩阵中的某一字符元素,需要使用deblank函数移除空格如name =char(‘abc’,’abcd’); deblank(name(1,:))。
其他用法
此外,Matlab同时提供一种更灵活的单元格数组方法,使用函数cellstr可以将字符串数组转换为单元格数组:
->? 4
cdata=cellstr(data) length(cdata{1})
->?3
**常用的字符操作函数**
blanks(n) 返回n个空字符
deblank(s) 移除字符串尾部包含的空字符
(string) 将字符串作为命令执行
findstr(s1,s2) 搜索字符串
ischar(s) 判断是否字符串
isletter(s) 判断是否字母
lower(s) 转换小写
upper(s) 转换大写
strcmp(s1,s2) 比较字符串是否相同
strncmp(s1,s2,n) 比较字符串中的前n个字符是否相同
strrep(s1,s2,s3) 将s1中的字符s2替换为s3
int2str 将整数转换为字符串
lower 把字符串变成小写
mat2str 将数组转换为字符串
num2str 把数值转换为字符串
strcat 把多个串连接成长串
strcmp 比较字符串
strcmpi 比较字符串(忽略大小写)
strings MATLAB 中的字符串
strjust 字符串的对齐方式
strmatch 逐行搜索串
strnomp 比较字符串的前N 个字符
strncmpi 比较字符串的前N 个字符(忽略大小写)
strrep 用另一个串代替一个串中的子串
strtok 删除串中的指定子串
strvcat 创建字符串数组
str2mat 将字符串转换为含有空格的数组
str2num 将字符串转换为数值
5. 日期和时间
Matlab提供三种日期格式:日期字符串如’1996-10-02’,日期序列数如729300(0000年1月1日为1)以及日期向量如 1996 10 2 0 0 0,依次为年月日时分秒。
**常用的日期操作函数**
datestr(d,f) 将日期数字转换为字符串
datenum(str,f) 将字符串转换为日期数字
datevec(str) 日期字符串转换向量
weekday(d) 计算星期数
eomday(yr,mth) 计算指定月份最后一天
calendar(str) 返回日历矩阵
clock 当前日期和时间的日期向量
date 当前日期字符串
now 当前日期和时间的序列数
6. 结构
结构是包含已命名“数据容器”或字段的数组。结构中的字段可以包含任何数据。
构建结构数组
(1) 赋值方法
下面的赋值命令产生一个名为patient的结构数组,该数组包含三个字段:
patient.name = 'John Doe';
patient.billing = 127.00;
patient.test = [79 75 73; 180 178 177.5; 220 210 205];
%在命令区内输入patient可以查看结构信息:
name: 'John Doe'billing: 127test: [3x3 double]
%继续赋值可扩展该结构数组:
patient(2).name = 'Ann Lane';
patient(2).billing = 28.50;
patient(2).test = [68 70 68; 118 118 119; 172 170 169];
赋值后结构数组变为[1 2]。
(2) 构建结构数组:struct函数 函数基本形式为:
strArray = struct('field1',val1,'field2',val2, ...)
例如:
weather(1) = struct('temp', 72,'rainfall', 0.0);
weather(2) = struct('temp', 71,'rainfall', 0.1);
weather = repmat(struct('temp', 72, 'rainfall', 0.0), 1, 3);
weather = struct('temp', {68, 80, 72}, 'rainfall', {0.2, 0.4, 0.0});
(3) 访问结构数据
以下都是合法的结构数组访问命令:
mypatients = patient(1:2) 获取子结构数据
mypatients(1) 访问结构数据
patient(2).name 访问结构数据中的特定字段
patient(3).test(2,2) 访问结构数据中的特定字段(该字段为数组)
bills = [patient.billing] 访问多个结构
tests = {patient(1:2).test} 提取结构数据转换成单元格数组
使用结构字段的动态名称
通过structName.(expression_r_r_r)可以赋予结构字段名称并访问数据。例如字段名为expression_r_r_r、结构名为structName,访问其中第7行1至25列数据可以使用命令:structName.(expression_r_r_r)(7,1:25)。
例如,存在一个学生每周成绩数据结构数组,其数据通过以下方式建立:
testscores.wang.week(1:25) = ...
[95 89 76 82 79 92 94 92 89 81 75 93 ...
85 84 83 86 85 90 82 82 84 79 96 88 98];
testscores.chen.week(1:25) = ...
[87 80 91 84 99 87 93 87 97 87 82 89 ...
86 82 90 98 75 79 92 84 90 93 84 78 81];
即结构名为testscores,字段使用每个学生的名称命名,分别为wang和chen,每个学生下面包含名为week的成绩结构数组。
现计算给定结构名称、学生名称和起止周数的平均分数。
在命令窗口中输入 edit avgscore.m,输入以下代码后保存文件:
function avg = avgscore(struct, student, first, last)
avg = sum(struct.(student).week(first:last))/(last - first + 1);
在命名窗口中输入:avgscore(testscores, ‘chen’, 7, 22) 计算学生陈从第7周到第22周的平均分数。
(4) 添加和删除结构字段
命令[struct](index).(field)可添加或修改字段。
如patient(2).ssn = '000-00-0000' 在结构patient中添加一个名为ssn的字段。
删除字段使用rmfield函数,如patient2 = rmfield(patient, 'name') 删除name字段并产生新的结构。
单元格数组:(cell)
单元格数组提供了不同类型数据的存储机制,可以储存任意类型和任意纬度的数组。
访问单元格数组的规则和其他数组相同,区别在于需要使用花括号{}访问,例如A{2,5}访问单元格数组A中的第2行第5列单元格。
(1) 构建单元格数组:赋值方法
使用花括号标识可直接创建单元格数组,如:
A(1,1) = {[1 4 3; 0 5 8; 7 2 9]}; A(1,2) = {'abcd'}; A(2,1) = {3+7i}; A(2,2) = {-pi:pi/10:pi};
上述命令创建2*2的单元格数组A。继续添加单元格元素直接使用赋值如A(2,3)={5}即可,注意需使用花括号标识。简化的方法是结合使用花括号{单元格数组}和方括号[]创建,
如C = {[1 2], [3 4]; [5 6], [7 8]};
(2)构建单元格数组:函数方法Cell函数。
如:B = cell(2, 3);B(1,3) = {1:3};
(3)访问数据
通过索引可直接访问单元格数组中的数据元素,例如:
N{1,1} = [1 2; 4 5]; N{1,2} = 'Name'; N{2,1} = 2-4i; N{2,2} = 7; c = N{1,2} d = N{1,1}(2,2)
函数句柄
函数句柄是用于间接调用一个函数的Matlab值或数据类型。在调用其它函数时可以传递函数句柄,也可在数据结构中保存函数句柄备用。
通过命令形式 fhandle = @functionname 可以创建函数句柄
例如 trigFun=@sin,或匿名函数sqr = @(x) x.^2;。
使用句柄调用函数的形式是
fhandle(arg1, arg2, ..., argn) 或 fhandle()(无参数)。
如:trigFun(1)。
例:
function x = plotFHandle(fhandle, data)
plot(data, fhandle(data))
使用
plotFHandle(@sin, -pi:0.01:pi)
结构数组的创建
MATLAB提供了两种定义结构的方式:直接应用和使用struct函数。
a) 使用直接引用方式定义结构
与建立数值型数组一样,建立新struct对象不需要事先申明,可以直接引用,而且可以动态扩充。比如建立一个复数变量x:
x.real = 0; % 创建字段名为real,并为该字段赋值为0
x.imag = 0 % 为x创建一个新的字段imag,并为该字段赋值为0
x =
real: 0
imag: 0
x(2).real = 0; % 将x扩充为1×2的结构数组
x(2).imag = 0;
x(1) % 查看结构数组的第一个元素的各个字段的内容
ans =
real: 0
imag: 0
scale: 0
x(2) % 查看结构数组的第二个元素的各个字段的内容,注意没有赋值的字段为空
ans =
real: 0
imag: 0
scale: []
应该注意的是,x的real、imag、scale字段不一定是单个数据元素,它们可以是任意数据类型,可以是向量、数组、矩阵甚至是其他结构变量或元胞数组,而且不同字段之间其数据类型不需要相同。
b) 使用struct函数创建结构
使用struct函数也可以创建结构,该函数产生或把其他形式的数据转换为结构数组。
struct的使用格式为:
s = sturct('field1',values1,'field2',values2,…);
该函数将生成一个具有指定字段名和相应数据的结构数组,其包含的数据values1、values2等必须为具有相同维数的数据,数据的存放位置与其他结构位置一一对应的。
对于struct的赋值用到了元胞数组。数组values1、values2等可以是元胞数组、标量元胞单元或者单个数值。每个values的数据被赋值给相应的field字段。
Matlab下同样功能实现的情况下,应该优先选择cell还是struct?
从内存分配上来讲,在赋值使用之前结构体可以精确地分配内存。如果你所需要使用的数据类型是固定的,并且向量或者矩阵的维数的固定的,那么推荐使用struct。在matlab里面cell的适用性非常灵活,cell数组的每个元素的在使用过程中它的数据类型,数据尺寸都可以随意改变,但是这么方便这么好用的东西肯定也是要付出代价的。首先cell数组因为其强大的数据灵活性所以它的内存分配是动态的,这一定程度上会影响程序的执行效率。其次因为它赋值的极大灵活性,就算代码里面有错误例如不同数据类型之间的变量赋值,或者赋值过程中超出矩阵维度,matlab并不会报错,这样在debug方面就造成不便(不过这类错误比较低级,稍微小心一点就不会有)
单元数组的创建和操作
单元数组中的每一个元素称为单元(cell),单元中可以包含任何类型的Matlab数据,即可以是数组,字符,符号对象,单元数组或结构体等。理论上,单元数组可以创建任意数的单元数组,大多数情况下,为简单起见,创建简单的单元数组(如一维单元数组)。单元数组的创建方法可以分为两种,通过赋值语句直接创建;或通过cell函数首先为单元数组分配内存空间,然后再对每个单元赋值。
直接通过赋值语句创建单元数组时,可以采用两种方法来进行,即按单元索引法和内容索引法。按单元索引法赋值时,采用标准数组的赋值方法,赋值时赋给单元的数值通过花括号({ })将单元内容括起来。按内容索引法赋值时,将花括号写在等号左边,即放在单元数组名称后。下面通过例子说明这两种赋值方法。
>>clear A % 保证赋值的单元数组名称不重名
>>%按单元索引法赋值
>>A(1,1)={[1 3 5;2 4 6; 1 4 7]};
>>A(1,2)={3+5i};
>>A(2,1)={'Tsinghua in Beijing'};
>>A(2,2)={0:pi/5:pi};
>>A
A= [3x3double] [3.0000+5.0000i]
'Tsinghua in Beijing' [1x6 double]
>> 按内容索引法赋值
>>B{1,1}=[1 2 3;4 5 6;7 8 9];
>>B{1,2}=2+3i;
>>B{2,1}='Beijing Univ';
>>B{2,2}=1:2:13;
>>B
B= [3x3double] [2.0000+3.0000i]
'Beijing Univ' [1x7double]
>>D=cell(2,3)
D=
[] [] []
[] [] []
>>D{1,1}=randperm(5)
D=
[1x5 double] [] []
[] [] []
效率比较
不同的数据类型在存储和访问效率上各不相同,选择恰当的数据类型不仅能够节省内存空间,还能使MATLAB程序运行更快。
头部(header)
当定义一个矩阵时,MATLAB除了会根据矩阵大小分配内存空间外,还会开辟另一块内存空间,存储该矩阵的另外一些信息(比如数据类型和维数),这些信息被称为矩阵的头部(header)。对于大部分矩阵,存储header所需的内存空间非常小,可以忽略不计。所以在设计程序时,推荐使每个矩阵尽量存储多一些的数据,便可减少矩阵的个数,从而减小存储header所需的内存空间。
对于结构体,MATLAB不仅会为结构体本身创建一个header,还会为结构体中的每个域创建header。
结构体的header
例如,若需要存储3个100´50大小的数据,可以创建一个结构体S,其中包含3个矩阵,每个矩阵的大小为100´50。
S1.A(1:100,1:50)
S1.B(1:100,1:50)
S1.C(1:100,1:50)
则每个field需要一个header,每个field中的矩阵需要一个header,整个总的结构体S还需要一个header,一共需要7个header。
cell 的header
cell型矩阵不需要连续的内存空间进行存储,所以与结构体类似,每个cell单元也需要一个header,即使是空的cell单元,也需要额外的内存空间存储header。我们可以创建一个空cell型变量,以计算出MATLAB需要多大的存储空间来存储header,如下
A = {[]}; % Empty cell array
whos A
B = {[], []}; % Empty cell array
whos B
运行结果如下:
Name Size Bytes Class Attributes
A 1x1 112 cell
Name Size Bytes Class Attributes
B 1x2 224 cell
可以看到,MATLAB需要112个字节存储cell型矩阵中每个cell的header(实际上,112个字节的header是对于64位操作系统而言的,在32位操作系统下,只需要60个字节)。除了消耗额外的存储空间,cell型变量的访问速度也是很慢的。
对比double、cell和struct的访问效率
AccessCnt = 1e6;
a = magic(2);
b{1} = magic(2);
c.data = magic(2);
tic;
for i = 1 : AccessCnt
a;
end
tElapsed1 = toc;
disp(['访问double型变量', num2str(AccessCnt, '%.1e'), '次,共耗时', num2str(tElapsed1), '秒。']);
tic;
for i = 1 : AccessCnt
b{1};
end
tElapsed2 = toc;
disp(['访问cell型变量', num2str(AccessCnt, '%.1e'), '次,共耗时', num2str(tElapsed2), '秒。']);
tic;
for i = 1 : AccessCnt
c.data;
end
tElapsed3 = toc;
disp(['访问struct型变量', num2str(AccessCnt, '%.1e'), '次,共耗时', num2str(tElapsed3), '秒。']);
运行结果如下:
访问double型变量1.0e+06次,共耗时0.12513秒。
访问cell型变量1.0e+06次,共耗时0.5391秒。
访问struct型变量1.0e+06次,共耗时0.18014秒。
可以看到,访问cell类型的变量确实比较耗时,而double型和struct型的耗时比较接近。综合内存消耗和访问速度,在设计程序时应尽量避免使用cell型数组。
9. 图像数据类型
Matlab中的图像数据类型转换
MATLAB中读入图像的数据类型是uint8,而在矩阵中使用的数据类型是double
因此 I2=im2double(I1) :把图像数组I1转换成double精度类型;
如果不转换,在对uint8进行加减时会产生溢出,可能提示的错误为:
Function '*' is not defined for values of class 'uint8'。
数据类型转换
%数据类型转换,如C语言中的强制类型转换相似
y=9;
z=double(y);
一、数字转字符
- char()
注意,char()使用的是ASCII编码。
- num2str(k)
将数字转换成字符串 - int2str(k)
将整数型转换为字符串 - mat2str(k)
将矩阵转换为字符串,供eval使用 - str2double(S)
将字符串数组转化为数值数组 - sprintf
将数据格式化为字符串
str = sprintf(formatSpec,A1,…,An)
[str,errmsg] = sprintf(formatSpec,A1,…,An)
formatSpec 部分与fprintf一致。
fprintf与sprintf有个使用的区别需要注意
fprintf 会直接显示出来,而sprintf是形成字符串,需要用disp输出到屏幕。
fprintf需要使用‘\n’来字符串输出的结束。sprintf不需要。
二、字符转数字
- double
-
str2num
-
str2double
三、数字格式间转换
logical, char,int8,uint8,int16,uint16,int32,uint32,int64,uint64,single,double
想要转化成特定类型,就用该类型作为函数.比如说double(X) int64(X)
- base2dec X进制串转换为十进制整数
- bin2dec 二进制串转换为十进制整数
- dec2base 十进制整数转换为X 进制串
- dec2bin 十进制整数转换为二进制串
- dec2hex 十进制整数转换为16 进制串
- findstr 在一个串中寻找一个子串
- hex2dec 16进制串转换为十进制整数
- hex2num 16进制串转换为浮点数
四、图像数据类型转换函数
默认情况下,matlab将图像中的数据存储为double型,即64位浮点数;matlab还支持无符号整型(uint8和uint16);uint型的优势在于节省空间,涉及运算时要转换成double型。
- im2double()
将图像数组转换成double精度类型
- im2uint8()
将图像数组转换成unit8类型
在数据类型转换时候uint8和im2uint8的区别,uint8的操作仅仅是将一个double类型的小数点后面的部分去掉;
但是im2uint8是将输入中所有小于0的数设置为0,而将输入中所有大于1的数值设置为255,再将所有其他值乘以255。
- im2uint16()
将图像数组转换成unit16类型
eval执行代码
- 执行字符串
eval
eval(expression)
[output1,…,outputN] = eval(expression)
eval([‘xxxxx’,variable,‘xxxxxxxx;’])
eval(strcat(‘xxxxx’,variable,‘xxxxxxxx;’))
- 执行函数
feval
数据结构的查找效率
数据结构包括数组、链表、栈、二叉树、哈希表等等
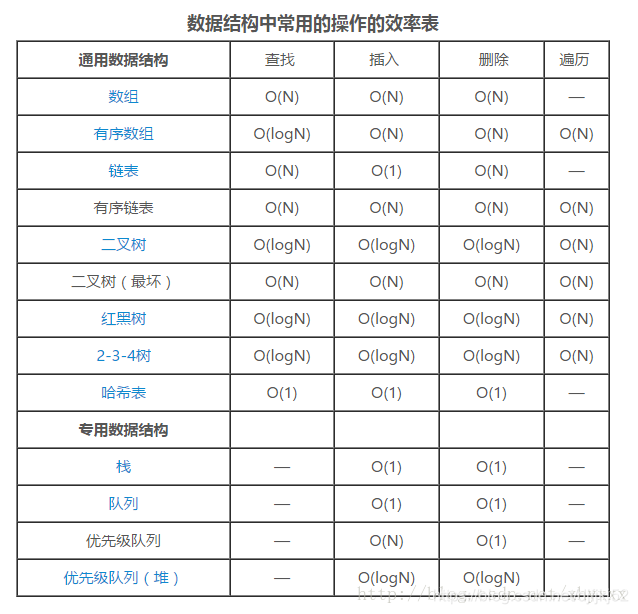

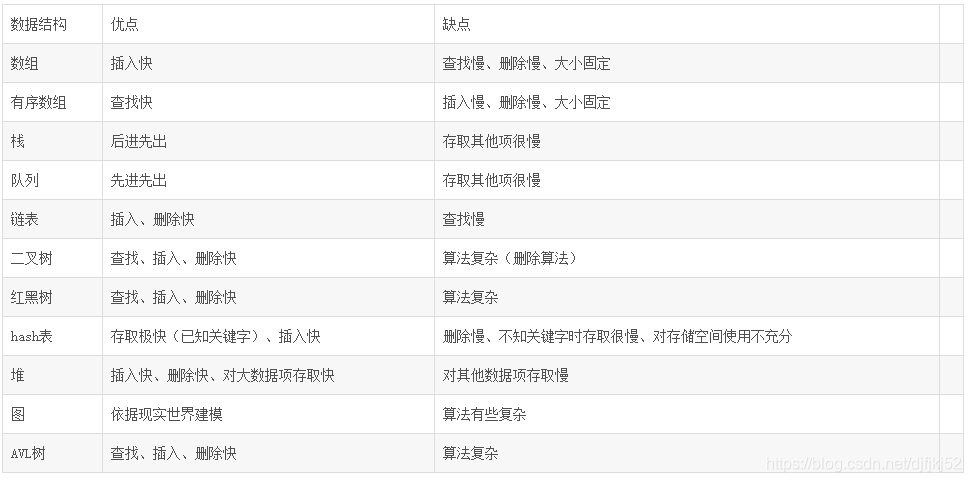
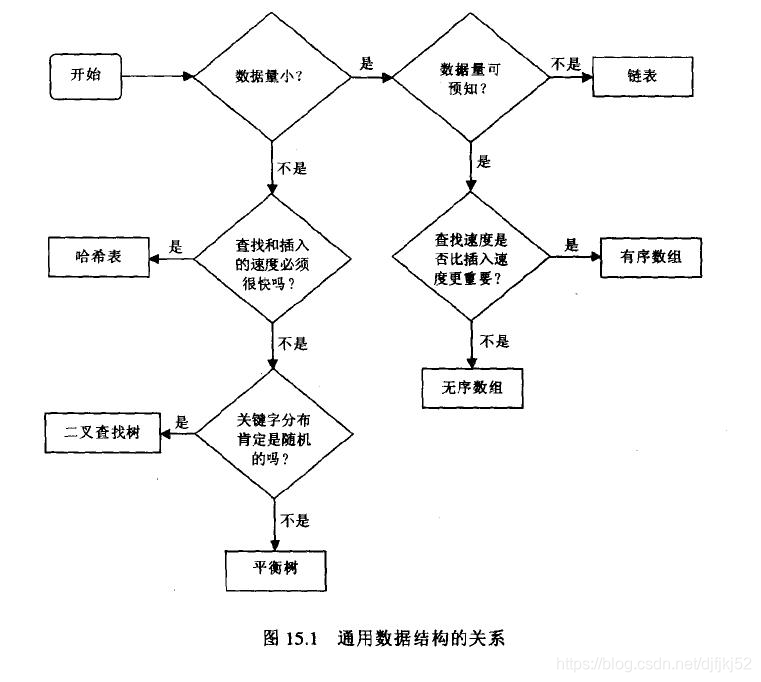
数组在下列情况下很有用:
1、数据量较小
2、数据量的大小事先可预测
3、如果存储空间足够大的话,可以放松第二条,创建一个足够大的数组来应付所有可以预见的数据输入。
如果插入速度很重要的话,使用无序数组。如果查找速度很重要的话,使用有序数组,并用二分查找。数组元素的删除总是很慢,这是由于为了填充空出来的单元,平均半数以上的数组元素要被移动。在有序数组中的遍历是很快的,而在无序的数组不支持这种功能。
如果需要存储的数据量不能预知或者需要频繁地插入删除数据元素时,考虑使用链表。当有新的元素加入时,链表就开辟新的所需要的空间,所以它甚至可以占满全部可用内存;在删除过程中没有必要像数组那样添补“空洞”。
常见的数据结构有:array,list,stack,deque,binaryTree,hashMap,heap,对于C++而言还有最常用的vector
接着分析每一种的特点:
[1] array
内存分配:在内存中分配一段连续的空间;
特点:需要再定义时就知道分配空间的大小;
使用:用于预先就已知需要的最大储存空间的情况;
[2] vector
内存分配:在内存中分配一段连续的空间;
实现:内部实际通过管理一个数组指针实现;
特点:插入的元素如果超出分配的内存空间,会自动划分一段更大的内存空间,将数据拷贝过去后,释放原空间;
使用:对于C++而言采用vector的情况比较多。对于需要随机访问元素,预先不知道需要分配的内存空间大小情况。但是vector在中间和头部插入比较麻烦,插入时间复杂度是O(N);因此vector适用于只在尾部插入和删除的情况;
[3] list
内存分配:随机分配;
实现:通过一个结构体保存指向前一个元素和后一个节点的指针(双向链表);
特点:在任何地方插入都很方便,但是随机访问时间复杂度是O(N);
[4] stack
实现:通过一个表实现很方便,也可以通过数组实现;
特点:后进先出,在编译器中得到广泛应用,例如编译器实现的函数堆栈;
[5] deque
实现:通过一个数组实现;
特点:先进先出,典型应用是多个对象需要抢占同一个资源时;
[6] binaryTree
内存分配:随机分配
实现:保存左右儿子的指针
特点:插入和访问的时间复杂度都是O(logN),内部操作函数的实现很多靠递归来实现。每个节点儿子的个数可以扩展。在操作系统的编译器中的得到广泛应用;
[7] hashMap
实现:分离链接法通过数组和链表实现,开放地址法通过数组实现;
特点:支持随机访问,可以保存到每个数据的信息,可以访问指定的元素。因此应用于需要知道数据信息的情况,比如实现一个词典,就可以将单词存入一个hash表中;
[8] heap
实现:通过数组实现一个完全二叉树,称为堆
矩阵的存储顺序:按行优先存储 vs. 按列优先存储
涉及到在计算机中使用矩阵时,首先会碰到存储矩阵的问题。因为计算机存储空间是先后有序的,如何存储A[mn]的mn个元素是个问题,一般有两种:按行优先存储和按列优先存储。
row-major:存成a11,a12,…,amn的顺序。
PASCAL, C/C++,, Python语言中,数组按行优先顺序存储。
行优先顺序推广到多维数组,可规定为先排最右的下标。
column-major:存成a11,a21,…,amn的顺序。
FORTRAN语言,Matlab中,数组按列优先顺序存储。
列优先顺序推广到多维数组,可规定为先排最左的下标。
For example:
序列 A = [1,2,3,4],用Matlab 和 Python 分别reshape为2*2大小:
Matlab中 reshape(A, [2 2]), 得到 [[1 3] [2 4]]
Python中 A.reshape(2,2), 得到[[1 2] [3 4]]
参考
链接:https://www.jianshu.com/p/9570f76f3b4d
https://blog.csdn.net/m0_37407756/article/details/70045209
链接:https://www.zhihu.com/question/49877600/answer/118223217
链接:https://blog.csdn.net/qq_32865355/article/details/80232982
http://blog.chinaaet.com/beautyofcomm/p/5100018519
https://blog.csdn.net/xhyxxx/article/details/65937427
链接:https://blog.csdn.net/jirryzhang/article/details/79199958
http://en.wikipedia.org/wiki/Row-major_order
http://www.cnblogs.com/soroman/archive/2008/03/21/1115571.html
https://blog.csdn.net/duanlangzhuifeng/article/details/11727513

















 10
10

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









