







修正20240422,计算HWC格式排列,那么内存位置计算公式错误
OpenCV读取RGB图像
在OpenCV中,读取的图片默认是HWC格式,即按照高度、宽度和通道数的顺序排列图像尺寸的格式。我们看最后一个维度是C,因此最小颗粒度是C。
例如,一张形状为256×256×3的RGB图像,在OpenCV中读取后的格式为[256, 256, 3],其中最后一个维度表示图像的通道数。在OpenCV中,可以通过cv2.imread()函数读取图片,该函数的返回值是一个NumPy数组,表示读取的图像像素值。
需要注意的是,OpenCV读取的图像像素值是按照BGR顺序排列的,而不是RGB顺序。因此,如果需要将OpenCV读取的图像转换为RGB顺序,可以使用cv2.cvtColor()函数进行转换。
OpenCV读取一张RGB图像时,它会将像素数据按照BGR的顺序排列,对于一张3×4的RGB图像,其像素信息在内存中的排列方式如下所示:
[
[[B G R] [B G R] [B G R][B G R],
[[B G R] [B G R] [B G R][B G R],
[[B G R] [B G R] [B G R][B G R], ]
可知,每一个像素点都由三个值组成,分别表示该像素点在蓝色、绿色和红色通道中的颜色值,而整张图像的像素数据则按照BGR的顺序排列。
在HWC格式中,最小的像素坐标是(0,0),如果像素点的坐标为(i, j),且其在第k个通道中的值需要被访问,那么其在内存中的存储位置可以表示为:
o
f
f
s
e
t
=
i
∗
W
∗
C
+
j
∗
C
+
k
offset = i * W * C + j * C + k
offset=i∗W∗C+j∗C+k
也可以写成
o
f
f
s
e
t
=
(
i
∗
W
+
j
)
∗
C
+
k
offset = (i * W + j) * C + k
offset=(i∗W+j)∗C+k
其中:
- i 表示像素点的高度索引(在0到H-1之间,H是图像的高度)。
- j 表示像素点的宽度索引(在0到W-1之间,W是图像的宽度)。
- k 表示通道索引(在0到C-1之间,C是通道数,对于RGB图像,C通常是3)。
- W 表示图像的宽度。
- C 表示通道数。
所以,对于 按照 BGR 排列的图像中的任意一个像素点(i, j),如果你想要获取该像素点的蓝色通道的值,你需要计算该像素点在内存中的偏移量,然后加上0,如果你想要获取绿色通道的值,则加上1,对于红色通道则加上2。
首先计算了像素点(i, j)在整个图像中的线性位置(i * W + j),然后乘以通道数(C)以找到该像素点第一个通道值的起始位置。最后,加上通道索引(k)来得到特定通道的内存偏移量。
与CHW格式相比,HWC格式更直观,因为它首先按照图像的二维空间布局(高度和宽度)来排列数据,然后再按照通道来组织。这也是许多图像处理库(如OpenCV)和某些深度学习框架中默认的图像数据格式。
在PyTorch中读取RGB图像
特别是使用PyTorch等框架时,数据可能以CHW(通道、高度、宽度)或NHWC(批量大小、高度、宽度、通道)的格式存储,但这通常是在特定的库或框架内部为了计算效率而进行的优化,而不是图像在磁盘上的存储格式或常规处理时的格式。因此,在计算偏移量时,需要根据实际数据的布局来确定正确的公式。像素值通常采用浮点数的形式表示,并且像素值的范围通常是[0, 1]或[-1, 1]。
一般pytorch中的tensor,即网络的输入,要转换为plane的格式,即rrrrggggbbbb。
[
[[R R R R] [R R R R] [R R R R]],
[[G G G G] [G G G G] [G G G G]],
[[B B B B] [B B B B] [B B B B]], ]
在PyTorch中,模型接收的RGB图像通常采用CHW格式,即按照通道数、高度和宽度的顺序排列像素信息的方式。
在这种格式下,对于一个特定的像素点(i, j)在通道k中,其在内存中的存储位置(或偏移量)可以通过以下公式计算:
offset = k * H * W + i * W + j
其中:
k是通道索引(在0到C-1之间,C是通道数)。i是高度索引(在0到H-1之间,H是图像的高度)。j是宽度索引(在0到W-1之间,W是图像的宽度)。H是图像的高度。W是图像的宽度。
这个公式首先计算了通道k在整个图像中的起始位置(k * H * W),然后加上当前行在通道k中的起始位置(i * W),最后加上当前像素点在当前行中的位置(j)。这样就得到了像素点(i, j)在通道k中的内存偏移量。
请注意,这个公式假设图像数据是紧密排列的,没有额外的填充或间隙。此外,这里计算的是以字节为单位的偏移量,实际上每个像素点可能由多个字节组成(例如,对于浮点数表示的图像),但这不影响偏移量的计算,只需在访问数据时考虑每个像素点的大小即可。
实验
1 生成一张图片
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
# 用随机数模拟一张图像
image = np.random.randint(256, size=60)
image = image.reshape((5,4,3))
image_hwc = np.uint8(image)
# 展示图像
image_show = Image.fromarray(image_hwc)
plt.imshow(image_show)
plt.show()
# 打印图像像素值,[h, w, c]格式
print(image_hwc)
# 打印像素值,[c, h, w]格式
image_chw = np.transpose(image_hwc, (2,0,1))
print(image_chw)
以上代码模拟生成的图像如下图所示,图中有5行4列总共20个像素。
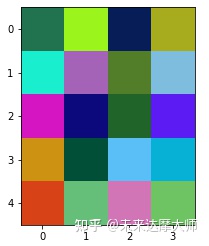
上图的所有像素及其像素值如下图所示,[h, w, c]格式。可以看出,最里层的括号内为单个像素在三个通道上的像素值。
我们看这种维度的一个方法是:看最后一个维度的含义,[h,w,c]最后一个维度是3,因此意味着最小的颗粒度维度是3。

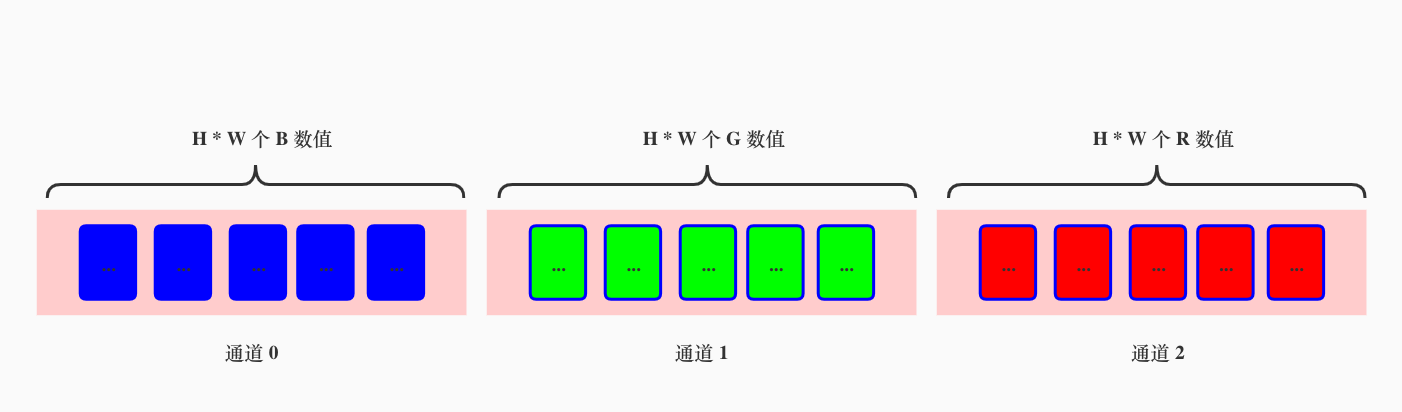
如果以[c, h, w]格式表示的话,应该是下图这样的:
看最后一个维度的含义,[c,h,w]最后一个维度是w(我们实验中是4),因此意味着最小的颗粒度维度是4。
我们想象,一束光通过三棱镜后分解为彩色光,我们取出其中一个频段的数据,把这个频段的数据进行二维排列,就是该通道的情况。

2 CHW和HWC的本质
本质是一个规范,排列多维度的数据的规范,换句话说,就是定义了一个数据类型的结构体。
转换过程
- 其实数据可以看做是一堆无序的数据,轴的存在让这些数据按照一定层级及次序排布
- 转换前的数据是这样排布的,先按照图像高分成3堆,对这3堆的每一堆按照图像图像宽分2堆,分好的2堆分别按照通道数分成3堆
- 转换后的数据排布顺序变了,它先按照通道数分成3堆,分好的3堆各自按照图像高分成3堆,再按照图像宽分成2堆。
参考
https://blog.csdn.net/hh1357102/article/details/130622666
https://zhuanlan.zhihu.com/p/476310426















 1873
1873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











