







论文阅读:(TPVFormer)Tri-Perspective View for Vision-Based 3D Semantic Occupancy Prediction
Abstract
以视觉为中心的自动驾驶感知的现代方法广泛采用鸟瞰图(BEV)表示来描述3D场景。尽管它的效率比体素表示更好,但它很难用单个平面描述场景的细粒度3D结构。为了解决这个问题,我们提出了一种三透视图(TPV)表示,它伴随着BEV和两个额外的垂直平面。我们通过总和其在三个平面上的投影特征来对3D空间中的每个点进行建模。为了将图像特征提升到3D TPV空间,我们进一步提出了一种基于Transformer的TPV编码器(TPVFormer)来有效地获取TPV特征。我们采用注意力机制来聚集与每个TPV平面中的每个查询对应的图像特征。实验表明,我们用稀疏监督训练的模型可以有效地预测所有体素的语义占用。我们首次证明,仅使用相机输入即可实现与基于LiDAR的方法相当的性能。代码:https://github.com/wzzheng/TPVFormer.
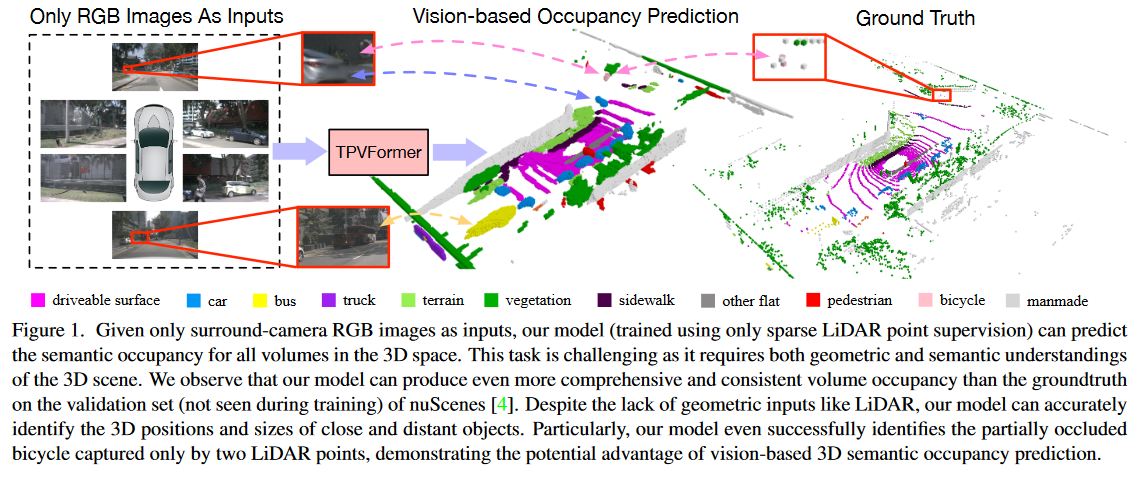
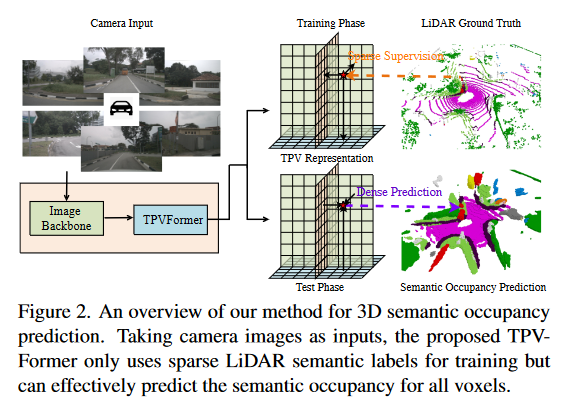
为了展示TPV的优越性,我们制定了一个实用而具有挑战性的基于视觉的3D语义占有率预测任务,其中只提供稀疏的激光雷达语义标签用于训练,测试需要所有体素的预测,如图2所示。然而,由于在这种具有挑战性的环境下没有提供基准,我们只对两个代理任务进行了定性分析,但提供了定量评估:nuScenes[4]上的激光雷达分割(稀疏训练,稀疏测试)和SemantiKITTI[2]上的3D语义场景完成(密集训练,密集测试)。对于这两个任务,我们只使用RGB图像作为输入。对于LiDAR分割,我们的模型只使用点查询的LiDAR数据来计算评估指标。可视化结果表明,TPVFormer在训练过程中只需要稀疏点监督就能产生一致的语义体素占用预测,如图1所示。我们还首次证明了我们的基于视觉的方法在LiDAR分割上取得了与基于LiDAR的方法相当的性能。
3. Proposed Approach
3.1. Generalizing BEV to TPV
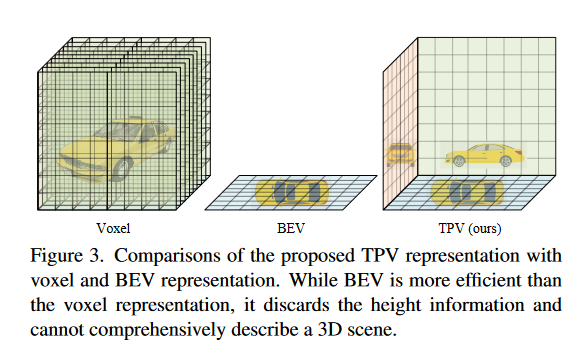
自动驾驶感知通常需要复杂3D场景的富有表现力和高效的表示,其中体素和鸟瞰图(BEV)表示是两种最广泛采用的框架。体素表示[26,43,48]描述了具有密集立方体特征的3D场景 V ∈ R H × W × D × C \mathbf{V}\in\mathbb{R}^{H\times W\times D\times C} V∈RH×W×D×C,其中 H H H、 W W W、 D D D 是体素空间的空间分辨率, C C C 表示特征维度。现实世界中位于 ( x , y , z ) (x, y, z) (x,y,z) 处的随机点通过一一对应 P v o x \mathcal{P}_{vox} Pvox 映射到其体素坐标 ( h , w , d ) (h, w, d) (h,w,d),所得特征 f x , y , z \mathrm{f}_{x,y, z} fx,y,z 通过在 ( h , w , d ) (h, w, d) (h,w,d) 处对 V \mathrm{V} V 进行采样来获得:
f x , y , z = v h , w , d = S ( V , ( h , w , d ) ) , = S ( V , P v o x ( x , y , z ) ) , \begin{aligned}\mathrm{f}_{x,y,z}=\mathrm{v}_{h,w,d}&=\mathcal{S}(\mathrm{V},(h,w,d)),\\&=\mathcal{S}(\mathrm{V},\mathcal{P}_{vox}(x,y,z)),\end{aligned} fx,y,z=vh,w,d=S(V,(h,w,d)),=S(V,Pvox(x,y,z)),
其中 S ( a r g 1 , a r g 2 ) \mathcal{S}(arg1,arg2) S(arg1,arg2) 表示在 a r g 2 arg2 arg2 中指定的位置处采样 a r g 1 arg1 arg1, v h , w , d \mathbf{v}_{h,w,d} vh,w,d是采样的体素特征。请注意,如果体素空间与现实世界对齐,投影函数 P v o x \mathcal{P}_{vox} Pv
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 648
648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









