






目录(方便查找自己所需)
1、YOLOv10介绍
YOLOv10是清华大学的研究人员在Ultralytics Python包的基础上,引入了一种新的实时目标检测方法,解决了YOLO 以前版本在后处理和模型架构方面的不足。通过消除非最大抑制(NMS)和优化各种模型组件,YOLOv10 在显著降低计算开销的同时实现了最先进的性能。大量实验证明,YOLOv10 在多个模型尺度上实现了卓越的精度-延迟权衡。
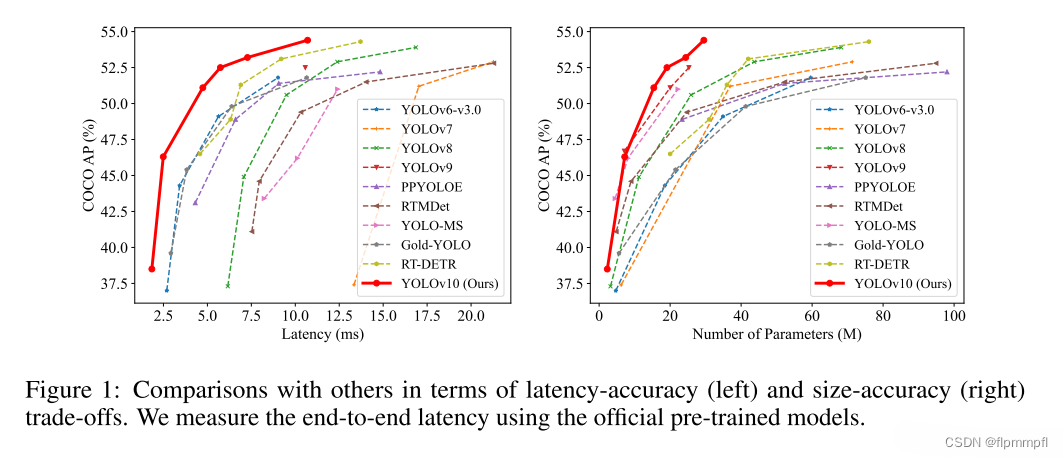
2、yolov10模型图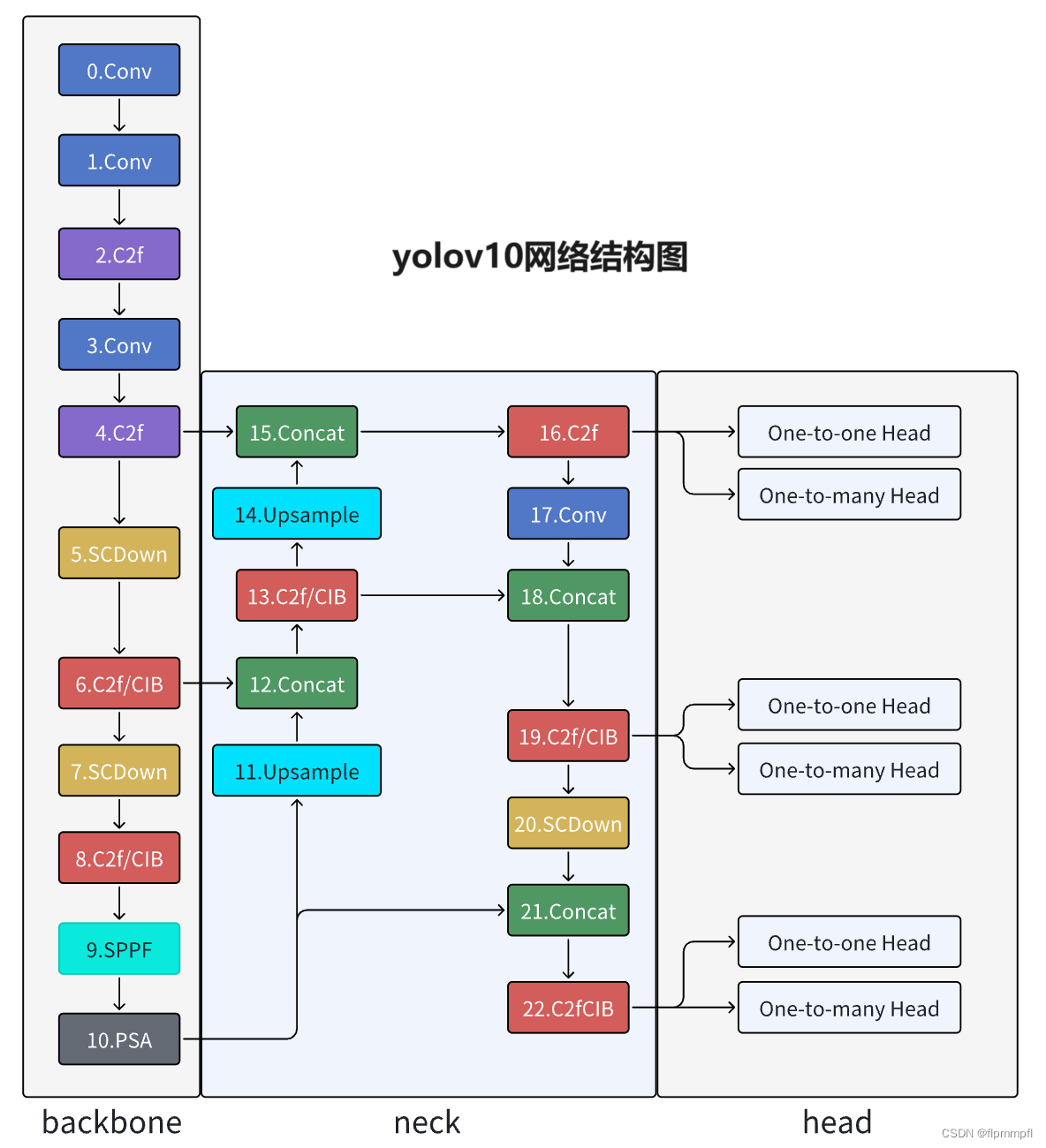
3、前提所需
anaconda3、pycharm下载完成(最好不要最新版本,也不要太旧,本人使用2021.3)
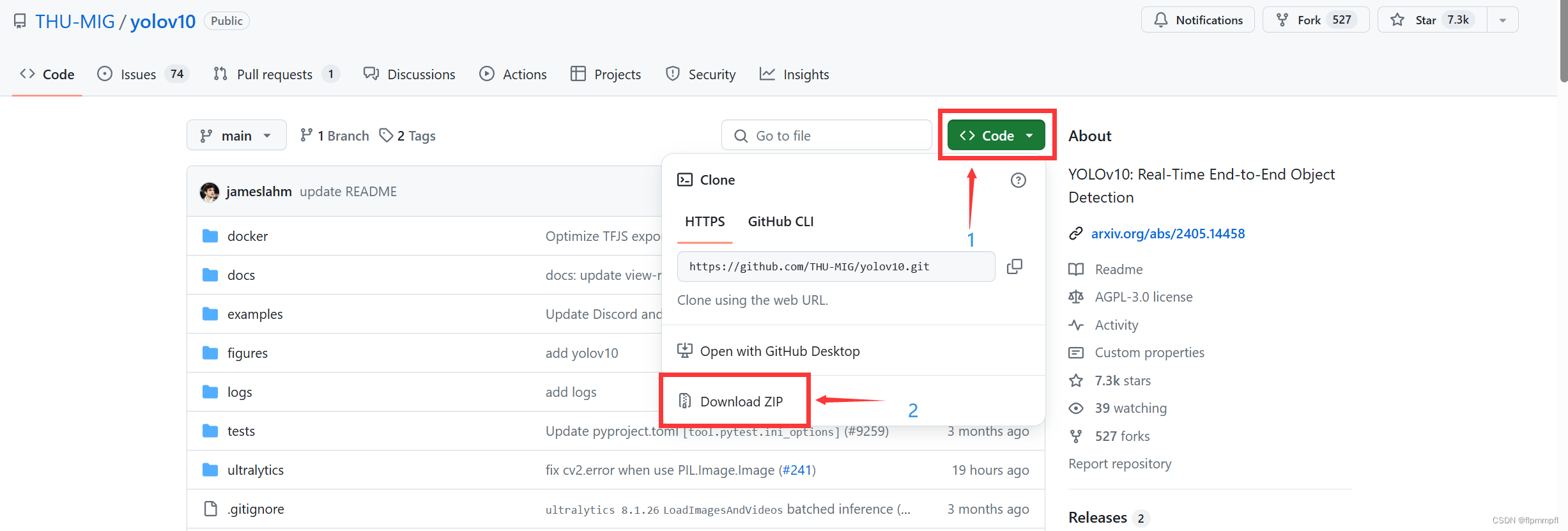
4、yolov10模型、权重下载
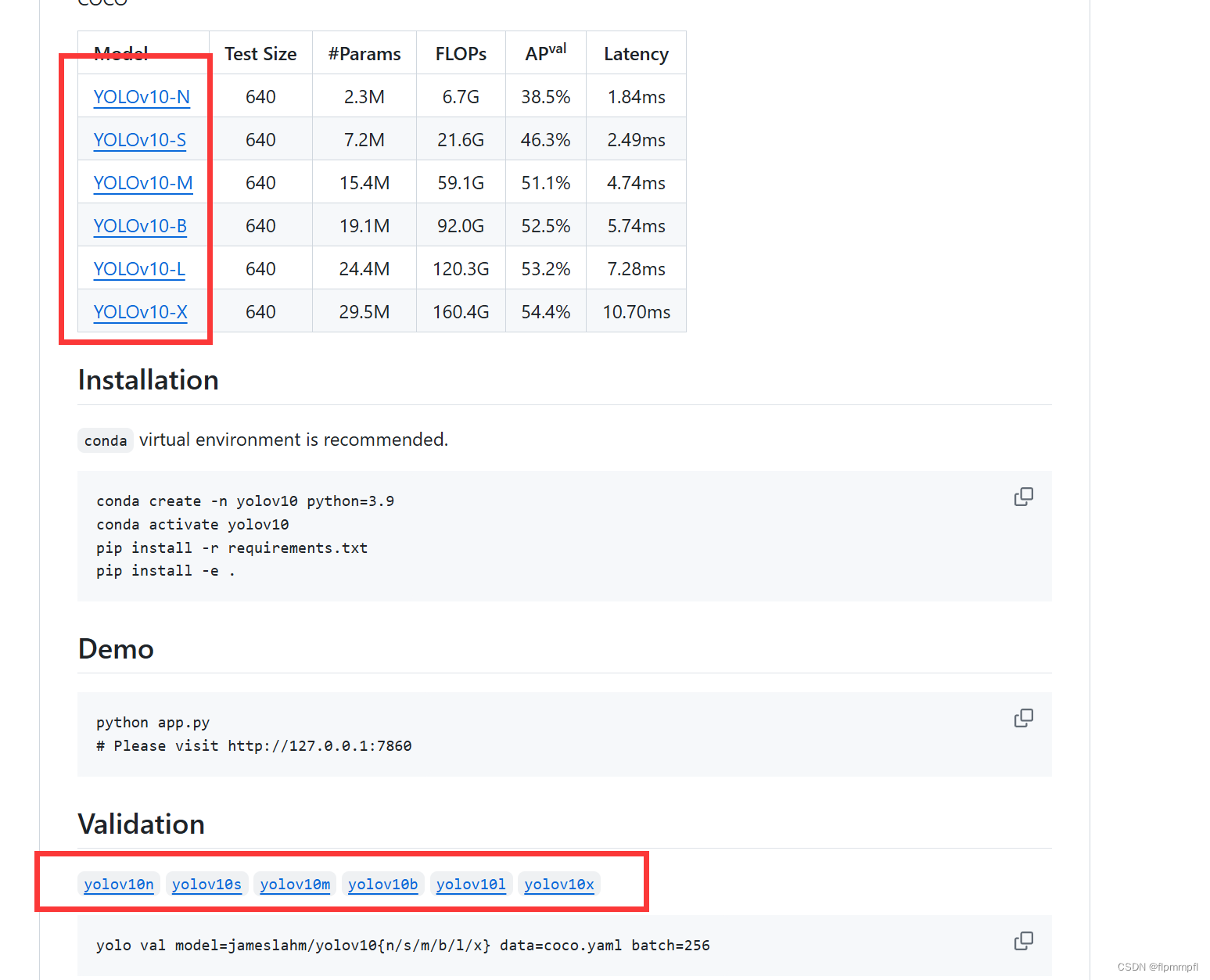
1.模型下载: github模型代码下载
2.模型权重下载(非必须):yolov10模型下载相同位置,往下翻,下载所需的
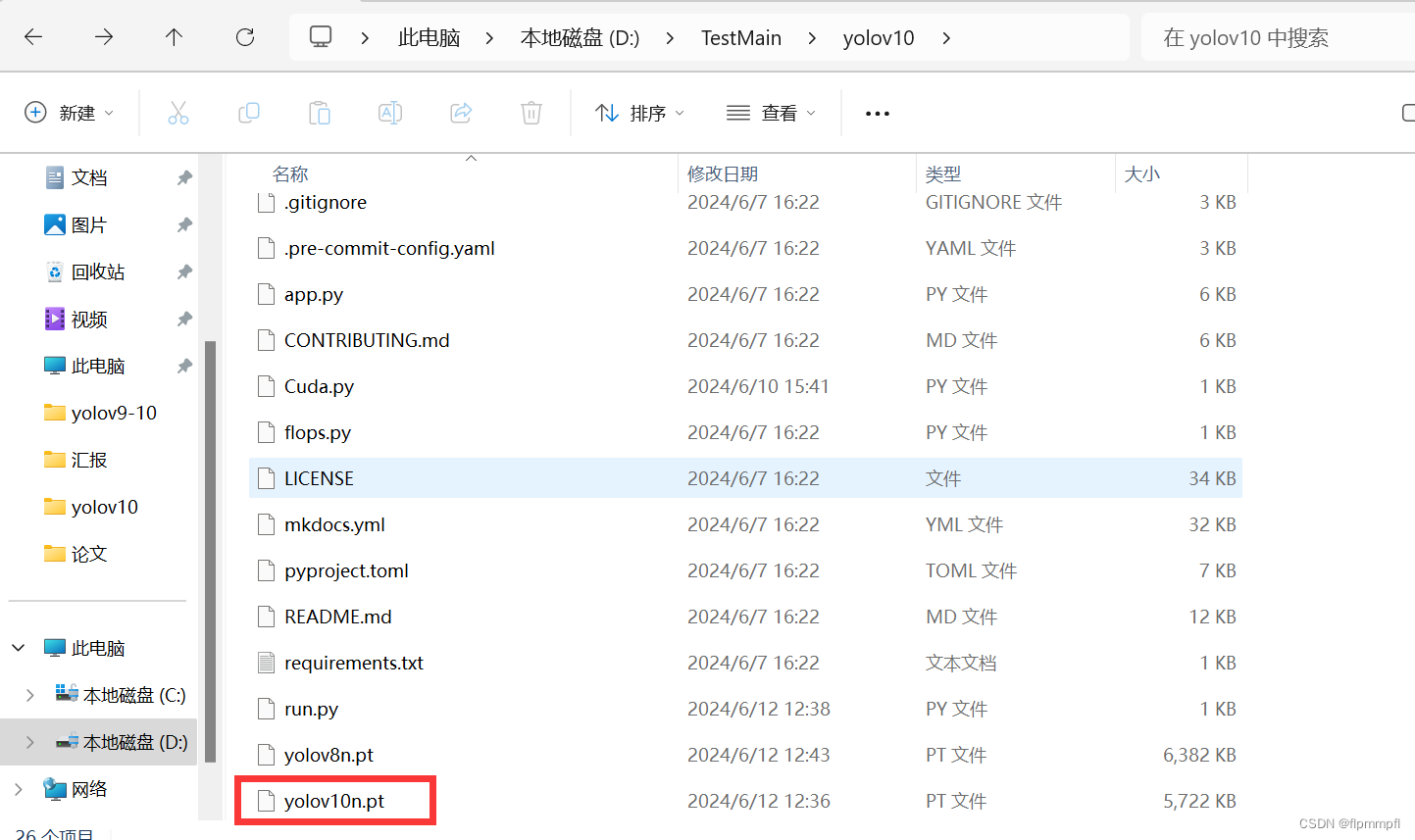
直接放yolov10文件夹根目录下
5、环境配置
5.1.下载yolov10所需虚拟环境
打开anaconda prompt
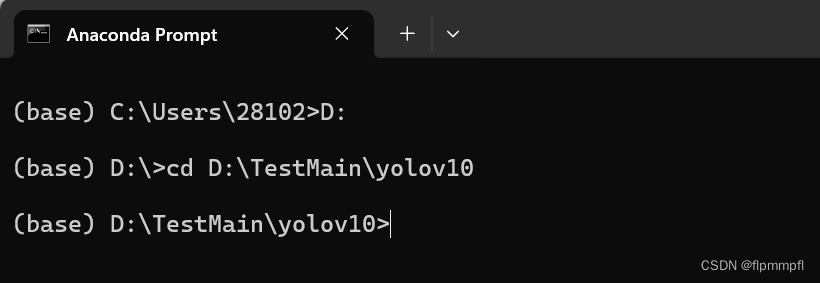
cd进入你下载的yolov10文件夹中
创建yolov10环境:输入 conda create -n yolov10(代表环境名称)python=3.9(使用Python的版本),按y+回车

无脑复制
conda create -n yolov10 python=3.9
进入你刚安装的yolov10环境:conda activate yolov10(你的环境名称)
无脑复制
conda activate yolov10
进入后()会变成你环境名称 (判断是否安装成功)

5.2.下载yolov10依赖库
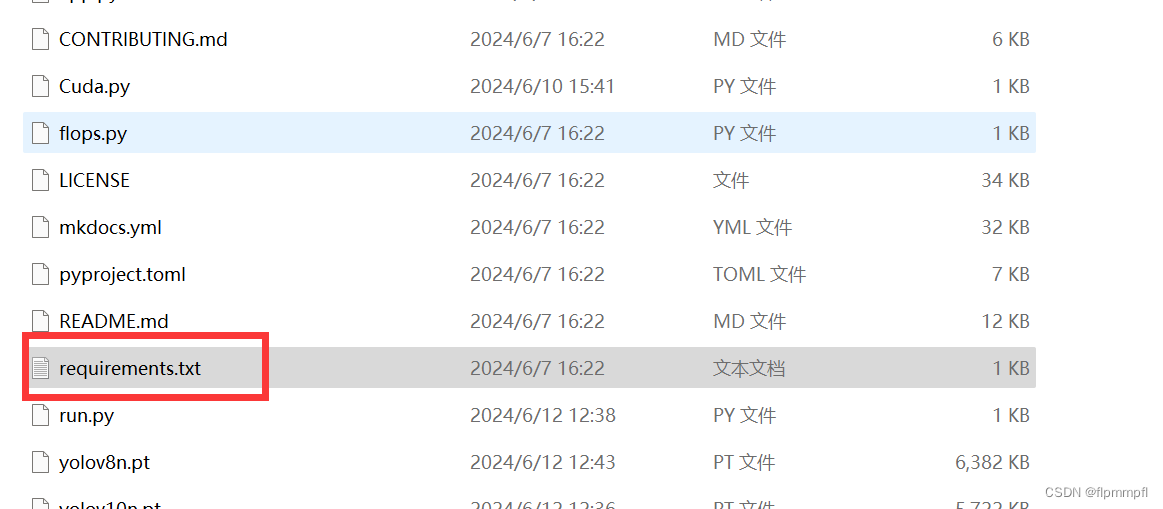
首先到你下载的yolov10文件中找到requirements.txt文件
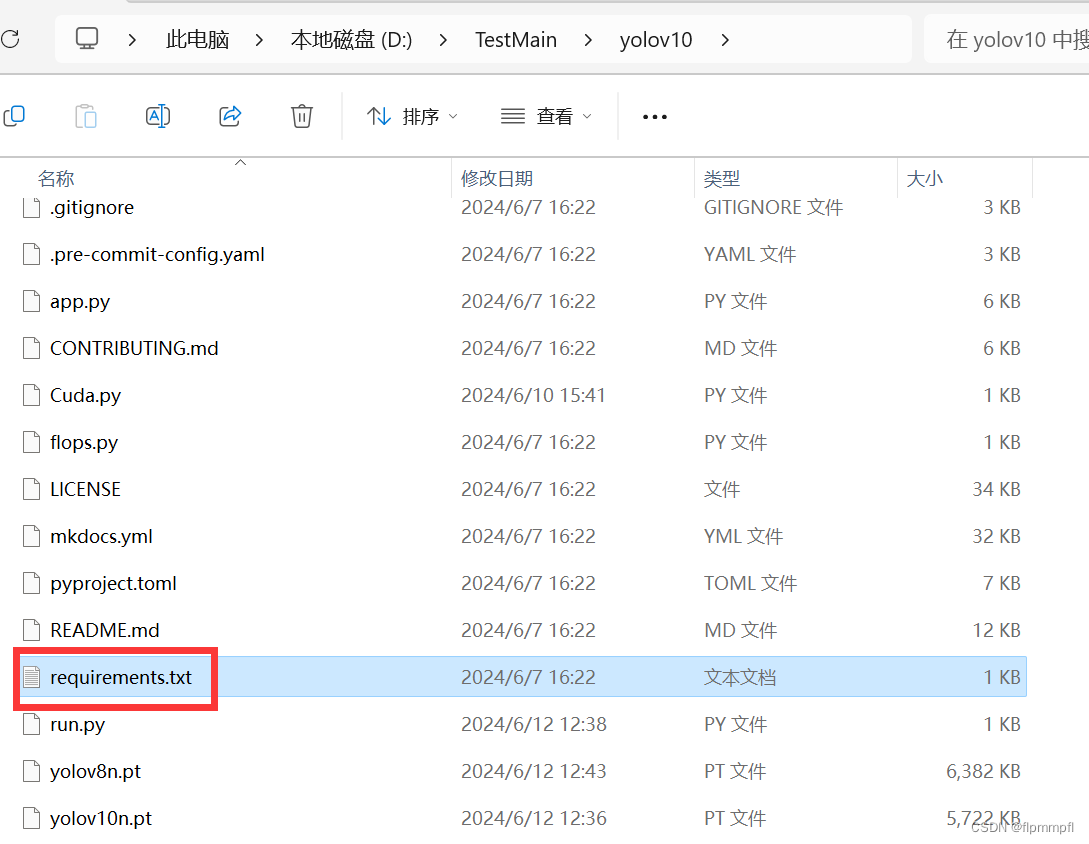
这个标记蓝色的直接删除,这是cpu版本的torch和torchvison(后续实验了一下删不删都可)
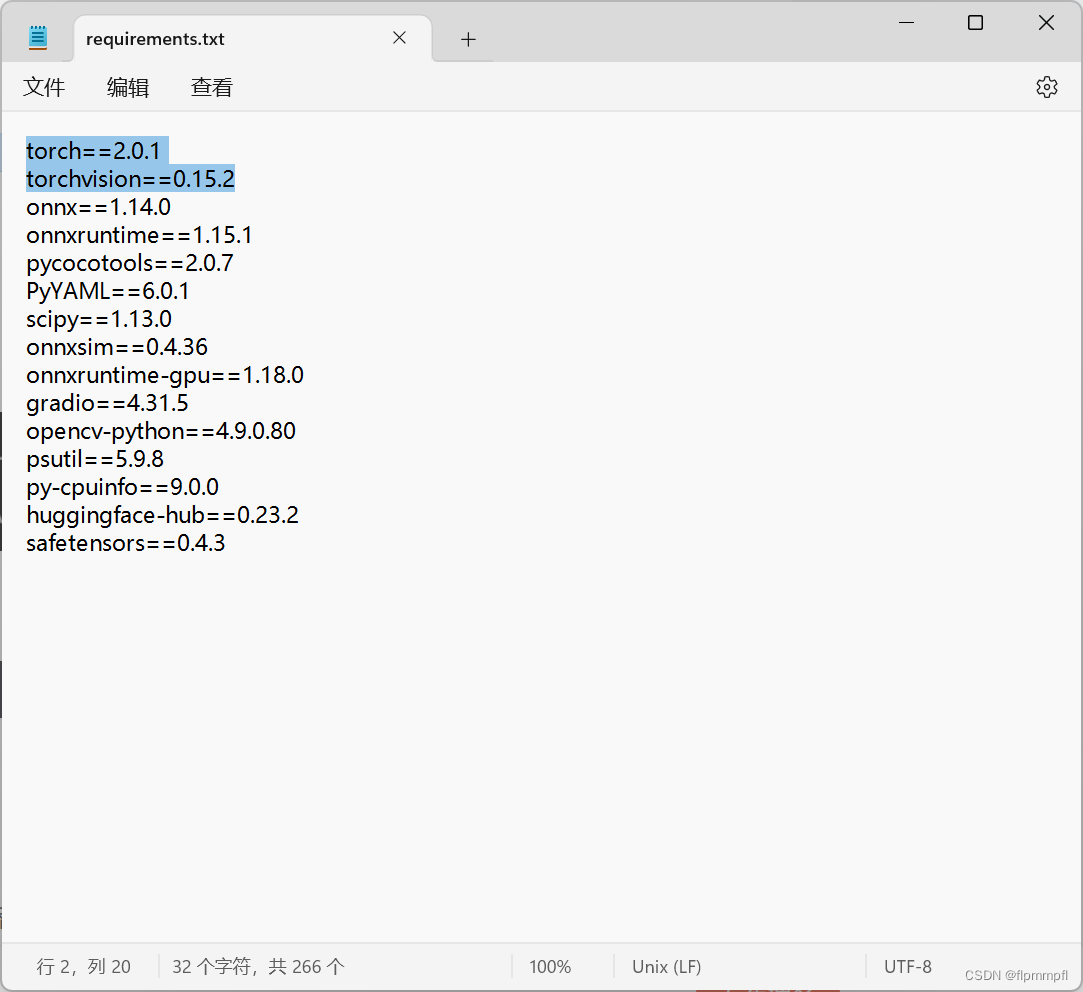
然后安装包里的库文件

无脑复制
pip install -r requirements.txt
去除模型只读权限(如果说你要修改模型,必须pip install -e.,如果说只是复现,可加可不加)

无脑复制
pip install -e .只要中间不报错即为下载成功
5.3.下载CUDA(GPU所需)
cuda是连接GPU和模型训练的桥梁,pytorch是进入桥梁那段上坡的路(CPU训练慢,GPU快还好)(最好选择在虚拟环境安装,以下介绍为虚拟机安装过程)
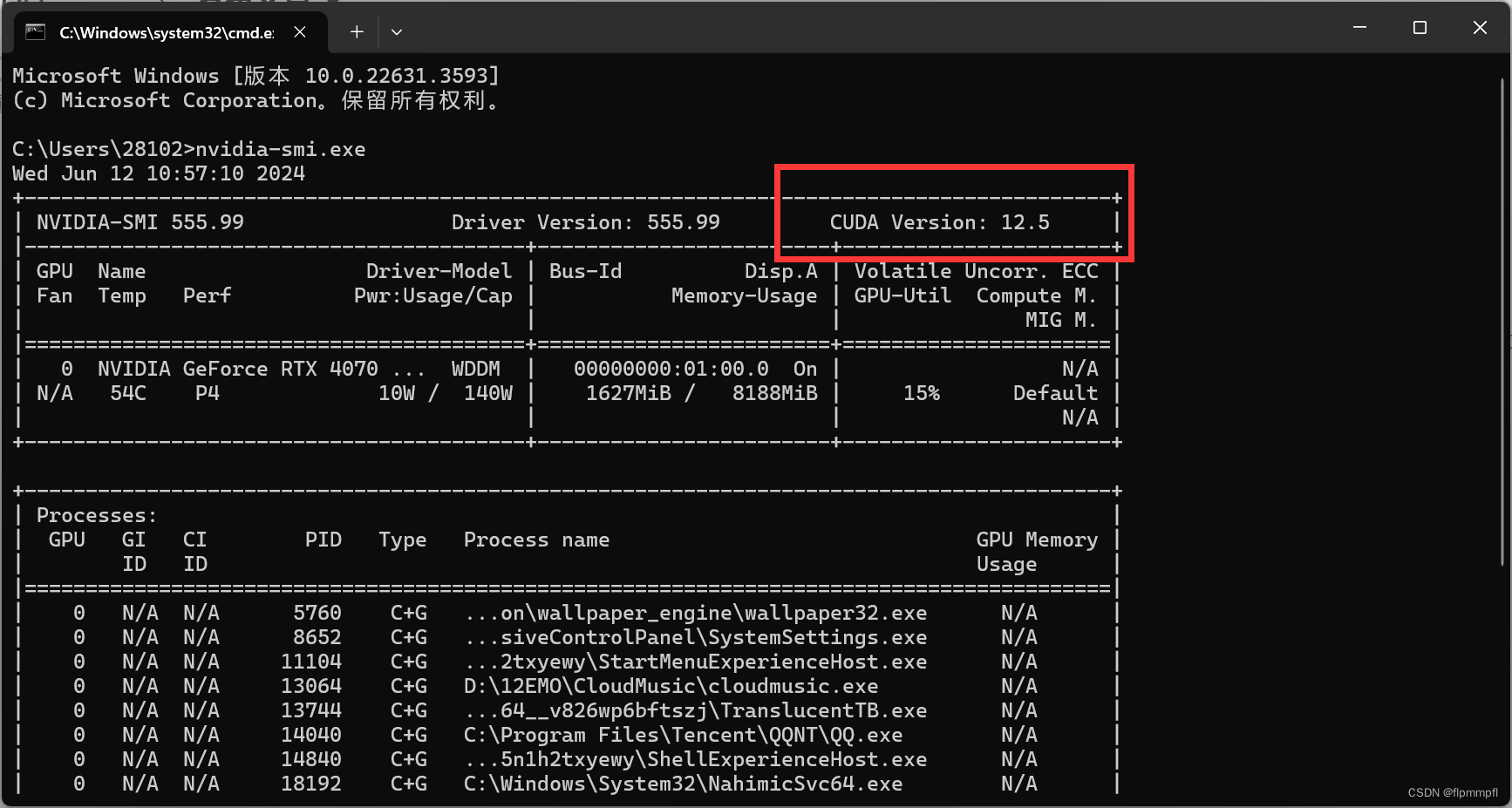
查看cuda最高支持版本,win+R,输入cmd,打开命令窗口,输入nvidia-smi.exe,红框位置为最大可支持安装版本
![]()
无脑复制
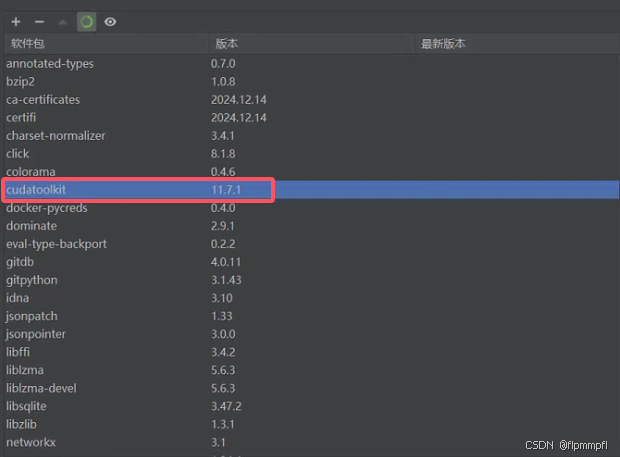
conda install cudatoolkit=11.7
安装后的结果
5.4.下载pytorch(GPU所需)
cuda是连接GPU和模型训练的桥梁,pytorch是进入桥梁那段上坡的路(pytorch库必须和cuda版本匹配)(其实这个在之前下载yolov10虚拟环境已经下载过了,但是为了确保你的pytorch版本和CUDA版本一致,所以这里在从下一遍以确保环境没有问题)


无脑复制(CUDA 11.7)两个任选其一,第一个是下载pytorch,第二个是下载torch,经过实验均可(优先使用第一个)
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia安装后的结果
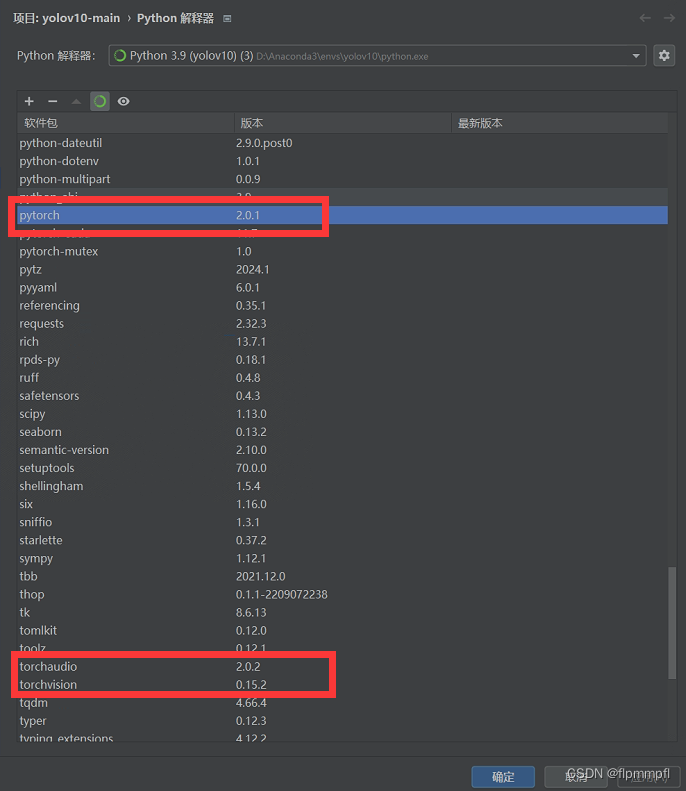
无脑复制(CUDA 11.7)两个任选其一,第一个是下载pytorch,第二个是下载torch,经过实验均可(优先使用第一个)
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2安装后的结果
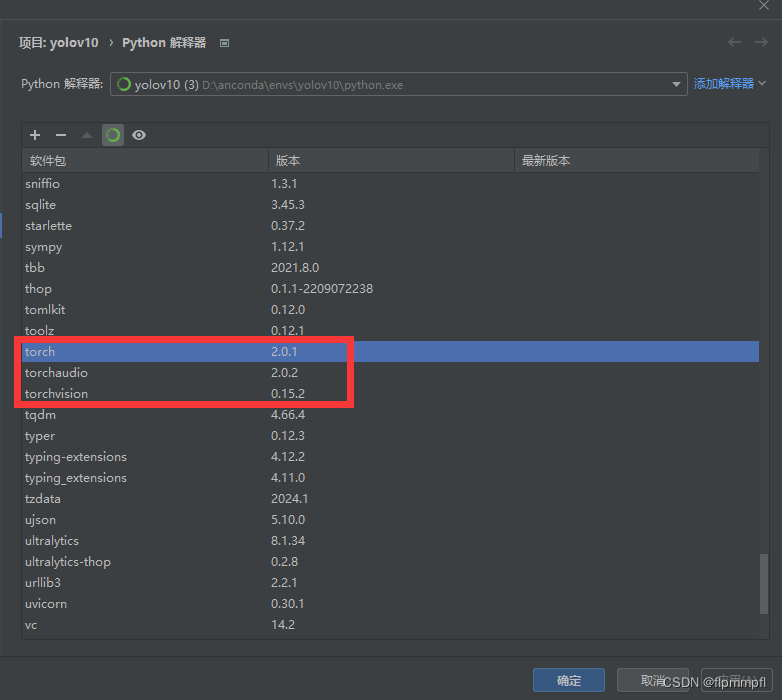
或者去pytorch官网查找(只是教你怎么去找你所下载CUDA对应的pytorch,以防下载的别的版本的CUDA)(例如CUDA=11.8)
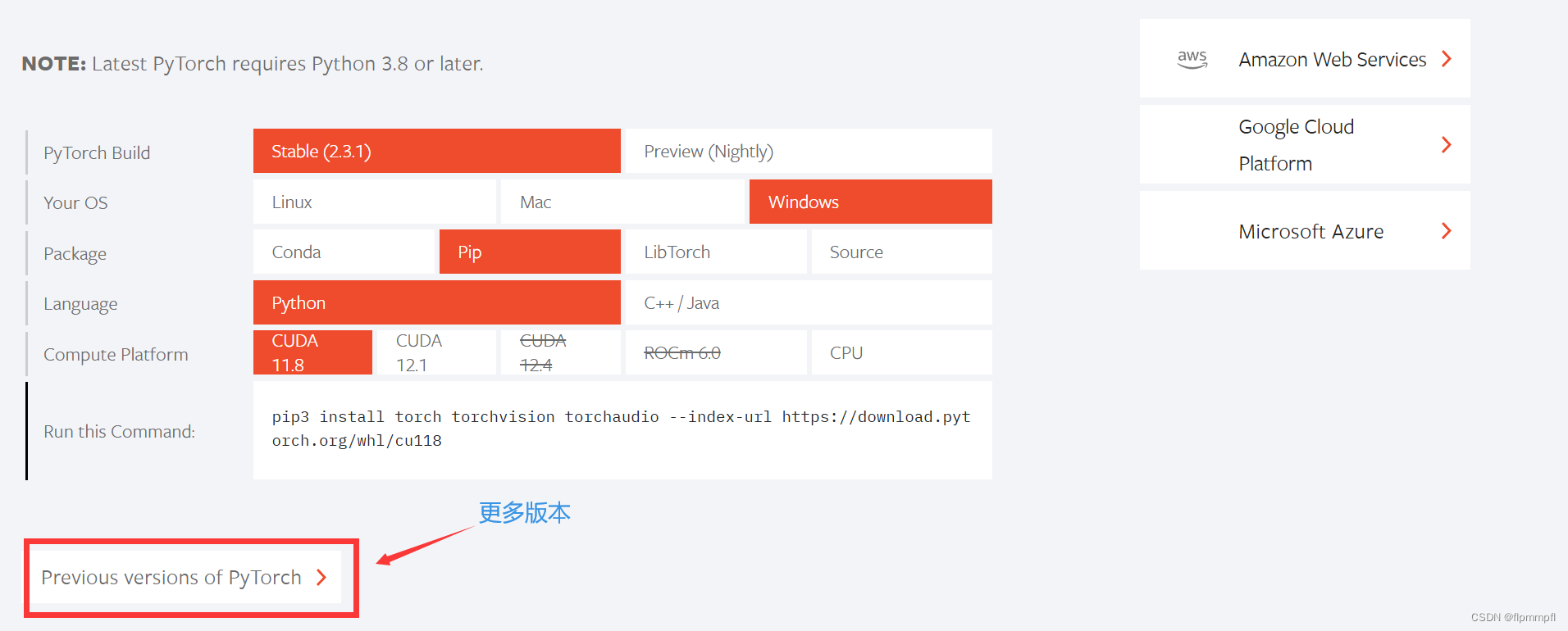
从下载的yolov10文件中去查看所需要的最低版本号
找到requirements.txt,可以看到是最低需要1.7.0版本

然后找到最低的pytorch版本号和对应的cuda版本,复制下面的代码
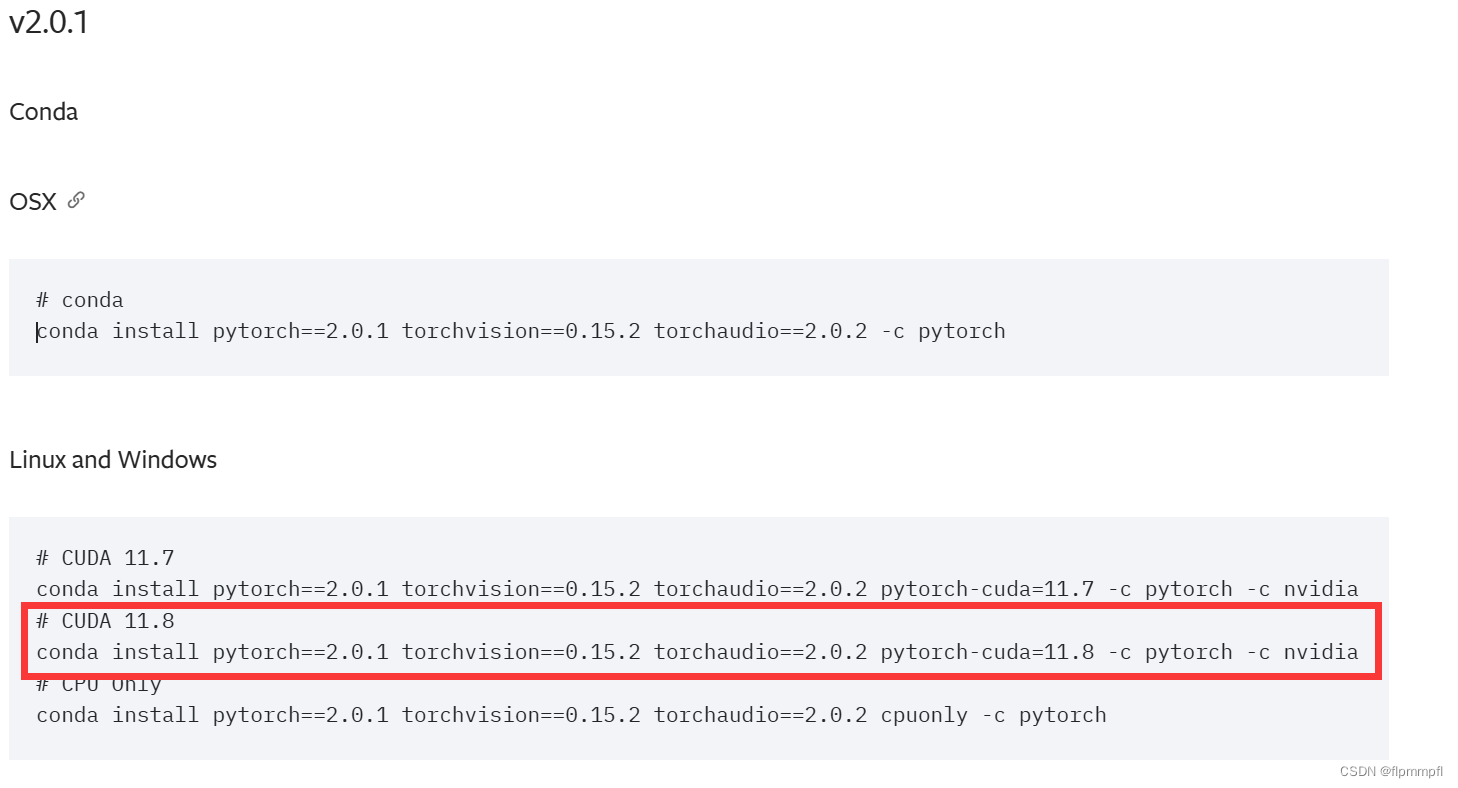

conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.8 -c pytorch -c nvidia5.5检测是否安装正确
(环境已经配好添加好了,6搞完)
建立cuda.py
import torch
print('CUDA版本:',torch.version.cuda)
print('Pytorch版本:',torch.__version__)
print('显卡是否可用:','可用' if(torch.cuda.is_available()) else '不可用')
print('显卡数量:',torch.cuda.device_count())
print('当前显卡型号:',torch.cuda.get_device_name())
print('当前显卡的CUDA算力:',torch.cuda.get_device_capability())
print('当前显卡的总显存:',torch.cuda.get_device_properties(0).total_memory/1024/1024/1024,'GB')
print('是否支持TensorCore:','支持' if (torch.cuda.get_device_properties(0).major >= 7) else '不支持')
print('当前显卡的显存使用率:',torch.cuda.memory_allocated(0)/torch.cuda.get_device_properties(0).total_memory*100,'%')6、pycharm添加解释器
点击文件、设置
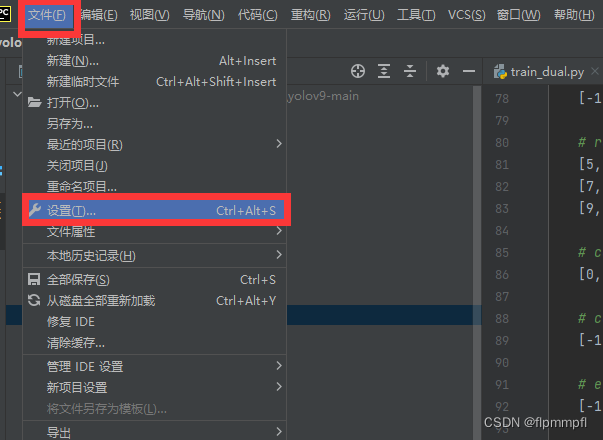
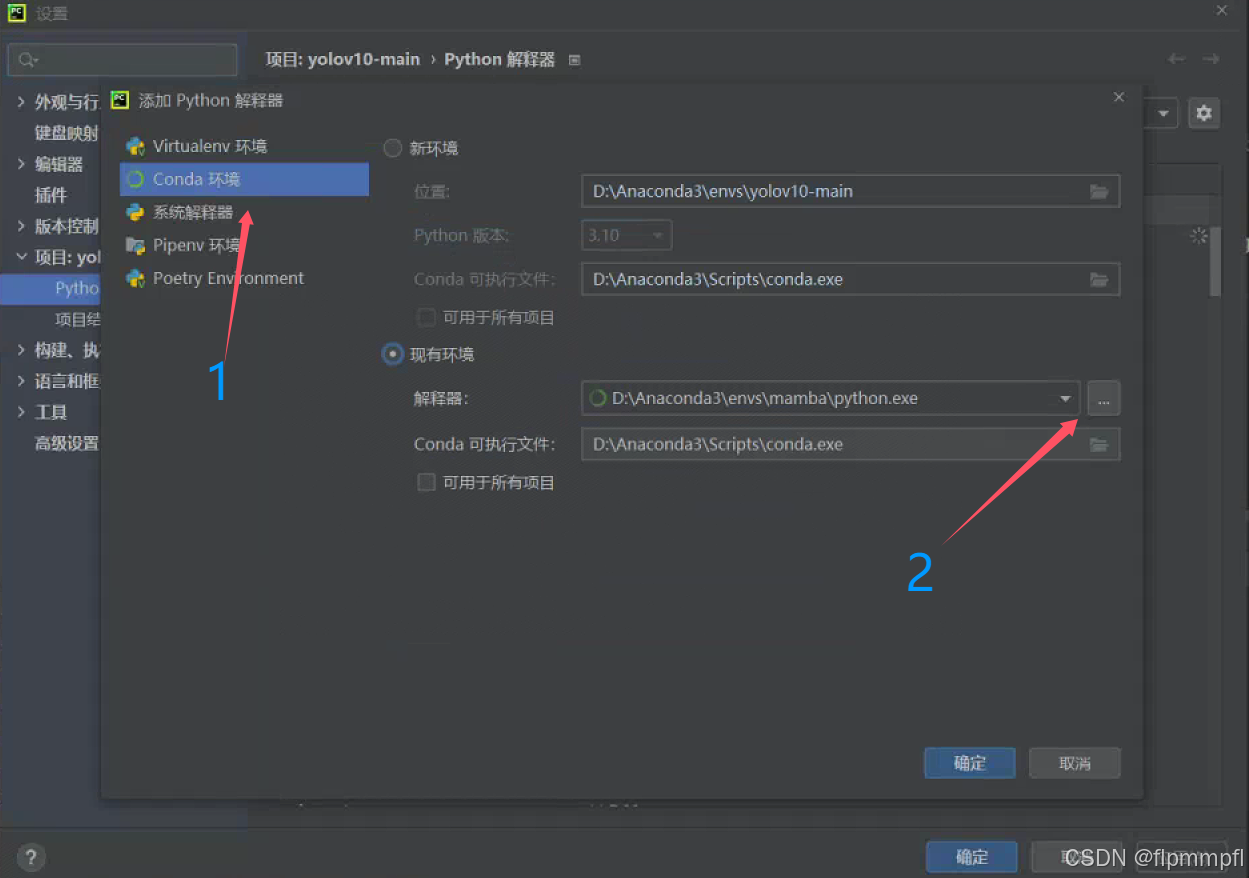
找到python解释器,添加新的解释器
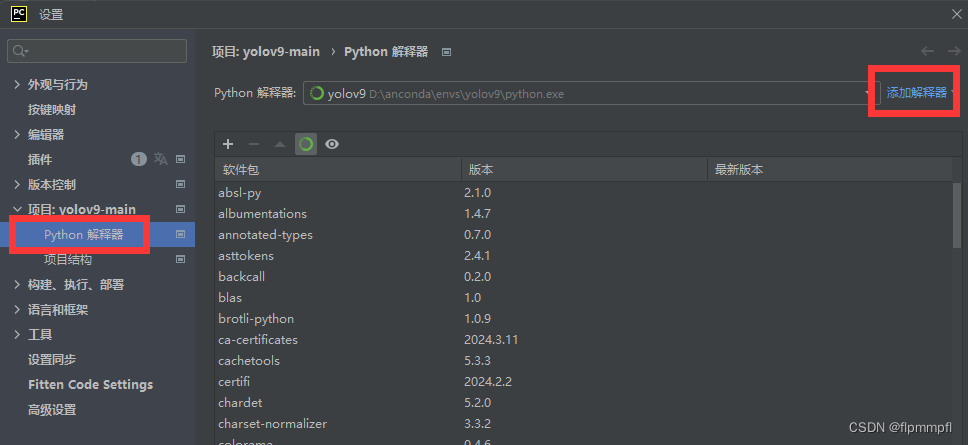
找到conda环境、使用现有环境,找到你前面配置的yolov10(环境名称)
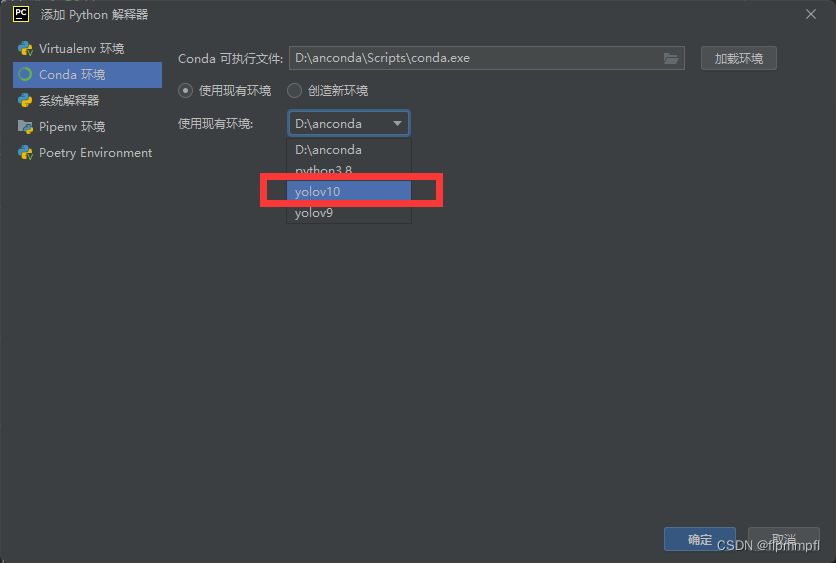
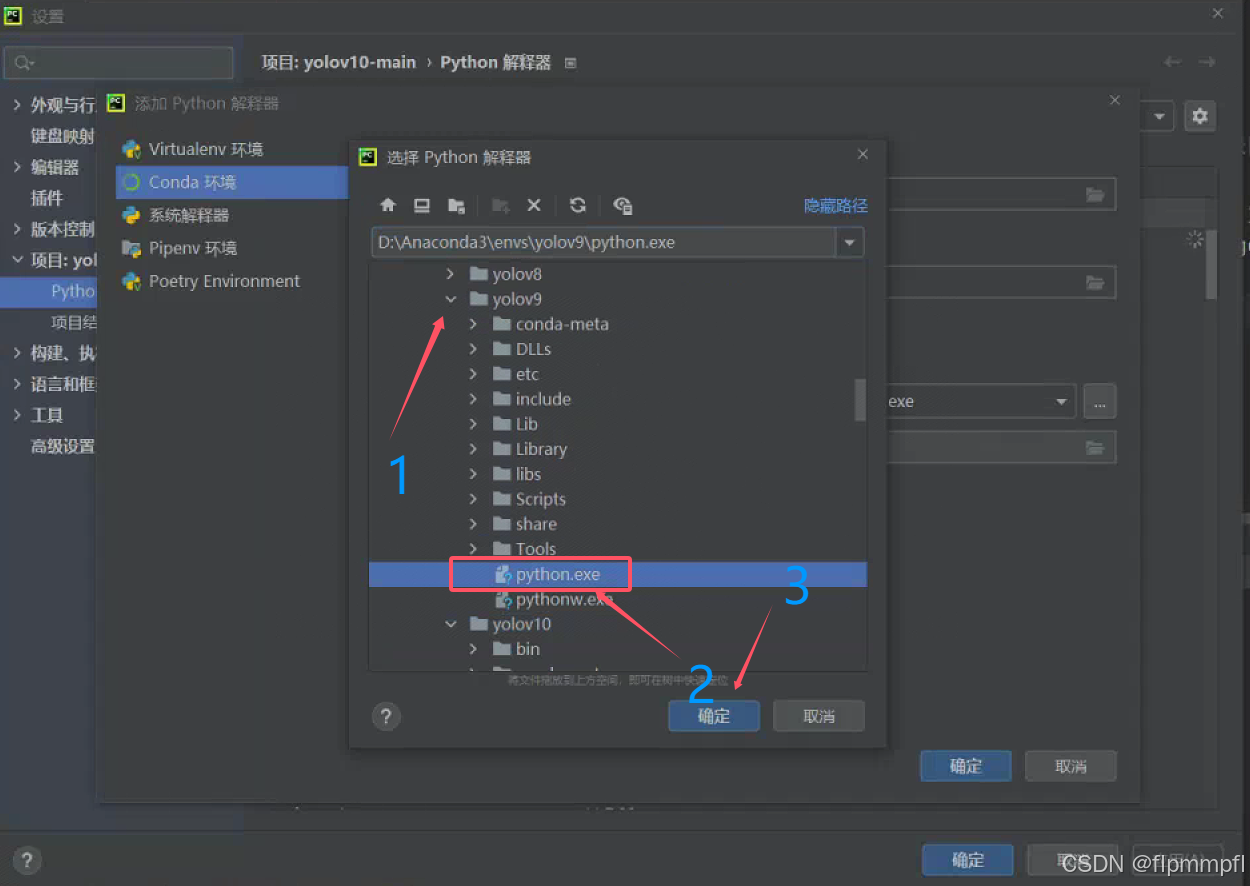
还有老版的pycharm,使用应该找Anaconda3\envs\yolov10(环境名称)\python.exe
(用yolov9举例)
点击应用
7、数据集制作
这边去看yolov9的数据集制作就可以,方法相同
YOLOv9最详细教程(训练自己数据集、结构介绍、重点代码讲解)(草履虫都能看懂系列)-CSDN博客
8、训练
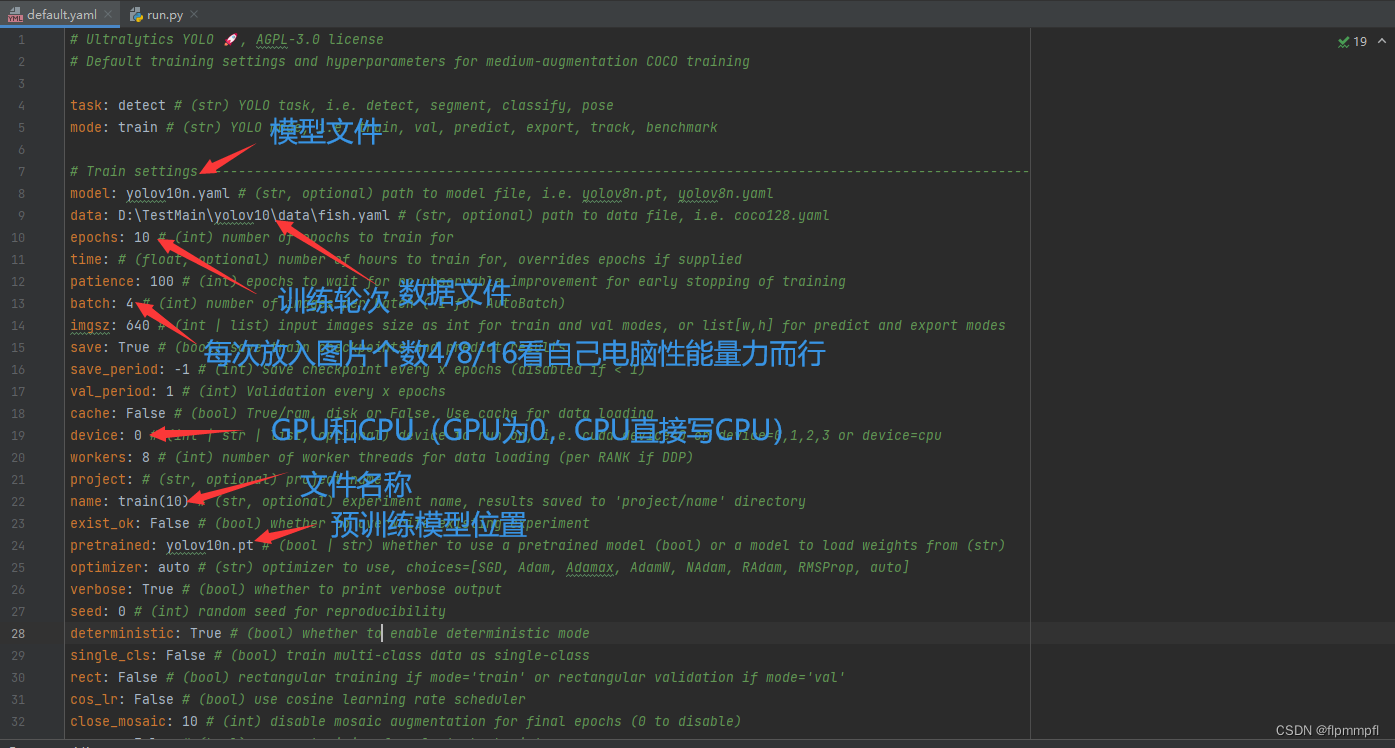
训练有很多种训练方式,我挑选的是我认为最为简单的一种,即修改default.yaml文件,然后在终端调用
default.yaml文件在yolov10/ultralytics/cfg文件中
需修改(最好为绝对路径,多仔细看看,容易出错)
模型文件model(yolov10n.yaml(模型文件)位置)
数据文件(训练图片)data(data.yaml文件所在位置)
训练轮次epochs(基本为300)
训练所放图片个数batch(4/8/16,看自己电脑量力而行)
训练存储地址和名称name(可不改)
使用GPU训练device:0(重点)(如有两个GPU:[0,1])
预训练权重pretrained(yolov10n.pt(权重文件,要于上面对应,就比如你用yolo10n训练你就必须要yolov10n.pt来作为你的预训练权重)位置,无可以不填)
点击终端,输入神秘代码: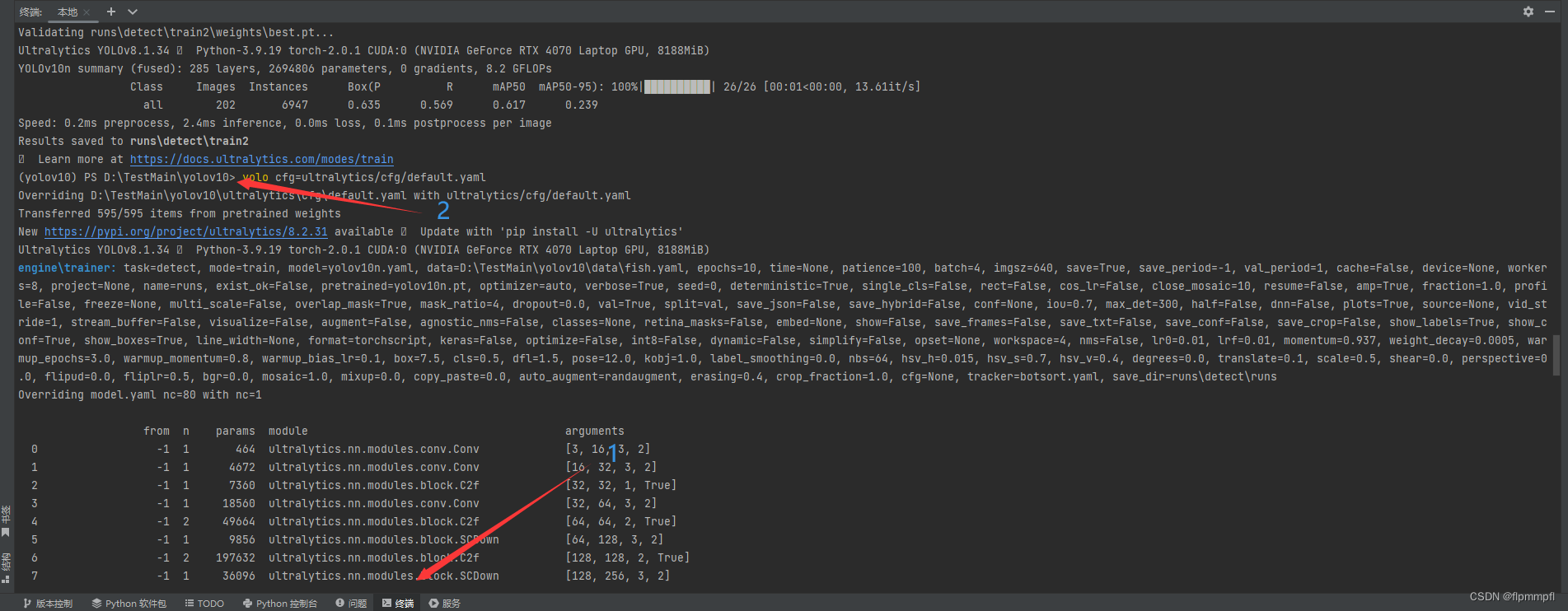
yolo cfg=ultralytics/cfg/default.yaml
9、预测
新建一个test.py,复制粘贴,需改.pt文件和预测集图片位置 .pt文件改你训练出的
from ultralytics import YOLO
import os
def predict_and_save_images_in_folder(model_path, input_folder, output_folder, prefix="test_"):
"""
使用 YOLOv10 模型处理输入文件夹中的所有图片,并将结果以 'prefix' 前缀的形式保存到指定的输出文件夹。
:param model_path: 模型权重文件的路径
:param input_folder: 输入文件夹的路径
:param output_folder: 输出文件夹的路径
:param prefix: 添加到新文件名前的前缀,默认为'test_'
"""
# 加载模型
model = YOLO(model_path)
# 遍历输入文件夹中的所有图片文件
for filename in os.listdir(input_folder):
if filename.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.gif')):
input_image_path = os.path.join(input_folder, filename)
# 进行预测
results = model.predict(source=input_image_path)
# 获取文件名和扩展名
base_name = os.path.splitext(os.path.basename(input_image_path))
new_file_name = f"{prefix}{base_name[0]}{base_name[1]}"
# 构建新文件的完整路径
new_file_path = os.path.join(output_folder, new_file_name)
# 确保输出文件夹存在
os.makedirs(output_folder, exist_ok=True)
# 保存结果图像到新文件名
results[0].save(new_file_path)
print(f"Image saved with the new name {new_file_name} in {output_folder}.")
# 示例使用
model_path = r"D:\boat\ultralytics-mainv8\yolov8x.pt" # 替换为你的模型权重路径
input_folder = r"D:\boat\ultralytics-mainv8\bot\Image" # 替换为你的预测集文件夹路径
output_folder = r"D:\boat\ultralytics-mainv8\bot\test_Image" # 替换为你希望保存输出图像的文件夹路径
predict_and_save_images_in_folder(model_path, input_folder, output_folder)9、跟踪(视频)
修改.pt权重文件,source为你视频文件
yolo track model=D:\boat\ultralytics-mainv8\yolov8n.pt source=D:\boat\ultralytics-mainv8\bot\Video\1.mp4 tracker=bytetrack.yaml大功告成,觉得好的就点点赞,点点收藏,如有什么错误或者建议麻烦指出(字码错了也可以说,毕竟经常这样),谢谢



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









