






官网解读
在过去的一年里,用于预训练和迁移学习的新模型和方法在一系列语言理解任务中推动了显着的性能改进。一年前推出的 GLUE 基准测试提供了一个单一数字的指标,总结了各种此类任务的进展,但该基准测试的表现最近已接近非专家人类的水平,这表明进一步研究的空间有限。
我们考虑了从原始 GLUE 基准测试中吸取的经验教训,并推出了 SuperGLUE,这是一个以 GLUE 为风格的新基准测试,具有一组新的更困难的语言理解任务、改进的资源和新的公共排行榜。
总结
SuperGLUE(Super General Language Understanding Evaluation)是一个评估自然语言处理(NLP)模型性能的基准测试集。它由纽约大学、华盛顿大学、DeepSeek、艾伦人工智能研究所和Facebook AI Research共同开发,旨在提供一个更加全面和具有挑战性的评估平台,以推动NLP领域的发展。
SuperGLUE包含了一系列不同的任务,这些任务涵盖了语言理解的不同方面,包括:
BoolQ:一个基于阅读理解的任务,要求模型回答关于给定段落的是非题。
CommitmentBank:一个基于阅读理解的任务,要求模型判断给定句子是否与给定段落中的信息一致。
MultiRC:一个多选题阅读理解任务,要求模型从给定段落中找到支持每个选项的证据。
RTE:一个文本蕴涵任务,要求模型判断一个句子是否可以由另一个句子蕴涵。
WSC:一个代词消歧任务,要求模型识别句子中的代词指代哪个名词。
COPA:一个常识推理任务,要求模型根据两个可能的行动和两个可能的结果来判断哪个行动导致了哪个结果。
ReCoRD:一个多选题阅读理解任务,要求模型从给定段落中找到支持每个选项的证据。
WiC:一个词汇消歧任务,要求模型判断两个句子中的相同单词是否具有相同的含义。
CB:一个基于阅读理解的常识推理任务,要求模型判断给定句子是否与给定段落中的信息一致。
SuperGLUE的目的是提供一个更加严格和全面的评估平台,以促进NLP模型的研究和发展。通过在SuperGLUE上进行测试,研究人员可以更好地理解他们的模型在不同类型任务上的表现,并针对性地改进模型。
SuperGLUE的人类水平是指在SuperGLUE基准测试中,人类参与者在各个任务上的平均表现。这个基准测试旨在评估自然语言处理(NLP)模型的性能,并提供一个与人类水平相比较的标准。
在SuperGLUE中,每个任务都有一个人类基线分数,这个分数是通过让一组人类参与者完成任务并计算他们的平均正确率来确定的。这个基线分数代表了人类在完成这些任务时的平均水平。
对于NLP模型来说,达到或超过人类水平是一个重要的里程碑,因为它表明模型在理解语言和完成语言任务方面已经达到了与人类相当的水平。然而,需要注意的是,即使模型在某些任务上达到了人类水平,这并不意味着它在所有语言理解方面都与人类相当,因为语言理解是一个非常复杂和多维度的领域。
在过去的一年里,用于预训练和迁移学习的新模型和方法在一系列语言理解任务中推动了显着的性能改进。一年多前推出的 GLUE 基准测试提供了一个单一数字的指标,总结了各种此类任务的进展情况,
但最近基准测试的表现已经超过了非专家的水平,这表明进一步研究的空间有限。在本文中,我们介绍了 SuperGLUE,这是一个以 GLUE 为风格的新基准测试,具有一组新的更困难的语言理解任务、一个软件工具包和一个公共排行榜。
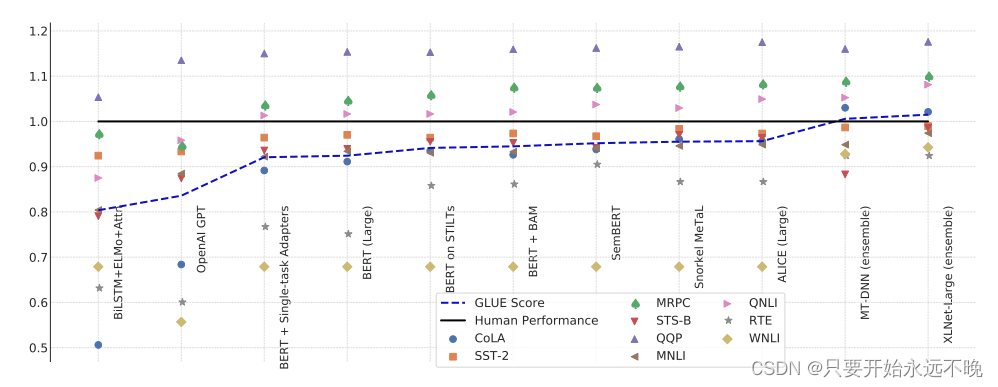
最近,在ELMo(Peters等人,2018年),OpenAI GPT(Radford等人,2018年)和BERT(Devlin等人,2019年)等方法的带领下,许多自然语言处理(NLP)任务取得了显着进展。这些方法的统一主题是,它们将来自大量未标记文本语料库的自我监督学习与结果模型的有效适应目标任务相结合。已被证明适合这种通用方法的任务包括问答、文本蕴涵和解析等(Devlin 等人,2019 年;Kitaev 等人,2019 年,i.a.)。在此背景下,GLUE基准(Wang et al., 2019a)已成为通用语言理解技术研究的重要评估框架。 GLUE 是建立在现有公共数据集上的九个语言理解任务的集合,以及私有测试数据、评估服务器、单数目标指标和随附的专家构建的诊断集。GLUE 旨在提供对语言理解的通用评估,涵盖一系列训练数据量、任务类型和任务表述。我们认为,正是这些方面使 GLUE 特别适合展示 OpenAI GPT 和 BERT 等方法的迁移学习潜力。过去 12 个月的进展极大地削弱了 GLUE 基准的余地。虽然在 GLUE 中测量的一些任务(图 1)和一些语言现象(附录 B 中的图 2)仍然很困难,但截至 2019 年 7 月初,目前最先进的 GLUE 分数(来自 Yang 等人,2019 年的 88.4 分)比人类的表现(Nangia 和 Bowman,2019 年的 87.1 分)高出 1.3 分,实际上超过了四项任务的人类表现估计值。因此,尽管在实现GLUE的高级目标方面仍有很大的改进空间,但基准的原始版本不再是量化此类进展的合适指标。作为回应,我们推出了 SuperGLUE,这是一个新的基准测试,旨在对语言理解进行更严格的测试。 SuperGLUE与GLUE有着相同的高层次动机:提供一种简单、难以博弈的衡量标准,以衡量英语通用语言理解技术的进展。我们预计,SuperGLUE的重大进展需要在机器学习的许多核心领域进行实质性创新,包括采样高效、传输、多任务以及无监督或自监督学习。SuperGLUE遵循GLUE的基本设计:它由一个围绕八个语言理解任务构建的公共排行榜组成,利用现有数据,并附有一个单一数字的性能指标和一个分析工具包。但是,它在以下几个方面改进了 GLUE:
更具挑战性的任务:SuperGLUE保留了GLUE中最难的两项任务。其余的任务是从提交给公开征集任务提案的任务中确定的,并根据当前NLP方法的难度进行选择。
更多样化的任务格式:GLUE中的任务格式仅限于句子和句子对分类。我们扩展了 SuperGLUE 中的任务格式集,以包括共指解决和问答 (QA)。
全面的人类基线:我们包括所有基准任务的人类绩效估计,这些估计验证了基于BERT的强大基线与人类绩效之间存在相当大的空间。
改进的代码支持:SuperGLUE 与一个新的模块化工具包一起分发,用于 NLP 中的预训练、多任务学习和迁移学习,围绕标准工具构建,包括 PyTorch(Paszke 等人,2017 年)和 AllenNLP(Gardner 等人,2017 年)。
完善的使用规则:修改了加入 SuperGLUE 排行榜的条件,以确保公平竞争、信息丰富的排行榜以及数据和任务创建者的全部功劳分配
SuperGLUE 概述
设计过程
SuperGLUE 的目标是为能够应用于各种语言理解任务的任何方法提供简单、强大的评估指标。为此,在设计SuperGLUE时,我们在基准测试中确定了以下任务:
任务内容:任务应测试系统对英语文本的理解和推理能力.
任务难度:任务应超出当前最先进的系统的范围,但大多数受过大学教育的英语使用者都可以解决。我们排除了需要特定领域知识的任务,例如医学笔记或科学论文。
可评估性:任务必须具有自动性能指标,该指标与人类对输出质量的判断非常吻合。由于 ROUGE 和 BLEU 等自动指标的问题,一些文本生成任务无法满足此标准(Callison-Burch 等人,2006 年;Liu et al., 2016, i.a.)
公开数据:我们要求任务具有现有的公共训练数据,以最大程度地降低新创建数据集的风险。我们还更喜欢我们可以访问(或可以创建)具有自有标签的测试集的任务。
任务格式:我们更喜欢输入和输出格式相对简单的任务,以避免激励基准测试的用户创建复杂的特定于任务的模型架构。尽管如此,虽然 GLUE仅限于涉及单个句子或句子对输入的任务,但对于 SuperGLUE,我们扩大了范围以考虑具有较长输入的任务。这会产生一组任务,这些任务需要理解上下文中的单个标记、完整的句子、句子间关系和整个段落。
许可证:任务数据必须在允许用于研究目的的使用和重新分发的许可证下提供。
为了确定 SuperGLUE 的可能任务,我们向 NLP 社区发布了任务提案的公开征集,并收到了大约 30 份提案。我们根据我们的标准过滤了这些提案。 由于许可问题、复杂的格式和空间不足,许多提案不合适;我们在附录 D 中提供了此类任务的示例。对于剩下的每个任务,我们运行了一个基于BERT的基线和一个人类基线,并过滤掉了那些对没有广泛培训的人类来说太具有挑战性的任务,或者对我们的机器基线来说太容易的任务
任务
按照这个过程,我们得出了在SuperGLUE中使用的八个任务。
有关每个任务的详细信息和具体示例,请参阅表 1 和表 2。
BoolQ(Boolean Questions, Clark et al., 2019a) 是一项 QA 任务,其中每个示例都由一个短文和一个关于该文的是/否问题组成。 这些问题是由谷歌搜索引擎的用户匿名和主动提供的,然后与包含答案的维基百科文章中的段落配对。根据原始工作,我们进行准确的评估。
举例
{
"question": "is france the same timezone as the uk",
"passage": "At the Liberation of France in the summer of 1944, Metropolitan France kept GMT+2 as it was the time then used by the Allies (British Double Summer Time). In the winter of 1944--1945, Metropolitan France switched to GMT+1, same as in the United Kingdom, and switched again to GMT+2 in April 1945 like its British ally. In September 1945, Metropolitan France returned to GMT+1 (pre-war summer time), which the British had already done in July 1945. Metropolitan France was officially scheduled to return to GMT+0 on November 18, 1945 (the British returned to GMT+0 in on October 7, 1945), but the French government canceled the decision on November 5, 1945, and GMT+1 has since then remained the official time of Metropolitan France."
"answer": false,
"title": "Time in France",
}CB(CommitmentBank, de Marneffe et al., 2019)是一个短文本语料库,其中至少有一个句子包含嵌入子句。这些嵌入的子句中的每一个都标注了撰写文本的人对子句的真实性的承诺程度。由此产生的任务被框定为三类文本蕴涵,这些例子来自《华尔街日报》,小说来自英国国家语料库和总机。 每个示例都由一个包含嵌入子句的前提组成,相应的假设是该子句的提取。我们使用注释者间一致性高于 80% 的数据子集。数据是不平衡的(相对较少的中性示例),因此我们使用准确性和 F1 进行评估,其中对于多类 F1,我们计算每个类 F1 的未加权平均值。
COPA(Choice of Plausible Alternatives, Roemmele et al., 2011)是一项因果推理任务,其中系统被赋予一个前提句,并且必须从两个可能的选择中确定前提的原因或结果。 所有示例都是手工制作的,并专注于博客和摄影相关百科全书中的主题。在原著的基础上,我们用精度来评价。
举例:
前提:那个男人摔断了脚趾。这是什么原因?
备选方案1:他的袜子上有个洞。
备选方案2:他把锤子砸在脚上。
前提:我把瓶子倒了。结果是什么?
备选方案1:瓶子里的液体结冰了。
备选方案2:瓶子里的液体倒了出来。
前提:我敲了邻居的门。结果是什么?
备选方案1:我的邻居邀请我进去。
备选方案2:我的邻居离开了他的房子。MultiRC(Multi-Sentence Reading Comprehension, Khashabi et al., 2018)是一项 QA 任务,其中每个示例都由一个上下文段落、一个关于该段落的问题和一个可能的答案列表组成。 系统必须预测哪些答案是真的,哪些是假的。 虽然存在许多 QA 任务,但我们使用 MultiRC 是因为有许多理想的属性:(i) 每个问题可以有多个可能的正确答案,因此每个问题-答案对都必须独立于其他对进行评估,(ii) 问题的设计使得回答每个问题都需要从多个上下文句子中提取事实,以及 (iii) 问答对格式比更流行的跨度提取 QA 格式更接近 SuperGLUE 中其他任务的 API。 这些段落来自七个领域,包括新闻、小说和历史文本。评估指标在所有答案选项上都是 F1,并且每个问题的答案集 (EM) 完全匹配。
ReCoRD(Reading Comprehension with Commonsense Reasoning Dataset, Zhang et al., 2018)是一项多项选择的QA任务。每个示例都由一篇新闻文章和一个关于文章的完形填空式问题组成,其中有一个实体被屏蔽。系统必须从所提供段落中可能的实体列表中预测被遮蔽的实体,其中同一实体可以用多种不同的表面形式表示,这些表面形式都被认为是正确的。文章来自CNN和每日邮报。我们使用最大(在所有提及次数中)标记级别 F1 和完全匹配 (EM) 进行评估。
ReCoRD
├── version: (string) the version of ReCoRD.
└── data: (list) ReCoRD examples.
Each example has the following structure.
├── id: (string) the example ID.
├── source: (string) the original news source of this example.
├── passage: (dict) the passage of this example.
│ ├── text: (string) the passage text.
│ └── entities: (list) the named entities in the passage.
│ Each named entity has the following structure.
│ ├── start: (int) the start char index of the entity.
│ └── end: (int) the end char index (inclusive) of the entity.
└── qas: (list) queries for the corresponding passage
Each query has the following structure.
├── id: (string) the query ID.
├── query: (string) the query text (the missing text span is indicated by "@placeholder").
└── answers: (list) the reference answers.
Each answer has the following structure.
├── start: (int) the start char index of the answer in the passage.
├── end: (int) the end char index (inclusive) of the answer in the passage.
└── text: (string) the answer textRTE(Recognition Textual Entailment)数据集来自一系列关于文本蕴涵的年度竞赛。RTE包含在GLUE中,我们使用与GLUE相同的数据和格式:我们合并了来自RTE1(Dagan等人,2006),RTE2(Bar Haim等人,2006),RTE3(Giampiccolo等人,2007)和RTE5(Bentivogli等人,2009)的数据。所有数据集都合并并转换为两类分类:蕴涵和非蕴涵。 在所有 GLUE 任务中,RTE 是那些从迁移学习中受益最多的任务之一,性能从 GLUE 推出时的近乎随机几率 (∼56%) 跃升至 86.3% 的准确率(Liu 等人,2019d;Yang et al., 2019)在撰写本文时。然而,鉴于在人类表现方面存在近8个百分点的差距,机器尚未解决这项任务,我们预计剩余的差距将难以缩小。
WiC(Word-in-Context, Pilehvar and Camacho-Collados, 2019)是一个词义消歧任务,作为句子对的二元分类。给定两个文本片段和一个出现在两个句子中的多义词,任务是确定该词在两个句子中的使用是否具有相同的意义。句子来自WordNet(Miller,1995),VerbNet(Schuler,2005)和维基词典。我们遵循原始工作并使用准确性进行评估。
| Label | Target | Context-1 | Context-2 |
|---|---|---|---|
| F | bed | There's a lot of trash on the bed of the river | I keep a glass of water next to my bed when I sleep |
| F | land | The pilot managed to land the airplane safely | The enemy landed several of our aircrafts |
| F | justify | Justify the margins | The end justifies the means |
| T | beat | We beat the competition | Agassi beat Becker in the tennis championship |
| T | air | Air pollution | Open a window and let in some air |
| T | window | The expanded window will give us time to catch the thieves | You have a two-hour window of clear weather to finish working on the lawn |
WSC(Winograd Schema Challenge, Levesque et al., 2012)是一项共指解析任务,其中示例由带有代词的句子和句子中的名词短语列表组成。系统必须从提供的选项中确定代词的正确指称。Winograd 模式旨在需要日常知识和常识推理来解决。
Dan不得不阻止Bill玩弄受伤的鸟。他非常富有同情心。
片段:他非常富有同情心。
Dan
BillGLUE 包括一个重铸为 NLI 的 WSC 版本,称为 WNLI。直到最近,WNLI还没有取得实质性进展,许多意见书选择提交多数类预测。在过去的几个月里,有几部作品(Kocijan 等人,2019 年;Liu et al., 2019d) 通过 hueristic 数据增强方案取得了快速进展,将机器性能提高到 90.4% 的准确率。鉴于估计的人类性能约为 96%,机器和人类性能之间仍然存在差距,我们预计这将相对难以弥合。因此,我们包括一个版本的WSC作为二元分类,其中每个示例由一个带有标记的代词名词的句子组成,任务是确定代词是否指代该名词。训练和验证示例来自原始WSC数据(Levesque et al., 2012),以及由附属组织分发的Commonsense Reasoning.测试示例来自小说书籍,并由原始数据集的作者与我们共享。我们使用准确性进行评估。
基线
BERT我们的主要基线是围绕BERT构建的,在撰写本文时,BERT的变体是GLUE上最成功的方法之一。 具体来说,我们使用 bert-large-cased 变体。按照Devlin等人(2019)推荐的做法,对于每个任务,我们在BERT之上使用最简单的架构。我们为每个任务分别微调预训练的 BERT 模型的副本,并将多任务学习模型的开发留给未来的工作。对于训练,我们使用 Devlin 等人 (2019) 中指定的程序:我们使用 Adam (Kingma and Ba, 2014),初始学习率为 10−5,并微调最多 10 个 epoch。对于具有句子对输入(BoolQ、CB、RTE、WiC)的分类任务,我们用 [SEP] 标记连接句子,将融合的输入馈送到 BERT,并使用逻辑回归分类器查看对应于 [CLS] 的表示。对于 WiC,我们还连接了标记单词的表示形式。 对于 COPA、MultiRC 和 ReCoRD,对于每个答案选项,我们同样将上下文与该答案选项连接起来,并将结果序列输入 BERT 以生成答案表示。对于 COPA,我们将这些表示投影到标量中,并将具有最高相关标量的选择作为答案。对于 MultiRC,由于每个问题可以有多个正确答案,因此我们将每个答案表示形式输入到逻辑回归分类器中。对于ReCoRD,我们还评估了每个候选者独立于其他候选者的概率,并将最有可能的候选者作为模型的预测。对于基于跨度的任务 WSC,我们使用了受 Tenney 等人 (2019) 启发的模型。给定原始句子中每个单词的 BERT 表示,我们通过自注意力跨度池运算符 (Lee et al., 2017) 获得代词和名词短语的 span 表示,然后将其输入逻辑回归分类器。BERT++我们还使用 BERT 报告结果,并在对基准任务进行微调之前对相关数据集进行额外训练,遵循 STILTs 的迁移学习风格(Phang 等人,2018 年)。鉴于 MultiNLI 在预训练语言模型的预训练和中间微调中的有效使用(Conneau 等人,2017 年;Phang et al., 2018, i.a.),对于 CB、RTE 和 BoolQ,我们首先使用 MultiNLI 上的上述过程作为传输任务。同样,鉴于 COPA 与 SWAG 的相似性(Zellers 等人,2018 年),我们首先在 SWAG 上微调 BERT。这些结果报告为 BERT++。对于所有其他任务,我们重用了针对该任务微调的 BERT 结果。其他基线我们包括一个基线,对于每个任务,我们简单地预测大多数类,6以及一个词袋基线,其中每个输入都表示为其代币的 GloVeword 向量的平均值(Pennington 等人发布的 300D/840B,2014 年)。最后,我们列出了截至 2019 年 5 月每个任务的最佳已知结果,但重铸 (WSC)、重新拆分 (CB) 或实现最已知结果 (WiC) 的任务除外。COPA、MultiRC 和 RTE 的外部结果分别来自 Sap et al. (2019)、Trivedi et al. (2019) 和 Liu et al. (2019d)。
人类表现Pilehvar 和 Camacho-Collados (2019)、Khashabi 等人 (2018)、Nangia 和 Bowman (2019) 和 Zhang 等人 (2018) 分别提供了人类在 WiC、MultiRC、RTE 和 ReCoRD 上的表现估计。对于其余的任务,包括诊断集,我们通过亚马逊的Mechanical Turkplatform雇用众包注释员来重新注释每个测试集的样本,从而估计人类的表现。 我们遵循一个两步程序,其中众包工作者在进入注释阶段之前完成一个简短的训练阶段,该阶段以 Nangia 和 Bowman (2019) 用于 GLUE 的方法为模型。
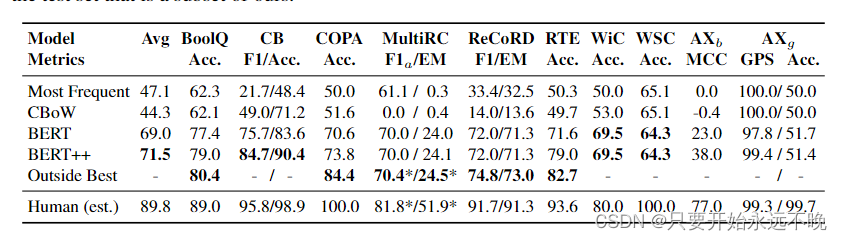
上表显示了所有基线的结果。最常见的类和 CBOW 基线总体表现不佳,在一些任务中实现了近乎偶然的性能。 使用 BERT 可将 SuperGLUE 的平均得分提高 25 分,在所有基准测试任务上都取得了显着的收益,尤其是 MultiRC、ReCoRD 和 RTE。在WSC上,BERT实际上比简单基线更差,这可能是由于数据集规模小且缺乏数据增强。使用 MultiNLI 作为 BoolQ、CB 和 RTE 的额外监督来源,可使所有任务提高 2-5 分。使用 SWAG 作为 COPA 的转移任务可提高 8 分。我们的最佳基线仍然远远落后于人类的表现。平均而言,BERT++与人类表现之间存在近20个百分点的差距。最大的差距是在WSC上,最佳模型和人类表现之间有35分的差距。 最小的利润是 BoolQ、CB、RTE 和 WiC,每个点的差距都在 10 点左右。我们相信,要弥合这些差距将具有挑战性:在WSC和COPA上,人类的表现是完美的。在其他三项任务中,它处于 90 年代的中高水平。在诊断方面,所有模型都继续明显落后于人类。尽管所有模型在 Winogender 上都获得了接近完美的性别均等分数,但这是因为它们获得了接近随机猜测的准确性 。
结论
我们提出了SuperGLUE,一种评估通用语言理解系统的新基准。SuperGLUE 通过识别一组新的具有挑战性的 NLU任务来更新 GLUE 基准,这些任务通过人类和机器基线之间的差异来衡量。我们基准测试中的八项任务集强调不同的任务格式和低数据训练数据任务,其中近一半的任务的样本少于 1k,除一项任务外,所有任务的样本数都少于 10k。我们评估了基于BERT的基线,发现它们仍然落后于人类近20个百分点。鉴于 SuperGLUE 在 BERT 中的难度,我们预计在多任务、转移和无监督/自监督学习技术方面的进一步进展将是必要的,以在基准测试上接近人类水平。总的来说,我们认为SuperGLUE为开发新的通用语言理解机器学习方法的工作提供了一个丰富且具有挑战性的测试平台。

















 374
374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









