







思维链(CoT)提示工程是生成式AI(GenAI)中一种强大的方法,它能让模型通过逐步推理来解决复杂任务。通过构建引导模型思考过程的提示,思维链能提高输出的准确性、连贯性和可靠性。本白皮书探讨了思维链提示工程的核心设计原则,提供实用案例,并概述了在各种应用中有效实施思维链的策略。
生成式AI系统越来越多地用于需要逻辑推理、多步骤问题解决和上下文理解的任务。传统的提示方法往往导致输出缺乏深度或无法满足任务的复杂性。思维链提示工程通过让AI系统模拟逐步推理来解决这一问题,从而产生更有结构性和可靠性的输出。
思维链提示工程在制造业、教育、金融和医疗保健等多个领域都有应用。这种方法利用模型的固有能力来逻辑地处理和排序信息,使响应与用户目标保持一致。
思维链提示工程的关键原则
1. 将复杂任务分解为子任务
设计技巧
- 原则:将复杂目标分解为可管理的步骤。
- 关注逻辑顺序:确保每个子任务自然地流向下一个。这创造了一个连贯的问题解决过程,防止AI推理中出现逻辑漏洞。
- 精细度很重要:子任务应该具体且可操作。避免过于宽泛的步骤,那可能会让AI感到困惑。
- 迭代优化:定义子任务后,与AI一起模拟任务,并在必要时优化分解结构,以提高清晰度和全面性。
- 好处:增强清晰度并确保回答全面。
- 例子:不要简单提示"诊断汽车引擎问题的步骤是什么?“,而是使用"第1步:识别问题的症状。第2步:列出可能的原因。第3步:推荐诊断测试。”
2. 鼓励逐步推理
设计技巧
- 原则:通过明确要求中间步骤,提示模型按顺序思考。
- 明确的提示:清楚地指导AI按顺序思考问题。使用强调中间步骤的语言,如"解释你是如何得出这个答案的。"
- 验证中间输出:鼓励AI自我检查每一步。例如,完成计算后,提示它"确认这个中间结果是否与提供的输入一致。"
- 加强逻辑进展:确保每一步都合理地建立在前一步的基础上。避免跳过步骤,即使对人类用户来说这些步骤看起来很明显。
- 迭代测试:通过在不同场景中测试模型的响应并根据观察到的弱点调整提示,验证逐步说明的有效性。
- 好处:减少逻辑和计算任务中的错误。
- 例子:解决数学问题时,使用"345 × 67等于多少?首先,将其分解为345 × 60和345 × 7。然后,把结果相加。"
3. 提供背景和约束
设计技巧
- 原则:包括相关细节和边界,以集中模型的推理。
- 目标明确:清楚说明任务的目的和预期结果。这确保模型能够明确理解问题,不产生歧义。
- 仅提供相关细节:仅包含与任务直接相关的信息,避免不相关的数据分散或混淆AI。
- 设定边界:指定时间、预算或范围等约束。例如,“在2周的时间内,提出增加社交媒体参与度的策略。”
- 避免过载背景:虽然提供背景至关重要,但过多的细节可能会让模型不堪重负,降低输出质量。
- 迭代背景测试:通过测试响应来完善提供的背景细节。如果输出不相关,逐步调整输入背景以找出改进领域。
- 好处:确保输出相关且可操作。
- 例子:当询问商业策略时,明确指出:“考虑100万美元的预算,为一家科技初创公司推荐营销计划。”
4. 使用示例进行少样本学习
设计技巧
- 原则:提供推理路径的例子来指导模型。
- 选择代表性例子:选择能反映模型将遇到的任务多样性和复杂性的例子。确保这些例子简洁但全面。
- 按逻辑顺序排列示例:排序示例以展示渐进式推理或逐渐增加难度的场景,以建立理解。
- 解释推理路径:清楚地注释每个例子,以展示思考过程,帮助模型调整其推理。
- 平衡特定性与一般性:提供足够具体指导推理但又足够通用以避免模型过度拟合狭窄场景的例子。
- 迭代示例调整:根据模型响应的质量持续评估和更新示例,确保它们保持有效。
- 好处:通过将响应与期望的推理模式对齐,提高模型性能。
- 例子:展示一个已解决的例子:“如果火车在2小时内行驶60英里,速度是30英里/小时。现在,解决这个问题:如果火车在4小时内行驶120英里,速度是多少?”
5. 提示的迭代优化
设计技巧
- 原则:通过迭代反馈测试和优化提示。
- 有效性测试:首先在不同场景中测试初始提示,以评估清晰度、相关性和结果一致性。
- 整合用户反馈:使用用户或利益相关者的反馈来识别响应中的歧义或误解。
- 渐进式优化:根据测试结果迭代修改提示。例如,将模糊的短语如"改善沟通"精确为"列出三种改善虚拟会议中团队沟通的方法。"
- 监控输出质量:分析生成的响应的连贯性、逻辑进展和与预期目标的一致性。
- 尝试变体:探索替代的表述、结构或额外背景,以提高模型的理解。
- 自动评估指标:使用工具或框架来衡量提示的有效性,如准确率、召回率或用户满意度。
- 好处:确保提示不断发展,以获得精确、高质量的响应,适应特定用例。
- 例子:如果初始提示"提供营销计划"导致泛泛而谈的输出,将其优化为"为针对千禧一代受众的新产品开发3步营销策略。"
- 例子:如果对"列出改善团队协作的步骤"的回答很模糊,将其优化为"列出五个在混合工作环境中改善团队协作的可行步骤。"
思维链提示工程的应用
1. 制造业和自动化
场景:优化生产流程。例子:一家制造厂由于装配线上的设备瓶颈而经常出现生产延迟。使用思维链提示工程,AI的引导如下:
- 第1步:识别瓶颈。
- 第2步:建议流程改进。
- 第3步:估算成本节约。
结果:这种逐步推理使得见解可操作,从而提高效率并带来可衡量的成本降低。
实施:提示AI通过优化进行推理:"第1步:识别瓶颈。第2步:建议流程改进。第3步:估算成本节约。"成果:提高运营效率和成本效益。
2. 教育和培训
场景:为数学或物理等复杂学科设计辅导系统。例子:
- 目标:创建一个关于如何解二次方程的逐步解释。
- 提示:“解释如何解二次方程x² - 5x + 6 = 0。首先分解因式,然后找出根。”
- AI回应:"解决x² - 5x + 6 = 0:
- 结果:逐步推理为学生澄清了过程,增强了理解并建立了解决类似问题的信心。
实施:使用思维链提示AI逐步解释解决方案,如推导公式或解方程。成果:通过详细和逻辑的解释增强学习体验。
通过DeepSeek-R1生成问题的思维链
我们可以将一些指令数据集的问题,请求DeepSeek-R1模型然后拿到reasoning_content当做思维链,下面是一个示例代码:
from openai import OpenAI
import os
from dotenv import load_dotenv
load_dotenv()
for key, value in os.environ.items():
print(f"{key} = {value}")
client = OpenAI(
# 替换为您需要调用的模型服务Base Url
base_url=os.environ.get("BASE_URL"),
# 环境变量中配置您的API Key
api_key=os.environ.get("ARK_API_KEY")
)
print("----- standard request -----")
completion = client.chat.completions.create(
model="deepseek-r1-250120",
messages = [
{"role": "system", "content": "你是豆包,是由字节跳动开发的 AI 人工智能助手"},
{"role": "user", "content": "常见的十字花科植物有哪些?"},
],
)
print(completion)
print("reasoning_content:\n",completion.choices[0].message.reasoning_content)
print("------"*100)
print("content:\n")
print(completion.choices[0].message.content)
思维链内容如下:
reasoning_content:
好的,我现在要回答用户关于常见十字花科植物的问题。首先,我需要确认十字花科植物的主要特征和分类。十字花科,学名Brassicaceae,以前也叫Cruciferae,所以有时会看到这两个名字交替使用。这个科的植物通常有四个花瓣,排列成十字形,因此得名。
接下来,我需要回忆常见的十字花科植物有哪些。首先想到的是蔬菜类,比如卷心菜、花椰菜、西兰花、芥菜、萝卜、油菜等。这些都是餐桌上常见的蔬菜,用户可能对它们比较熟悉。然后,还有调味料类的植物,比如芥末,它的种子用来制作芥末酱,这也是十字花科的。
另外,还有一些油料作物,比如油菜籽,用来榨油,这也是十字花科的重要经济作物。然后可能还有观赏植物,比如紫罗兰,虽然紫罗兰可能不像前面那些那么常见,但确实属于十字花科。
不过,我需要确认这些植物的分类是否正确。例如,油菜、卷心菜、花椰菜、西兰花、甘蓝都属于同一属,即芸苔属(Brassica)。而萝卜属于萝卜属(Raphanus)。芥菜包括不同的种,比如芥菜(Brassica juncea)和白芥(Sinapis alba)。此外,芝麻菜(Eruca sativa)也是十字花科的,可能用户也会提到。
还有,十字花科的一些植物可能在不同地区有不同的名称或常见程度,比如羽衣甘蓝(kale)现在在健康饮食中比较流行,也应该被包括进去。另外,大头菜(kohlrabi)、芜菁(turnip)也是十字花科的成员。
需要注意的是,有些植物虽然名字里有“菜”或者类似的名字,但不一定属于十字花科。例如,菠菜属于藜科,甜菜属于苋科,所以需要避免混淆。
在回答时,应该将这些植物分类,比如蔬菜类、调味料类、油料作物、观赏植物等,这样用户更容易理解。同时,可以简要提到它们的用途,比如食用、榨油或观赏,增加信息的实用性。
另外,可能需要提到十字花科植物的一些共同特点,比如富含硫代葡萄糖苷,这种物质被认为具有抗癌作用,这也是为什么这些蔬菜常被推荐为健康食品的原因之一。不过,用户的问题可能只需要列举种类,但稍微提一下它们的营养价值可能也有帮助。
最后,检查是否有遗漏的常见种类,比如水芹(Nasturtium officinale)属于十字花科吗?是的,水田芥(watercress)是十字花科的。还有,辣根(horseradish)也是,属于Armoracia属。
总结一下,常见的十字花科植物应包括:
蔬菜类:卷心菜、花椰菜、西兰花、甘蓝、羽衣甘蓝、芥菜、萝卜、大头菜、芜菁、芝麻菜、水田芥、辣根。
油料类:油菜(油菜籽)。
调味料:芥末(包括白芥和黑芥)。
观赏类:紫罗兰。
需要确保这些都属于十字花科,没有错误。例如,确认紫罗兰确实是十字花科的,可能有些用户会误以为是其他科。另外,辣根的正确学名是Armoracia rusticana,属于十字花科。
这样整理后,回答应该全面且准确,同时分类清晰,便于用户理解。
答案内容如下:
常见的十字花科(Brassicaceae)植物种类丰富,涵盖蔬菜、油料作物、调味料和观赏植物等,以下是主要分类及代表性物种:
---
### 🌱 **常见蔬菜类**
1. **芸苔属(Brassica)**
- **卷心菜**(甘蓝)、**花椰菜**、**西兰花**、**羽衣甘蓝**、**芥菜**、**大头菜**(苤蓝)、**芜菁**(Turnip)。
2. **萝卜属(Raphanus)**
- **萝卜**(白萝卜、樱桃萝卜等)。
3. **其他属**
- **芝麻菜**(火箭菜,*Eruca sativa*)、**水田芥**(西洋菜,*Nasturtium officinale*)、**辣根**(*Armoracia rusticana*)。
---
### 🌾 **油料作物**
- **油菜**(*Brassica napus*):种子榨油(菜籽油),广泛用于食用油和生物柴油。
---
### 🌶️ **调味料**
- **芥末**:原料包括**白芥**(*Sinapis alba*)和**黑芥**(*Brassica nigra*)的种子。
- **辣根**:根茎磨碎后用作调味品。
---
### 🌸 **观赏植物**
- **紫罗兰**(*Matthiola*)、**香雪球**(*Lobularia maritima*)。
---
### 🌟 **特点与营养价值**
十字花科植物的共同特征是**四瓣十字形花**,多数富含**硫代葡萄糖苷**(glucosinolates),代谢产物(如萝卜硫素)具有抗氧化、抗炎及潜在抗癌作用,因此常被视为健康蔬菜。
**注意**:菠菜(藜科)、甜菜(苋科)虽名称类似,但非十字花科植物。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
大模型目前在人工智能领域可以说正处于一种“炙手可热”的状态,吸引了很多人的关注和兴趣,也有很多新人小白想要学习入门大模型,那么,如何入门大模型呢?
下面给大家分享一份2025最新版的大模型学习路线,帮助新人小白更系统、更快速的学习大模型!
*有需要完整版学习路线*,可以微信扫描下方二维码,立即免费领取!

一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。
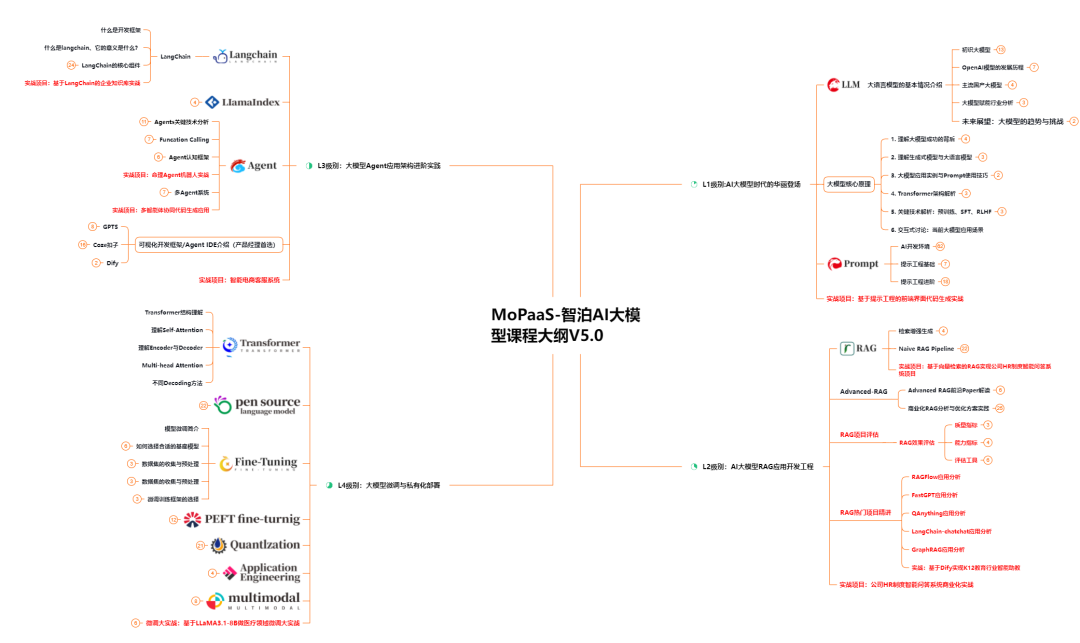
L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。
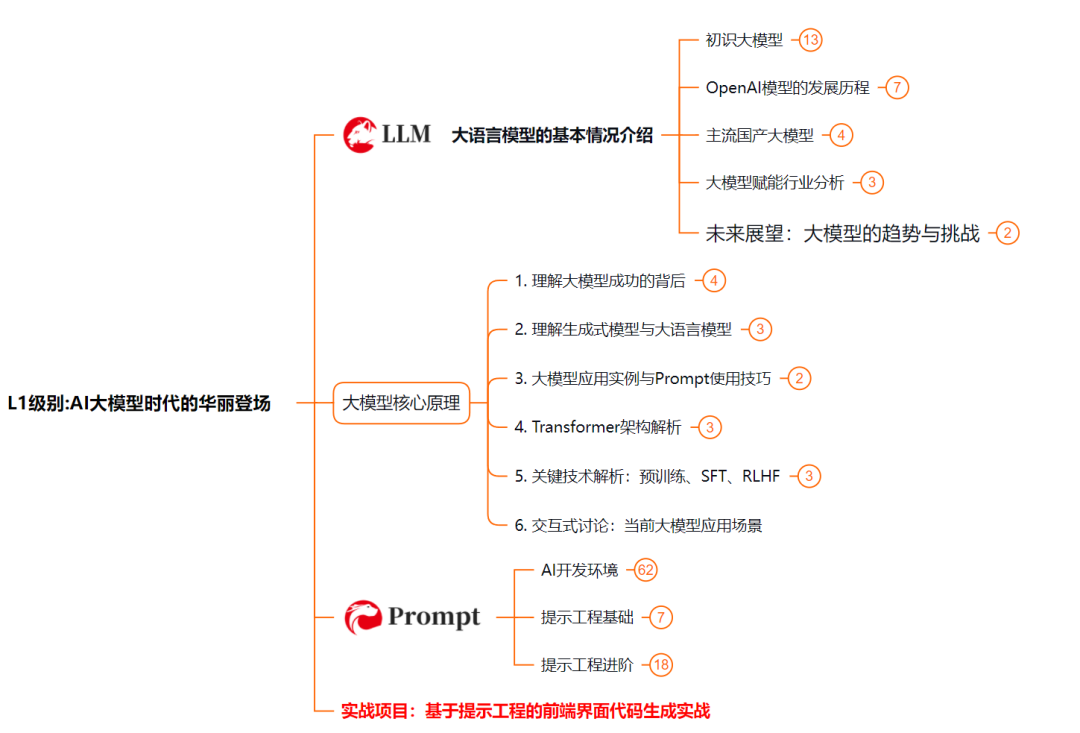
L2级别:AI大模型RAG应用开发工程
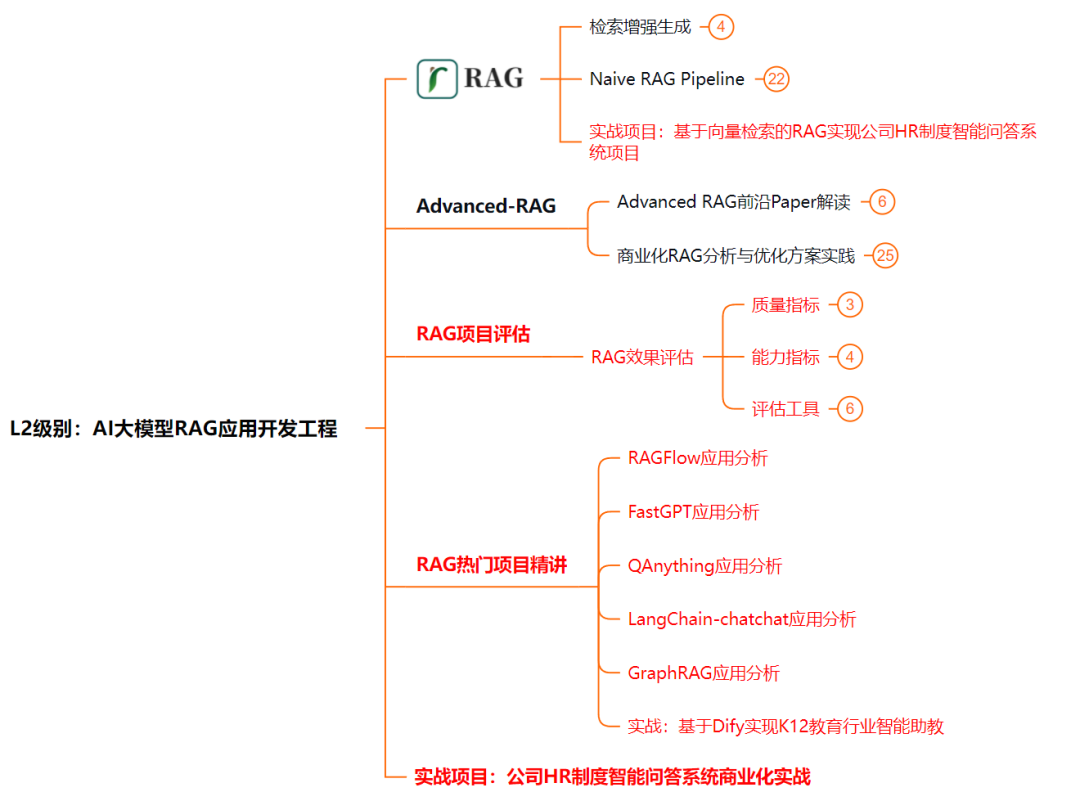
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。
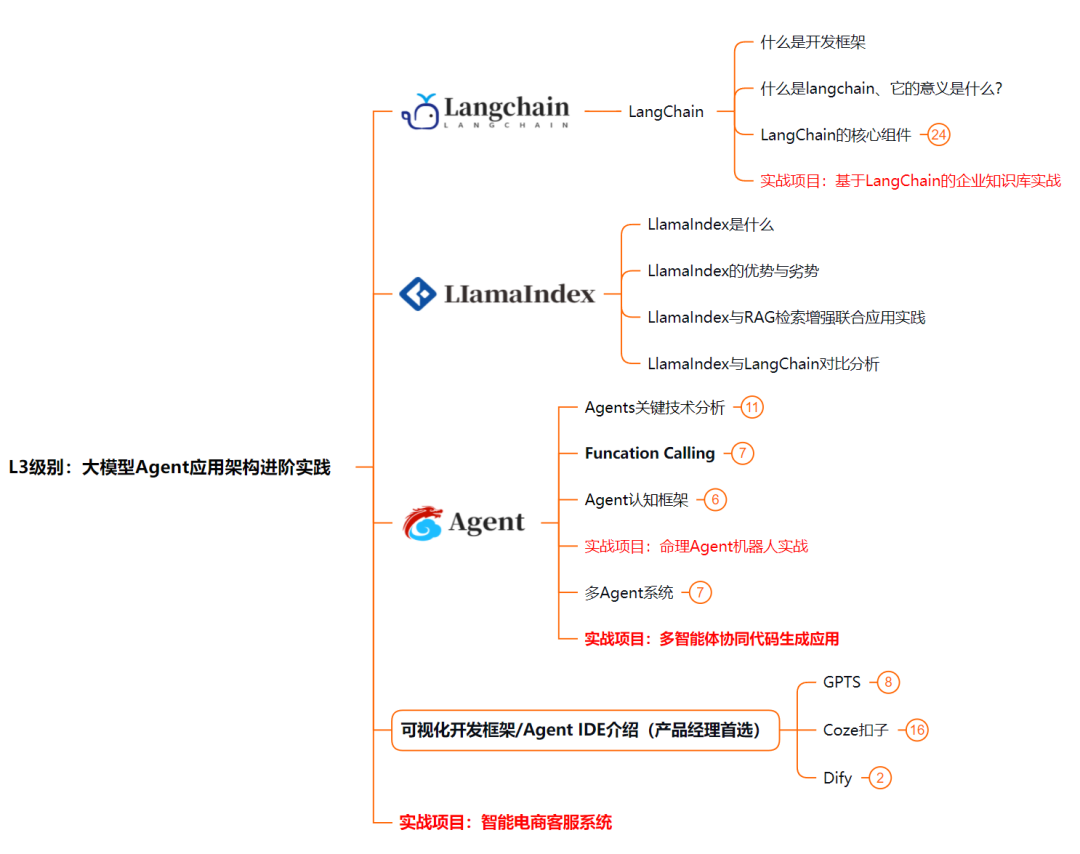
L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。
L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。
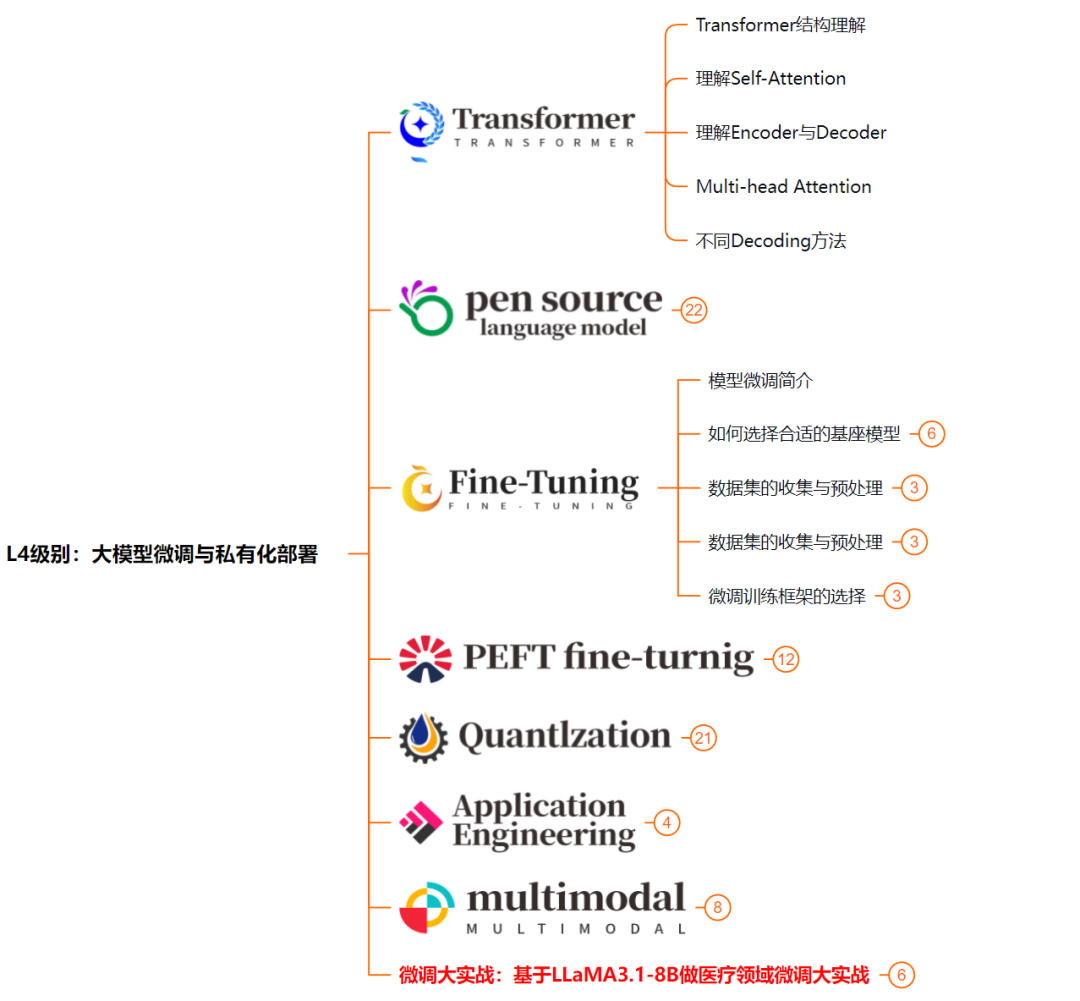
整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。
四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。
五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

****如果这篇文章对你有所帮助,还请花费2秒的时间**点个赞+收藏+分享,**让更多的人看到这篇文章,帮助他们走出误区。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









