







发布时间: 2025年3月19日
官方Git: https://github.com/NVIDIA/Isaac-GR00T/
论文pdf: https://d1qx31qr3h6wln.cloudfront.net/publications/GR00T_1_Whitepaper.pdf
中文翻译:VLA 论文精读(二)GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
模型下载:https://huggingface.co/nvidia/GR00T-N1-2B
B站视频【NVIDIA发布 https://www.bilibili.com/video/BV16DZoYEES6/

简介
GR00T:全称为 Generalist Robot 00 Technology(通用机器人00技术)
全球首个开源且完全可定制的基础模型 NVIDIA Isaac GR00T N1,该模型接受包括语言和图像在内的多模态输入,以在不同的环境中执行操作任务,可赋能通用人形机器人实现推理及各项技能。
GR00T N1 可以轻松地实现各种常见任务 (例如抓取、用一只或两只手臂移动物体以及将物品从一只手臂转移到另一只手臂) ,也可以执行需要较长背景和常规技能组合的多步骤任务。这些功能可应用于多个用例,包括物料搬运、包装和检查。
核心功能与架构设计
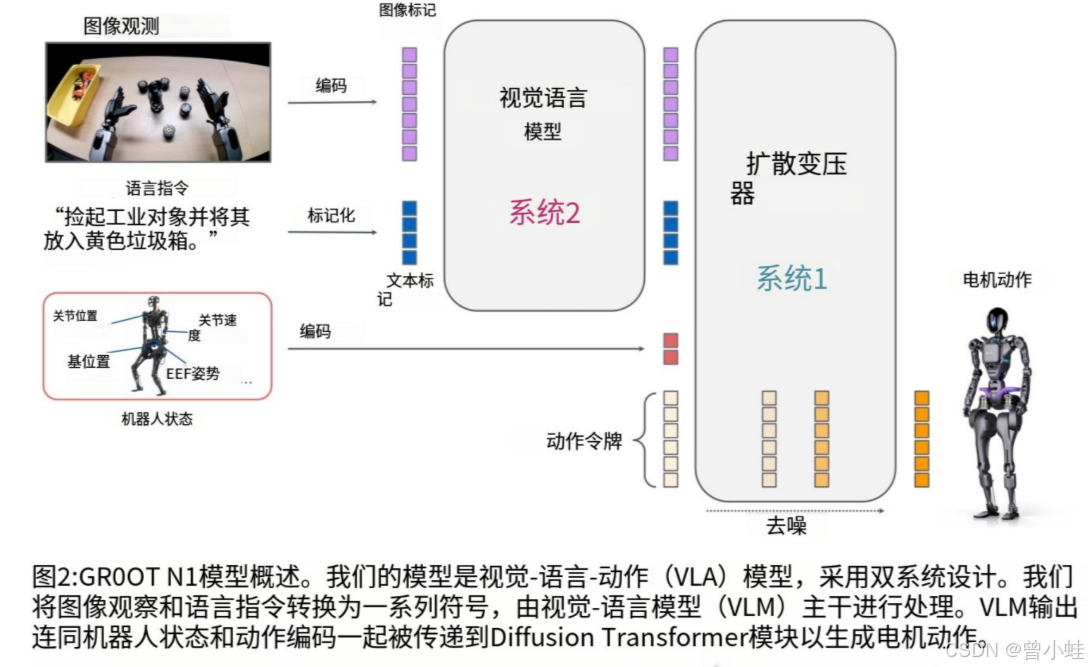
此架构模仿人类认知的“双系统理论”,兼顾实时控制与复杂决策,显著提升机器人通用性
系统1(快思考):
基于扩散变换器(Diffusion Transformer)的动作生成模型,负责快速响应环境变化并执行精确运动(如抓取、避障)
系统2(慢思考):
由视觉语言模型(VLM)驱动的推理与规划模块,支持语言指令解析、长上下文任务分解(如多步骤搬运)
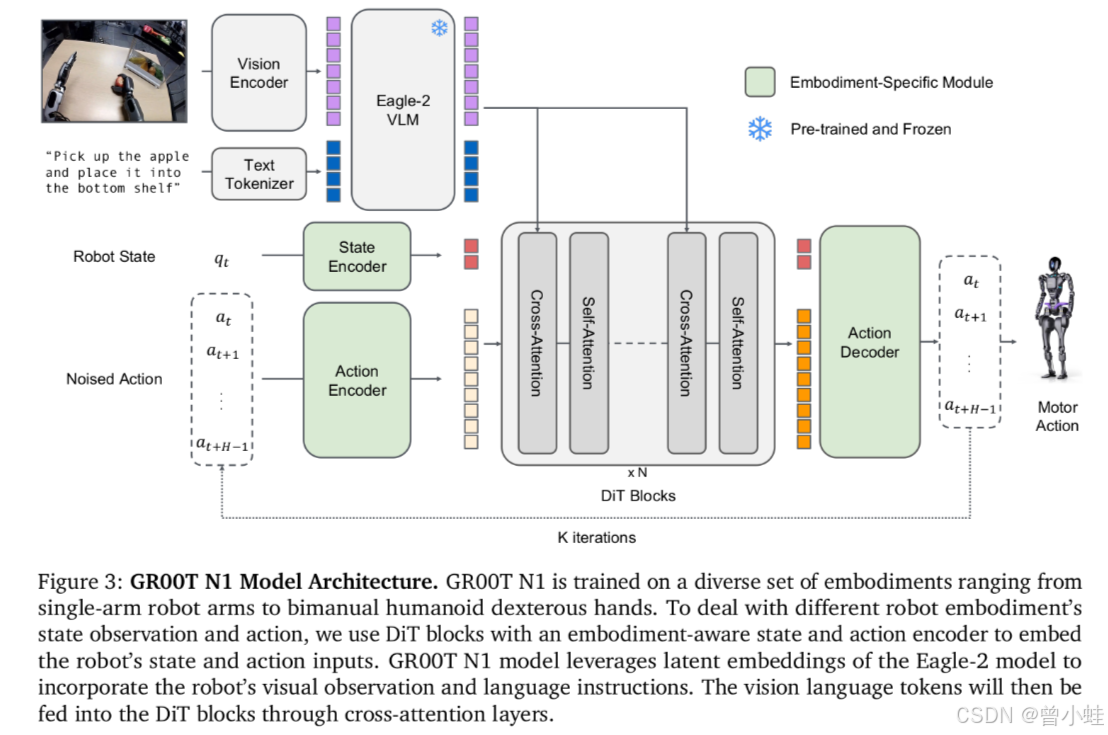
进一步的架构图3:GRO0TN1模型架构。
GROOTN1在从单臂机械臂到双人手型灵巧手的各种化身上进行训练。为了处理不同机器人化身的状态观察和动作,我们使用DiT块,其中包含一个化身意识的状态和动作编码器,以嵌入机器人的状态和动作输入。GROOTN1模型利用Eagle-2模型的潜在嵌入,以整合机器人的视觉观察和语言指令。然后,视觉语言令牌将通过交叉注意力层馈送到DiT
数据策略与训练方法
底层:大规模互联网视频数据(如人类操作视频),提供基础行为模式
中层:Omniverse生成的合成数据(如模拟工厂场景),加速训练并降低成本
顶层:真实机器人遥操作数据,弥合仿真与现实的差距
合成数据优势: 通过 GR00T Blueprint 工具,11小时可生成等效9个月的人类演示数据,使模型训练效率提升40%
技术突破与意义
通用性:通过单一模型适配多机器人硬件(如Fourier GR-1、1X Neo)
适应性:支持少量真实数据微调,快速迁移至新任务和环境
产业价值:加速人形机器人在制造业、医疗等领域的商业化落地,应对全球劳动力短缺问题



















 445
445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











