









总结自视频(吴恩达大模型入门课):8_12_generative-configuration_哔哩哔哩_bilibili
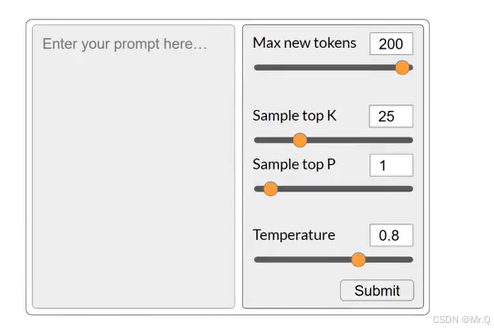
影响模型推理结果的参数:
Max new tokens: 200, 限制了模型生成的新token数量,防止生成过长或无用的内容。限制回复长度,比如在聊天应用中,限制回复长度可以提升用户体验,避免资源浪费。
Sample top K: 25,控制生成过程中的采样策略,top k是选择概率最高的前k个token;

如上图,模型生成了字典大小长度的概率分布,top k只在前k个大小概率中,按照概率加权随机选择一个作为生成的token。这样可以是生成的结果具有随机性,同时防止过于随机,生成一些不太可能完成的句子。
Sample top P: 1,基于累积概率选择token,前面累计概率不超过P,从这几个里面随机选择;
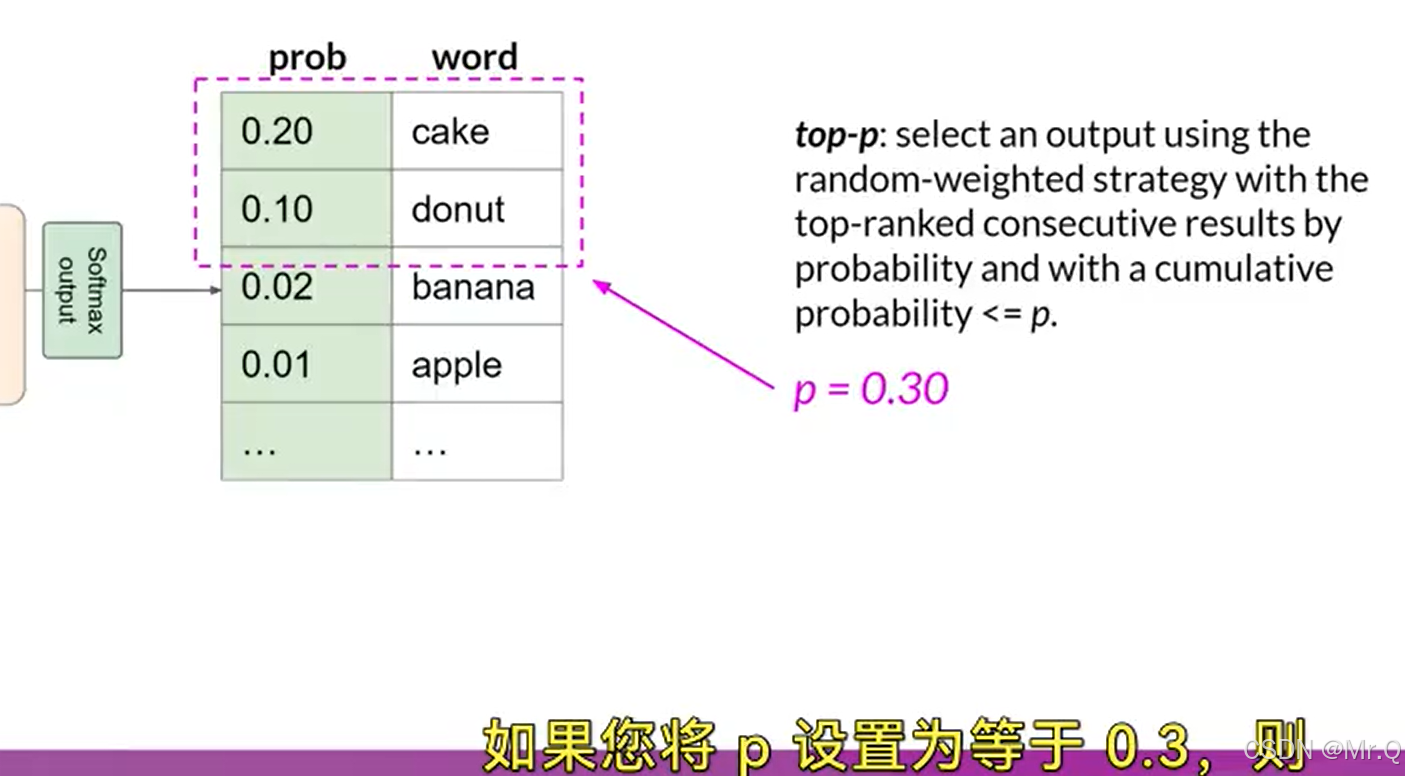
比如设置P=0.3,则累积概率到donut,再往后就超过了,从前面两个选择一个。
Temperature: 0.8,温度越高,随机性越高,温度是一个缩放系数,调整softmax输出结果。

小于1,越小,概率分布越集中,随机性降低;
大于1,越大,概率分布较为平缓,多个tokens被选中的概率值相当,随机性增强。



















 489
489

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











