







DeepSeek 是近年来备受关注的 AI 研究团队,推出了一系列先进的深度学习模型,涵盖了大语言模型(LLM)、代码生成模型、多模态模型等多个领域。本文将大概介绍 DeepSeek 旗下的不同类别的模型,帮助你更好地理解它们的特点和应用场景。
DeepSeek官网:DeepSeek
Deepseek在Huggingface的地址:https://huggingface.co/deepseek-ai
1. DeepSeek LLM(大语言模型)
DeepSeek LLM 是 DeepSeek 推出的通用大语言模型,主要用于文本生成、文本理解、对话交互等任务。这些模型采用 Transformer 架构,并经过大规模的预训练和指令微调,以提供更自然、智能的文本处理能力。
主要特性:
- 支持多种任务:问答、文本补全、翻译等。
- 经过 RLHF(人类反馈强化学习)优化,提高回答质量。
- 适用于各种 NLP 任务,如聊天机器人、智能客服、文本摘要等。
训练方式:它是在包含 2 万亿个英文和中文标记的庞大数据集上从头开始训练的。
论文地址: [2401.02954] DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
2. DeepSeek Coder(代码生成模型)
DeepSeek Coder是针对编程任务优化的代码生成和理解模型,可用于代码补全、代码解释、自动修复等。
主要特性:
- 支持多种编程语言,如 Python、Java、C++、JavaScript 等。
- 能够基于自然语言描述生成代码,提升开发效率。
- 代码补全和重构能力强,可用于 IDE 插件或自动化开发工具。
训练方式:基于DeepSeek LLM 模型继续运行得到的。
3. DeepSeek-VL(多模态模型)
DeepSeek-VL(Vision-Language) 是 DeepSeek 推出的多模态 AI 模型,能够处理文本、图像等不同模态的数据,实现跨模态的理解与生成。
主要特性:
- 能够根据文本生成图像,支持 AI 绘画任务。
- 具备图像理解能力,可以进行图片标注、OCR 识别等。
- 适用于 AIGC(人工智能生成内容)、数字创意等领域。
模型类别:DeepSeek-VL, DeepSeek-VL2
论文地址:[2403.05525] DeepSeek-VL: Towards Real-World Vision-Language Understanding
4. DeepSeek Math(数学推理模型)
DeepSeek Math 主要针对数学推理任务优化,适用于数学问题求解、公式推导、数学建模等任务。
主要特性:
- 适用于解方程、数学证明、数值计算等任务。
- 结合符号推理和深度学习,提高数学问题的解答能力。
- 可用于数学教育、科学研究等领域。
论文地址: [2402.03300] DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
5. DeepSeek Chat(对话模型)
DeepSeek Chat 是专门针对对话任务优化的聊天 AI,旨在提供更自然、更符合人类沟通习惯的交互体验。
主要特性:
- 经过 RLHF 训练,提高对话的连贯性和可控性。
- 适用于 AI 助手、智能客服、社交聊天等应用场景。
- 支持多轮对话记忆,提升用户体验。
6. DeepSeek MoE(专家混合模型)
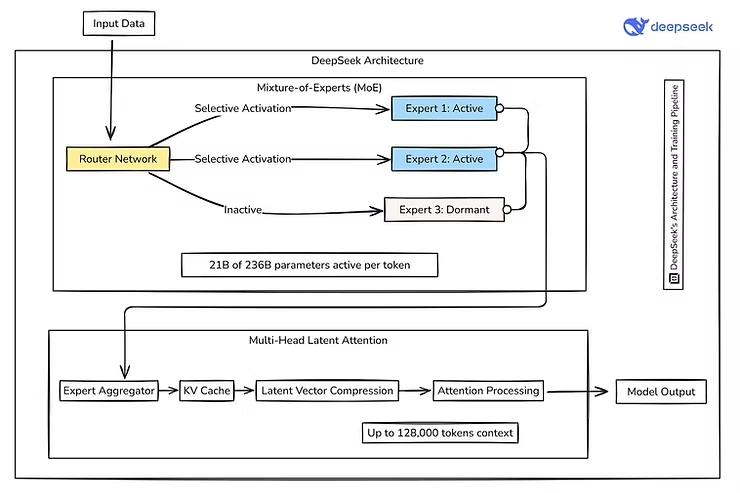
DeepSeek MoE(Mixture of Experts)采用专家混合架构,它只激活特定任务所需的子模型。这种设计提高了计算效率,降低了训练成本,这就是它的独特之处。在计算效率和模型能力之间取得平衡,适用于大规模推理任务。MOE相关的博客。
DeepSeek-V3 的训练总共使用了 2,788,000 H800 GPU小时,官方提到 DeepSeek 使用了 2048 块 H800 GPU 进行训练,因此:
这大约是 55~57 天,
主要特性:
- 采用 MoE 机制,提高计算效率。
- 适用于超大规模 NLP 任务。
- 结合多个子模型,根据任务动态分配计算资源。
不同版本, DeepSeek-V2, DeepSeek-V2-Lite, DeepSeek-V3 ....
7. DeepSeek-R1
基准模型:DeepSeek-R1-Zero 和 DeepSeek-R1 都是在DeepSeek-V3-Base模型的基础上训练出来的。

DeepSeek-R1-Zero
DeepSeek-R1-Zero 是一个通过大规模强化学习(RL)训练的模型,在训练过程中未使用监督微调(SFT)作为初步步骤,展现出了卓越的推理能力。通过强化学习,DeepSeek-R1-Zero 自然涌现出许多强大且有趣的推理行为,例如在 AIME 2024 数学竞赛中,其 pass@1 分数从 15.6% 提升至 71.0%,接近 OpenAI 的同类模型水平。训练过程中,模型展现了自我进化能力,如反思和重新评估解题方法。然而,DeepSeek-R1-Zero 也面临一些挑战,例如无尽重复(endless repetition)、可读性差(poor readability)以及语言混杂(language mixing)等问题。
为了解决这些问题并进一步提升推理能力,我们引入了 DeepSeek-R1,该模型在强化学习之前加入了冷启动数据(cold-start data)。DeepSeek-R1 在数学、编程和推理任务上的表现可与 OpenAI-o1 相媲美。
DeepSeek-R1
DeepSeek-R1 是 DeepSeek 开发的开源 AI 模型,在多个基准测试中表现出色,甚至超越了一些行业领先的模型。值得注意的是,DeepSeek-R1 的开发成本仅为 600 万美元,远低于其他大型 AI 模型的开发费用

8. DeepSeek-R1-Distill 模型
知识蒸馏(Distillation):小型模型也能强大
已被DeepSeek证明了,大型模型的推理模式可以被蒸馏到小型模型中,从而使其推理能力优于直接在小型模型上通过强化学习(RL)获得的推理模式。
利用 DeepSeek-R1 生成的推理数据,对多个广泛应用于研究领域的稠密模型进行了微调。评测结果表明,这些蒸馏后的小型稠密模型在基准测试中表现出色。DeepSeek向社区开源了基于 Qwen2.5 和 Llama3 系列的 1.5B、7B、8B、14B、32B 和 70B 规模的模型检查点,以促进研究与发展。

DeepSeek-R1-Distill 模型是在开源模型的基础上进行微调的,使用了 DeepSeek-R1 生成的样本。他们对其配置和分词器进行了轻微调整。请使用他们的设定来运行这些模型。
关于知识蒸馏的详细知识查阅我这篇博客。
总结
DeepSeek 在 AI 领域的研究覆盖多个重要方向,包括 NLP、代码生成、多模态 AI、数学推理等。无论是开发者、研究人员还是 AI 爱好者,都可以从这些模型中找到适合自己需求的工具。未来,DeepSeek 可能会推出更多创新模型,让我们拭目以待!
个人感觉DeepSeek的成功有以下几点。
1. 代码,开源和可访问性
2. R1-zero 强大的推理模型, 验证了不需要有监督微调(SFT)方法 + PPO模强化学习(RL)训练的方式,只用GRPO的强化学习训练方式也是可以的。
3. 知识蒸馏法,验证了大型模型的推理模式可以被蒸馏到小型模型中,从而使其推理能力优于直接在小型模型上通过强化学习(RL)获得的推理模式。
4. 训练与推理,华为 AI 芯片集成(Ascend 910C)。DeepSeek R1 在 华为 Ascend 910C AI 芯片 上运行推理任务。推理的时候不需要Nvidia。大大降低了费用。 训练期间用2000张NVIDIA H800 GPU (低性能相比于H100) 参考资料
5. 模型增强,对2020年中出现的GShard中的传统的MOE(Mixture of Experts) 有创新的改良, 它只激活特定任务所需的子模型。这种设计提高了计算效率,降低了训练成本,这就是它的独特之处。
6. DeepSeek-V3 的训练总共使用了 2,788,000 H800 GPU小时,官方提到 DeepSeek 使用了 2048 块 H800 GPU 进行训练. 这大约是 55~57 天.
相关论文
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
其它
DeepSeek-R1 和 DeepSeek-V3比较
尽管它们都属于大型语言模型,但在设计目标、训练方法和应用场景上存在显著差异。
1. DeepSeek-R1
-
设计目标:专注于推理任务,特别是在数学、代码生成和复杂逻辑推理领域。
-
训练方法:采用多阶段循环训练,包括基础训练、强化学习(RL)和微调的交替进行,以增强模型的深度思考能力。
-
应用场景:适用于需要深度推理的任务,如数学建模、代码生成和复杂逻辑推理等。
2. DeepSeek-V3
-
设计目标:追求高效的自然语言处理,强调模型的可扩展性和计算效率。
-
训练方法:基于混合专家(MoE)架构,结合广泛的训练数据,提供增强的性能能力。
-
应用场景:适用于大规模自然语言处理任务,特别是在多语言应用和需要高效计算的场景中表现出色。
主要区别
-
架构差异:DeepSeek-R1 强调通过强化学习提升推理能力,而 DeepSeek-V3 则采用 MoE 架构,注重模型的可扩展性和效率。
-
训练成本:DeepSeek-V3 的训练成本约为 DeepSeek-R1 的六分之一,体现了其在计算资源利用上的优势。
-
应用领域:DeepSeek-R1 更适合需要深度推理的专业领域,而 DeepSeek-V3 则适用于广泛的自然语言处理任务。
总的来说,DeepSeek-R1 和 DeepSeek-V3 各有优势,选择哪种模型取决于具体的应用需求和场景


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











