







最近,突然想要用R来搞搞机器学习,这让我想起了一个被尘封的草稿,当初让我放弃使用R做嵌套交叉验证的想法。于是,决定好好完善一番再发出去。有些事情不捋清楚,它就会在将来的某个时候等着你,让你心神不宁。先从交叉验证开始。
交叉验证
交叉验证(Cross Validation; CV)用于检验机器学习的模型表现,选择模型。如下图显示的便是一个3-fold CV。其中loop都使用了相同的随机森林(RF)模型。
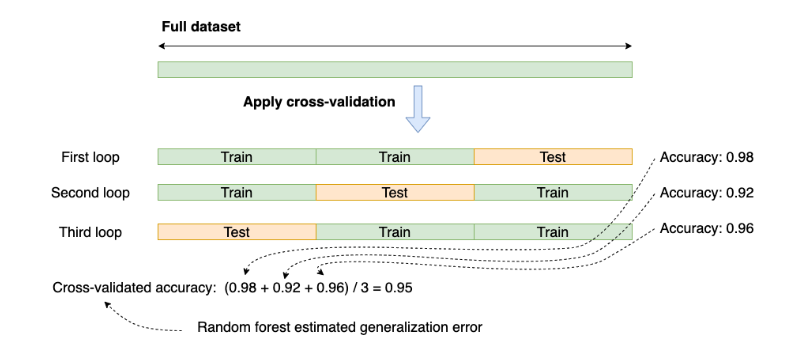
(https://ploomber.io/blog/nested-cv/)
使用同样的方法,可以对比不同模型的表现,例如,如果支持向量机(SVM)比随机森林(RF)的表现好,便选用支持向量机作为最终模型。同样地,每个loop都使用相同的模型超参数)。
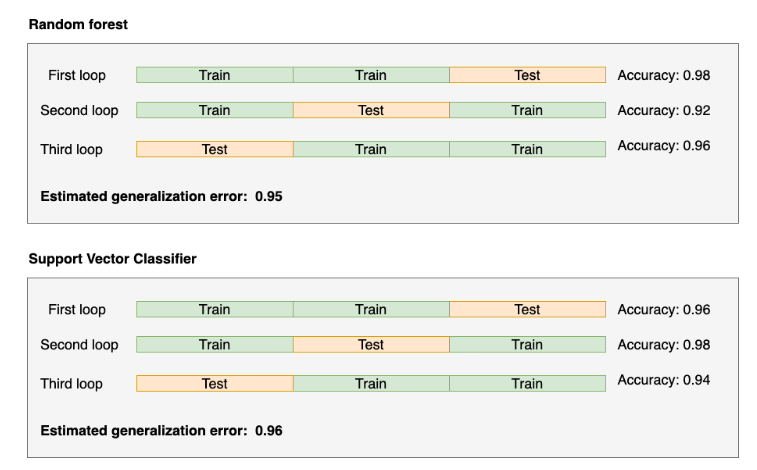
(https://ploomber.io/blog/nested-cv/)
机器学习的模型都会涉及超参数(hypoparameters),选择不同的超参数可能会让模型表现改变。因此做交叉验证也可以用于调参。
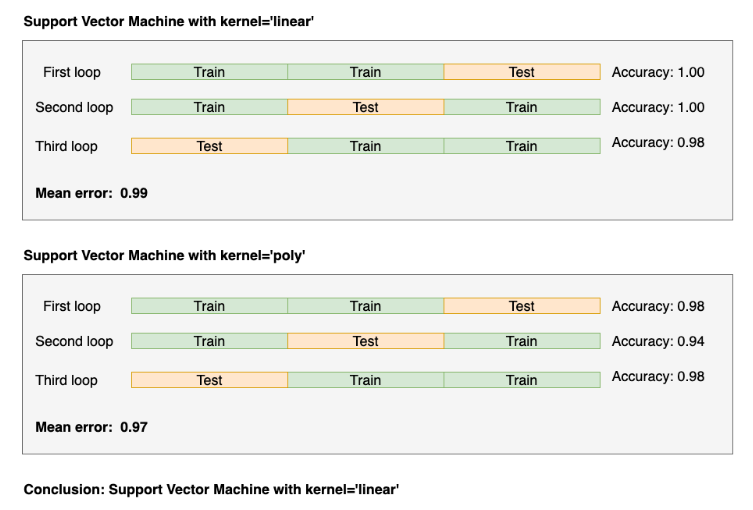
(https://ploomber.io/blog/nested-cv/)
例如,这里使用交叉验证的结果说明,支持向量机(SVM)选择线性(Linear)内核比非线性(i.e., Poly)内核表现更好。这样做潜在的问题是,一旦选择了表现最好的超参数,该模型的表现通常会被报告为最优模型。由于这里每一次交叉验证的循环中,都使用了相同的数据来调参,因此存在着严重的优化偏差(bias)问题,可能导致对模型表现的乐观估计。
嵌套交叉验证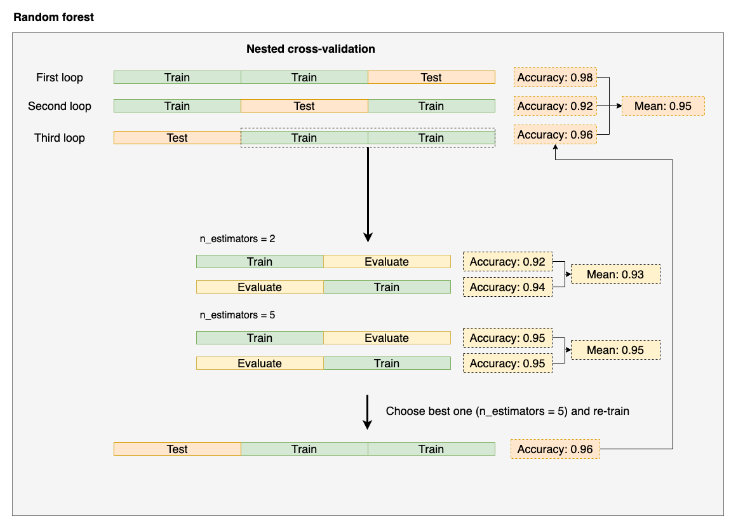
(https://ploomber.io/blog/nested-cv/)
如图所示,嵌套交叉验证进而将外层(outer)每个循环中的训练集再做一个k折交叉验证进行调参,这里调参的是n_estimations的数量,结果表示n_esimations=5的第三个fold的表现好,因此选择该参数的模型作为第三个fold的模型。实际中,可能会使用grid.search等策略对多种参数进行评估,每一个组合都会做一次k折交叉验证计算平均模型表现,最好的选为一个外层的最优模型。
重复交叉验证(Repeated CV)
由于在做k折交叉验证时,将数据一次划分为了k组,这样的划分存在随机性。有可能某一次划分会得到较好的结果,而另一次划分得到较差的结果。因此做重复交叉验证能减小由于将数据划分而造成的随机变化。
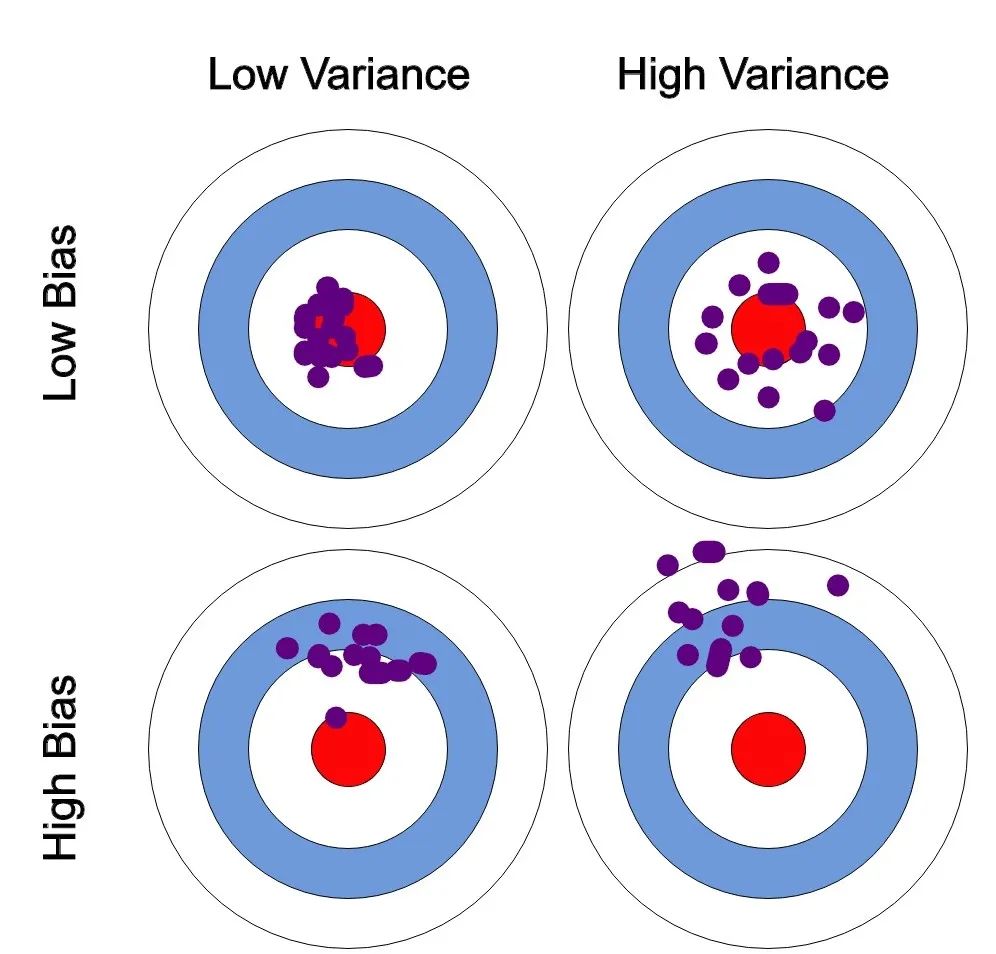
R中的交叉验证
实际看一下caret的文档,调参类似于Python中的GridSearchCV。

(https://topepo.github.io/caret/model-training-and-tuning.html)
例如使用重复交叉验证对一个SVM调参 输出如下:
输出如下:
(https://stats.stackexchange.com/questions/421701/tuning-svm-parameters-in-r)
输出的时候出现了Resampling,指的是对数据进行重采样的方式。交叉验证也算作一种重采样的方式。在trainControl的method中还有除了交叉验证的其他选项,例如resampling。
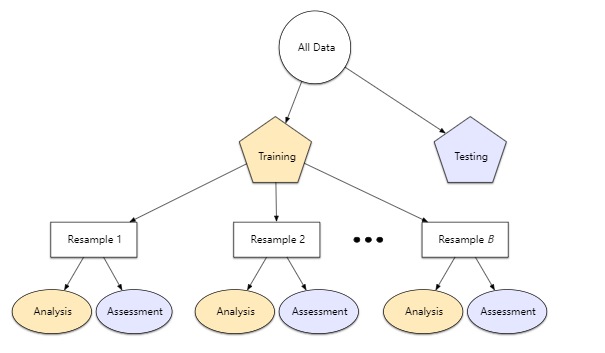 (http://appliedpredictivemodeling.com/blog/2017/9/2/njdc83d01pzysvvlgik02t5qnaljnd)
(http://appliedpredictivemodeling.com/blog/2017/9/2/njdc83d01pzysvvlgik02t5qnaljnd)
想在R中做Nested CV?
在R常用的工具包Caret并未提供Nested CV的做法,工具包作者首先质疑了做Nested CV的收益,然后加了工单。

随后又嫌麻烦,写了个相关的blog,要做嵌套的就照着做吧。
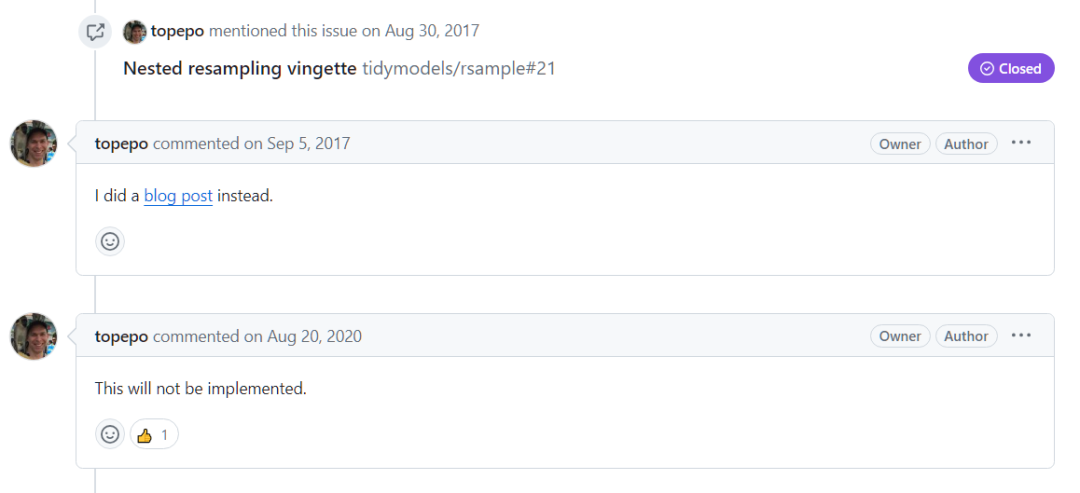
博客中,作者使用数据说明了做嵌套过程的收益其实不大。

(http://appliedpredictivemodeling.com/blog/2017/9/2/njdc83d01pzysvvlgik02t5qnaljnd)
类似的观点:


所以大部分时候,使用标准版的CV调参可以提高运行速度,对于200个参数组合,10-fold标准版CV计算量是2000,而10-fold嵌套CV的计算量则是20000。但是当参数数量>>样本量时就需要考虑嵌套交叉验证,Python很方便,在R中有以下几种思路:
在R中使用reticulate包调用Python代码。如果知道Python的嵌套怎么做,难度1星。
使用R工具包nestedcv,难度2星。
3. 手动增加外层循环或者参照caret作者的博客,难度4星。

(https://stats.stackexchange.com/questions/125843/outer-crossvalidation-cycle-in-caret-package-r)


















 225
225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









