







突然有人问的,感觉有很多东西值得研究,于是写一下;
在比较简单的说法中,我们可以把区别简单归结为三类
1.urp较Build in(内置管线)具有更自由的自定义渲染流程 -----更自由
2.urp具有兼容更多图形学API的特性,且具有基于物理渲染的系统功能(PBS) ----更全面
3.urp更加轻量级更适配移动端,主机端等多端开发,但某些渲染功能较难实现 ----更轻量
这么一看似乎urp要先进很多,事实上也确实如此,接下来的内容会进一步介绍这些内容。

两种管线的追根溯源
在这里我们不能只关注两种管线在功能层面上的区别,更多的要聚焦他们在底层渲染逻辑上的不同,因此呢,两种渲染管线的设计源头就值得我们研究。
SRP与Built in
众所周知(bushi),urp(Universal Render Pipeline)的前身是 LWRP(Lightweight Render Pipeline),也是SRP(Scriptable Render Pipeline)中提供的一个模板(类似于C++模板编程的概念?),这里需要着重介绍一下SRP的概念
什么是SRP
从它的英文全名便可以看出,SRP的最显著的特点便是可以自定义编程(Scriptable),是Unity提供的新渲染系统,可以在Unity通过C#脚本调用一系列API配置和执行渲染命令的方式来实现渲染流程,SRP将这些命令传递给Unity底层图形体系结构,然后再将指令发送给图形API。
说白了就是我们可以用SRP的API来创建自定义的渲染管线,可用来调整渲染流程或修改或增加功能。
它主要把渲染管线拆分成二层:
- 一层是比较底层的渲染API层,像OpenGL,D3D等相关的都封装起来。
- 另一层是渲染管线上层,上层代码使用C#(shaderlab)来编写。在C#这层不需要关注底层在不同平台上渲染API的差别,也不需要关注具体如何做一个Draw Call
即通过SRP我们可以精准的调用某些图形学的API来自定义我们的渲染流程,且开发者不太需要注意硬件层面的信息
Built in管线介绍
built in管线的渲染大致流程与urp相同(底层API均为OpenGL)即:
几何阶段:计算场景内物体和光照地信息,
光栅化阶段:由几何阶段渲染结束后,将3D场景转换成能映像到我们屏幕上的2D图像。即计算每一个像素点该呈现的颜色
后处理阶段:调整图像的亮度,为某一区域增加模糊效果、修改图像中部分像素的颜色等等
但在具体的渲染方面可能会有不同,后面会具体介绍
但built也具有一些缺点,也正是这些缺点,让SRP被开发了出来。比如无体积光与光线追踪的功能,但最重要的是无法自定义,只能在引擎内调用一些功能
总结
本质上说,SRP模式在C++端保留一个非常小的渲染内核,让C#端可以通过API暴露出更多的选择性,也就是说,Unity会提供一系列的C# API以及内置渲染管线的C#实现;这样一来,一方面可以保证C++端的代码都能严格通过各种白盒测试,另一方面C#端代码就可以在实际项目中调整。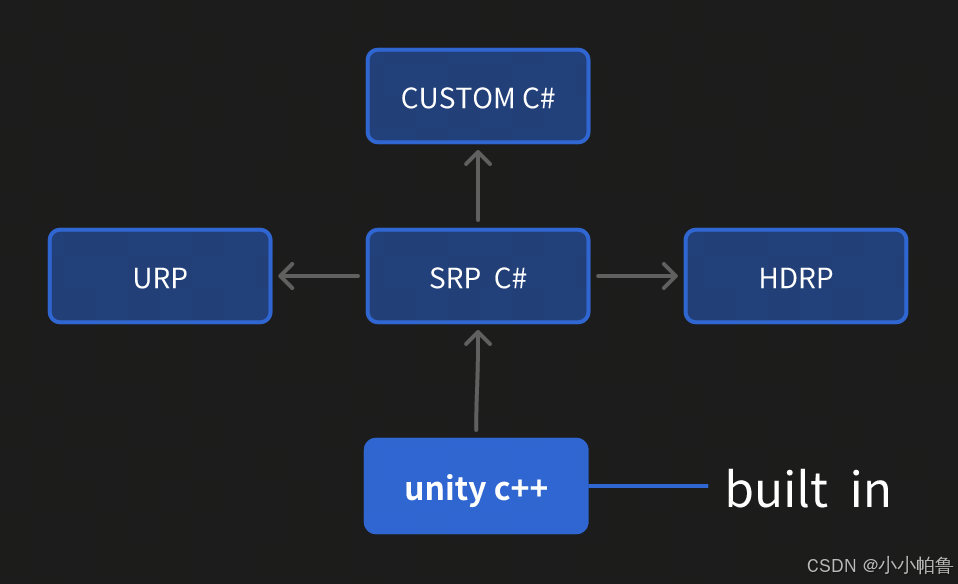
顺带一提,Unity 5.x版本对内置的管线着色器的导入和编译均以进行了优化,所有的固定管线着色器会在导入时被转换为顶点/片元着色器。
urp与built in 性能对比
接下来我们将通过一些主要的功能区别来介绍URP与Built in的不同(不全面)
光照
一言以蔽之,URP实现了单Pass的光照渲染,但于此同时的是,它对单个pass内灯光的数量进行了限制(其目的是限制Draw call的数量,使其在GPU的接受限制范围内),而built in中每多一个动态光源,都有可能新建一个Pass。
具体情况如下:
传统Bulidin渲染管线的光照是多Pass渲染,每多一个动态光就多一个Pass,这个光影响的物体就要多画一遍。eg:所有物体都受动态光影响,则m个动态光,n个物体,绘制次数m*n。
URP实现了单Pass渲染光照。也就是上面的例子,最后绘制只需要n次。但URP中限制了灯光的数量。目前是支持1詹平行光,每个对象最多只能接受4个动态光。
批处理
什么是批处理
要先讲清楚批处理,首先要搞清楚Draw call的概念,简单一下理解,就是CPU发出一个指令,让GPU去画(Draw),这是在渲染流程中的具体应用:
1. 把数据加载到显存中:把网格和纹理等数据从硬盘加载到显存中(因为显卡对显存的访问速度更快)
2. 设置渲染状态:CPU根据材质球设置渲染状态,比如,使用哪个顶点着色器/片元着色器、光源属性、纹理等
3. 调用Draw Call:准备好上述工作后,CPU就调用一个渲染命令(Draw Call)来告诉GPU可以开始渲染啦。
在具体的项目实施中,我们能不能把多个Draw call合并为一个,继而提升效率呢?这就是批处理的应用了,下面我们将介绍几种主要的批处理方法。
Static batching(静态批处理)
在游戏中不移动不旋转不缩放的物体可以被视为静态物体。 在检视面板,勾选【Static】以标记物体为静态物体。 使用相同材质引用的静态物体可以被静态批处理
静态批处理:将静态物体合并为一个大网格,从而以更快的速度渲染它们。不会减少DrawCall(误),但是会让CPU在“设置渲染状态-提交Draw Call”上更高效。
1.Unity将静态物体合并为一个(或多个)大网格,这个(或这些)大网格以vertex buffers和index buffers的形式存储在GPU上;
2.Unity按顺序绘制场景中的物体时,如果两个物体的数据属于同一块buffer,且在vertex buffer和index buffer上连续,那么这两个物体仅产生1次DrawCall;
3.如果它们不连续,那么将产生2次DrawCall(specify different regions of this buffer);但是由于它们属于同一块buffer,因此这2次DrawCall之间的GPU状态不发生改变,它们构成1次StaticBatch;虽然没有降低DrawCall次数,但是避免了重复的"buffer binding"——我对"buffer binding"的理解是:在shader开始执行前告诉shader这个是vertex buffer、这个是index buffer……
4.静态批处理不一定减少DrawCall,但是会让CPU在“设置渲染状态-提交Draw Call”上更高效;
Dynamic batching (动态批处理)
在运行时Unity自动把每一帧画面里符合条件的多个模型网格合并为一个,再传递给GPU
需符合的条件:
1. 使用相同材质引用的网格实例——只有使用相同材质球的Mesh才可以被批处理。
2. 物体之间Transform不能具有镜像关系——比如物体A的scale=+1,物体B的scale=-1,那就不能被批处理。
3. 着色器使用的顶点属性数量不能大于900——比如,漫反射计算需要使用顶点的“位置、法线、UV”这3种属性,所以模型的顶点数不能超过300;如果着色器需要使用顶点的“位置、法线、UV0、UV1和切向量”这5种属性,那就只能批处理180顶点以下的物体。
4. 材质的着色器不能依赖多个过程——多Pass的shader会中断批处理。
5. 网格实例应引用相同的光照纹理文件——如果物体使用光照纹理,需要保证它们指向光照纹理中的同一位置,才可以被动态批处理。
SRP的批处理技术
之前Unity支持:动态批处理,静态批处理,GPU Instancing。SRP在原来的基础上还支持SRP Batcher。SRP Batcher不会减少Draw Call数量,但可以减少Set Pass Call的数量。并减少绘制命令的开销。
减少绘制命令的开销的原因:CPU不需要每帧都给GPU发送渲染数据,如果数据没有变化,就保存在GPU内存中,每个绘制仅调用包含一个指向正确内存位置的偏移量。(值传递变成了引用传递?!)
减少Set Pass Call的原因:传统批处理的前提是同一材质,SRP的判断依据是Shader 变种是否变化,Shader变种相同,即使是不同材质都不会被打断。
底层原理:
SRP会在主存中将模型的坐标信息、材质信息、主光源信息阴影参数和非主光源阴影参数分别保存到不同的CBUFFER(常量缓冲区)中,只有CBUFFER发生变化才会重新提交到GPU并保存。
CBUFFER在Shader中就是包含各种声明的Property。所以支持CG的UnlitShader是不能使用SRP Batcher的。只有使用了名为UnityPerMaterial的CBUFFER才能使用SRP Batcher。
总结
URP与Built in在性能的具体表现方面有着很多的不同,这里不再过多赘述,下面是功能比较的具体图片

笔者声明
本人是刚接触技术美术的新新新手,很多观点若有问题请勘误,想要看什么也可留言,希望能够给大家讲清楚

















 1550
1550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









