






http://m.blog.csdn.net/article/details?id=50667290
【Ogre编程入门与进阶】第十六章 GPU编程
发表于2016/2/15 11:03:02 201人阅读
分类: OGRE2
从本章开始,将进入可编程流水线的学习。一般在图形渲染时可以通过两种途径来实现,一种称为固定功能流水线(Fixed Function Pipeline),另一种就是从本章开始要介绍的可编程流水线(Programmable Pipeline),使用可编程流水线技术进行的程序设计我们也可以称为GPU编程。
在前面的示例程序中我们所采用的方法都是固定功能流水线,当我们使用固定功能流水线时,我们通常是在程序中通过相应函数调用来设置不同的渲染状态。而使用可编程流水线技术,我们可以在源程序之外,编写另外的程序代码,直接操作顶点或像素,这样可以大大提高程序的灵活性。
16.1 GPU 图形绘制管线
首先,我们先来了解一下GPU渲染流程。图形绘制管线描述了GPU的渲染流程,即“给定视点、三维物体、光源、照明模式和纹理等元素,如何绘制一幅二维图像”。在计算机图形学中,通常将图形绘制管线分为三个主要阶段:应用程序阶段、几何阶段、光栅阶段。
应用程序阶段,使用高级编程语言(如C、C++、Java等)进行开发,主要和CPU、内存打交道,诸如碰撞检测、场景图建立、空间八叉树更新、视锥裁剪等都在此阶段执行。在该阶段的末端,几何体数据(顶点坐标、法向量、纹理坐标、纹理等)通过数据总线传送到图形硬件。
几何阶段,主要负责顶点坐标变换、光照、裁剪、投影以及屏幕映射,该阶段基于GPU进行运算,在该阶段的末端得到了经过变换和投影之后的顶点坐标、颜色以及纹理坐标。
光栅阶段,基于几何阶段的输出数据,为像素正确配色,以便绘制完整图像,该阶段进行的都是单个像素的操作,每个像素的信息存储在颜色缓冲器或帧缓冲器中。
值得注意的是:光照计算属于几何阶段,因为光照计算涉及视点、光源和物体的世界坐标,所以通常放在世界坐标系中进行计算;而雾化以及涉及物体透明度的计算属于光栅化阶段,因为上述两种计算都需要深度值信息(Z值),而深度值是在几何阶段中计算,并传递到光栅阶段的。
应用程序阶段我们一直在使用,相信我们都已经比较熟悉,下面我们具体阐述一下从几何阶段到光栅化阶段的流程。
几何阶段
几何阶段的主要工作是“变换三维顶点坐标”和“光照计算”,由于输入到计算机中的是一系列三维坐标点,但是我们最终需要看到的是从视点出发观察到的显示在二维屏幕上的点。一般情况下,GPU帮我们自动完成了这个转换。而基于GPU的顶点程序为开发人员提供了控制顶点坐标空间转换的方法。
根据顶点坐标变换的先后顺序,主要有如下几个坐标空间(或者说坐标类型):Object Space(模型坐标空间);World Space(世界坐标空间);Eye Space(观察坐标空间);Clip and Project Space(屏幕坐标空间)。下图中表述了GPU的整个处理流程,其中茶色区域所展示的就是顶点坐标空间的变化流程。

从object space 到world space
Object Space Coordinate就是模型文件中的顶点值,这些值是在模型建模时得到的,例如,用3DMAX建立一个球体模型并导出为.max文件,这个文件中包含的数据就是Object Space Coordinate,它与其它物体没有任何参照关系。而无论在现实世界,还是在计算机的虚拟空间中,物体都必须和一个固定的坐标原点进行参照才能确定自己所在的位置,这就是World Space Coordinate的实际意义所在。
毫无疑问,我们将一个模型导入计算机后,就应该给它一个相对于坐标原点的位置,那么这个位置就是World Space Coordinate,从Object Space Coordinate到World Space Coordinate的变换过程由一个四阶矩阵控制,通常称之为World Matrix。
光照计算通常是在世界坐标空间中进行的,这也符合人类的生活常识。当然,也可以在Eye Coordinate Space中得到相同的光照效果,因为,在同一观察空间中物体之间的相对关系是保存不变的。
需要高度注意的是:顶点法向量在模型文件中属于Object Space,在GPU的顶点程序中必须将法向量转换到World Space中才能使用,如同必须将顶点坐标从Object Space转换到World Space中一样,但两者的转换矩阵是不同的,准确的说,法向量从Object Space到World Space的转换矩阵是World Matrix的转置矩阵的逆矩阵(参阅潘李亮的3D变换中法向量变换矩阵的推导一文),可以阅读电子工业出版社的《计算机图形学(第二版)》第11 章,进一步了解三维顶点变换具体的计算方法,如果对矩阵运算感到陌生,则有必要复习一下线性代数。
从world space 到eye space
每个人都是从各自的视点出发观察这个世界,无论是主观世界还是客观世界。同样,在计算机中每次只能从唯一的视角出发渲染物体。在游戏中,都会提供视点漫游的功能,屏幕显示的内容随着视点的变换而变换。这是因为GPU将物体顶点坐标从World Space转换到了Eye Space。
所谓Eye Space,即以camera(视点或相机)为原点,由视线方向、视角和远近屏幕,共同组成一个梯形体的三维空间,称之为viewing frustum(视锥),如下图所示,近平面,是梯形体较小的矩形面,作为投影平面,远平面是梯形体较大的矩形,在这个梯形体中的所有顶点数据是可见的,而超过这个梯形体之外的场景数据,会被视点去除(Frustum Culling,也称之为视锥裁剪)。

从eye space 到project andclip space
一旦顶点坐标被转换到Eye Space中,就需要判断哪些点是视点可见的。位于viewing frustum梯形体以内的顶点,被认定为可见,而超出这个梯形体之外的场景数据会被视点去除(Frustum Culling,也称之为视锥裁剪)。这一步通常称之为“clip(裁剪)”,识别指定区域内或区域外的图形部分的过程称之为裁剪算法。
光栅化阶段
光栅化:决定哪些像素被集合图元覆盖的过程,经过上面诸多坐标转换之后,现在我们得到了每个点的屏幕坐标值,也知道我们需要绘制的图元(点、线、面)。但此时还存在两个问题:点的屏幕坐标值是浮点数,但像素都是由整数点来表示的,如何确定屏幕坐标值所对应的像素?在屏幕上需要绘制的有点、线、面,如何根据两个已经确定位置的两个像素点绘制一条线段,如何根据已经确定了位置的三个像素点绘制了一个三角形面片?
对于第一个问题,“绘制的位置只能接近两指定端点间的实际线段位置,例如,一条线段的位置是(10.48,20.51),转换为像素位置则是(10,21)”。
对于第二个问题,涉及到具体的画线算法,以及区域图元填充算法。通常的画线算法有DDA 算法、Bresenham 画线算法;区域图元填充算法有,扫描线多边形填充算法、边界填充算法等,具体请参阅计算机图形学中的相关内容。
这个过程结束之后,顶点以及绘制图元(线、面)已经对应到像素。下面阐述的是“如何处理像素,即:给像素赋予颜色值”。
Pixel Operation
Pixel operation 又称为Raster Operation,是在更新帧缓存之前,执行最后一系列针对每个片段的操作,其目的是:计算出每个像素的颜色值。在这个阶段,被遮挡面通过一个被称为深度测的过程而消除。总体来讲Pixel Operation主要包括:消除遮挡面、纹理操作(也就是根据像素的纹理坐标,查询对应的纹理值)、Blending(混色)、Filtering(滤波或者滤镜),该阶段之后,像素的颜色值被写入帧缓存中。下面是像素操作的流程:
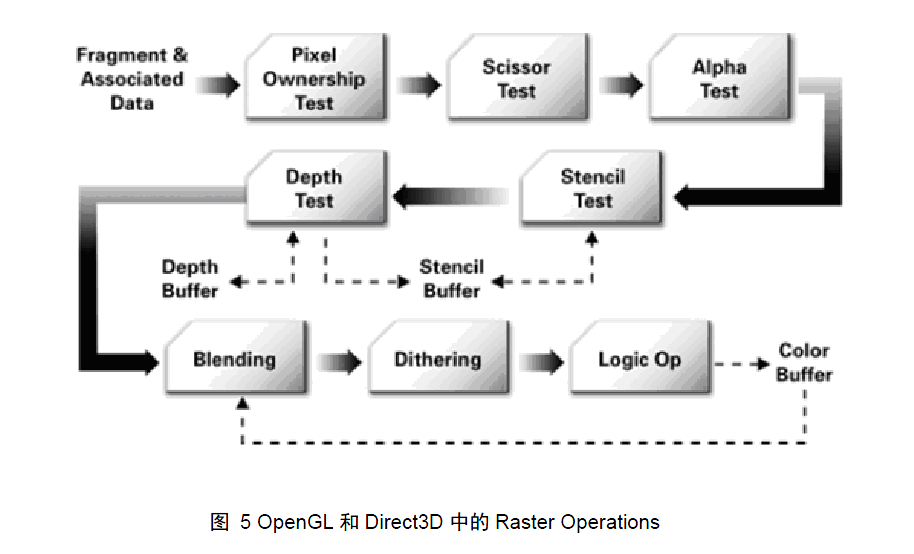
| 笔者注: 前面这些陆陆续续向大家介绍了GPU图形绘制管线的一下知识,图形绘制管线是GPU编程的基础,事实上顶点着色程序和片段着色程序正在按照图形绘制管线而划分的,由于本书并不是一本介绍计算机图形学的书籍,所以关于计算机图形学里的很多内容我们不可能在这里面面俱到都给大家讲详细,读者朋友如果想深入学习的话还需要多多涉猎计算机图形书籍学习相关知识,这对我们今后对整个图形渲染流程架构的理解十分有帮助。 |
一般可编程流水线都分为可编程顶点渲染(programmable vertexshader)流水线和可编程像素渲染(programmable pixel shader)流水线,简称顶点渲染(vertex shader)和像素渲染(pixel shader),它们取代了固定功能流水线中的顶点处理流水线(顶点坐标变换、光照、纹理坐标变换)以及部分像素光栅化处理过程。对每一种三维数据模型,图形程序设计人员都可以对它定义特定的顶点坐标变换和光照计算程序以及像素渲染方法,应用程序最终会根据每种数据特定的渲染计算方法(指定顶点渲染或像素渲染)进行渲染,从而极大地增加了三维图形程序设计的灵活性,并且针对特定数据编写的渲染程序能够有效地提高图形程序的执行效率。可编程流水线就是将顶点处理和像素处理的第一部分以可编程的方式实现,在这些具体的步骤中运行自己定义的函数,这样可以灵活的扩展图形渲染流水线的功能。
Shader Language
Shader Language,称为着色语言,在GPU编程发展的早起,shader language的提出目标是加强对图形处理算法的控制,所以对shaderlanguage的定义是:基于物体本身属性和光照条件,计算每个像素的颜色值。但随着技术的进步,目前的shaderlanguage早已经用于通用计算研究。
使用shader language编写的程序称之为shader program(着色程序)。着色程序分为两类:vertex shader program(顶点着色程序)和fragmentshader program(片段着色程序)。为了清楚的解释顶点着色和片段着色的含义,我们首先从阐述GPU上的两个组件:Programmable Vertex Processor(可编程顶点处理器,又称为顶点着色器)和Programmable Fragment Processor(可编程片段处理器,又称为片段着色器)顶点和片段处理器被分离成可编程单元,可编程顶点处理器是一个硬件单元,可以运行顶点程序,而可编程片段处理器则是一个可以运行片段程序的单元。顶点和片段处理器都拥有非常强大的并行计算能力,并且非常擅长于矩阵(不高于4 阶)计算,片段处理器还可以高速查询纹理信息。
如上所述,顶点程序运行在顶点处理器上,片段程序运行在片段处理器上,那么它们究竟控制了GPU 渲染的哪个过程。下图展示了可编程图形渲染管线。
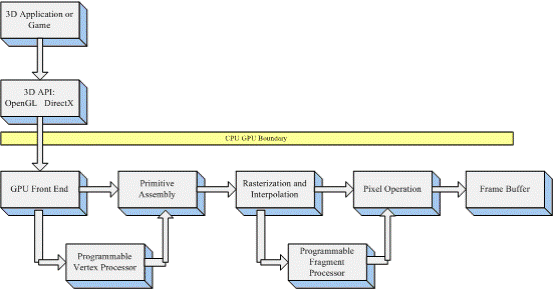
可编程图形渲染管线
对比前面的GPU 渲染管线,可以看出,顶点着色器控制顶点坐标转换过程;片段着色器控制像素颜色计算过程。这样就区分出顶点着色程序和片段着色程序的各自分工:Vertex program 负责顶点坐标变换;Fragment program负责像素颜色计算;前者的输出是后者的输入。
Vertex Shader Program
Vertex shader program(顶点着色程序)和Fragment shaderprogram(片断着色程序)分别被ProgrammableVertex Processor(可编程顶点处理器)和
Programmable Fragment Processo(可编程片断处理器)所执行。
顶点着色程序从GPU 前端模块(寄存器)中提取图元信息(顶点位置、法向量、纹理坐标等),并完成顶点坐标空间转换、法向量空间转换、光照计算等
操作,最后将计算好的数据传送到指定寄存器中;然后片断着色程序从中获取需要的数据,通常为“纹理坐标、光照信息等”,并根据这些信息以及从应用程序传
递的纹理信息(如果有的话)进行每个片断的颜色计算,最后将处理后的数据送光栅操作模块。
下图展示了在顶点着色器和像素着色器的数据处理流程。在应用程序中设定的图元信息(顶点位置坐标、颜色、纹理坐标等)传递到vertex buffer 中;纹
理信息传递到texture buffer 中。其中虚线表示目前还没有实现的数据传递。当前的顶点程序还不能处理纹理信息,纹理信息只能在片断程序中读入。
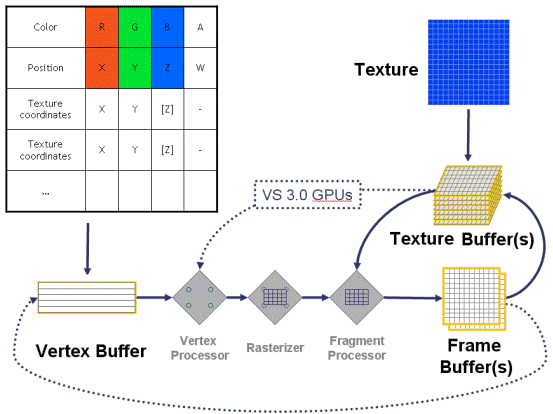
顶点着色器和像素着色器的数据处理流程
顶点着色程序与片断着色程序通常是同时存在,相互配合,前者的输出作为后者的输入。不过,也可以只有顶点着色程序。如果只有顶点着色程序,那么只对输入的顶点进行操作,而顶点内部的点则按照硬件默认的方式自动插值。例如,输入一个三角面片,顶点着色程序对其进行phong 光照计算,只计算三个顶点的光照颜色,而三角面片内部点的颜色按照硬件默认的算法(Gourand 明暗处理或者快速phong 明暗处理)进行插值,如果图形硬件比较先进,默认的处理算法较好(快速phong 明暗处理),则效果也会较好;如果图形硬件使用Gourand 明暗处理算法,则会出现马赫带效应(条带化)。而片断着色程序是对每个片断进行独立的颜色计算,并且算法由自己编写,不但可控性好,而且可以达到更好的效果。由于GPU 对数据进行并行处理,所以每个数据都会执行一次shader 程序程序。即,每个顶点数据都会执行一次顶点程序;每个片段都会执行一次片段程序。
Fragment Shader Program
片断着色程序对每个片断进行独立的颜色计算,最后输出颜色值的就是该片段最终显示的颜色。可以这样说,顶点着色程序主要进行几何方面的运算,而片段着色程序主要针对最终的颜色值进行计算。
片段着色程序还有一个突出的特点是:拥有检索纹理的能力。对于GPU 而言,纹理等价于数组,这意味着,如果要做通用计算,例如数组排序、字符串检索等,就必须使用到片段着色程序。让顶点着色器也拥有检索纹理的能力,是目前的一个研究方向。
| 笔者注: 在GPU编程中,由于像素着色和片段着色两种翻译都比较常见,所以,一般情况下,在文中我们会交替使用片段着色和像素着色。 什么是片断?片断和像素有什么不一样?所谓片断就是所有的三维顶点在光栅化之后的数据集合,这些数据还没有经过深度值比较,而屏幕显示的像素都是经过深度比较的。在我们的文章中不引起混淆的情况下,如无特殊说明,两者都是指同一个。 |
着色语言
Shader Language目前有3中主流语言:基于OpenGL的GLSL(OpenGLShading Language),基于Direct3D的HLSL(High Level Shading Language),还有NVIDIA公司的Cg(C for Graphic)语言。
GLSL与HLSL分别基于OpenGL和Direct3D的接口,相比起来,GLSL的语法体系自称一家,而HLSL和Cg语言的语法基本相同,这就意味着,只要学习HLGL和Cg中的任何一种,就等同于学习了两种语言。不过OpenGL毕竟图形API的曾经领袖,通常介绍OpenGL都会附加上一句“事实上的工业标准”,所以在其长期发展中积累下的用户群庞大,这些用户当然会选择GLSL学习。此外,GLSL继承了OpenGL的良好移植性,而微软的HLSL移植性较差,但在Windows平台上可谓一家独大,这一点在很大程度上限制了HLSL的推广和发展。目前HLSL多半都是用于游戏领域。NVIDIA是现在当之无愧的显卡之王,是GPU编程理论的奠基者,GeForce系列显卡早已深入人心,它突出的Cg语言已经取得了巨大的成功,生生形成了三足鼎立之势。而我们本文选择使用的着色语言就是Cg(但读者朋友不用担心,我们在编写cg代码的同时也会给出hlsl的实现代码),主要基于以下理由:其一,Cg是一个可以被OpenGL和Direct3D广泛支持的图形处理器编程语言。Cg语言和OpenGL、DirectX并不是同一层次的语言,而是OpenGL和DirectX的上层,即,Cg程序时运行在OpenGL和DirectX标准顶点和像素着色的基础上的;其二,Cg语言是Microsoft和NVIDIA相互协作在标准硬件光照语言的语法和语义上达成了一致,它是由两家公司联合开发的,所以,HLSL和Cg其实可以说是同一种语言,很多时候你会发现用HLSL写的代码可以直接当成Cg代码使用。并且Cg具有跨平台性,选择Cg语言是大势所趋。Cg同时被OpenGL与Direct3D两种编程API所支持,这一点不但对开发人员而言非常方便,而且也赋予了Cg程序良好的跨平台性。一个正确编写的Cg应用程序可以不做任何修改的同时工作在OpenGL和Direct3D之上。
Cg,即C for graphics,用于图形的C 语言,这其实说明了当时设计人员的一个初衷,就是“让基于图形硬件的编程变得和C 语言编程一样方便,自由”。正如C++和Java 的语法是基于C 的,cg 语言本身也是基于C 语言的。如果您使用过C、C++、Java 其中任意一个,那么Cg 的语法也是比较容易掌握的。Cg 语言极力保留了C 语言的大部分语义,力图让开发人员从硬件细节中解脱出来,Cg 同时拥有高级语言的好处,如代码的易重用性,可读性提高等。使用cg还可以实现动画驱动、通用计算(排序、查找)等功能。使用Cg 编写的着色程序默认的文件后缀是*. Cg。
| 笔者注: 虽然着色语言的内容远远不止我们上面讲到的这些,但是毕竟我们本书只是一本讲解Ogre相关知识的书,对于GLSL、HLSL和Cg语言的语法结构我们也不可能面面俱到给大家都详细讲解,所以如果读者朋友想多了解这方面的知识还需自己去学习相关知识,这样才能掌握的更扎实,GLSL和HLSL相关的书籍已经很多,Cg语言相关的书籍近年来也在不断增多,推荐大家可以参考一下《GPU Programming And Cg Language Primer 1rd Edition》(中文名叫《GPU编程与CG语言之阳春白雪下里巴人》,康玉之),我们本书关于GPU编程方面的知识,很多也是引用了康老师的内容,这本书写得相当不多,推荐大家阅读。 |
16.2 顶点程序与片断程序的声明
了解了这么多,我们现在讨论一下在Ogre中使用Shader编程的方式,Ogre中为了在我们定义的材质中使用顶点或者片断程序,我们首先必须定义它们,一个程序定义可以被多个材质使用,唯一的前提条件是必须在引用它之前在材质的渲染通路部分中定义。
程序定义可以被嵌套在.material脚本内(在这种情况下,它必须位于任何对它的引用之前,即必须先定义后引用)或者如果你希望跨多个.material脚本使用同一个程序,你可以在一个外部的.program脚本中定义。程序定义的方式与在.program或者.material脚本中一样,唯一的区别是所有的.program脚本都肯定会在.material脚本之前被处理,因此确保你的程序肯定在任何.material脚本之前被定义。正像.material脚本一样,.program可以从你指定的资源路径上的任意读取,并且你可以在一个脚本中定义多个程序。
顶点和片段程序既可以是低级渲染语言(例如按照给定的诸如vs_1_1或者arbfp1的低级语法规格写成的汇编代码)也可以是高级渲染语言,例如HLSL,GL SL或者Cg。高级语言给你许多优势,例如能够写出更加直观的代码,能够在一个程序中针对多种架构(例如,一段Cg程序即可用在D3D上,也可用在GL上),与此同时,低级的程序也许会需要单独的技术,各自针对不同的API)。
一个低级顶点程序示例如下:
vertex_program myVertexProgram asm
{
sourcemyVertexProgram.asm
syntax vs_1_1
}
如你所见,很简单。定义一个片断程序,与此相同,只是将vertex_program换成fragment_program。在头部给出程序的名字,后跟'asm'指示这是一个低级程序。在大括号内部,你要指定资源来自何处(从指定的资源位置查找,进行装载),还要指出要使用的语法规格。你可能会奇怪为什么要指定语法规格,头部不是已经指定了汇编器的语法了吗,其实原因在于,引擎需要在读取程序之前知道语法规格,因为在材质编译期间,我们想迅速退出使用不支持语法的程序,一开始就不装载这个程序。
当前支持的语法有:
vs_1_1
这是一种DirectX顶点渲染器汇编语法。
支持的显卡有:ATI Radeon 8500,nVidia GeForce 3
vs_2_0
另一种DirectX顶点渲染器汇编语法。
支持的显卡有:ATI Radeon 9600,nVidia GeForce FX 5 系列
vs_2_x
另一种DirectX顶点渲染器汇编语法。
支持的显卡有:ATI Radeon X 系列, nVidia GeForce FX 6 系列
vs_3_0
另一种DirectX顶点渲染器汇编语法。
支持的显卡有:ATI Radeon HD 2000+,nVidia GeForce FX 6 系列
arbvp1
这是OpenGL标准顶点程序汇编格式。大体上相当于DirectX vs_1_1。
vp20
这是一种nVidia特有的OpenGL顶点渲染器语法,是vs 1.1的一个超集。
ATI Radeon HD 2000+ 也支持它。
vp30
另一种nVidia特有的OpenGL顶点渲染器语法,是vs 2.0的一个超集,被nVidia GeForce FX 5及以上系列支持。ATI Radeon HD 2000+也支持它.
vp40
另一种nVidia特有的OpenGL顶点渲染器语法,是vs 3.0的一个超集,被nVidia GeForce FX 6及以上系列支持。
ps_1_1, ps_1_2,ps_1_3
DirectX像素渲染器 (例如片段程序)汇编语法。
支持显卡: ATI Radeon 8500, nVidia GeForce 3
注解: 对于 ATI 8500, 9000, 9100, 9200 硬件,也可用于OpenGL。ATI 8500 到 9200 不支持 arbfp1 但是确实支持OpenGL的atifs扩展,功能上非常类似DirectX的ps_1_4。 Ogre 有针对atifs编译器的ps_1_x模块,当在ATI硬件上在OpenGL中使用ps_1_x时,它会自动执行。
ps_1_4
DirectX像素渲染器(片段程序)汇编语法。
支持显卡有: ATI Radeon 8500,nVidia GeForce FX 5 系列。
注解: 对于ATI 8500, 9000, 9100, 9200 硬件,此项也可用于OpenGL。 ATI 8500 to 9200不支持arbfp1但是确实支持OpenGL的atifs扩展,功能上非常类似DirectX的ps_1_4。 Ogre 有针对atifs编译器的ps_1_x模块,当在ATI硬件上在OpenGL中使用ps_1_x时,它会自动执行。
ps_2_0
DirectX像素渲染器(片段程序)汇编语法。
支持显卡有: ATI Radeon 9600,nVidia GeForce FX 5 系列
ps_2_x
DirectX像素渲染器(片段程序)汇编语法。基本上是带有更多指令的ps_2_0。
支持显卡有: ATI Radeon X 系列, nVidia GeForce FX 6 系列。
ps_3_0
DirectX像素渲染器(片段程序)汇编语法。
支持显卡有: ATI Radeon HD2000+, nVidia GeForce FX6 系列。
ps_3_x
DirectX像素渲染器(片段程序)汇编语法。
支持显卡有: nVidia GeForce FX7 系列。
arbfp1
这是OpenGL标准片段程序汇编格式。大体上相当于ps_2_0,意味着不是所有支持 着不是所有支持DirectX下的基本像素渲染器都支持arbfp1(例如GeForce3 和 GeForce4 就都不支持arbfp1,但它们都支持ps_1_1)。
fp20
这是一个nVidia特有的OpenGL片段程序语法,是ps 1.3的一个超集。它允许你为基本片段程序使用 'nvparse' 格式。实际上,它使用NV_texture_shader和 NV_register_combiners在GL下提供相当于DirectX's ps_1_1的功能,但是仅限于nVidia显卡。然而,因为ATI显卡比nVidia早一步采用arbfp1,所以它主要用于像GeForce3 和 GeForce4系列的nVidia显卡。你可以在http://developer.nvidia.com/object/nvparse.html上找到更多有关nvparse的信息。
fp30
另一种nVidia特有的OpenGL片段渲染语法。它是ps 2.0的一个超集,被nVidia GeForce FX 5或更高级的显卡支持。ATI Radeon HD 2000+也支持它。
fp40
另一种nVidia特有的OpenGL片段渲染语法。它是ps 3.0的一个超集,被nVidia GeForce FX 6或更高级的显卡支持。ATI Radeon HD 2000+也支持它。
gpu_gp, gp4_gp
一种nVidia特有的OpenGL几何渲染语法
支持显卡有: nVidia GeForce FX8 系列。
你可以通过调用GpuProgramManager::getSingleton().getSupportedSyntax()得到当前显卡支持的语法列表。
| 笔者注: 几何着色器的概念在我们本书中并没有涉及到,它超出了本书讨论的范围,如果读者有兴趣可以查阅相关资料学习。 几何着色器(Geometry Shader)是 Shader Model 4.0的标准规格,DirectX 10与OpenGL 3.1已有支援几何着色器。 Shader Model 4.0引进了几何着色器,可使用Shader 资源来处理graphics pipeline 的点、线、面的几何坐标变换,一次最多处理6个点,快速地将模型类似的顶点结合起来进行运算。此一过程无需CPU参与。NVIDIA公司的GeForce 8800 图形处理器是第一个提供硬件支持的几何着色器。 几何着色器典型用途包括: point sprite 的生成, 几何镶嵌(tessellation), 阴影体(shadow volume) extrusion。 几何着色器可以借由 Cg, Direct3D的 HLSL, OpenGL的GLSL等语言来完成。 |
在详细介绍我们的顶点程序和片段程序之前,我们先来看一个示例,通过这个示例来逐步展开我们的讨论。
同样,我们使用我们和《Ogre材质与纹理》一章中相同的代码,只是我们把对材质名的引用改为“MyTestMaterial3”:
| #include <windows.h> #include "ExampleApplication.h"
class Example1 : public ExampleApplication { public: void createScene() { Ogre::Entity*cube =mSceneMgr->createEntity("cube","cube.mesh"); Ogre::SceneNode*cubeNode =mSceneMgr->getRootSceneNode()->createChildSceneNode(); cubeNode->attachObject(cube); cube->setMaterialName("MyTestMaterial3"); } protected: private: };
INT WINAPI WinMain( HINSTANCE hInst, HINSTANCE, LPSTR strCmdLine, INT ) { Example1 app; app.go(); return 0; } |
然后,为了更清晰的分析我们的代码,我们可以在和MyTest.material脚本文件同一目录下中新添加一个材质脚本文件MyTest2.material,这样我们就可以在MyTest2.material中创建我们的新材质MyTestMaterial3了(当然你也可以不用新建MyTest2.material,直接在原来的MyTest.material创建):
第一步:我们先定义一个片段着色器。关于着色器的定义,Ogre3D需要定义五项信息:
着色器的名字;
着色器是使用什么语言写的;
它存储在哪个源文件中;
着色器调用的主函数;
着色器以什么语法编译。
所有的这些信息都应该在材质脚本文件中定义:
| fragment_program MyFragmentShader1 cg { source Ogre3DTestShaders.cg entry_point MyFragmentShader1_Main profiles ps_2_0 arbfp1 } |
| 笔者注: 如果读者想编写HLSL的实现代码,请参看本节的最后,我们也提供了对应的HLSL着色语言的代码实现: |
通过上面的内容我们可以了解到,我们通过关键字fragment_program定义了一个片段着色程序,名字叫MyFragmentShader1,采用cg语言编写,着色器的实现代码存储在Ogre3DTestShaders.cg这个文件中,通过关键字source定义,然后通过关键字entry_point定义了着色器的入口主函数名叫MyFragmentShader1_Main,也就是说,每次我们需要片断着色器的时候这个函数会首先被调用,最后,我们可以看到有个profiles关键字,这个就是定义前面我们提及过的渲染器的各种语法,如果我们使用DirectX渲染那么这里着色器采用 ps_2_0语法编译,如果我们采用OpenGL,则采用arbfp1语法编译,这样我们就简单实现了所谓的跨平台性。
我们现在在来看一下顶点着色程序,它和片段着色程序一样,同样需要上面的五项基本信息,但是它还需要定义一个参数,这个参数是从Ogre3D应用程序传递到我们的shader中的:
| vertex_program MyVertexShader1 cg { source Ogre3DTestShaders.cg entry_point MyVertexShader1_Main profiles vs_2_0 arbvp1
default_params { param_named_auto worldViewMatrix worldviewproj_matrix } } |
这里param_named_auto意为我们不必提供数值,它是由Ogre3D自动更新的世界/视点/投影矩阵,后面的worldViewMatrix是我们自定的的参数名,而我们想让Ogre3D每次给我们自动传递给这个参数的是worldviewproj_matrix类型的矩阵值,它包含了我们把模型从局部空间转换到相机空间所使用的矩阵。
当定义一个顶点或片段程序时,除非特殊情况下参数被重载了,否则你也可以指定默认参数用于材质中。要是使用默认参数,需要你嵌套一个‘default_params’块。
参数可以被指定为如下四种之一:
param_indexed
param_indexed_auto
param_named
param_named_auto
无论你要定义一个参数只为这个程序特别使用,还是指定默认的程序参数,语法都是一样的。程序特殊使用的参数设置会重载默认值。
param_indexed
此命令设置索引参数的数值。
格式:param_indexed <index><type> <value>
示例:param_indexed 0 float4 10.0 0 0 0
'index'简单地是表示应当被写进参数表的位置的数值,应当从你的程序定义派生。索引是与常量在显卡上的存储方式相关的,即四元组方式。例如,如果你在索引0位置定义了一个float4参数,那么下一个索引就会是1。如果你在索引0位置定义了一个matrix4x4,那么下一个可用索引就会是4,因为一个4x4矩阵占据4个索引位置。
'type'的值可以是float4,matrix4x4,float<n>,int4,int<n>。注意'int'参数只可用于某些更为高级的程序语法中,细节请检查D3D或者GL顶点/片断程序有关文档。一般最有用的是float4和matrix4x4。注意如果你使用了一个不是4的倍数的类型,那么剩余的值会被填充为0(因为GPU总是使用4个浮点数一组表示常量,尽管只用了其中的一个)。
'value'简单地是由空格或者tab制表符分割的数值列表,这些数值可以被转换成你指定过的类型。
param_indexed_auto
此命令告诉Ogre用源数值自动更新给定的参数。这就将你从编写代码的繁重劳动中解放出来,当参数总是在改变的时候,不用逐帧去更新。
格式:param_indexed_auto <index><value_code> <extra_params>
示例:param_indexed_auto 0worldviewproj_matrix
'index'意思与param_indexed中所述相同;注意,这次你不必指定参数的大小,因为引擎已经知道了。在示例中,使用了世界/视点/投影矩阵暗含地就是说这是matrix4x4。
'value_code'是如下的一个值:world_matrix(当前世界矩阵)、inverse_world_matrix(当前世界矩阵的反转矩阵)、transpose_world_matrix (当前世界矩阵的转置矩阵)、inverse_transpose_world_matrix(当前世界矩阵的反转转置矩阵)、light_diffuse_colour 等等,更详细的列表可以参看官方文档。
param_named
这同param_indexed是一样的,但是使用一个命名的参数替代索引号。这只能与包括参数名的高级程序一起使用;如果你要使用一个编译程序,那么你除了索引别无选择。注意,你也可以在高级程序中使用索引参数,但是这样它就不便移动了,因为如果你用高级程序渲染参数,索引号会发生改变。
格式: param_named <name><type> <value>
示例:param_named shininess float4 10.0 0 00
这里的type是必需的,因为当材质脚本被分析时,程序并不被编译和装载,所以在这时,我们不知道参数是什么类型。程序只有被使用过后才装载和编译,为的是节约内存。
param_named_auto
功能同param_indexed_auto,只不过这个是有名字的,用于高级程序。
格式:param_named_auto <name><value_code> <extra_params>
示例:param_named_auto worldViewProjWORLDVIEWPROJ_MATRIX
extra_params允许的数值代码和意思详见param_indexed_auto。
定义了片断和顶点着色器之后,我们现在在下面继续定义MyTestMaterial3材质,在这个材质中我们会引用到我们刚才定义的这两项内容:
| material MyTestMaterial3 { technique { pass { vertex_program_ref MyVertexShader1 { } fragment_program_ref MyFragmentShader1 { } } } } |
上面的代码中我们可以看到定义材质的时候,我们使用到了关键字vertex_program_ref和fragment_program_ref,也就是我们想引用到哪个顶点着色程序和片段着色程序,同样,我们可以在两个大括号内部添加更多的一下参数定义,这里我们仅仅保持为空。
这样,我们在MyTest2.material这个文件中定义的三部分内容基本算是完成了,可是我们或许会有这样的疑问,我们在着色器中引用到的那个Ogre3DTestShaders.cg那个文件在哪呢?是的,我们现在就开始编写这个文件。
我们打开media\materials\programs这个目录文件夹,应该可以看到比较熟悉的东西,有一些文件后缀为*.cg、*.glsl、*.hlsl的文件,同样,我们在这里新创建一个文件Ogre3DTestShaders.cg,然后把我们的着色程序写在这个文件里Ogre在加载的时候就能找到了,正是因为Ogre可以找到这个文件,所以前面我们用到这个文件的时候才没有用绝对路径,我们先来添加片断着色器的入口函数实现代码(当然这里也可以先添加顶点着色器的入口函数):
| void MyFragmentShader1_Main(out float4 color:COLOR) { color = float4(0,0,1,0); } |
通过上面的代码我们可以看出,cg文件中定义的函数我们通过C语言定义的函数结构很类似,不同的是参数的声明方式,这里的out前缀表示这个参数是一个输出类型的参数,只是用于输出,而参数的类型是float4,简单来说它相当于一个具有四个浮点数的数组,它是表示float 类型的4 元向量,我们这里可以把它看做一个四元组(r,g,b,a)。接着在这个参数名之后有一个COLOR类型,我们把这种类型叫做语义描述符(语义词),也就是说如果这个参数标示的含义是顶点位置,我们可以把COLOR改为POSITION,这样渲染管线就能推断出这个参数是代表着颜色还是位置。在函数体中我们仅仅添加了一行代码,我们用来输出的参数color赋予一个蓝颜色的值(0,0,1,0),这句话的意思就是每一个用这个材质渲染的物体最终都被修改为蓝色。
Cg 语言中参数传递方式同样分为“值传递”和“引用传递”,但指针机制并不GPU 硬件所支持,所以Cg 语言采用不同的语法修辞符来区别“值传递”和“引用传递”。这些修辞符分别为:
1. in: 修辞一个形参只是用于输入,进入函数体时被初始化,且该形参值的改变不会影响实参值,这是典型的值传递方式。
2. out: 修辞一个形参只是用于输出的,进入函数体时并没有被初始化,这种类型的形参一般是一个函数的运行结果;
3. inout: 修辞一个形参既用于输入也用于输出,这是典型的引用传递。
举例如下:
void myFunction(out float x); //形参x,只是用于输出
void myFunction(inout float x); //形参x,即用于输入时初始化,也用于输出数据
void myFunction(in float x); //形参x,只是用于输入
void myFunction(float x); /等价与 in float x,这种用法和C\C++完全一致
也可以使用return 语句来代替out 修辞符的使用。输入\输出修辞符通常和语义词一起使用,表示顶点着色程序和片段着色程序的输入输出。
下面我们来看一下cg中函数的参数声明时的语法结构:
[const] [in | out |inout]<type><identifier> [:<binding-semantic>][=<initializer>]
其中,const 作为可选项,修辞形参数据;in、out、inout 作为可选项,说明数据的调用方式;type 是必选项,声明数据的类型;identifier 是必选项,形参变量名;一个冒号“:”加上一个绑定语义,是可选项;最后是初始化参数,是可选项。
然后,添加顶点着色器的入口函数实现代码:
| void MyVertexShader1_Main(float4 position:POSITION, out float4 oPosition:POSITION, uniform float4x4 worldViewMatrix) { oPosition = mul(worldViewMatrix,position); } |
这里顶点着色程序我们定义了三个参数,两个被标记为位置类型的参数,另一个是float4x4类型的矩阵,但是我们可以发现在这个参数定义的最前面我们又加了一个关键字uniform。每次当顶点着色程序被调用的时候,都会传进来一个新的位置顶点,作为输入参数,因为我们可以发现第一参数position没有用out修饰,其实默认是in类型的,所以可以作为输入参数,这样对这个顶点修改之后可以通过输出参数oPosition输出,也就是说每次调用这个参数都会改变,但是worldViewMatrix却不一样,uniform表示一些与三维渲染有关的离散信息数据,这些数据通常由应用程序传入,并通常不会随着图元信息的变化而变化,如材质对光的反射信息、运动矩阵等。uniform 修辞一个参数,表示该参数的值由外部应用程序初始化并传入;“外部”的含义通常是用OpenGL 或者DirectX 所编写的应用程序。使用uniform 修辞的变量,除了数据来源不同外,与其他变量是完全一样的。
我们再来看一下函数体中的内容,在函数体中,我们让得到的位置顶点和worldViewMatrix相乘,得到在相机空间的顶点变化,然后通过输出参数oPosition输出。mul是cg中的标准函数库中的函数。和C 的标准函数库类似,Cg 提供了一系列内建的标准函数。这些函数用于执行数学上的通用计算或通用算法(纹理映射等),例如,需要求取入射光线的反射光线方向向量可以使用标准函数库中的reflect 函数,求取折射光线方向向量可以使用refract 函数,做矩阵乘法运算时可以使用mul 函数。Cg 标准函数库主要分为五个部分:数学函数(Mathematical Functions)、几何函数(Geometric Functions)、纹理映射函数(Texture MapFunctions)、偏导数函数(DerivativeFunctions)。
编译并运行程序,你将会看到以下效果:

通过这一整个流程我们可以再来回忆一下顶点着色程序和片段着色程序执行的整个流程:应用程序(宿主程序)将图元信息(顶点位置、法向量、纹理坐标等)传递给顶点着色程序;顶点着色程序基于图元信息进行坐标空间转换,运算得到的数据传递到片段着色程序中;片段着色程序还可以接受从应用程序中传递的纹理信息,将这些信息综合起来计算每个片段的颜色值,最后将这些颜色值输送到帧缓冲区(或颜色缓冲区)中。
这些是顶点着色程序和片段着色程序的基本功能和数据输入输出,实际上现在的着色程序已经可以接受多种数据类型,并灵活的进行各种算法的处理,如,可以接受光源信息(光源位置、强度等)、材质信息(反射系数、折射系数等)、运动控制信息(纹理投影矩阵、顶点运动矩阵等),可以在顶点程序中计算光线的折射方向,并传递到片段程序中进行光照计算。
上面的示例中我们直接修改的是材质的颜色,使之为蓝色,如果我们想像原来那样想显示一张图片该怎么办呢,或许大家会想到,在pass中添加一个texture_unit应该就可以了,其实不然,因为我们在片段着色程序中已经把固定功能管线中的任务截获了,如果想显示出来这张图片我们需要对着色程序做一些修改,下面我们就来看看这样的一个过程:
首先,把材质MyTestMaterial3的pass中修改为如下内容,如下:
| pass { vertex_program_ref MyVertexShader1 { } fragment_program_ref MyFragmentShader1 { } texture_unit { texture BeachStones.jpg } } |
然后,修改Ogre3DTestShaders.cg文件中的两个函数
MyFragmentShader1_Main函数修改如下所示:
| void MyFragmentShader1_Main(float2 uv : TEXCOORD0, out float4 color : COLOR, uniform sampler2D texture) { color = tex2D(texture, uv); } |
这里和原来的代码相比,增加了两个参数,第一个参数uv是float2类型的,它代表了一个二元组,TEXCOORD0是语义词,指的是纹理坐标;另一个新的参数被定义为一种新的类型sample2D,它代表纹理对象的句柄,简单来说相当于纹理的另一个名字,我们把这个参数标记为uniform表示这个参数的值将来自外部的CG程序,被Ogre3D渲染环境来设置。在函数体中我们使用了tex2D函数,它需要一个sample2D和一个float2类型的值作为输入参数,然后返回一个float4类型的值作为颜色值,它的功能时根据对应的纹理返回对应纹理坐标的颜色。
MyVertexShader1_Main函数修改如下所示:
| void MyVertexShader1_Main(float4 position : POSITION, out float4 oPosition : POSITION, float2 uv : TEXCOORD0, out float2 oUv : TEXCOORD0, uniform float4x4 worldViewMatrix) { oPosition = mul(worldViewMatrix,position); oUv = uv; } |
这里我们也新添加了一些新的参数,float2类型的uv代表传入的纹理坐标值,它和position一样,每次传入一个顶点时相应的也会把对应的纹理坐标传入进来,然后我们又定义了一个用来传出纹理坐标的参数oUv。
最后,编译并运行程序,你将会发现图片能正常显示了。

下面我们再来讨论一下,在我们的程序代码中怎样向shader中传递变量值,通过这个值来完成更复杂的操作。
首先,找到MyTestMaterial3中fragment_program_ref部分的代码,修改如下:
| fragment_program_ref MyFragmentShader1 { param_named_auto colorModulate custom 1 } |
回到前面查看一下param_named_auto我们可以看到它的格式如下:param_named_auto <name> <value_code><extra_params>
这里我们再来到官方文档查看一下custom的解释:
custom
这允许你映射一个自定义参数到GPU程序参数上(详见Renderable::setCustomParameter)。它需要你添上'extra_params'中索引,该索引在Renderable::setCustomParameter调用时会被用到,且这会保证无论何时使用这个Renderable,它都会有其自定义的参数映射。重要的是这个参数已经在所有Renderables上定义了,且包含这个自动映射的材质赋值给Renderables,否则过程会失败。
于是,这里我们相当于定义了一个名为colorModulate的自定义参数,它的extra_params值我们这里定义为1,这样我们就可以在应用程序代码中读取或修改这个参数了,稍后我们会看到怎么在我们的代码中使用它。
然后,修改Ogre3DTestShaders.cg中MyFragmentShader1_Main函数中的代码,如下:
| void MyFragmentShader1_Main( float2 uv : TEXCOORD0, out float4 color : COLOR, uniform float4 colorModulate, //增加一个颜色调整参数 uniform sampler2D texture) { color = tex2D(texture, uv); color = color*colorModulate;//调整颜色 } |
上面的内容很简单,除了多了一个参数外,其它代码和原来一样,我们在函数体中用得到的颜色值乘以这个参数,从而达到调整颜色的目的。
最后,修改我们应用程序代码中createScene函数中的代码,如下:
| void createScene() { Ogre::Entity*cube =mSceneMgr->createEntity("cube","cube.mesh"); Ogre::SceneNode*cubeNode =mSceneMgr->getRootSceneNode()->createChildSceneNode(); cubeNode->attachObject(cube); cube->setMaterialName("MyTestMaterial3"); cube->getSubEntity(0)->setCustomParameter(1,Vector4(0.f, 0.f, 1.0f, 0.2f)); } |
编译并运行程序,我们会看到如下效果,原来的图片被修改了:

当我们基于Mesh创建出一个Entity时,该Entity由多个SubEntity构建而成,SubEntity与Mesh中的SubMesh一一对应。因此Entity是由SubEntity组成的,而SubEntity是从Renderable继承而来的,所以Entity是可渲染的。前面我们提到过'extra_params'中索引,该索引在Renderable::setCustomParameter调用时会被用到,因此我们在程序中就可以通过这样的方式调用到shader程序中自定义的参数,从而达到程序代码和shader程序通信的目的。
HLSL实现代码(MyTest2.material部分):
| vertex_program MyVertexShader2 hlsl { source Ogre3DTestShaders_VP.hlsl target vs_2_0 entry_point main
default_params { param_named_auto worldViewMatrix worldviewproj_matrix } }
fragment_program MyFragmentShader2 hlsl { source Ogre3DTestShaders_FP.hlsl target ps_2_0 entry_point main }
material MyTestMaterial4 { technique { pass { vertex_program_ref MyVertexShader2 { } fragment_program_ref MyFragmentShader2 { param_named_auto colorModulate custom 1 } texture_unit { // sampler s0 texture BeachStones.jpg } } } } |
HLSL实现代码(Ogre3DTestShaders_VP.hlsl部分):
| float4x4 worldViewMatrix;
struct VS_OUTPUT { float4 pos: POSITION; float2 texCoord0: TEXCOORD0; };
VS_OUTPUT main( float4 Pos: POSITION, float3 normal: NORMAL, float2 texCoord0: TEXCOORD0 ) { VS_OUTPUT Out; Out.pos = mul(worldViewMatrix, Pos); Out.texCoord0 = texCoord0; return Out; } |
HLSL实现代码(Ogre3DTestShaders_FP.hlsl部分):
| sampler Tex0: register(s0); float4 colorModulate;
float4 main(float4 texCoord0: TEXCOORD0): COLOR0 { float4 color = tex2D(Tex0, texCoord0); color = color*colorModulate; return color; } |
注:由于时间关系,本章内容当时写得比较匆忙,还有很多内容没有写完,由于Ogre这一系列的文章,特别是这第十七章是临近毕业以及刚工作那段时间整理的,所以有哪里不对的地方还望见谅,本章内容其实很想找时间继续完善下,但是由于工作原因,暂时也没有时间研究这一块,只能写到这里了,所以后续有机会再说吧,大家继续努力。














 3170
3170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









