






系列5中讲到会讲解3个方面RAG的提升,它们可能与RAG的准确率有关系,但是更多的它们是有其它用途。本期来讲解第二部分:查询结构化(Query Construction)。在系列3文档处理中,我们着重讲解了文档解析,但是我们说的文档都是大部分是非结构化的文档或者说它就是以一个文档的形式存储。而现实中我们很多有价值的数据可能以结构化(关系型数据库、图形数据库等)或者半结构(关系型数据库、文档数据库等)的形式存储中,并且这些数据一般都是存储于特定数据库,那么如果数据存储在结构化或者半结构化中,我们RAG又该如何与之配合。这一章就着重来讲讲查询结构化内容(Query Construction)
目录
1 查询结构内容(Query Construction)
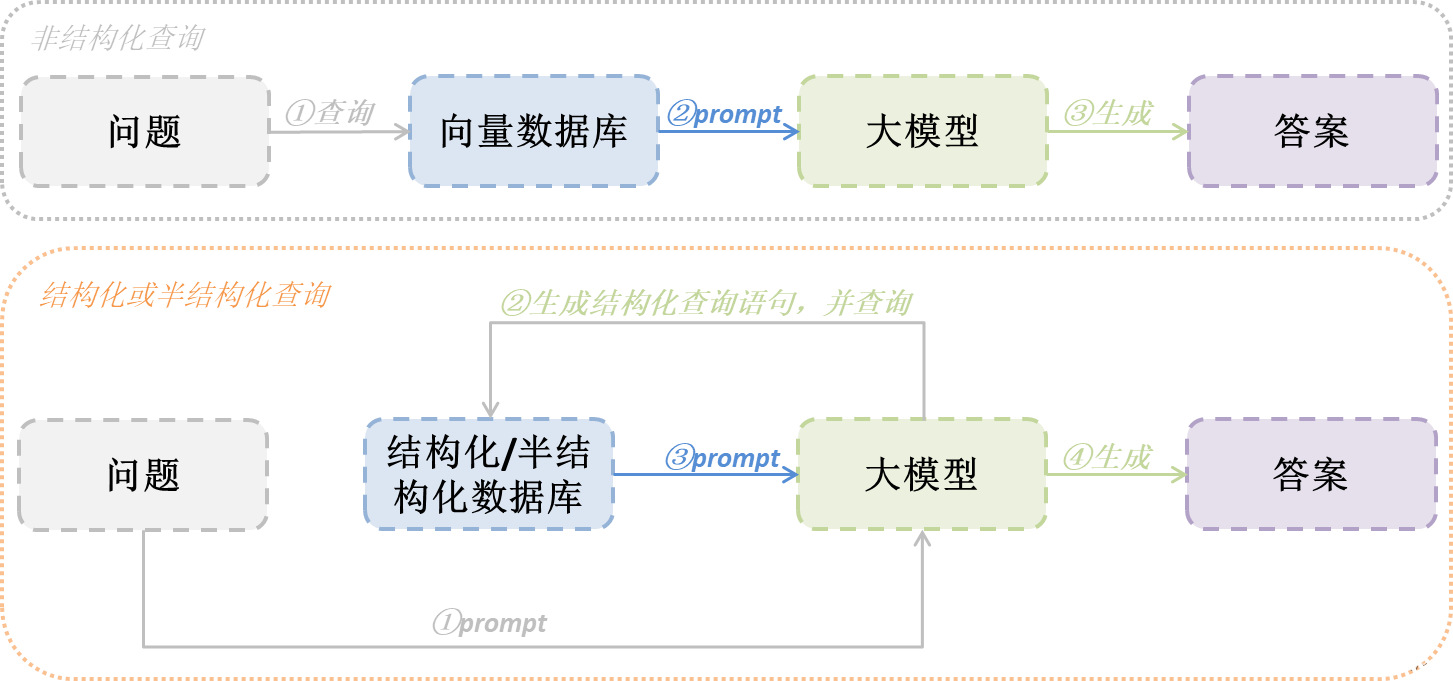
现实中我们很多有价值的数据可能以结构化(关系型数据库、图形数据库等)或者半结构化(关系型数据库、文档数据库等)的形式存储中,并且这些数据一般都是存储于特定数据库,同时数据库提供结构化的查询功能,使用其结构化查询(比如SQL等)比使用向量化查询更为准确。那这时候如果我们RAG想要去查询这些有结构的数据,就不是将数据向量化后再去查询,而是利用大模型将用户问题转换为结构化查询,再通过结构化查询去数据库查询结果,最后利用结果回答用户问题。下图流程可以让你明显感受不同之处:
我们将不同结构化或者半结构化查询归纳如下表,下面也是逐一讲解各个方法
| 方法 | 数据源 |
|---|---|
| Text-to-metadata-filter | 向量数据库 |
| Text-to-SQL | 关系型数据库 |
| Text-to-Cypher | 图形数据库 |
| Text-to-SQL+ Semantic | 关系型+向量混合数据库 |
2 Text-to-metadata-filter
第一个要利用大模型将用户问题转换为结构化查询的依旧是向量数据库,但是这里并非做向量查询,而是很多向量存储其实都配备了元数据过滤功能,这些元数据其实就是结构化存储,因此需要过滤的是存储在向量数据库的元数据。
这里以查询ChromaDB的metadata为例,做一个demo代码演示。在运行代码之前我们需要做以下前置条件
- 这里采用智谱AI的API接口,因此可以先去申请一个API KEY(当然你使用其它模型也可以,目前智谱AI的GLM4送token,就拿它来试验吧)
- 下载m3e-base的embedding模型
- 给一个文档目录,里面放入一个文档即可,文档内容不限
import os
from typing import List
from langchain_openai import ChatOpenAI
from langchain_core.documents import Document
from langchain_community.vectorstores import Chroma
from langchain_core.prompts import ChatPromptTemplate
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_core.runnables import RunnablePassthrough
from langchain_community.document_loaders import DirectoryLoader
# 前置工作1:文档存储,给文档设置author属性
encode_kwargs = {"normalize_embeddings": False}
model_kwargs = {"device": "cuda:0"}
embeddings = HuggingFaceEmbeddings(
model_name='/root/autodl-tmp/model/AI-ModelScope/m3e-base', # 换成自己的embedding模型路径
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
if os.path.exists('VectorStore'):
db = Chroma(persist_directory='VectorStore', embedding_function=embeddings)
loader = DirectoryLoader("/root/autodl-tmp/doc") # 换成自己的文档路径
documents = loader.load()
# 这里假设设置一个author作者的属性
documents[0].metadata["author"] = "刘震云"
database = Chroma.from_documents(documents, embeddings, persist_directory="VectorStore")
database.persist()
# 前置工作2:创建llm
llm = ChatOpenAI(
temperature=0.95,
model="glm-4",
openai_api_key="你的API KEY",
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
# 前置工作3:为了将用户问题转换为结构化查询,使用LangChain可以通过Pydantic类轻松指定所需的function call schema:
# 这里假设书籍有2个字段匹配,一个是内容content_search,一个是作者author_search
class BookSearch(BaseModel):
content_search: str = Field(
...,
description=(
"书籍文本内容进行相似性搜索"
),
)
author_search: str = Field(
...,
description=(
"书籍作者,仅在使用人名查询时,才进行关键字匹配,其它情况不使用"
),
)
# 第一步:让模型将用户问题转换成与查询字段匹配的格式
system = """你是将用户问题转换为数据库查询的专家。
你可以访问关于的书籍数据库。
给定一个问题,返回一个优化为检索最相关结果的数据库查询。"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
# 绑定前面定义的输出数据格式,意思就是要求模型根据类结构返回数据。
structured_llm = llm.with_structured_output(BookSearch)
# 定义chain
query_analyzer = {"question": RunnablePassthrough()} | prompt | structured_llm
print(query_analyzer.invoke("作家刘震云的书"))
# 第二步:转换匹配,拼接向量查询条件查询Chroma
def retrieval(search: BookSearch) -> List[Document]:
if search.author_search is not None:
_filter = {"author": {"$eq": search.author_search}}
else:
_filter = None
return database.similarity_search(search.content_search, filter=_filter)
retrieval_chain = query_analyzer | retrieval
# 未查询到结果
print(retrieval_chain.invoke("作家莫言的书"))
# 查询到结果
print(retrieval_chain.invoke("作家刘震云的书"))
3 Text-to-SQL
关于关系型数据库就不用在累赘了,但是使用大模型生成SQL可能会出现以下问题:
- 幻觉:大模型容易对虚构的表或字段产生“幻觉”,从而产生无效的查询。方法必须将这些大模型 建立在现实中,确保它们生成与实际数据库模式一致的有效 SQL。
- 用户错误:文本转 SQL 方法应能够防止用户拼写错误或用户输入中可能导致无效查询的其他不规范情况。
对于以上问题,有不少的解决方案供参考:
- 数据库描述:要生成SQL查询,必须向大模型提供数据库的准确描述。常见的做法:为大模型提供每张表的CREATE TABLE描述,包括列名、类型等,然后再给出几个SELECT语句的示例。
- Few-shot样例:在prompt中添加question-query的几个样例可以提高query生成的准确性。在prompt中简单的添加标准的静态示例指导大模型如何基于question创建query。
- 错误处理:当遇到错误时,利用工具(例如SQL Agent)修复错误。
- 查找专有名词中的拼写错误:当查询名称等专有名词时,用户可能会不小心写错。我们允许大模型Agent根据向量库搜索正确的名称,向量库在SQL数据库中存储相关专有名词的正确拼写。
下面以查询sqlite数据库为例子,,做一个demo代码演示。在运行代码之前我们需要做以下前置条件
- 这里采用智谱AI的API接口,因此可以先去申请一个API KEY(当然你使用其它模型也可以,目前智谱AI的GLM4送token,就拿它来试验吧)
- 准备一个本地sqlite数据库,并创建数据库test.db,以及表和存入数据,脚本如下
sqllite3 test.db
create table student(id Integer,name char,score Integer);
insert into student values(1,“student1”,100);
insert into student values(2,“student2”,80);
insert into student values(3,“student3”,50);
代码如下:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain.chains import create_sql_query_chain
from langchain_community.utilities import SQLDatabase
# 前置工作1:创建llm
llm = ChatOpenAI(
temperature=0.01,
model="glm-4",
openai_api_key="你的API KEY",
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
# 前置工作2:改写了一下prompt(因为默认的prompt似乎不适合智谱AI)
_sqlite_prompt = """你是一个SQLite专家。给定一个输入问题,首先创建一个语法正确的SQLite查询来运行,然后查看查询的结果并返回输入问题的答案。
除非用户在问题中指定要获取的特定数量的示例,否则根据SQLite使用LIMIT子句查询最多{top_k}个结果。您可以对结果进行排序,以返回数据库中信息量最大的数据。
永远不要查询表中的所有列。您必须只查询回答问题所需的列。将每个列名用双引号(")括起来,以表示它们为分隔符。
注意,只使用您可以在下面的表中看到的列名。注意不要查询不存在的列。另外,要注意哪个列在哪个表中。
如果问题涉及“今天”,注意使用date('now')函数来获取当前日期
使用以下格式:
问题:问题
SQLQuery:要运行的SQL查询
答案:最终答案
只使用以下表格:
{table_info}
问题: {input}
"""
SQLITE_PROMPT = PromptTemplate(
input_variables=["input", "table_info", "top_k"],
template=_sqlite_prompt,
)
db = SQLDatabase.from_uri("sqlite:///sqlite-autoconf-3460000/test.db") # 你的数据库地址
# 使用create_sql_query_chain的方式,langchain还有agent方式,大家可以去探索使用
chain = create_sql_query_chain(llm, db, SQLITE_PROMPT)
response = chain.invoke({"question": "总共有多少学生"})
print(response)
4 Text-to-Cypher
对于图形数据库的作用,一般就是表示实体之间的关系,适合于知识图谱、人际关系等应用场景。
下面以查询neo4j图数据库为例子,,做一个demo代码演示。在运行代码之前我们需要做以下前置条件
- 这里采用智谱AI的API接口,因此可以先去申请一个API KEY(当然你使用其它模型也可以,目前智谱AI的GLM4送token,就拿它来试验吧)
- 准备一个本地neo4j数据库,并创建数据库test_relationship,录入一些作家、书籍以及相关关系
from langchain.chains import GraphCypherQAChain
from langchain_community.graphs import Neo4jGraph
from langchain_openai import ChatOpenAI
# 前置工作1:创建llm
llm = ChatOpenAI(
temperature=0.95,
model="glm-4",
openai_api_key="你的API KEY",
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
# 前置工作2:准备好图形数据库
graph = Neo4jGraph(
url="bolt://localhost:7687", username="test_relationship", password="***"
)
graph.refresh_schema()
# 使用langchain的GraphCypherQAChain进行封装,这里面的提示效果对于智谱AI来说一般般,没调试出来最终结果
chain = GraphCypherQAChain.from_llm(llm, graph=graph, verbose=True)
print(chain.run("谁是一地鸡毛的作者?"))
5 Text-to-SQL+ Semantic
现在混合类型(结构化和非结构化)数据存储越来越普遍。向关系数据库添加向量支持是支持混合检索方法的关键推动因素。比如PostgreSQL 的开源 pgvector 扩展将 SQL 的表现力与语义搜索提供的对语义的细致入微的理解相结合。那么在如何将用户问题转换为这种混合类型数据库就提出了更高的挑战。
在对这种类型数据库,更加复杂的query生成,需要创建few-shot prompt或者增加query-checking等环节来提升准确度,这里就不举例子,有兴趣深入的同学可以搜索研究。



















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











