








本项目源于ML2021Spring-hw1 | Kaggle,数据集取自该项目
class covidDataset(Dataset): # mode用于知道是训练集还是测试集
def __init__(self, file_path, mode):
with open(file_path, "r") as f:
ori_data = list(csv.reader(f))
# 把读的object类型,通过list转变为对象
csv_data = np.array(ori_data[1:])[:, 1:].astype(float)
if mode == "train":
indices = [i for i in range(len(csv_data)) if i % 5 != 0]
self.y = torch.tensor(csv_data[indices, -1])
elif mode == "val":
indices = [i for i in range(len(csv_data)) if i % 5 == 0]
self.y = torch.tensor(csv_data[indices, -1])
else:
indices = [i for i in range(len(csv_data))]
data = torch.tensor(csv_data[indices, :-1])
self.data = (data - data.mean(dim=0, keepdim=True)) / data.std(dim=0, keepdim=True)
self.mode = mode
# 给下标取值
def __getitem__(self, item):
if self.mode != "test":
return self.data[item].float(), self.y[item].float()
else:
return self.data[item].float()
def __len__(self):
return len(self.data)Dataset类一般都包含init getitem len三个函数,这三个函数必须有,别的辅助函数可以视情况而定。init为读取文件中的数据,此处多增加了一个mode的参数值,用来判断本次数据处理的训练集,验证集还是测试集。file_path是excel文件所在的文件路径。
ori_data是原始数据,csv.reader读出的是一个object类型,所以还需要用list转为可使用的数据。f就是 with open(file_path, "r")。list类型只能取单独的一个,所以要用np.array 转换成矩阵类型,从而去除对应数据集的第一行和第一列。
-
ori_data[1:]: 这部分表示从原始数据
ori_data中取出所有行,但忽略第一行。 -
[:, 1:]: 最后这部分是对新创建的NumPy数组进行切片操作,它表示取所有行(
:)且忽略每行的第一个元素(即从第二个元素开始,索引为1)。
第一行是地区名字,不用进行训练,删除。第一列是ID,为一个自增的数据类型,不参与训练,删除。 excel中的数据都是字符串类型,需要用astype转变为float类型。
训练集,测试集,验证集的各种类型的数据需要数不同,训练集的数据需求多,所以取的值是5个中取四个,只有当下标被5整除时,才不取。同理验证集合的需求数量少,下标当被5整除时才取。测试集是需要所有的数据都放进来,然后进行预测。data中的值是每个地区的数据,通过这些数据来训练出最后一列的结果,所以data中不用取最后一列的值
csv_data[indices, :-1]:取对应的下标的列,y就是excel中的最后一列(训练集和验证集),测试集的y是你要输出的部分,所以不用在初始化的时候读入。
getitem是取数据的作用,data是在init中 ,需要使用self来进行传递,使用self后就能在不同函数中进行使用了。测试集中没有y的值,不用管,使用if语句来判断mode类型
data.mean(dim=0, keepdim=True): 计算 data 在指定维度(这里是0维度,代表按列操作)上的均值,并保持输出形状与原数据相同(keepdim=True 确保平均值的形状与原始数据在指定维度上一致,即增加一个维度为1)
对data的处理就是进行标准化,X-EX/DX。(应该是,反正就正态分布那个)。KeepDim是保持原有的维度不变。
batch_size = 16
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1, shuffle=False)batch_size=16,一组为16个,是随机梯度下降的每组的个数。shuffle为打乱取16个,这句话就是通过16个为一组,进行数据的loss计算 test中为输出答案了,所以shuffle不能打乱。
把train_loader理解为一个载体,用于承载一组训练的数据量,并按照指定的方式(如批量大小、是否打乱顺序等)向你的模型提供这些数据。shuffle为随机选取,整体意思是从train_dataset中随机选取16个数据为一组,放进一个载体中然后进行后续操作。
class MyModel(nn.Module):
def __init__(self, indim):
super(MyModel, self).__init__()
self.fci1 = nn.Linear(indim, 64)
self.relu1 = nn.ReLU()
self.fci2 = nn.Linear(64, 1)
def forward(self, x): # 模型前项过程
x = self.fci1(x)
x = self.relu1(x)
x = self.fci2(x)
if len(x.size()) > 1:
return x.squeeze(1) # 要与batch_y的维度对应上
return xForward的函数就是下图的黑线,进行推送处理。
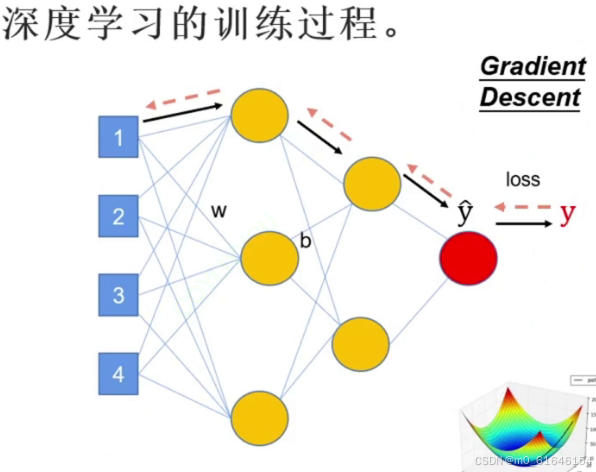
现在的网路只有2层,(93,64),(64,1)
x目前为二维,无法与y的维度对应,所以需要使用if语句对x的维度进行调整
device = "cuda" if torch.cuda.is_available() else "cpu"
config = {
"lr": 0.0001,
"epoch": 20,
"momentum": 0.9,
"save_path": "model_save/best_model.pth",
"rel_path": "pred_csv1"
}
model = MyModel(indim=93).to(device)
loss = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=config["lr"], momentum=config["momentum"])
# train_val(model, train_loader,val_loader device, config["epoch"], optimizer, loss, config["save_path"])
evaluate(config["save_path"], test_loader, device, config["rel_path"])
train_val里的参数分别是:模型,训练载体,设备,论数,优化器,loss,保存路径
def train_val(model, train_loader, val_loader,device, epochs, optimizer, loss, save_path):
model = model.to(device)
plt_train_loss = []
plt_val_loss = []
min_val_loss = 99999999999
for epoch1 in range(epochs):
train_loss = 0.0
val_loss = 0.0
start_time = time.time()
model.train()
for batch_x, batch_y in train_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
train_bat_loss = loss(pred, target)#计算loss
train_bat_loss.backward()#回传
optimizer.step()#更新模型
optimizer.zero_grad()
train_loss += train_bat_loss.cpu().item()#取数值
plt_train_loss.append(train_loss / train_loader.__len__())#把每轮的loss值都记录下来
model.eval()
with torch.no_grad():
for batch_x, batch_y in val_loader:
x, target = batch_x.to(device), batch_y.to(device)
pred = model(x)
val_bat_loss = loss(pred, target)
val_loss += val_bat_loss.cpu().item()
plt_val_loss.append(val_loss / val_loader.__len__())
if val_loss < min_val_loss:
torch.save(model, save_path)
min_val_loss = val_loss
print("[%03d/%03d %2.2f sec(s) Trainloss: %.6f |Valloss: %.6f" % \
(epoch1, epochs, time.time() - start_time, plt_train_loss[-1], plt_val_loss[-1]))
plt.plot(plt_train_loss)
plt.plot(plt_val_loss)
plt.title("loss")
plt.legend(["train", "val"])
plt.show()
model.train和model.eval都是把模型切换到训练模式和验证模式,训练模式中需要对梯度进行处理更新,验证模式中不需要,所以用了torch.no_grad()进行处理。并且在验证中,找到最好的对数据处理的模型,进行记录和保存,利用loss值进行比较。保存好的模型用于之后的测试集。
def evaluate(save_path, test_loader, device, rel_path):
model = torch.load(save_path).to(device) # 加载模型
rel = [] # 存储结果
with torch.no_grad():
for x in test_loader:
pred = model(x.to(device))
rel.append(pred.cpu().item())
print(rel)
with open(rel_path, "w",newline='') as f:
csvWriter = csv.writer(f)
csvWriter.writerow(["id", "tested_positive"])#输出格式的第一行
for i, value in enumerate(rel):
csvWriter.writerow([str(i), str(value)])
print("文件已保存到"+rel_path)
对数据进行测试和输出结果,使用最好的模型,输入x值,最后得到一个想要预测的结果并打印到文件中。文件保存到rel_path中。

















 2157
2157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









