







MPC简介
提到MPC不得不说一下反应控制Reactive Control和最优控制Optimal Control
Reactive Control通过在被控量上面加上误差乘以反馈增益达到控制的效果
它的设计很简单,缺点也很明显,PID手动调参困难并且没办法解决动态扰动并且其获取的解也不是最优解。
有没有什么办法可以获得一个系统的最优解呢,可以考虑最优控制,最优控制基于状态空间模型,首先对系统进行建模,获得状态空间模型。
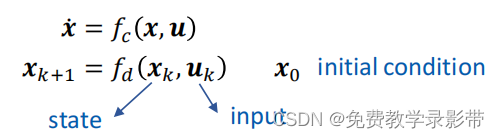
设计合适的目标函数Objective function以及约束,利用模型计算出后续所有状态的state,并最小化cost,得到而后每一步的最优输入交给系统去执行。
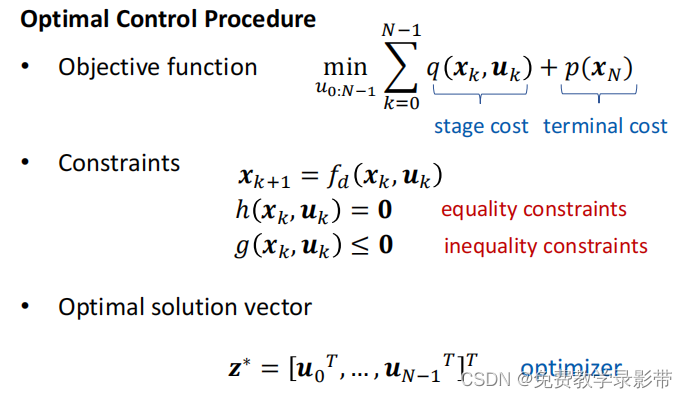
现在我们获得了问题的最优解,但是依然没法解决动态外部扰动,一旦环境发生改变,那么这个解就不一定事最优解了,所以考虑模型预测控制 Model Predictive Control(MPC)来对系统控制。
MPC像是一种介于反馈控制和最优控制之间的一种控制方法
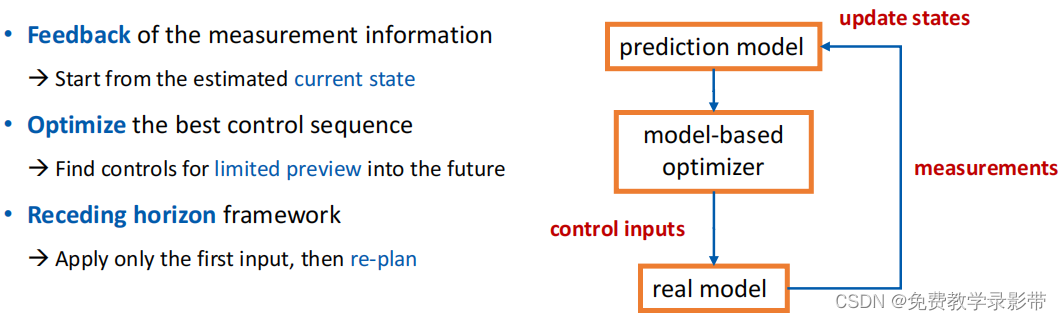
首先对系统建模,设计和最优控制类似的目标函数,计算后面N步的Cost对其优化得到后面N步的最优输入,然后重点来了:只取计算出后面N步最优输入计算结果的第一步作为下一步的输入,而不是将计算结果全部输入。然后再下一步的时候,再计算后面N步也是选择第一步作为输入,重复循环这个过程直到目标。

所以我们可以认为MPC就是计算后面N步最优控制问题,然后只取其中第一步进行输入。这样就可以在动态环境中进行实时控制。但是缺点也很明显,由于要实时计算,所以对设备的算力有要求,N取的越大,每步时间间隔dt越小,计算量就越大。
线性MPC,即目标函数和约束均为线性,我们可以通过二次规划进行简单的求解。




可以得到一个唯一的最优解
下面是一些MPC工具箱
• Matlab MPC toolbox: https://www.mathworks.com/products/mpc.html• μAO-MPC: http://ifatwww.et.uni-magdeburg.de/syst/muAO-MPC/• Acado toolkit: https://acado.github.io/• YANE: http://www.nonlinearmpc.com/• Multi-Parametric Toolbox 3: https://www.mpt3.org/
LQR
此外,经常与MPC比较的一种控制方法是 Linear Quadratic Regulator(LQR)
LQR基于动态规划的思想
贝尔曼最优原则
"An optimal policy has the property that, regardless of the decisions taken to enter a particular state, the remaining decisions made for leaving that stage must constitute an optimal policy."
如果一个问题可以分为多个步骤 ,它的最优解有这样的性质,不管前面的决策是怎样到达一个状态的,剩下的决策仍然是后面的子问题的最优解
对于我们这个问题而言,目标函数如下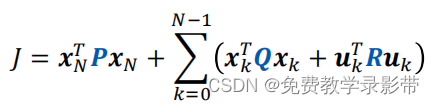
我们可以得到对于第N步的cost![]() 仅与第N步的状态xN有关,而第N步的状态可以通过N-1步加系统模型得到。
仅与第N步的状态xN有关,而第N步的状态可以通过N-1步加系统模型得到。
下面再写出第N-1步的Cost,等于第N步的最优cost加前面N-1步的cost,可以看出其只跟N-1步的状态x和N-1步的输入u有关。
我们对输入求导得到最优的输入u*

接下来把u*带入N-1的cost内得到N-1步的最优Cost,
然后再算N-2步的最优Cost,然后继续计算直到得到每一步的最优输入u*
其中整理得到每一步cost中间矩阵为黎卡缇矩阵

计算到最后得到第一步的输入u0*和x0的关系,就可以根据当前状态得到最优输入给系统去执行。
由于MPC中的z*求解需要求逆,所以复杂度为O(N^3),而LQR复杂度为线性O(N)。
LQR是一种特殊的MPC,它是无限horizon的,MPC是有限的,缺点是LQR通常没办法施加约束
线性MPC举例
假设输入的是Jerk,对三阶积分模型建模,离散化时间
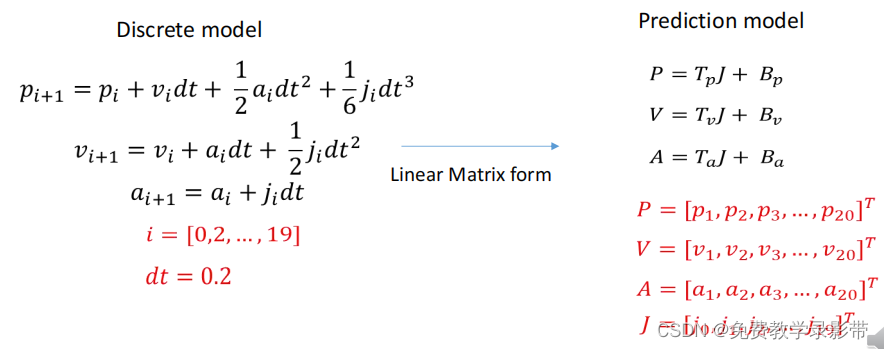
可以把目标位置,速度,加速度用J表示出来
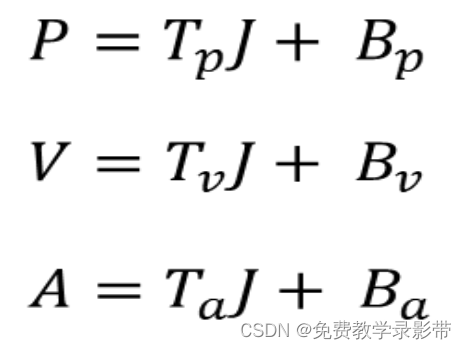
优化目标:让位置,速度,加速度和Jerk尽可能小
![]()
把上面算出来的PVA带入目标函数得到1个只关于J的函数

将中间的一大块表达式用矩阵H和F代替,再求导可以得到这个优化问题的闭式解
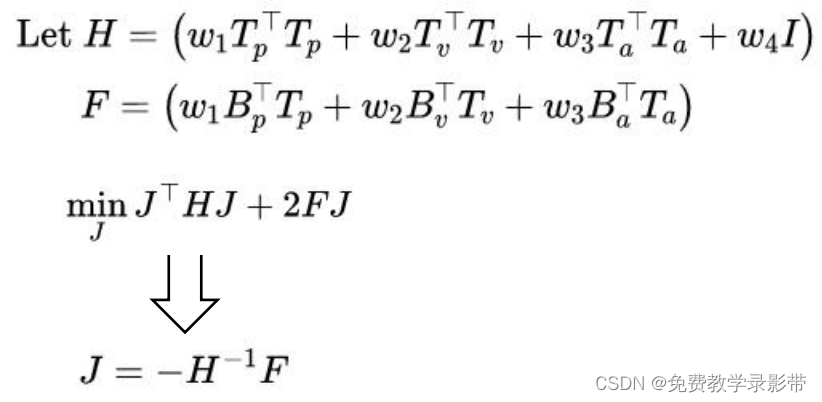
此外可以添加硬约束来限制速度,加速度以及Jerk,防止其超过最大值
这里对VA加约束,对每个离散时间点都加上最大最小值为1的约束,
注意优化器里面没有大于,所以所有的不等式约束都要通过加负号的方式化成小于号

有的时候初速度大于了最大速度,这个时候优化器计算结果是无解

可以将速度约束变为软约束,即把速度项作为惩罚函数加到目标函数内
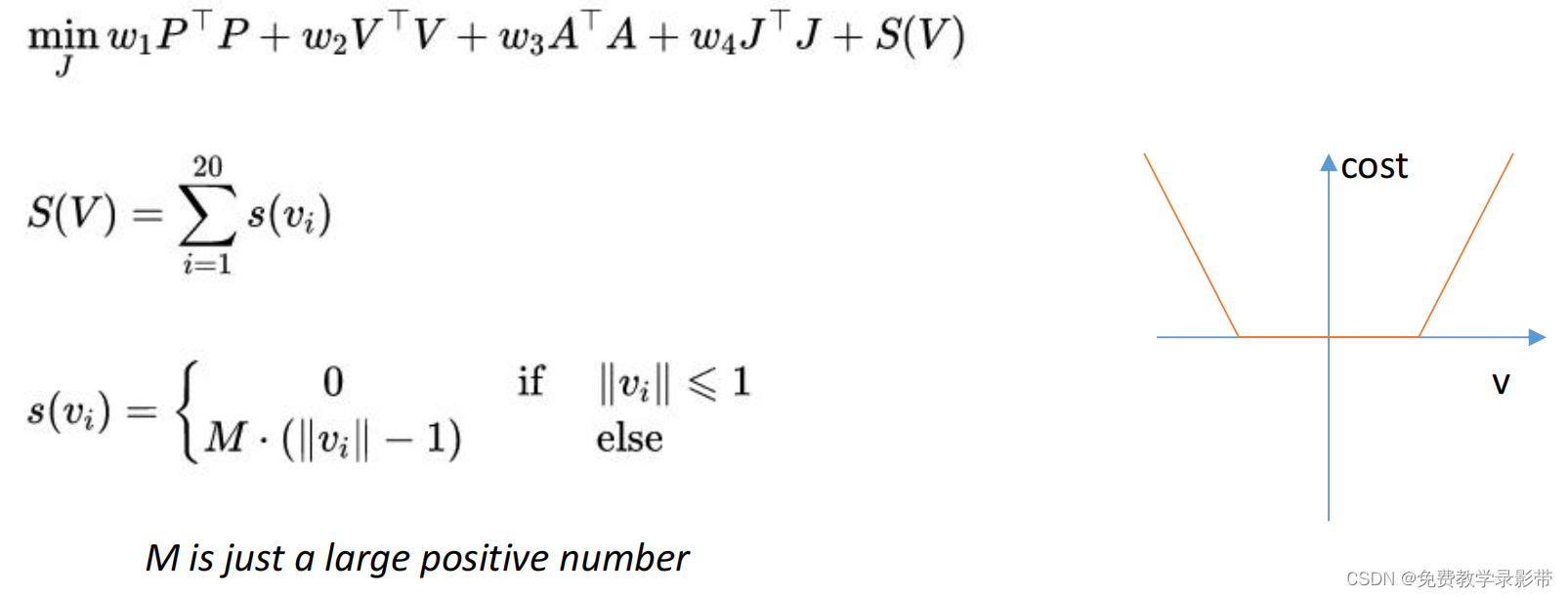
惩罚函数可以选择线性或者指数函数
另外一种施加软约束的方法是通过松弛变量的方法,在速度的硬约束项中加入松弛变量L,然后在目标函数中也加入对应项,此时优化变量变为[J L],

Matlab仿真代码(无约束)
clear all;
close all;
clc;
p_0 = 10;
v_0 = 0;
a_0 = 0;
K=20; %步数
dt=0.2; %每步时间间隔0.2s
log=[0 p_0 v_0 a_0];
w1 = 1; %位置权重
w2 = 1; %速度权重
w3 = 1; %加速度权重
w4 = 1; %Jerk权重
for t=0.2:0.2:10
%% Construct the prediction matrix
[Tp, Tv, Ta, Bp, Bv, Ba] = getPredictionMatrix(K,dt,p_0,v_0,a_0);
%% Construct the optimization problem 构建优化问题
H = w4*eye(K)+w1*(Tp'*Tp)+w2*(Tv'*Tv)+w3*(Ta'*Ta);
F = w1*Bp'*Tp+w2*Bv'*Tv+w3*Ba'*Ta;
%% Solve the optimization problem
J = quadprog(H,F,[],[]);
%J = -(H^-1) * F'; %闭式解法,可以直接算出J
%% Apply the control
j = J(1); % MPC,仅选择算出来的第一步作为输入
p_0 = p_0 + v_0*dt + 0.5*a_0*dt^2 + 1/6*j*dt^3;
v_0 = v_0 + a_0*dt + 0.5*j*dt^2;
a_0 = a_0 + j*dt;
%% Log the states
log = [log; t p_0 v_0 a_0];
end
%% Plot the result
plot(log(:,1),log(:,2:4));
grid on;
xlabel('t(s)');
legend('p','v','a');
MATLAB的quadprog函数讲解
(2条消息) 【MPC】①二次规划问题MATLAB求解器quadprog_后厂村路蔡徐坤的博客-CSDN博客_matlab求解二次规划
getPredictionMatrix函数
function [Tp, Tv, Ta, Bp, Bv, Ba] = getPredictionMatrix(K,dt,p_0,v_0,a_0)
Ta=zeros(K);
Tv=zeros(K);
Tp=zeros(K);
for i = 1:K
Ta(i,1:i) = ones(1,i)*dt;
end
for i = 1:K
for j = 1:i
Tv(i,j) = (i-j+0.5)*dt^2;
end
end
for i = 1:K
for j = 1:i
Tp(i,j) = ((i-j+1)*(i-j)/2+1/6)*dt^3;
end
end
Ba = ones(K,1)*a_0;
Bv = ones(K,1)*v_0;
Bp = ones(K,1)*p_0;
for i=1:K
Bv(i) = Bv(i) + i*dt*a_0;
Bp(i) = Bp(i) + i*dt*v_0 + i^2/2*a_0*dt^2;
end运行结果:
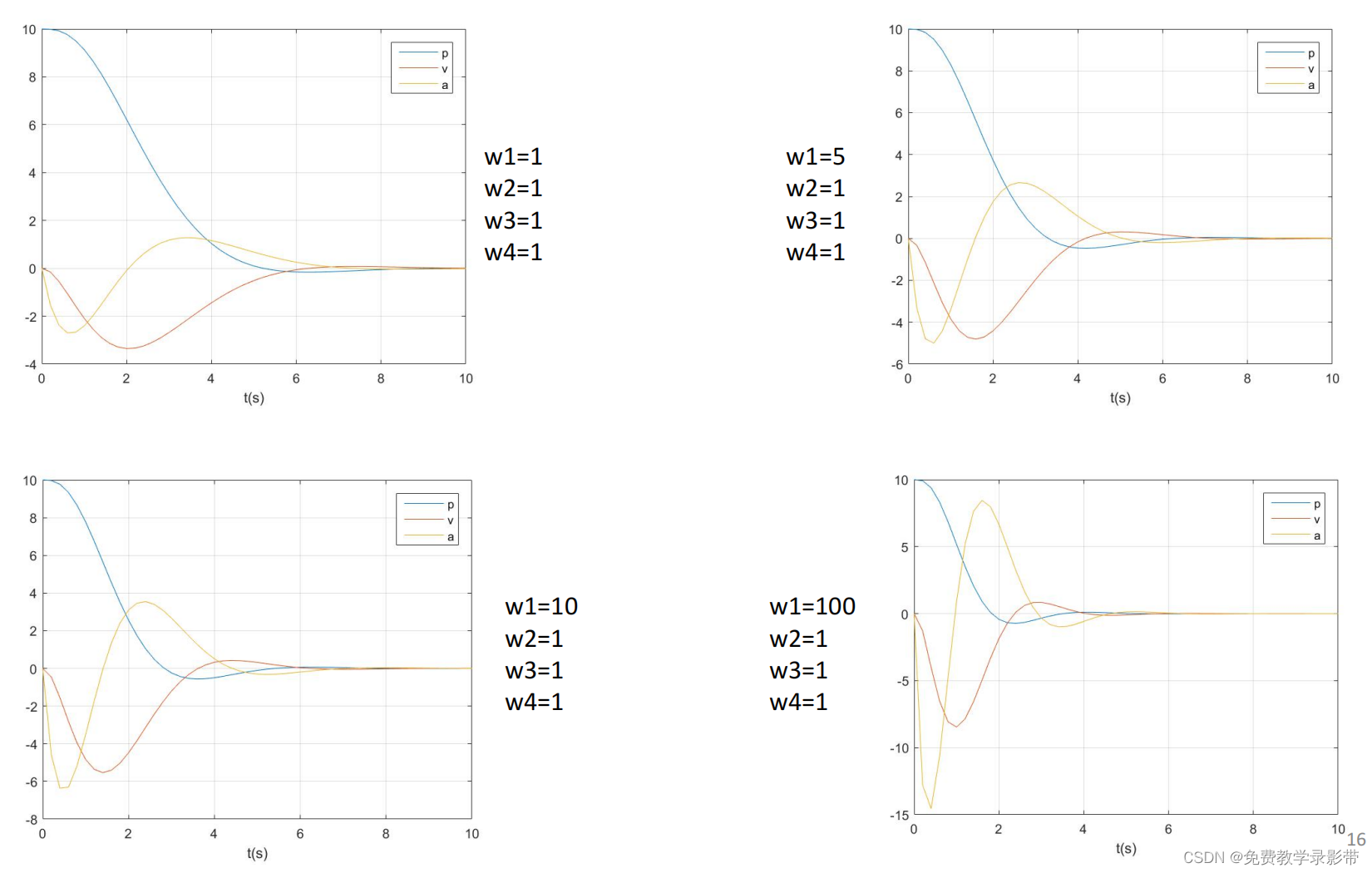
p的权重越大,越快收敛
下面是有约束的情况
(1)施加硬约束
%% Construct the optimization problem
H = w4*eye(K)+w1*(Tp'*Tp)+w2*(Tv'*Tv)+w3*(Ta'*Ta);
F = w1*Bp'*Tp+w2*Bv'*Tv+w3*Ba'*Ta;
A = [Tv;-Tv;Ta;-Ta];
b = [ones(20,1)-Bv;ones(20,1)+Bv;ones(20,1)-Ba;ones(20,1)+Ba];
%% Solve the optimization problem
J = quadprog(H,F,A,b); % Ax<b
运行结果
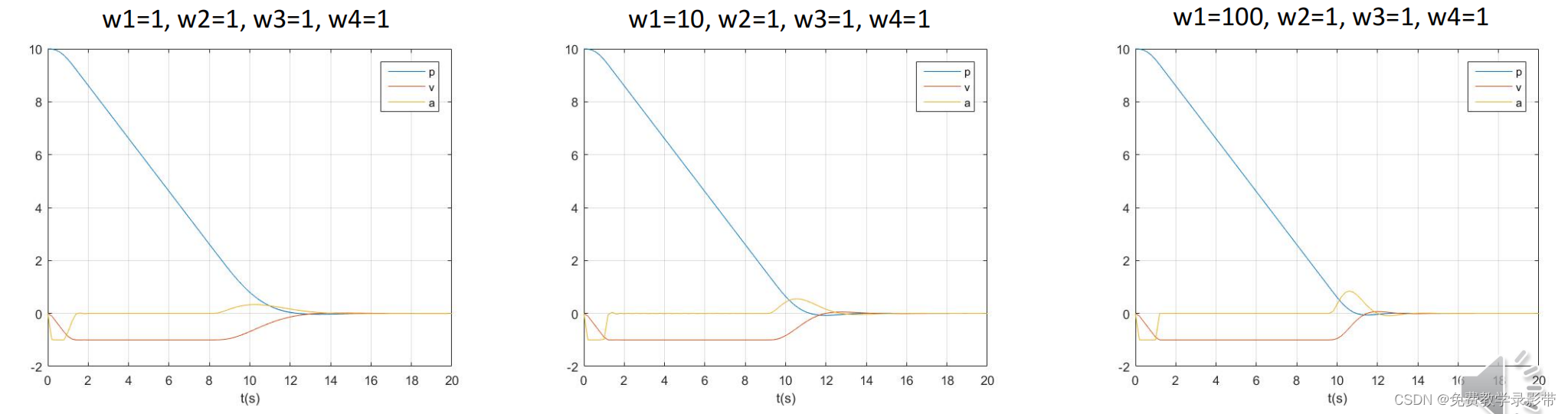
可以看到速度和加速度都被约束到+-1内了
但是问题是如果初速度比较大(这里是大于1),就会计算错误,所以施加软约束
(2)软约束
clear all;
close all;
clc;
p_0 = 10;
v_0 = -3;
a_0 = 0;
K=20;
dt=0.2;
log=[0 p_0 v_0 a_0];
w1 = 10;
w2 = 1;
w3 = 1;
w4 = 1;
w5 = 1e4;
for t=0.2:0.2:20
%% Construct the prediction matrix
[Tp, Tv, Ta, Bp, Bv, Ba] = getPredictionMatrix(K,dt,p_0,v_0,a_0);
%% Construct the optimization problem
H = blkdiag(w4*eye(K)+w1*(Tp'*Tp)+w2*(Tv'*Tv)+w3*(Ta'*Ta),w5*eye(K));
F = [w1*Bp'*Tp+w2*Bv'*Tv+w3*Ba'*Ta zeros(1,K)];
A = [Tv zeros(K);-Tv -eye(K);Ta zeros(K); -Ta zeros(K); zeros(size(Ta)) -eye(K)];
b = [ones(20,1)-Bv;ones(20,1)+Bv;ones(20,1)-Ba;ones(20,1)+Ba; zeros(K,1)];
%% Solve the optimization problem
J = quadprog(H,F,A,b);
%% Apply the control
j = J(1);
p_0 = p_0 + v_0*dt + 0.5*a_0*dt^2 + 1/6*j*dt^3;
v_0 = v_0 + a_0*dt + 0.5*j*dt^2;
a_0 = a_0 + j*dt;
%% Log the states
log = [log; t p_0 v_0 a_0];
end
%% Plot the result
plot(log(:,1),log(:,2:4));
grid on;
xlabel('t(s)');
legend('p','v','a');
运行结果
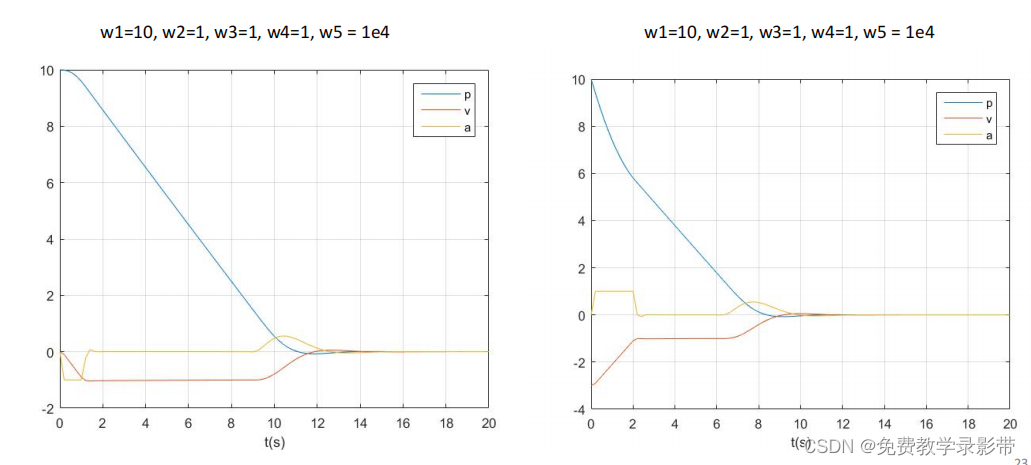
可以看到,初速度设置在-3,会很快进入限制区间内
MPC使用举例:
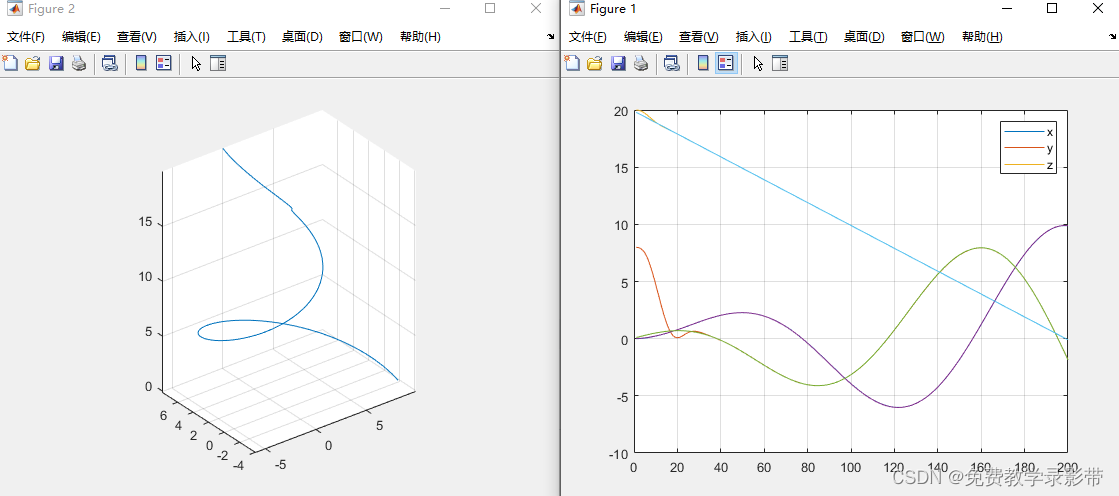
使用MPC跟踪下面的螺旋线,螺旋线转速0.08rad/s,z方向速度为-0.5m/s。三个方向上的约束在右边。
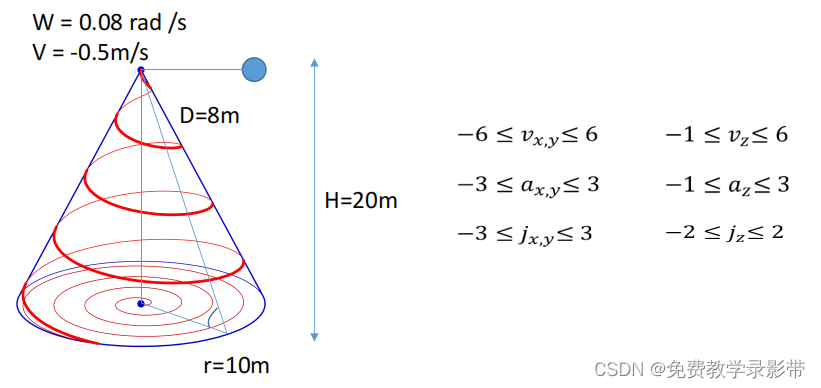
这里在设计的时候注意Cost Function变了,因为我们追踪的目标在不断变化,所以我们将P改为
在H矩阵中多加三项:-P_{target} * Tp - V_{target} * Tv - A_{target} * Ta
此外设置速度,加速度,jerk为硬约束
代码
clear all;
close all;
clc;
p_0 = [0 8 20];
v_0 = [0 0 0];
a_0 = [0 0 0];
K=20;
dt=0.2;
P=[];
V=[];
A=[];
for t=0.2:0.2:40
%% Construct the reference signal
% 创建螺旋线
for i = 1:20
tref = t + i*0.2;
r=0.25*tref;
pt(i,1) = r*sin(0.2*tref);
vt(i,1) = r*cos(0.2*tref);
at(i,1) = -r*sin(0.2*tref);
pt(i,2) = r*cos(0.2*tref);
vt(i,2) = -r*sin(0.2*tref);
at(i,2) = -r*cos(0.2*tref);
pt(i,3) = 20 - 0.5*tref;
vt(i,3) = -0.5;
at(i,3) = 0;
end
%% Do the MPC
%% Please follow the example in linear mpc part to fill in the code here to do the tracking
for i = 1:3
j(i) = mpc(K,dt,p_0,v_0,a_0,pt,vt,at,i); % 使用mpc求出一个最优的 j 给无人机去执行
end
for i=1:3
[p_0(i),v_0(i),a_0(i)] = forward(p_0(i),v_0(i),a_0(i),j(i),dt);% 根据p v a 和优化出的j计算出下一个状态
end
%% Log the states
P = [P;p_0 pt(1,:)];
V = [V;v_0 vt(1,:)];
A = [A;a_0 at(1,:)];
end
%% Plot the result
plot(P);
grid on;
legend('x','y','z');
figure;
plot3(P(:,1),P(:,2),P(:,3));
axis equal;
grid on;同样进行20步的预测,然后取第一步为最优作为输入
函数如下:
function j = mpc(K,dt,p_0,v_0,a_0,pt,vt,at,i)
w1 = 100;
w2 = 1;
w3 = 1;
w4 = 1;
% Cost Funtion
[Tp, Tv, Ta, Bp, Bv, Ba] = getPredictionMatrix(K,dt,p_0(i),v_0(i),a_0(i));
H = w4*eye(K)+w1*(Tp'*Tp)+w2*(Tv'*Tv)+w3*(Ta'*Ta);
F = w1*Bp'*Tp+w2*Bv'*Tv+w3*Ba'*Ta - w1*pt(:,i)'*Tp - w2*vt(:,i)'*Tv - w3*at(:,i)'*Ta;
% F = w1*(Bp-pt)'*Tp+w2*(Bv-vt)'*Tv+w3*(Ba-at)'*Ta;
% 约束,不等式约束 Ax < b
% xy速度限制在±6,加速度±3,j ± 3。
% z速度限制-1到6,加速度-1到3,jerk -2到2
if i ~= 3
A = [Tv;-Tv;Ta;-Ta];
b = [6*ones(20,1)-Bv; 6*ones(20,1) + Bv; 3*ones(20,1) - Ba; 3*ones(20,1) + Ba];
lb = -3*ones(20,1);
ub = 3 * ones(20,1);
J = quadprog(H,F,A,b,[],[],lb,ub);
j = J(1);
else
A = [Tv;-Tv;Ta;-Ta];
b = [6*ones(20,1)-Bv; 1*ones(20,1) + Bv; 3*ones(20,1) - Ba; 1*ones(20,1) + Ba];
lb = -2*ones(20,1);
ub = 2 * ones(20,1);
J = quadprog(H,F,A,b,[],[],lb,ub);
j = J(1);
end
endforward函数
function [p_0,v_0,a_0] = forward(p_0,v_0,a_0,j,dt)
p_0 = p_0 + v_0*dt + 0.5*a_0*dt^2 + 1/6*j*dt^3;
v_0 = v_0 + a_0*dt + 0.5*j*dt^2;
a_0 = a_0 + j*dt;得到的结果如下
















 3195
3195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









