







目录
理论介绍
在神经网络的计算中,无非就是矩阵相乘,输入的是线性,不论输出层有多少,相当于n个矩阵相乘,和一层相乘所获取的信息差距不大,那我们无非是要引入非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中,增加了神经网络模型泛化的特性。
早期研究神经网络主要采用sigmoid函数或者tanh函数,输出有界,很容易充当下一层的输入。 近些年Relu函数及其改进型(如Leaky-ReLU、P-ReLU、ELU等),由于计算简单、效果好所以在多层神经网络中应用比较多。
常见的激活函数
# 下面内容都要有此片段
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
x= torch.linspace(-10,10,60) A. sigmoid函数
导数 :
在sigmoid函数中我们可以看到,其输出是在(0,1)这个开区间,它能够把输入的连续实值变换为0和1之间的输出,如果是非常大的负数,那么输出就是0;如果是非常大的正数输出就是1,起到了抑制的作用。
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.spines['bottom'].set_position(('data', 0))
ax.yaxis.set_ticks_position('left')
ax.spines['left'].set_position(('data', 0))
plt.ylim((0, 1))
sigmod=torch.sigmoid(x)
plt.plot(x.numpy(),sigmod.numpy())
plt.show() 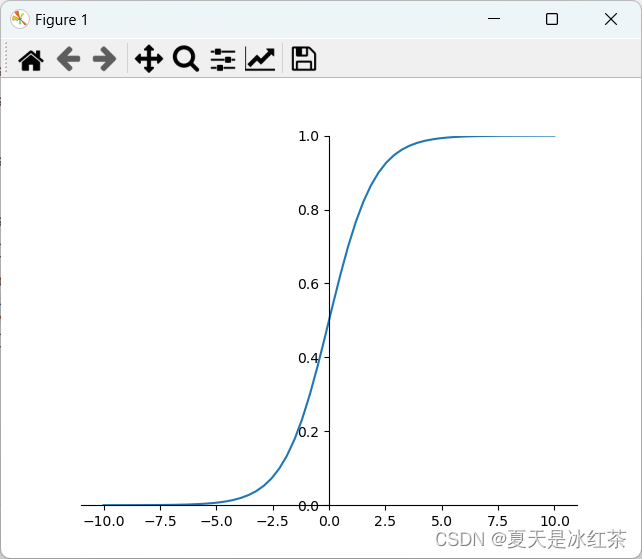
图7 sigmod图
但是sigmod由于需要进行指数运算(相比relu这个对于计算机来说是比较慢),再加上函数输出不是以0为中心的(这样会使权重更新效率降低),当输入稍微远离了坐标原点,函数的梯度就变得很小了(几乎为零)。在神经网络反向传播的过程中不利于权重的优化,这个问题叫做梯度饱和,也可以叫梯度弥散。这些不足,所以现在使用到sigmod基本很少了,基本上只有在做二元分类(0,1)时的输出层才会使用。
B. tanh
导数:
tanh是双曲正切函数,输出区间是在(-1,1)之间,而且整个函数是以0为中心的。
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.spines['bottom'].set_position(('data', 0))
ax.yaxis.set_ticks_position('left')
ax.spines['left'].set_position(('data', 0))
plt.ylim((-1, 1))
tanh=torch.tanh(x)
plt.plot(x.numpy(),tanh.numpy())
plt.show() 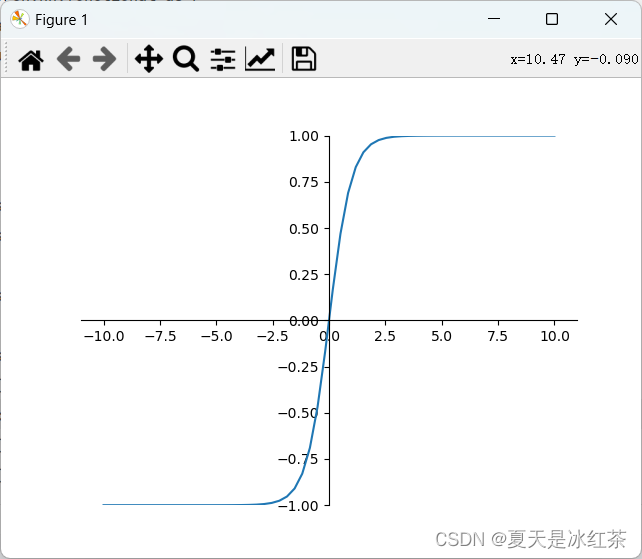
图7 sigmod图
与sigmoid函数类似,当输入稍微远离了坐标原点,梯度还是会很小,但是好在tanh是以0为中心点,如果使用tanh作为激活函数,还能起到归一化(均值为0)的效果。
一般二分类问题中,隐藏层用tanh函数,输出层用sigmod函数,但是随着Relu的出现所有的隐藏层基本上都使用relu来作为激活函数了。
C.ReLu
Relu修正线性单元
导数大于0时1,小于0时0。
也就是说: z>0时,梯度始终为1,从而提高神经网络基于梯度算法的运算速度。然而当 z<0时,梯度一直为0。 ReLU函数只有线性关系(只需要判断输入是否大于0)不管是前向传播还是反向传播,都比sigmod和tanh要快很多,当输入是负数的时候,ReLU是完全不被激活的,这就表明一旦输入到了负数,ReLU就会死掉。但是到了反向传播过程中,输入负数,梯度就会完全到0,这个和sigmod函数、tanh函数有一样的问题。 但是实际的运用中,该缺陷的影响不是很大。
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.spines['bottom'].set_position(('data', 0))
ax.yaxis.set_ticks_position('left')
ax.spines['left'].set_position(('data', 0))
plt.ylim((-3, 10))
relu=F.relu(x)
plt.plot(x.numpy(),relu.numpy())
plt.show() 
图7 Relu图
D.ReLU的变种
Leaky Relu 函数
为了解决relu函数z<0时的问题出现了 Leaky ReLU函数,该函数保证在z<0的时候,梯度仍然不为0。 ReLU的前半段设为αz而非0,通常
α=0.01,a=max(αz,z)
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.spines['bottom'].set_position(('data', 0))
ax.yaxis.set_ticks_position('left')
ax.spines['left'].set_position(('data', 0))
plt.ylim((-3, 10))
l_relu=F.leaky_relu(x,0.1) # 这里的0.1是为了方便展示,理论上应为0.01甚至更小的值
plt.plot(x.numpy(),l_relu.numpy())
plt.show() 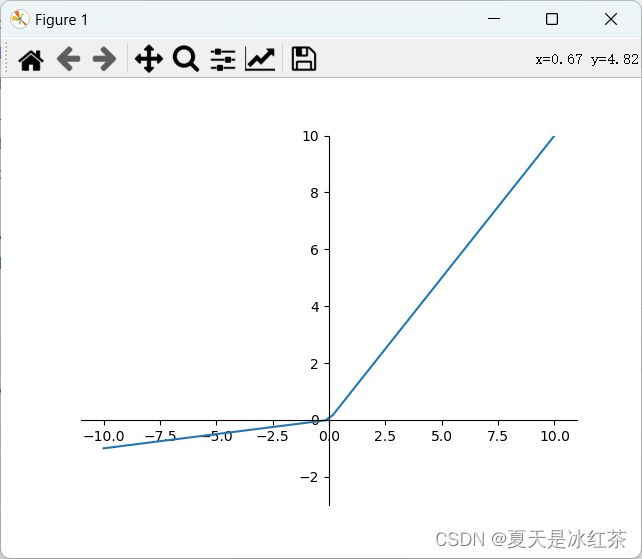
图7 Leaky Relu图
Parametric ReLU (PReLU)
PReLU是一种引入可学习参数的ReLU变种,它允许负数区域的斜率成为可学习的参数。这使得神经网络能够根据数据自适应地学习激活函数的形状。公式如下:
f(x) = max(ax, x)
p_relu = F.prelu(x, torch.tensor(0.25)) # 使用PReLU激活函数,参数为0.25
plt.figure()
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.spines['bottom'].set_position(('data', 0))
ax.yaxis.set_ticks_position('left')
ax.spines['left'].set_position(('data', 0))
plt.ylim((-3, 10))
plt.plot(x.numpy(), p_relu.numpy(), label='PReLU')
plt.legend()
plt.title('PReLU Activation')
plt.show() 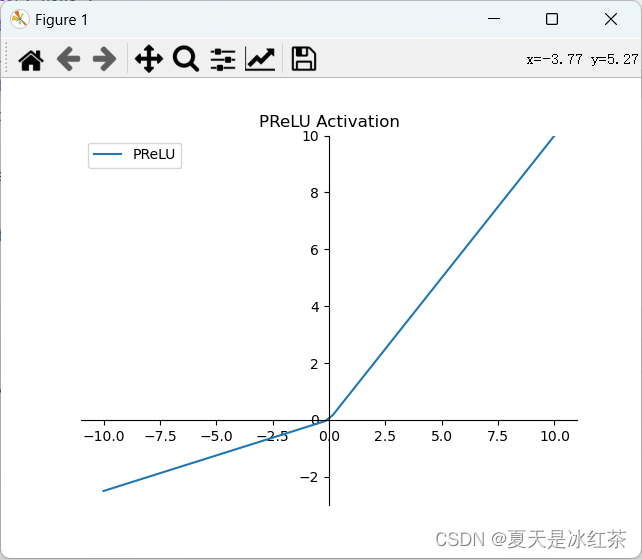
图8 Parametric Relu图
Exponential Linear Unit (ELU)
ELU是在负数区域引入一个指数衰减的激活函数,以解决ReLU在负数区域的问题。它提供了一个平滑的曲线,并具有负饱和度,可以减少梯度消失的问题。公式如下:
f(x) = x if x > 0
alpha * (exp(x) - 1) if x <= 0
其中,alpha是一个正数,控制ELU在负数区域的斜率。

图9 Exponential Linear Unit图
在实践中,ReLU和其变种的使用情况会因任务和数据的不同而有所变化。然而,目前来看,ReLU仍然是最常用的激活函数。
ReLU的主要优势是计算简单且有效,能够在许多深度学习任务中提供良好的性能。它具有线性增长的特性,在正数区域上不会饱和,可以避免梯度消失问题,并且在实践中被广泛使用。
在ReLU的变种中,Leaky ReLU是最常见的选择之一。它通过引入一个小的斜率来解决ReLU在负数区域的问题,提供了更好的负数响应。Leaky ReLU在某些情况下可能比传统的ReLU效果更好。PReLU和ELU等变种相对来说使用较少,但在某些特定任务或特定数据集上可能表现出更好的性能。PReLU通过引入可学习的参数,使激活函数能够自适应地调整形状,因此在一些复杂任务中可能更有优势。ELU通过引入指数衰减的负数响应,提供了平滑的非线性特性,对于一些需要更强鲁棒性和更低误差的任务可能更合适。
实验结果及分析
当涉及到选择适当的激活函数时,我们有多个选项可供选择。ReLU及其变种、Sigmoid和Tanh是常见的激活函数,各自具有不同的特点和适用情况。以下是对它们的总结:
ReLU及其变种(Leaky ReLU、PReLU、ELU等):
- ReLU(Rectified Linear Unit)是最常用的激活函数之一。它在正数区域上表现良好,不会引起梯度消失问题,并且计算简单高效。然而,ReLU在负数区域会完全被抑制,可能导致神经元“死亡”问题。
- Leaky ReLU引入了一个小的斜率来解决ReLU的负数区域问题,以提供更好的负数响应。
- PReLU通过引入可学习的参数,使激活函数能够自适应地调整形状,适用于一些复杂任务。
- ELU在负数区域引入了指数衰减,提供平滑的非线性特性,并具有负饱和度,对于一些需要更强鲁棒性和更低误差的任务可能更合适。
Sigmoid函数:
- Sigmoid函数将输入值映射到介于0和1之间的范围,常用于二分类问题的输出层。它的平滑曲线使其在处理概率和概率分布时具有一定优势。
- 然而,Sigmoid函数存在梯度饱和的问题,导致在深度神经网络中容易发生梯度消失和梯度爆炸的现象。
Tanh函数:
- Tanh函数将输入值映射到介于-1和1之间的范围,是一种常见的激活函数。它相对于Sigmoid函数具有更大的动态范围,并且在零点附近对称,对于处理中心化数据更适用。
- 与Sigmoid函数类似,Tanh函数也存在梯度饱和的问题。
- 在实际应用中,我们需要根据任务和数据的特点来选择适当的激活函数。一般而言,ReLU及其变种在大多数情况下表现良好,尤其在深度神经网络中。Sigmoid函数和Tanh函数适用于特定的场景,如二分类问题或处理中心化数据。然而,我们也可以尝试不同的激活函数来优化神经网络的性能和收敛速度,因为最佳选择因任务而异。
















 565
565











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











