










论文:https://arxiv.org/abs/1911.11907
源码:https://github.com/huawei-noah/ghostnet
简要论述GhostNet的核心内容。
Ghost Net
1、Introduction

在训练良好的深度神经网络的特征图中,丰富甚至冗余的信息通常保证了对输入数据的全面理解。
上图是ResNet-50中第一个残差组生成的一些特征图的可视化,其中三个相似的特征图对样例用相同颜色的方框标注。其中存在许多相似的特征图对,就像一个幽灵一样。其中一个特征映射可以通过简单的操作(用扳手表示)对另一个特征映射进行变换近似得到。
作者认为特征映射中的冗余是一个成功的深度神经网络的重要特征,而不是避免冗余的特征映射,更倾向于采用它们,但以一种经济有效的方式。
怎么以很小的代价生成许多能从原始特征发掘所需信息的幽灵特征图呢?这个便是整篇论文的核心思想。
2、Approach
主流CNN计算的中间特征映射存在广泛的冗余,比如上面的ResNet-50,依此提出了可以减少它所需的资源。
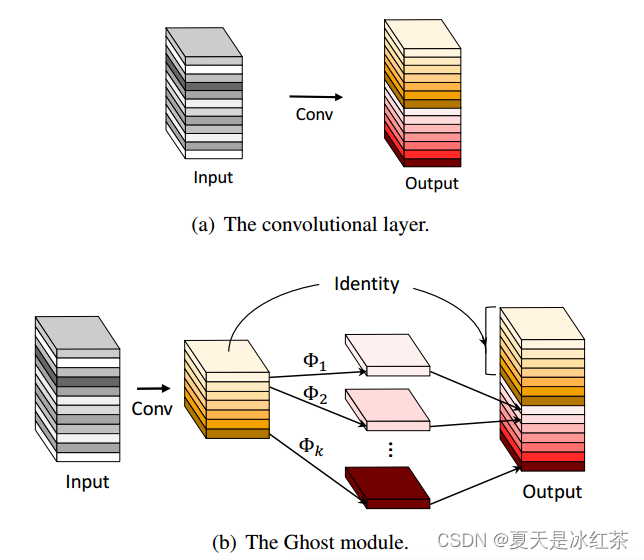
上面所对比的就是输出相同特征映射的卷积层与Ghost模块的对比,这里的表示的就是"很小的代价"。
Ghost模块的原理就是先进行Conv操作生成一些特征图,然后经过cheat生成一系列的冗余特征图,最后将Conv生成的特征图与cheap操作生成的特征图进行concat操作。
现有方法采用点向卷积跨通道处理特征,再采用深度卷积处理空间信息。相比之下,Ghost模块采用普通卷积先生成一些固有的特征映射,然后利用便宜的线性运算来增加特征和增加通道。而在以前的高效架构中,处理每个特征映射的操作仅限于深度卷积或移位操作,而Ghost模块中的线性操作具有较大的多样性。
3、GhostNet
Ghost bottleneck
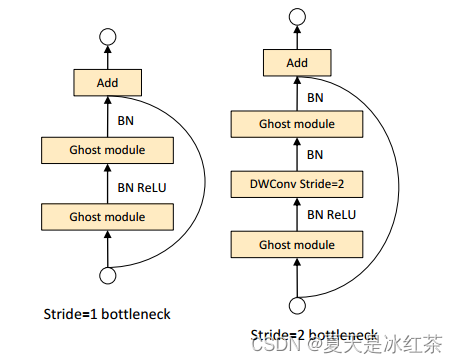
上图是步幅分别为1和2的Ghost bottleneck,这个结构看起来很眼熟,很像是resnet里面的残差模块。
- 左侧的G-bneck主要由两个堆叠的ghost模块组成,它的作用是作为扩展层增加通道的数量。
- 右侧的G-bneck减少了通道的数量以匹配快捷路径。批归一化和ReLU非线性在每一层之后应用,但MobileNetV2建议在第二个Ghost模块之后不使用ReLU。
网络结构
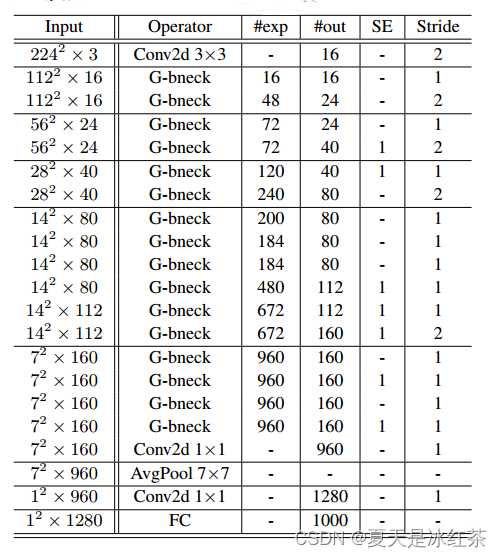
G-bneck表示Ghost bottleneck。#exp表示扩展大小。#out表示输出通道的数量。SE表示是否使用SE模块。
这里的G-bneck适用于stride=1。对于stride=2的情况,快捷路径由下采样层实现,并在两个Ghost模块之间插入stride=2的深度卷积。在实践中,Ghost模块的主要卷积是点卷积,因为它的效率很高。
4、pytorch实现
"""
Creates a GhostNet Model as defined in:
GhostNet: More Features from Cheap Operations By Kai Han, Yunhe Wang, Qi Tian, Jianyuan Guo, Chunjing Xu, Chang Xu.
<https://arxiv.org/abs/1911.11907>
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
__all__ = ["ghostnet"]
def _make_divisible(v, divisor, min_value=None):
"""
此函数取自TensorFlow代码库.它确保所有层都有一个可被8整除的通道编号
在这里可以看到:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
通过四舍五入和增加修正,确保通道编号是可被 divisor 整除的最接近的值,并且保证结果不小于指定的最小值。
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# 确保四舍五入的下降幅度不超过10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
def hard_sigmoid(x, inplace: bool = False):
"""
实现硬切线函数(hard sigmoid)的函数。
Args:
x: 输入张量,可以是任意形状的张量。
inplace: 是否原地操作(in-place operation)。默认为 False。
Returns:
处理后的张量,形状与输入张量相同。
注意:
ReLU6 函数是一个将小于 0 的值设为 0,大于 6 的值设为 6 的函数。
clamp_ 方法用于限制张量的取值范围。
"""
if inplace:
return x.add_(3.).clamp_(0., 6.).div_(6.)
else:
return F.relu6(x + 3.) / 6.
class SqueezeExcite(nn.Module):
def __init__(self, in_chs, se_ratio=0.25, reduced_base_chs=None,
act_layer=nn.ReLU, gate_fn=hard_sigmoid, divisor=4, **_):
super(SqueezeExcite, self).__init__()
self.gate_fn = gate_fn
reduced_chs = _make_divisible((reduced_base_chs or in_chs) * se_ratio, divisor)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_reduce = nn.Conv2d(in_chs, reduced_chs, 1, bias=True)
self.act1 = act_layer(inplace=True)
self.conv_expand = nn.Conv2d(reduced_chs, in_chs, 1, bias=True)
def forward(self, x):
x_se = self.avg_pool(x)
x_se = self.conv_reduce(x_se)
x_se = self.act1(x_se)
x_se = self.conv_expand(x_se)
x = x * self.gate_fn(x_se)
return x
class ConvBnAct(nn.Module):
def __init__(self, in_chs, out_chs, kernel_size,
stride=1, padding=0 ,act_layer=nn.ReLU):
super(ConvBnAct, self).__init__()
self.conv = nn.Conv2d(in_chs, out_chs, kernel_size, stride, padding, bias=False)
self.bn1 = nn.BatchNorm2d(out_chs)
self.act1 = act_layer(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn1(x)
x = self.act1(x)
return x
class GhostModule(nn.Module):
def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):
super(GhostModule, self).__init__()
self.oup = oup
init_channels = math.ceil(oup / ratio) # m = n / s
new_channels = init_channels*(ratio-1) # m * (s - 1) = n / s * (s - 1)
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1,x2], dim=1)
return out[:,:self.oup,:,:]
class GhostBottleneck(nn.Module):
""" Ghost bottleneck w/ optional SE"""
def __init__(self, in_chs, mid_chs, out_chs, dw_kernel_size=3,
stride=1, act_layer=nn.ReLU, se_ratio=0.):
super(GhostBottleneck, self).__init__()
has_se = se_ratio is not None and se_ratio > 0.
self.stride = stride
# Point-wise expansion
self.ghost1 = GhostModule(in_chs, mid_chs, relu=True)
# Depth-wise convolution
if self.stride > 1:
self.conv_dw = nn.Conv2d(mid_chs, mid_chs, dw_kernel_size, stride=stride,
padding=(dw_kernel_size-1)//2,
groups=mid_chs, bias=False)
self.bn_dw = nn.BatchNorm2d(mid_chs)
# Squeeze-and-excitation
if has_se:
self.se = SqueezeExcite(mid_chs, se_ratio=se_ratio)
else:
self.se = None
# Point-wise linear projection
self.ghost2 = GhostModule(mid_chs, out_chs, relu=False)
# shortcut
if (in_chs == out_chs and self.stride == 1):
self.shortcut = nn.Sequential()
else:
self.shortcut = nn.Sequential(
nn.Conv2d(in_chs, in_chs, dw_kernel_size, stride=stride,
padding=(dw_kernel_size-1)//2, groups=in_chs, bias=False),
nn.BatchNorm2d(in_chs),
nn.Conv2d(in_chs, out_chs, 1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_chs),
)
def forward(self, x):
residual = x
# 1st ghost bottleneck
x = self.ghost1(x)
# Depth-wise convolution
if self.stride > 1:
x = self.conv_dw(x)
x = self.bn_dw(x)
# Squeeze-and-excitation
if self.se is not None:
x = self.se(x)
# 2nd ghost bottleneck
x = self.ghost2(x)
x += self.shortcut(residual)
return x
class GhostNet(nn.Module):
def __init__(self, cfgs, num_classes=1000, width=1.0, dropout=0.2):
super(GhostNet, self).__init__()
# setting of inverted residual blocks
self.cfgs = cfgs
self.dropout = dropout
# building first layer
output_channel = _make_divisible(16 * width, 4)
self.conv_stem = nn.Conv2d(3, output_channel, 3, 2, 1, bias=False)
self.bn1 = nn.BatchNorm2d(output_channel)
self.act1 = nn.ReLU(inplace=True)
input_channel = output_channel
# building inverted residual blocks
stages = []
block = GhostBottleneck
for cfg in self.cfgs:
layers = []
for k, exp_size, c, se_ratio, s in cfg:
output_channel = _make_divisible(c * width, 4)
hidden_channel = _make_divisible(exp_size * width, 4)
layers.append(block(input_channel, hidden_channel, output_channel, k, s,
se_ratio=se_ratio))
input_channel = output_channel
stages.append(nn.Sequential(*layers))
output_channel = _make_divisible(exp_size * width, 4)
stages.append(nn.Sequential(ConvBnAct(input_channel, output_channel, 1)))
input_channel = output_channel
self.blocks = nn.Sequential(*stages)
# building last several layers
output_channel = 1280
self.global_pool = nn.AdaptiveAvgPool2d((1, 1))
self.conv_head = nn.Conv2d(input_channel, output_channel, 1, 1, 0, bias=True)
self.act2 = nn.ReLU(inplace=True)
self.classifier = nn.Linear(output_channel, num_classes)
def forward(self, x):
x = self.conv_stem(x)
x = self.bn1(x)
x = self.act1(x)
x = self.blocks(x)
x = self.global_pool(x)
x = self.conv_head(x)
x = self.act2(x)
x = x.view(x.size(0), -1)
if self.dropout > 0.:
x = F.dropout(x, p=self.dropout, training=self.training)
x = self.classifier(x)
return x
def ghostnet(**kwargs):
"""
Constructs a GhostNet model
"""
cfgs = [
# k, t, c, SE, s
# stage1
[[3, 16, 16, 0, 1]],
# stage2
[[3, 48, 24, 0, 2]],
[[3, 72, 24, 0, 1]],
# stage3
[[5, 72, 40, 0.25, 2]],
[[5, 120, 40, 0.25, 1]],
# stage4
[[3, 240, 80, 0, 2]],
[[3, 200, 80, 0, 1],
[3, 184, 80, 0, 1],
[3, 184, 80, 0, 1],
[3, 480, 112, 0.25, 1],
[3, 672, 112, 0.25, 1]
],
# stage5
[[5, 672, 160, 0.25, 2]],
[[5, 960, 160, 0, 1],
[5, 960, 160, 0.25, 1],
[5, 960, 160, 0, 1],
[5, 960, 160, 0.25, 1]
]
]
return GhostNet(cfgs, **kwargs)
if __name__=='__main__':
model = ghostnet()
model.eval()
print(model)
input = torch.randn(32,3,320,256)
y = model(input)
print(y.size())
参考文章
CVPR 2020:华为GhostNet,超越谷歌MobileNet,已开源 - 知乎 (zhihu.com)
GhostNet网络详解_ghostnet网络结构-CSDN博客
GHostNet网络最通俗易懂的解读【不接受反驳】_ghost卷积_☞源仔的博客-CSDN博客















 2680
2680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











