







文章目录
- 一、实验介绍
- 二、实验环境
- 1. 配置虚拟环境
- 2. 库版本介绍
- 三、实验内容
- 0. 导入必要的库
- 1. 质控与细胞筛选
- 过滤细胞和基因
- 标记线粒体基因
- 计算质量控制指标
- 绘制质量控制指标的小提琴图和散点图
- 代码整合
- 2. 高表达基因筛选
- 细胞和基因进一步过滤
- 总计数归一化
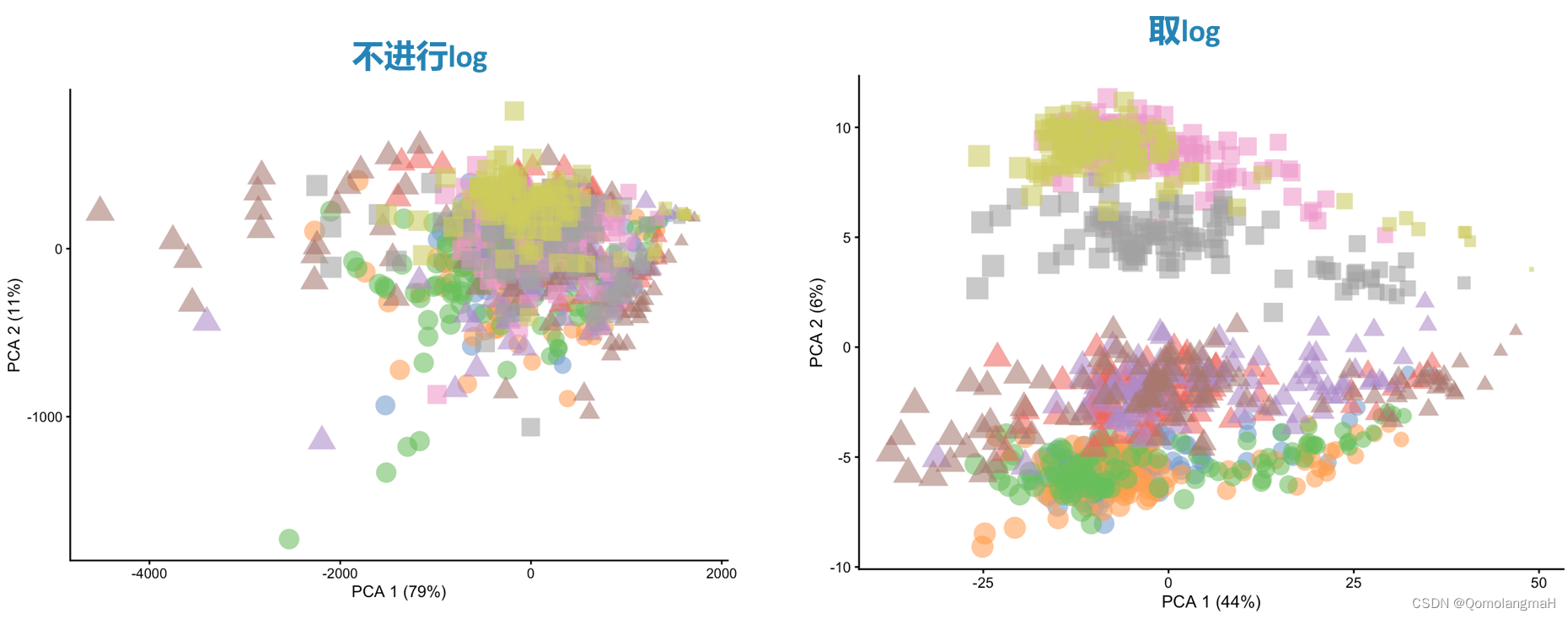
- 对数变换
- 特征选择:识别高度变异的基因
- 绘制高度变异基因的图
- 设置.raw属性
- 实际过滤数据
- 数据回归处理和标准化:
- 代码整合
一、实验介绍
在AI for Science(AI4S)时代,我们可以利用机器学习技术来分析单细胞转录组数据,揭示细胞状态、功能和动态变化,通常可分为三个阶段:
- 数据预处理
- 原始数据处理及质量控制;
- 基础分析
- 适用于几乎所有scRNA-seq数据的基本数据分析: 数据标准化和整合、高表达基因筛选(特征选择)、降维、细胞聚类、细胞类型标注等;
- 高级分析
- 针对特定研究场景定制的高级数据分析: GO/KEGG富集分析、基因集变异分析、转录因子识别、轨迹推断、细胞间通讯分析、空间转录组学等。
二、实验环境
1. 配置虚拟环境
可使用如下指令:
conda create -n bio python==3.9
conda activate bio
pip install -r requirements.txt
其中,requirements.txt:
numpy==1.21.5
pandas==1.4.4
scanpy==1.9.6
2. 库版本介绍
| 软件包 | 本实验版本 |
|---|---|
| numpy | 1.21.5 |
| pandas | 1.4.4 |
| python | 3.8.16 |
| scanpy | 1.9.6 |
| scipy | 1.10.1 |
| seaborn | 0.12.2 |
三、实验内容
0. 导入必要的库
import numpy as np
import pandas as pd
import scanpy as sc
- Scanpy是一个用于单细胞RNA测序数据分析的Python库,提供了许多功能和工具来处理和分析单细胞数据
1. 质控与细胞筛选
-
设置Scanpy参数:
sc.settings.verbosity = 3 sc.logging.print_header() sc.settings.set_figure_params(dpi=80, facecolor='white')sc.settings.verbosity: 设置日志的详细程度。sc.logging.print_header(): 打印日志信息的标题。sc.settings.set_figure_params(dpi=80, facecolor='white'): 设置图形参数以进行绘图。
-
定义结果文件路径:
results_file = 'write/pbmc3k.h5ad'- 定义以H5AD格式存储结果的文件路径。
-
读取单细胞数据:
adata = sc.read_10x_mtx( 'data/filtered_gene_bc_matrices/hg19/', # 数据目录 var_names='gene_symbols', # 使用基因符号作为变量名 cache=True) # 将数据写入缓存以便更快读取- 从10x Genomics格式读取单细胞RNA-seq数据。
- 从指定目录读取数据,将基因符号用作变量名。
- 将数据缓存以便将来更快地访问。

-
确保基因名唯一:
adata.var_names_make_unique()- 确保数据集中的基因名是唯一的。
-
绘制高度表达的基因:
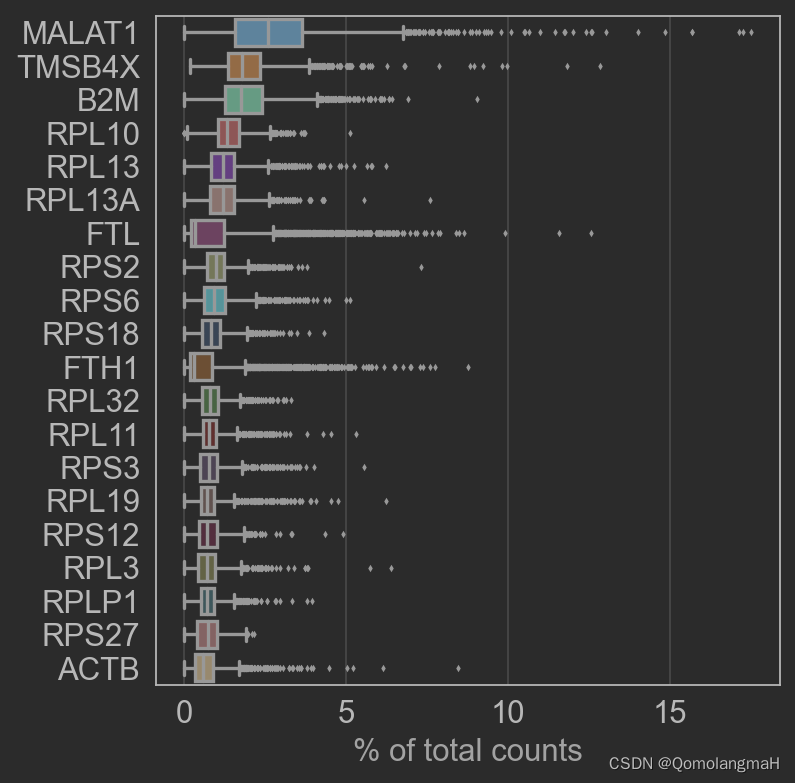
sc.pl.highest_expr_genes(adata, n_top=20)- 绘制数据集中最高表达的前20个基因。

- 绘制数据集中最高表达的前20个基因。
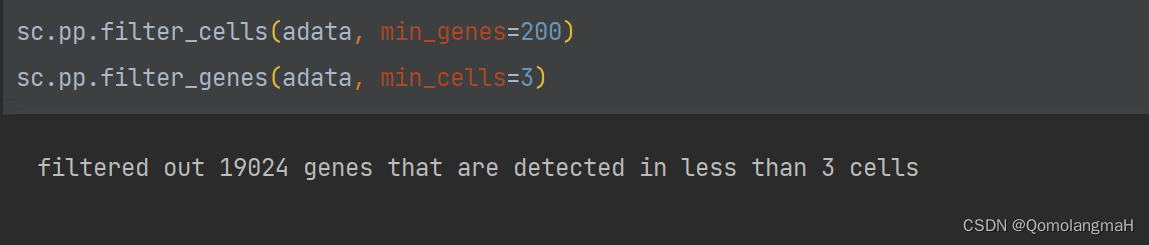
过滤细胞和基因
sc.pp.filter_cells(adata, min_genes=200)
sc.pp.filter_genes(adata, min_cells=3)
- 过滤掉表达基因数低于200的细胞;
- 过滤掉在至少3个细胞中表达的基因。
标记线粒体基因
adata.var['mt'] = adata.var_names.str.startswith('MT-')
- 通过创建一个名为
'mt'的变量,标记所有线粒体基因。
计算质量控制指标
sc.pp.calculate_qc_metrics(adata, qc_vars=['mt'], percent_top=None, log1p=False, inplace=True)
- 计算质量控制指标,包括线粒体基因的百分比以及细胞的总基因数和总计数。
绘制质量控制指标的小提琴图和散点图
sc.pl.violin(adata, ['n_genes_by_counts', 'total_counts', 'pct_counts_mt'], jitter=0.4, multi_panel=True)
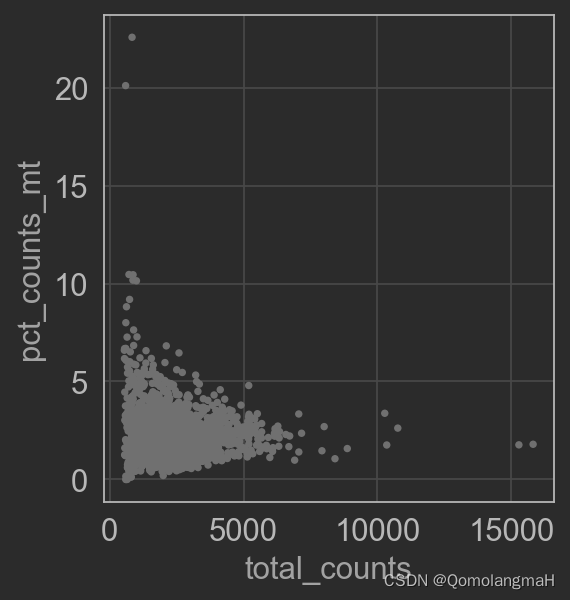
sc.pl.scatter(adata, x='total_counts', y='pct_counts_mt')
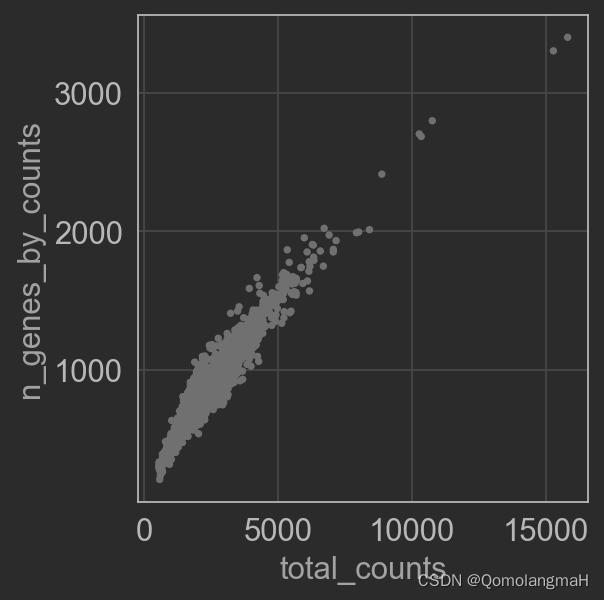
sc.pl.scatter(adata, x='total_counts', y='n_genes_by_counts')
- 使用小提琴图绘制细胞的总基因数 (
n_genes_by_counts)、总计数 (total_counts) 和线粒体基因的百分比 (pct_counts_mt)。 - 使用散点图绘制总计数与线粒体基因的百分比之间的关系,以及总计数与细胞的总基因数之间的关系。

代码整合
# 设置Scanpy参数
sc.settings.verbosity = 3
sc.logging.print_header()
sc.settings.set_figure_params(dpi=80, facecolor='white')
# 定义结果文件路径
results_file = 'write/pbmc3k.h5ad'
# 读取单细胞数据
adata = sc.read_10x_mtx(
'data/filtered_gene_bc_matrices/hg19/', # 数据目录
var_names='gene_symbols', # 使用基因符号作为变量名
cache=True) # 写入缓存文件以便后续更快读取
# 确保基因名唯一
adata.var_names_make_unique()
# 绘制展示高度表达的基因
sc.pl.highest_expr_genes(adata, n_top=20)
# 过滤细胞和基因
sc.pp.filter_cells(adata, min_genes=200)
sc.pp.filter_genes(adata, min_cells=3)
# 标记线粒体基因
adata.var['mt'] = adata.var_names.str.startswith('MT-')
# 计算质量控制指标
sc.pp.calculate_qc_metrics(adata, qc_vars=['mt'], percent_top=None, log1p=False, inplace=True)
# 绘制质量控制指标的小提琴图和散点图
sc.pl.violin(adata, ['n_genes_by_counts', 'total_counts', 'pct_counts_mt'], jitter=0.4, multi_panel=True)
sc.pl.scatter(adata, x='total_counts', y='pct_counts_mt')
sc.pl.scatter(adata, x='total_counts', y='n_genes_by_counts')
2. 高表达基因筛选
细胞和基因进一步过滤
adata = adata[adata.obs.n_genes_by_counts < 2500, :]
adata = adata[adata.obs.pct_counts_mt < 5, :]
- 进一步过滤掉表达基因数超过2500的细胞和线粒体基因的百分比超过5%的细胞。
总计数归一化
sc.pp.normalize_total(adata, target_sum=1e4)
- 对细胞进行总计数归一化,使它们的总计数总和为1e4。
对数变换
sc.pp.log1p(adata)
- 对数据进行对数变换,这通常用于使数据更加符合正态分布。
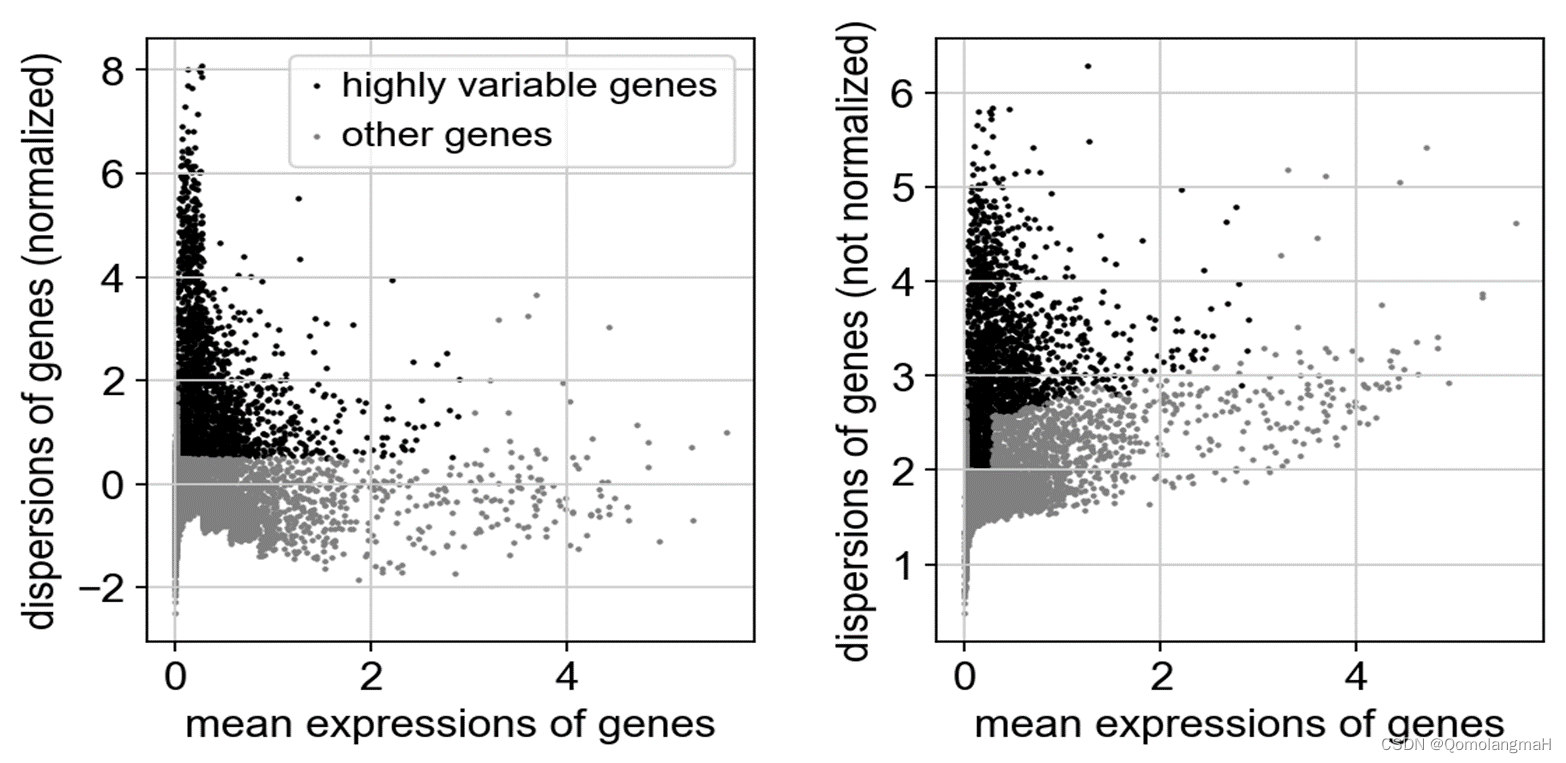
特征选择:识别高度变异的基因
sc.pp.highly_variable_genes(adata, min_mean=0.0125, max_mean=3, min_disp=0.5)
- 识别高度变异的基因,以进行后续的分析。
绘制高度变异基因的图
sc.pl.highly_variable_genes(adata)
- 绘制高度变异基因的图,可视化这些基因的特性。
设置.raw属性
adata.raw = adata
- 将原始数据保存在
.raw属性中,以备后续使用。
实际过滤数据
adata = adata[:, adata.var.highly_variable]
- 根据高度变异的基因过滤数据,仅保留这些基因的表达数据。
数据回归处理和标准化:
sc.pp.regress_out(adata, ['total_counts', 'pct_counts_mt'])
sc.pp.scale(adata, max_value=10)
- 使用线性回归回归掉总计数和线粒体基因的百分比的影响。
- 进行数据标准化,确保每个特征的均值为0,标准差为1,并限制值的范围在0到10之间。
代码整合
# 进一步的过滤和归一化
adata = adata[adata.obs.n_genes_by_counts < 2500, :]
adata = adata[adata.obs.pct_counts_mt < 5, :]
# 总计数归一化
sc.pp.normalize_total(adata, target_sum=1e4)
# 对数变换
sc.pp.log1p(adata)
# 特征选择:识别高度变异的基因
sc.pp.highly_variable_genes(adata, min_mean=0.0125, max_mean=3, min_disp=0.5)
# 绘制高度变异基因的图
sc.pl.highly_variable_genes(adata)
# 设置.raw属性
adata.raw = adata
# 实际过滤数据
adata = adata[:, adata.var.highly_variable]
# 数据回归处理和标准化
sc.pp.regress_out(adata, ['total_counts', 'pct_counts_mt'])
sc.pp.scale(adata, max_value=10)


















 2371
2371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











