









博主介绍:
✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W+粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台的优质作者。通过长期分享和实战指导,我致力于帮助更多学生完成毕业项目和技术提升。技术范围:
我熟悉的技术领域涵盖SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等方面的设计与开发。如果你有任何技术难题,我都乐意与你分享解决方案。为什么选择阅读我:
我是程序阿龙,专注于软件开发,拥有丰富的编程能力和实战经验。在过去的几年里,我辅导了上千名学生,帮助他们顺利完成毕业项目,同时我的技术分享也吸引了超过50W+的粉丝。我是CSDN特邀作者、博客专家、新星计划导师,并在Java领域内获得了多项荣誉,如博客之星。我的作品也被掘金、华为云、阿里云、InfoQ等多个平台推荐,成为各大平台的优质作者。
🍅获取源码请在文末联系我🍅

目录:
为什么选择我(我可以给你的定制项目推荐核心功能,一对一推荐)实现定制!!!
博主提供的项目均为博主自己收集和开发的!所有的源码都经由博主检验过,能过正常启动并且功能都没有问题!同学们拿到后就能使用!且博主自身就是高级开发,可以将所有的代码都清晰讲解出来。
文章下方名片联系我即可~大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻精彩专栏推荐订阅:在下方专栏👇🏻
一、详细操作演示视频
在文章的尾声,您会发现一张电子名片👤,欢迎通过名片上的联系方式与我取得联系,以获取更多关于项目演示的详尽视频内容。视频将帮助您全面理解项目的关键点和操作流程。期待与您的进一步交流!

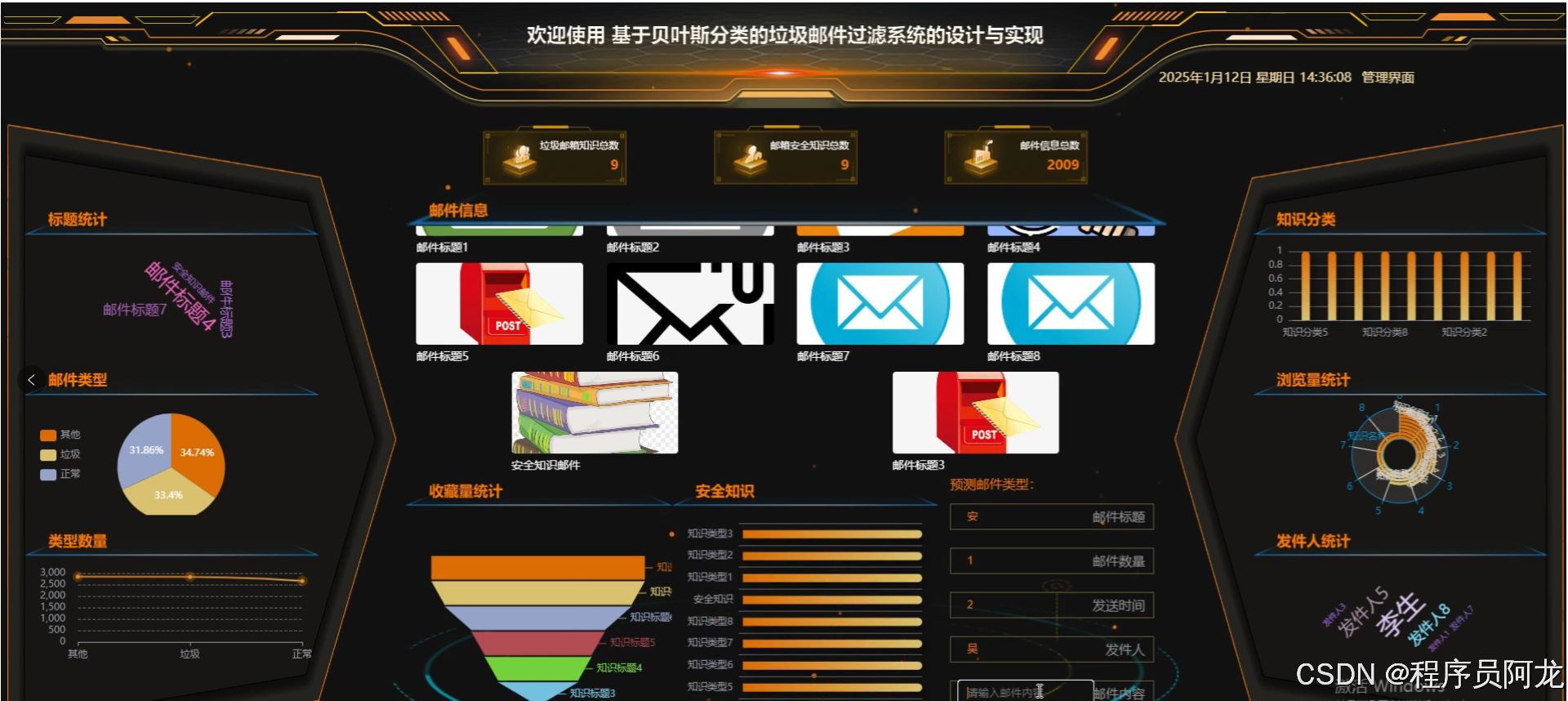
系统实现界面:


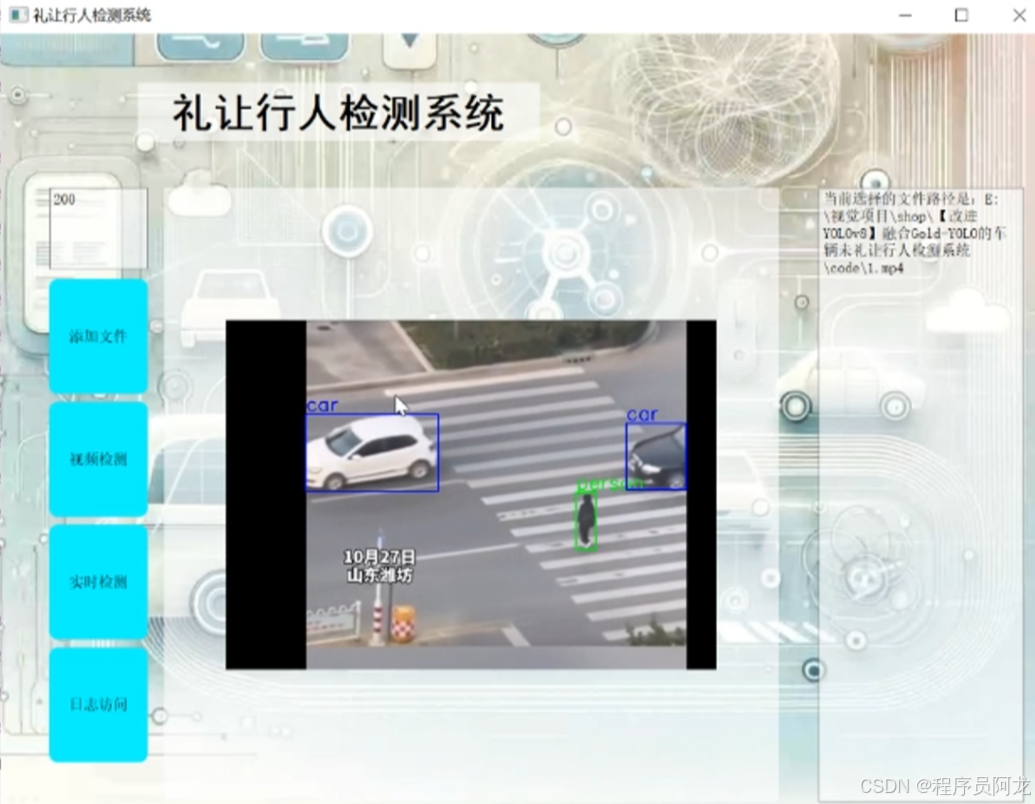
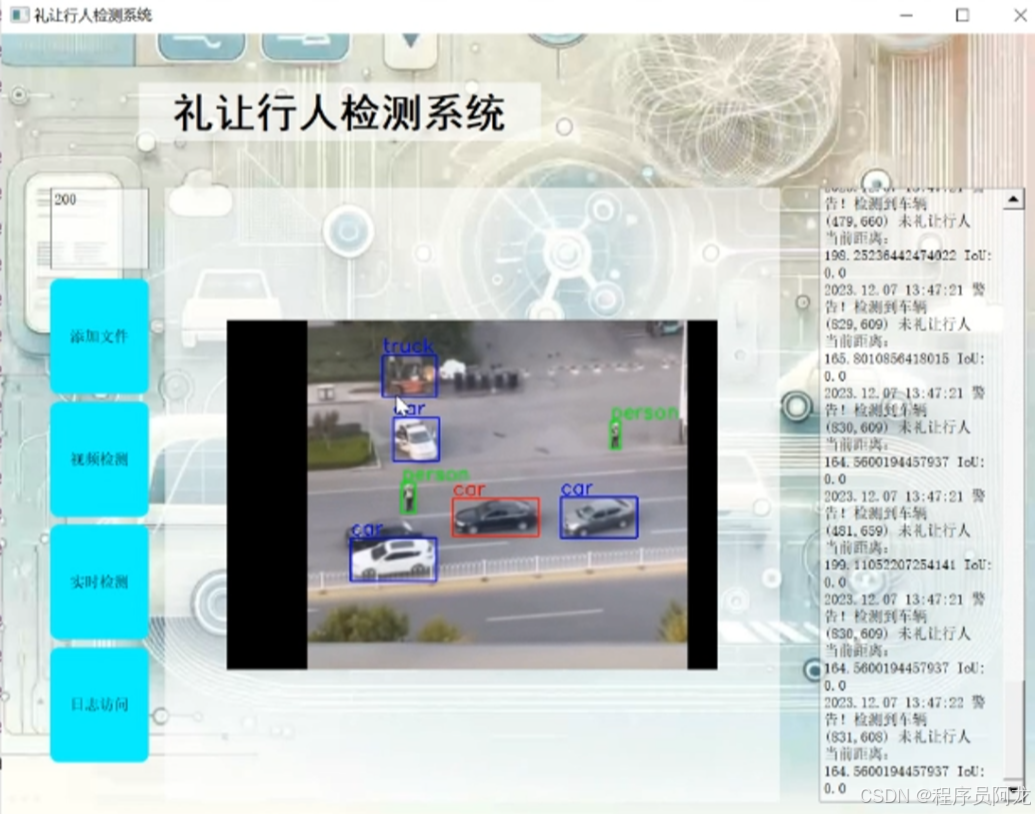
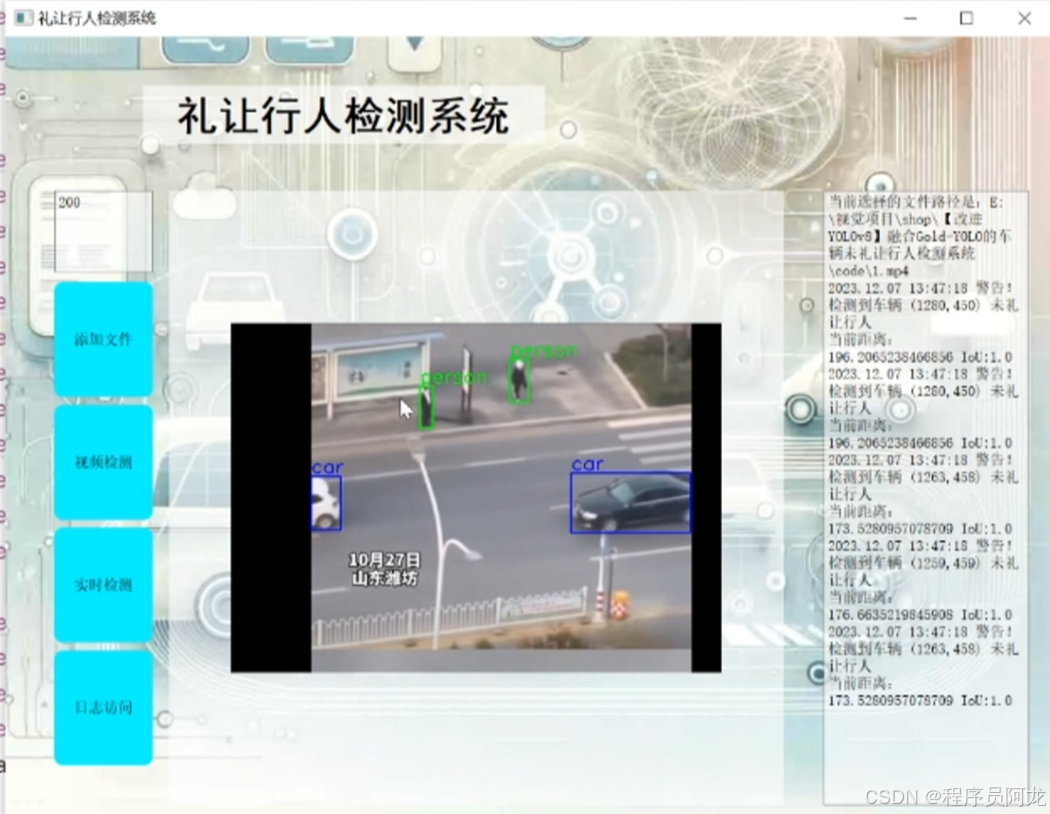
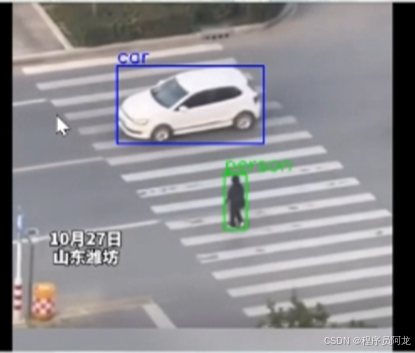

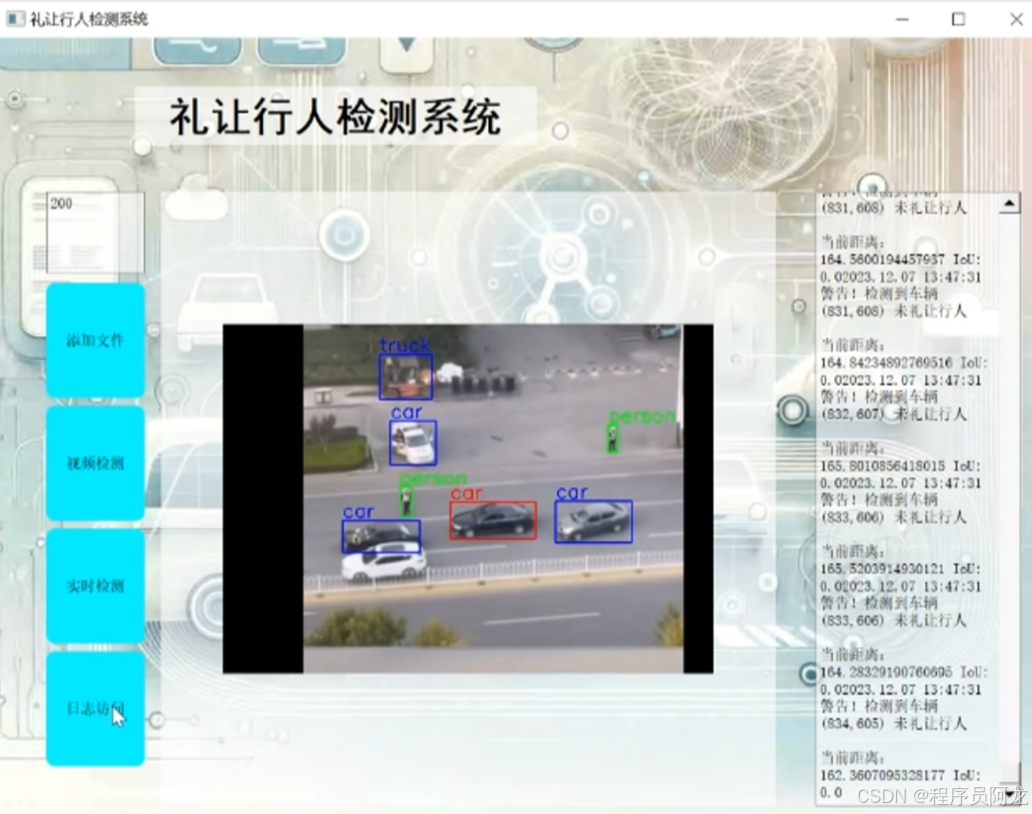

研究背景与意义:
随着交通工具的普及和道路交通量的不断增加,交通安全问题日益严峻,尤其是车辆未礼让行人这一问题,频繁发生的交通事故已对行人的生命安全构成了极大威胁。车辆未礼让行人不仅是导致交通事故的主要原因之一,还加剧了交通拥堵和道路通行效率的下降。因此,开发一种高效、准确的车辆未礼让行人检测系统,能够实时监测交通环境中的车辆与行人的互动,及时发现和预警未礼让行为,具有重要的现实意义。这一系统的实施不仅有助于提高交通安全,减少事故发生,也能够优化交通流量,提升道路通行效率,为智能交通系统的建设提供技术支持,推动智能交通的快速发展。随着深度学习技术在目标检测领域的突破,YOLO(You Only Look Once)算法作为一种快速、准确的目标检测工具,已广泛应用于多种交通监控场景。然而,传统YOLO算法在处理小目标、复杂场景以及目标遮挡等情况下存在一定的局限性,因此,本研究通过改进YOLOv8算法并融合Gold-YOLO的思想,旨在提升车辆未礼让行人检测系统的准确性与鲁棒性,从而有效提高交通安全和道路通行效率。
YOLOv8 概述:
YOLOv8(You Only Look Once version 8)是YOLO系列目标检测算法的最新版本,继承了YOLO系列的高效性和实时性,同时在精度和鲁棒性方面进行了显著优化。YOLOv8采用了先进的深度学习技术和高效的神经网络架构,结合了卷积神经网络(CNN)和 Transformer 技术,以进一步提升模型在处理复杂场景时的表现。与前几代YOLO模型相比,YOLOv8在小目标检测、遮挡目标识别和多尺度目标的处理能力上有了大幅提升,同时通过引入更精细的网络层和优化策略,能够在保证高帧率的同时提高检测的准确性。此外,YOLOv8还采用了新的目标检测策略和改进的损失函数,使得其在边界框回归和分类精度上均表现出色,尤其在交通监控和智能安防等领域展现出了强大的应用潜力。因此,YOLOv8不仅在学术研究中具有重要价值,也为实际应用中的目标检测任务提供了高效的解决方案。
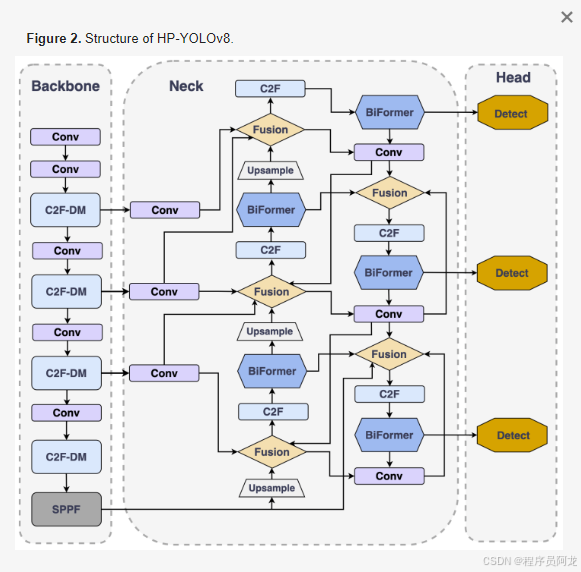
ultralytics 包加载YOLOv8模型,进行图像推理,并输出检测结果。假设你已经安装了 ultralytics,如果没有安装,可以通过以下命令进行安装:
核心检测代码如下:
import cv2
import torch
from ultralytics import YOLO
import matplotlib.pyplot as plt
# 1. 加载YOLOv8模型(使用预训练模型或你自己训练的模型)
model = YOLO("yolov8n.pt") # 这里可以替换成自己的训练好的模型路径
# 2. 加载并读取输入图片
image_path = "data/images/sample_image.jpg" # 替换为你的图像路径
img = cv2.imread(image_path) # 使用 OpenCV 读取图像
# 3. 进行推理
results = model(img) # 执行推理
# 4. 获取预测结果(边界框、标签、置信度等)
# results.pred 维度为 [N, 6]:N 为预测的框数,6分别为 [x1, y1, x2, y2, conf, class]
boxes = results.pred[0][:, :4].cpu().numpy() # 获取边界框坐标
labels = results.pred[0][:, 5].cpu().numpy() # 获取预测类别标签
confidences = results.pred[0][:, 4].cpu().numpy() # 获取置信度
# 5. 可视化检测结果
for i, box in enumerate(boxes):
x1, y1, x2, y2 = box
label = int(labels[i]) # 类别标签
confidence = confidences[i] # 置信度
# 绘制边界框
color = (0, 255, 0) # 边界框颜色为绿色
thickness = 2
img = cv2.rectangle(img, (int(x1), int(y1)), (int(x2), int(y2)), color, thickness)
# 添加类别标签和置信度
text = f"{model.names[label]} {confidence:.2f}" # 类别名称 + 置信度
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img, text, (int(x1), int(y1)-10), font, 0.5, color, 2)
# 6. 使用OpenCV显示检测结果
cv2.imshow("YOLOv8 Detection Result", img)
cv2.waitKey(0) # 等待键盘输入
cv2.destroyAllWindows() # 关闭所有OpenCV窗口
# 7. 保存检测结果图像
output_path = "output_image.jpg" # 结果保存路径
cv2.imwrite(output_path, img)
# 如果你想显示图片并保存为Matplotlib图表,可以使用以下代码
plt.figure(figsize=(10, 10))
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) # 将BGR转为RGB
plt.axis('off') # 不显示坐标轴
plt.show()
-
加载YOLOv8模型:
model = YOLO("yolov8n.pt")加载了YOLOv8的预训练模型(yolov8n.pt是YOLOv8中的一个小型模型,如果你有自己的训练模型,可以将路径替换为你自己的模型文件)。
-
读取图像:
cv2.imread(image_path)使用OpenCV读取图像文件。
-
执行推理:
results = model(img)将图像传递给YOLOv8模型进行推理,results是YOLOv8返回的一个结果对象。
-
获取检测结果:
results.pred[0][:, :4]提取边界框坐标(x1, y1, x2, y2)。results.pred[0][:, 5]提取每个框的类别标签(label)。results.pred[0][:, 4]提取每个框的置信度(confidence)。
-
后处理与可视化:
- 使用OpenCV绘制边界框和标签(包括类别名称和置信度)。
cv2.rectangle()用于绘制矩形框。cv2.putText()用于添加类别名称和置信度文本。
-
显示与保存检测结果:
cv2.imshow()使用OpenCV展示图像,cv2.waitKey(0)等待用户按键关闭窗口。cv2.imwrite()保存处理后的图像。
-
Matplotlib显示图像:
- 使用
matplotlib显示图像,并将OpenCV的BGR图像转换为RGB格式。 -
安装与环境要求
ultralytics是YOLOv8的核心库,需要通过pip install ultralytics安装。- 如果使用OpenCV显示和保存图像,需要安装
opencv-python:
- 使用
-
pip install opencv-python
为什么选择我(我可以给你的定制项目推荐核心功能,一对一推荐)实现定制!!!
博主提供的项目均为博主自己收集和开发的!所有的源码都经由博主检验过,能过正常启动并且功能都没有问题!同学们拿到后就能使用!且博主自身就是高级开发,可以将所有的代码都清晰讲解出来。


















 181
181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











