






摘要:我们推出了SigLIP 2,这是一系列基于原始SigLIP成功经验的新型多语言视觉-语言编码器。在第二代中,我们将原先的图像-文本训练目标与多个先前独立开发的技术相结合,形成了一个统一的训练方案——这包括基于标题生成的预训练、自监督损失(自蒸馏、掩码预测)以及在线数据筛选。通过这些改进,SigLIP 2模型在核心能力上全面超越了其前代SigLIP,包括零样本分类、图像-文本检索以及为视觉-语言模型(VLM)提取视觉表示时的迁移性能。此外,新的训练方案在定位和密集预测任务上带来了显著提升。我们还训练了支持多种分辨率并保持输入原始宽高比的变体。最后,我们在更加多样化的数据混合上进行了训练,其中包括去偏技术,从而实现了更好的多语言理解和改进的公平性。为了让用户能够在推理成本和性能之间做出权衡,我们发布了四种尺寸的模型检查点:ViT-B(86M)、L(303M)、So400m(400M)和g(1B)Huggingface链接:Paper page,论文链接:2502.14786
1. 引言
随着人工智能技术的不断发展,多语言视觉-语言编码器(Vision-Language Encoders)在跨模态信息处理领域扮演着越来越重要的角色。这类模型能够理解和处理图像与文本之间的复杂关系,为图像描述生成、视觉问答、图像检索等任务提供了强大的支持。然而,现有的多语言视觉-语言编码器在语义理解、定位和密集特征提取等方面仍存在不足。为了克服这些挑战,本文介绍了SigLIP 2,一种基于原始SigLIP模型改进的新型多语言视觉-语言编码器。
2. SigLIP 2模型介绍
2.1 模型架构与训练数据
SigLIP 2模型延续了SigLIP的架构,采用了视觉Transformer(ViT)作为图像编码器,并结合了多语言文本编码器。这种架构使得SigLIP 2能够同时处理图像和文本信息,并捕捉它们之间的复杂关系。在训练数据方面,SigLIP 2使用了WebLI数据集,该数据集包含了100亿张图像和120亿条替代文本,覆盖了109种语言。这种大规模、多语言的数据集为SigLIP 2提供了丰富的训练素材,有助于提升其多语言理解能力。
2.2 训练方案
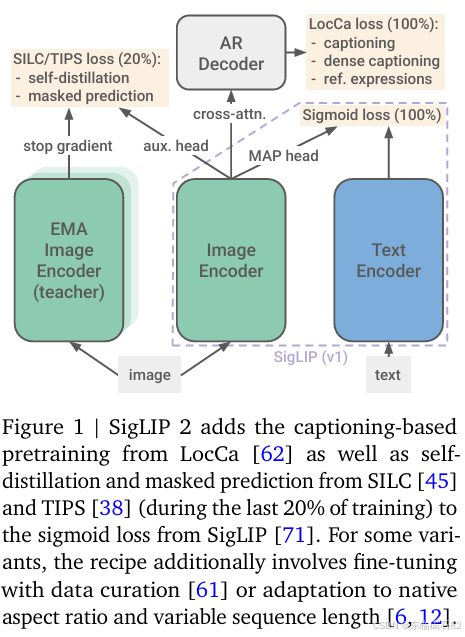
SigLIP 2的训练方案是其核心竞争力的关键所在。该方案将原先的图像-文本训练目标与多个先前独立开发的技术相结合,形成了一个统一的训练框架。具体来说,SigLIP 2的训练方案包括以下几个方面:
- 基于标题生成的预训练:通过附加一个标准的Transformer解码器到未池化的视觉编码器表示上,SigLIP 2能够进行图像标题生成、自动引用表达式预测和基于区域的标题生成等任务。这些任务不仅有助于提升模型的文本生成能力,还能增强其对图像内容的理解能力。
- 自监督损失:SigLIP 2引入了自蒸馏和掩码预测等自监督损失函数。这些损失函数通过让模型从自身或其他模型的学习中获取监督信号,从而进一步提升模型的表示学习能力。特别是在密集预测任务(如语义分割、深度估计等)中,自监督损失函数能够显著提升模型的性能。
- 在线数据筛选:为了提升训练数据的质量,SigLIP 2采用了在线数据筛选技术。该技术能够在训练过程中动态地选择高质量的数据样本,从而加速模型的收敛速度并提高模型的性能。
3. SigLIP 2的改进与优势
3.1 语义理解的改进
SigLIP 2在语义理解方面的改进主要体现在以下几个方面:
- 多语言支持:通过在大规模多语言数据集上进行训练,SigLIP 2能够理解和处理多种语言的图像和文本信息。这使得SigLIP 2在全球化背景下具有广泛的应用前景。
- 标题生成辅助训练:基于标题生成的预训练任务使得SigLIP 2能够更好地理解图像内容,并生成与图像内容高度相关的文本描述。这种能力在图像描述生成、视觉问答等任务中尤为重要。
- 自监督学习的引入:自监督损失函数的引入使得SigLIP 2能够在没有标签数据的情况下进行学习,从而进一步提升其语义理解能力。特别是在低资源语言或领域特定任务中,自监督学习能够显著缓解数据稀缺的问题。
3.2 定位能力的提升
除了语义理解外,SigLIP 2在定位能力方面也取得了显著提升。这主要得益于其训练方案中的自动引用表达式预测任务。通过该任务,SigLIP 2能够学习如何将图像中的特定区域与相应的文本描述关联起来。这种能力在图像标注、目标检测等任务中尤为重要。
3.3 密集特征提取的增强
SigLIP 2在密集特征提取方面的增强主要体现在以下几个方面:
- 自监督损失的引入:自蒸馏和掩码预测等自监督损失函数使得SigLIP 2能够学习到更丰富、更精细的图像特征表示。这些特征表示不仅包含了图像的全局信息,还涵盖了图像的局部细节和纹理信息。
- 多任务学习:通过同时进行图像标题生成、自动引用表达式预测和基于区域的标题生成等任务,SigLIP 2能够学习到不同任务之间的共享表示。这种共享表示有助于提升模型在密集预测任务中的性能。
4. SigLIP 2的实验与结果
4.1 实验设置
为了验证SigLIP 2的性能,我们在多个基准数据集上进行了广泛的实验。这些数据集涵盖了零样本分类、图像-文本检索、视觉语言模型(VLM)的迁移性能、语义分割、深度估计等多个任务。在实验过程中,我们采用了不同的模型尺寸和分辨率设置,以全面评估SigLIP 2的性能。
4.2 实验结果
实验结果表明,SigLIP 2模型在核心能力上全面超越了其前代SigLIP模型以及其他开源基线模型。具体来说:
- 零样本分类:在ImageNet、ObjectNet、ImageNet-v2和ImageNet ReaL等基准数据集上,SigLIP 2模型取得了显著的零样本分类性能提升。
- 图像-文本检索:在COCO、TextCaps、HierText和SciCap等基准数据集上,SigLIP 2模型在图像到文本和文本到图像的检索任务上均取得了优异的性能。
- 视觉语言模型的迁移性能:在将SigLIP 2作为视觉编码器与大型语言模型(LLM)结合构建视觉语言模型(VLM)时,我们发现SigLIP 2模型在多个下游任务上均表现出色。
- 密集预测任务:在语义分割、深度估计和表面法线估计等密集预测任务上,SigLIP 2模型也取得了显著的性能提升。特别是在语义分割任务上,SigLIP 2模型在多个基准数据集上均取得了领先的结果。
此外,我们还对SigLIP 2模型的多语言理解能力和公平性进行了评估。实验结果表明,通过在大规模多语言数据集上进行训练并采用去偏技术,SigLIP 2模型在多语言理解方面表现出色,并且在不同文化背景下的公平性也得到了显著提升。
5. SigLIP 2的变体与应用
5.1 支持多种分辨率和原始宽高比的变体
为了满足不同应用场景的需求,我们还训练了支持多种分辨率并保持输入原始宽高比的SigLIP 2变体(称为NaFlex)。这种变体能够在处理不同类型和尺寸的图像时自动调整其分辨率和宽高比,从而提供更灵活、更高效的图像处理能力。
5.2 潜在应用场景
SigLIP 2模型具有广泛的应用前景。在电子商务领域,SigLIP 2可以用于商品图像的自动描述生成和搜索推荐;在医疗影像领域,SigLIP 2可以用于医学图像的自动标注和辅助诊断;在自动驾驶领域,SigLIP 2可以用于交通标志的识别和理解等。此外,SigLIP 2还可以与其他人工智能技术相结合,形成更加智能、更加高效的解决方案。
6. 结论与展望
本文介绍了SigLIP 2——一种基于原始SigLIP模型改进的新型多语言视觉-语言编码器。通过引入基于标题生成的预训练、自监督损失和在线数据筛选等技术,SigLIP 2在语义理解、定位和密集特征提取等方面取得了显著提升。实验结果表明,SigLIP 2模型在多个基准数据集上均表现出色,并且在多语言理解和公平性方面也取得了显著进步。未来,我们将继续优化SigLIP 2模型的性能和效率,并探索其在更多应用场景中的潜力。同时,我们也将关注相关领域的前沿技术动态,为SigLIP 2的持续改进和创新提供有力支持。
7. 相关工作
在本文的研究过程中,我们参考了大量相关工作。这些工作涵盖了对比学习、自监督学习、多模态学习等多个领域。特别是CLIP和ALIGN等对比学习模型的成功应用为我们提供了宝贵的经验和启示。此外,我们还借鉴了其他研究者在多语言视觉-语言编码器方面的研究成果和技术路线。这些相关工作为我们提供了丰富的技术储备和理论支持,也为SigLIP 2模型的改进和创新提供了有力保障。
8. 致谢
在本文的研究过程中,我们得到了许多人的帮助和支持。我们感谢所有参与SigLIP 2模型开发和测试的研究人员和技术人员;感谢提供数据和计算资源的机构和合作伙伴;感谢审稿人和编辑对本文的宝贵意见和建议。正是有了大家的共同努力和支持,我们才能够顺利完成本文的研究工作并取得了一系列重要成果。
9. 未来工作
尽管SigLIP 2模型在多个方面取得了显著进步,但仍存在一些不足和挑战。未来,我们将继续优化SigLIP 2模型的性能和效率,特别是在处理大规模数据和高分辨率图像时的性能和效率。同时,我们还将探索SigLIP 2模型在更多应用场景中的潜力,并与其他人工智能技术相结合形成更加智能、更加高效的解决方案。此外,我们还将关注相关领域的前沿技术动态和市场需求变化,为SigLIP 2的持续改进和创新提供有力支持。

















 482
482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









