







 该专栏为热销专栏榜 第19名
该专栏为热销专栏榜 第19名目录
效果展示
-
通过控制文本标签,驱动模型对特定物体进行语义分割:
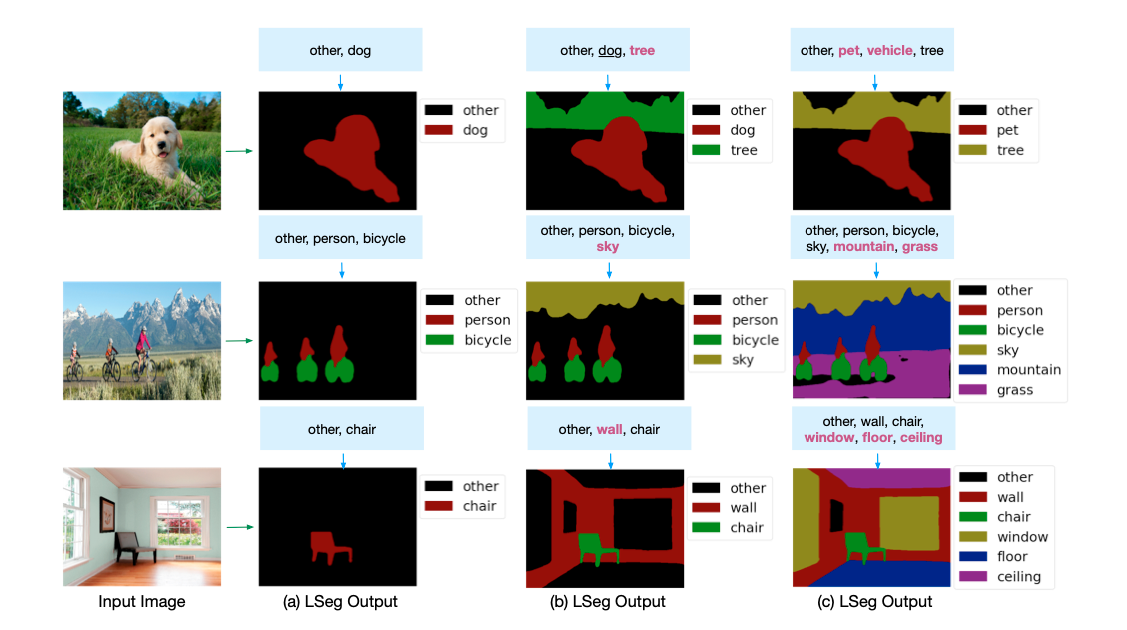
引言
在计算机视觉领域,图像语义分割是一项至关重要的任务,其目标是理解图像中的对象及其相互关系。近年来,一种新的趋势是将文本信息融合到图像语义分割中,这被称为文本驱动的图像语义分割。本文将深入探讨这种新方法的原理、实现及未来前景。
1. 什么是文本驱动的图像语义分割?
文本驱动的图像语义分割是一种将文本描述与视觉信息相结合,以改善语义分割性能的方法。在这种方法中,模型不仅仅需要理解视觉信息,而且还需要理解文本信息,并将这两种信息整合起来进行决策。

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 523
523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











