









最新研究显示,多智能体强化学习(MARL)正迎来一系列技术革新,让AI系统真正具备“群体智能”。同济大学团队提出的动态图通信网络(TGCNet),通过Transformer建模智能体间的动态协作关系,在复杂任务中实现了比传统方法更高的协同效率;ICLR 2025最新收录的扩散分解框架(DoF),首次将扩散模型引入多智能体决策,让AI在星际争霸等复杂博弈中展现出接近人类的策略配合能力。
这些突破不仅让AI更聪明,也让它们更懂“合作”,未来将在交通调度、智能制造等领域大放异彩。我整理了10篇【多智能体强化学习】的相关论文,全部论文PDF版,工中号 沃的顶会 回复“多智能强化”即可领取
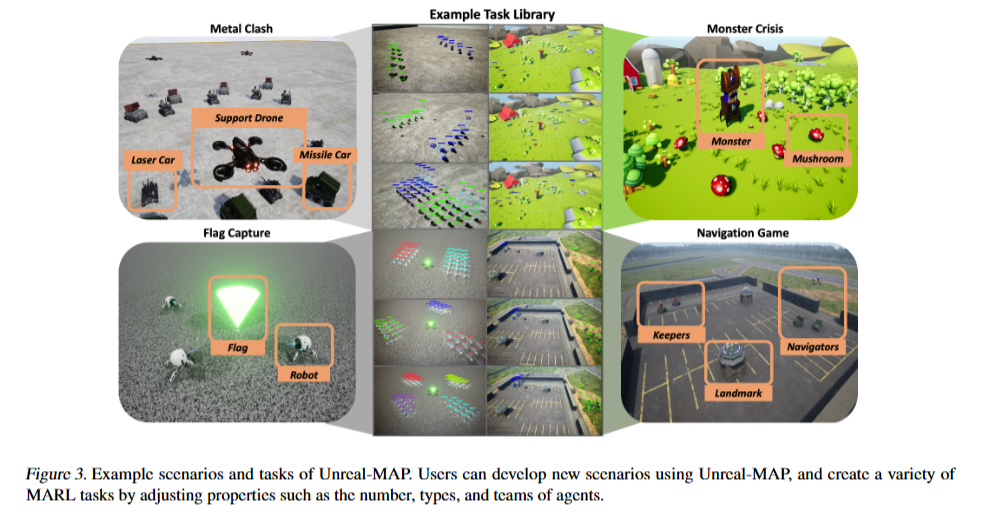
Unreal-MAP:Unreal-Engine-Based General Platform for Multi-Agent Reinforcement Learning
文章解析
本文提出了一种基于虚幻引擎(Unreal Engine)的多智能体强化学习通用平台Unreal-MAP,允许用户利用虚幻社区丰富的视觉和物理资源自由创建多智能体任务,并部署最先进的MARL算法。
该平台具有易用性、可修改性和可视化特性,同时支持从规则到学习型算法的第三方框架集成。
创新点
提出了一个基于虚幻引擎的多智能体强化学习通用平台Unreal-MAP。
提供了优化的底层引擎以支持大规模多智能体模拟和数据传输。
支持并行多进程执行以及单进程时间流控制,加速训练或慢动作分析。
开发了配套的模块化实验框架HMAP,集成了多种算法以方便环境定制和算法部署。
研究方法
设计了一个分层架构,使用户能够专注于高层操作层进行任务元素修改。
通过优化底层引擎提升大规模多智能体仿真效率。
构建了一个实验框架HMAP,包含规则基算法、内置学习基算法及第三方框架算法。
在多个示例任务中部署SOTA算法并进行实验分析。
研究结论
Unreal-MAP为多智能体强化学习领域提供了一个全面的工具,促进算法与用户自定义任务的紧密集成。
该平台有助于推动多智能体强化学习算法的实际应用。
通过实验验证,展示了平台在多智能体任务中的有效性和灵活性。
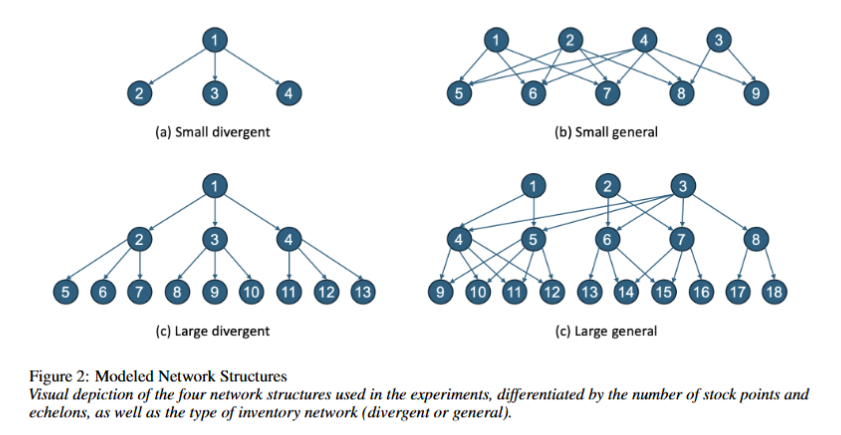
Iterative Multi-Agent Reinforcement Learning:A Novel Approach Toward Real-World Multi-Echelon Inventory Optimization
文章解析
本文研究了深度强化学习(DRL)在多级库存优化(MEIO)中的适用性,提出了一种新型的迭代多智能体强化学习(IMARL)方法。
IMARL在解决复杂供应链问题时表现出更好的可扩展性、有效性和可靠性,超越传统启发式方法。
创新点
提出了一种基于多智能体强化学习的新型方法——IMARL。
结合图神经网络(GNNs)和多智能体强化学习技术以应对维度灾难问题。
通过13个不同供应链场景验证了IMARL的有效性和优越性。
研究方法
复制并改进了最先进的DRL模型作为基础模型。
开发了三种额外模型,结合GNNs和MARL技术进行实验。
在13个供应链场景中测试模型性能,并与传统启发式方法对比。
研究结论
IMARL在复杂MEIO问题上表现优于传统方法。
DRL在解决实际供应链问题方面具有潜力,但需进一步研究。
IMARL为解决真实世界多级库存优化问题提供了新方向。

















 970
970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









