









动机与出发点
纯视觉、视觉+Lidar的感知系统在复杂城市道路场景下并不能如预期那般表现稳定,其中遮挡就是一个巨大挑战。现在的BEV静态感知方案多采用多趟重建的方式获取,这就导致无论前方是否有车辆、建筑物、绿化带等,只要能投影到BEV空间的车道线都会参与到参数训练过程中,也就会导致模型输出结果对这些不置信区域也产生响应。自然可以通过给感知元素添加遮挡判别属性来帮助下游判别车道线的可信程度,这个方式要做好的话需要在感知环境中区分可行驶区域和非可行驶区域。还有一个方案是使用辅助信息,如SD地图,SD地图(standard definition map)是一种较为廉价和覆盖范围广的辅助信息,并且其也是相对置信的,则可以考虑将它与传感器感知算法结合,得到更加鲁棒的感知方案,因而这里对最近看到的几篇SD地图结合方案进行梳理。
对于SD地图如何在感知中使用,其实就是需要解决如下几个问题:
- 1)SD地图的坐标系如何与ego坐标系对齐
- 2)SD地图的信息如何编码并与传感器数据融合
1. PriorLane: A Prior Knowledge Enhanced Lane Detection Approach Based on Transformer
参考代码:PriorLane
这篇文章中将SD地图建模为二值图像,1代表可行驶区域,0代表不可行驶区域。SD地图通过文章提出的KEA模块实现与ego数据的对齐,再通过与传感器数据cat之后进行融合得到混合表达。
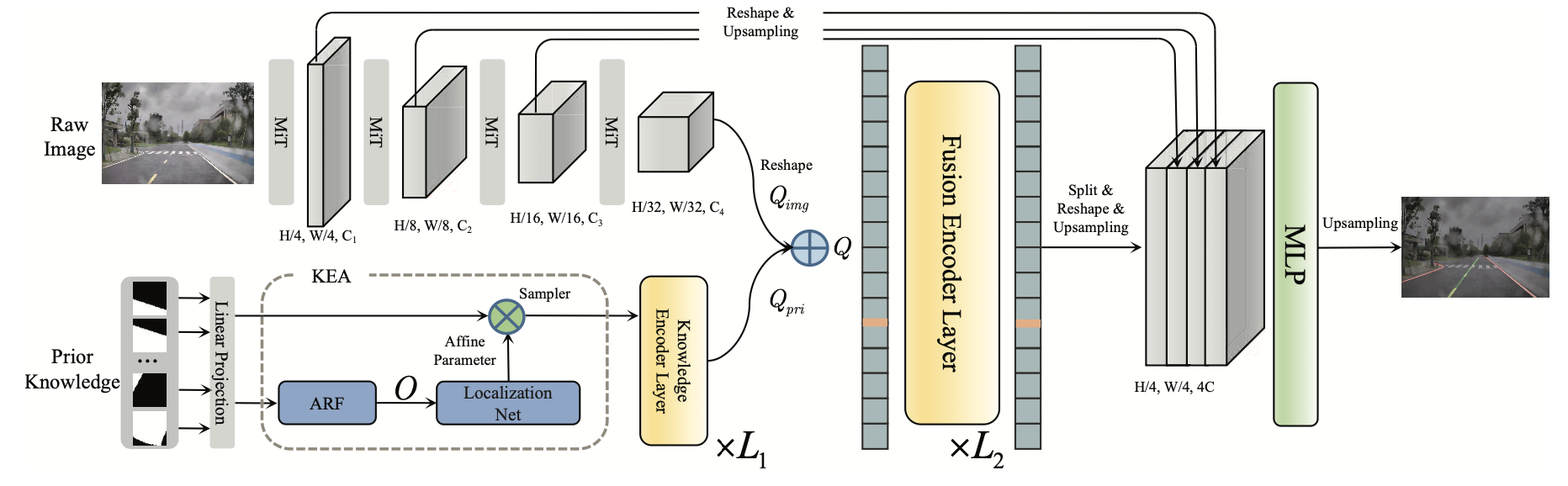
这篇文章fusion部分比较简单,就是cat之后使用多层网络融合。主要的工作是在前面的对齐部分,首先对场景构建二值图,也就是下面所示的一个大场景地图:
这里使用且分patch方式进行特征抽取,其实就是用一个kernel_size=stride_size的大卷积实现。核心在KEA模块的下面,使用一个对方向信息敏感的卷积处理地图数据,再通过一个定位网络输出地图需要的旋转角度和平移量,并完成网格采样以此实现特征对齐。
CULane测试集上的性能表现:

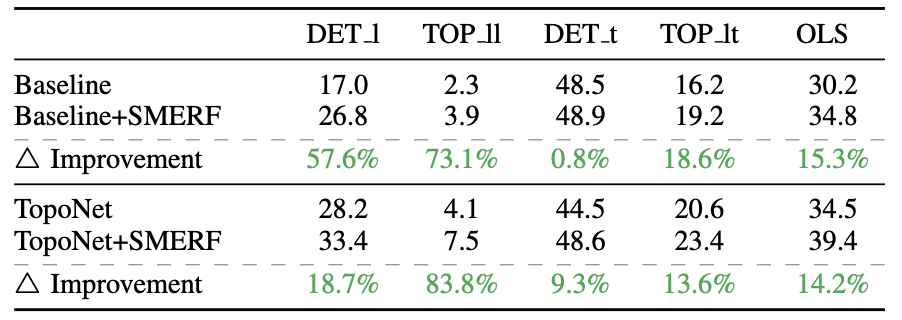
2. SMERF:Augmenting Lane Perception and Topology Understanding with Standard Definition Navigation Maps
参考代码:SMERF
SD地图数据来源:OpenStreetMap
这篇文章原本是挂了代码链接的但是失效了已经,本来NVIDIA的工作一般来讲都不给代码的,dddd(已经重新开放) 。这个工作是在BEV空间去做SD地图和传感器数据的融合的。其大体流程如下图所示:

其主要的过程可以划分为如下两个步骤:
- 1)抽取SD地图中的地面元素,包含线条位置和属性,对于线条数据会通过均匀采样的方式得到 N N N个数据点,若是经过sin-cos编码之后便是得到 N ⋅ d N\cdot d N⋅d维度的线条描述,而属性则会通过one-hot编码得到维度为 K K K的向量。则对于感知范围内的地面元素会得到 M ⋅ ( N ⋅ d + K ) M\cdot(N\cdot d+K) M⋅(N⋅d+K)的编码数据,这些编码数据会经过几层transformer得到地图特征表达。
- 2)对于地图数据与传感器数据对齐和融合部分则是放到后面,通过Map Cross-Attn实现与原本BEV特征的交互实现。
OpenLane-V2数据集下相对base带来的涨点比较:
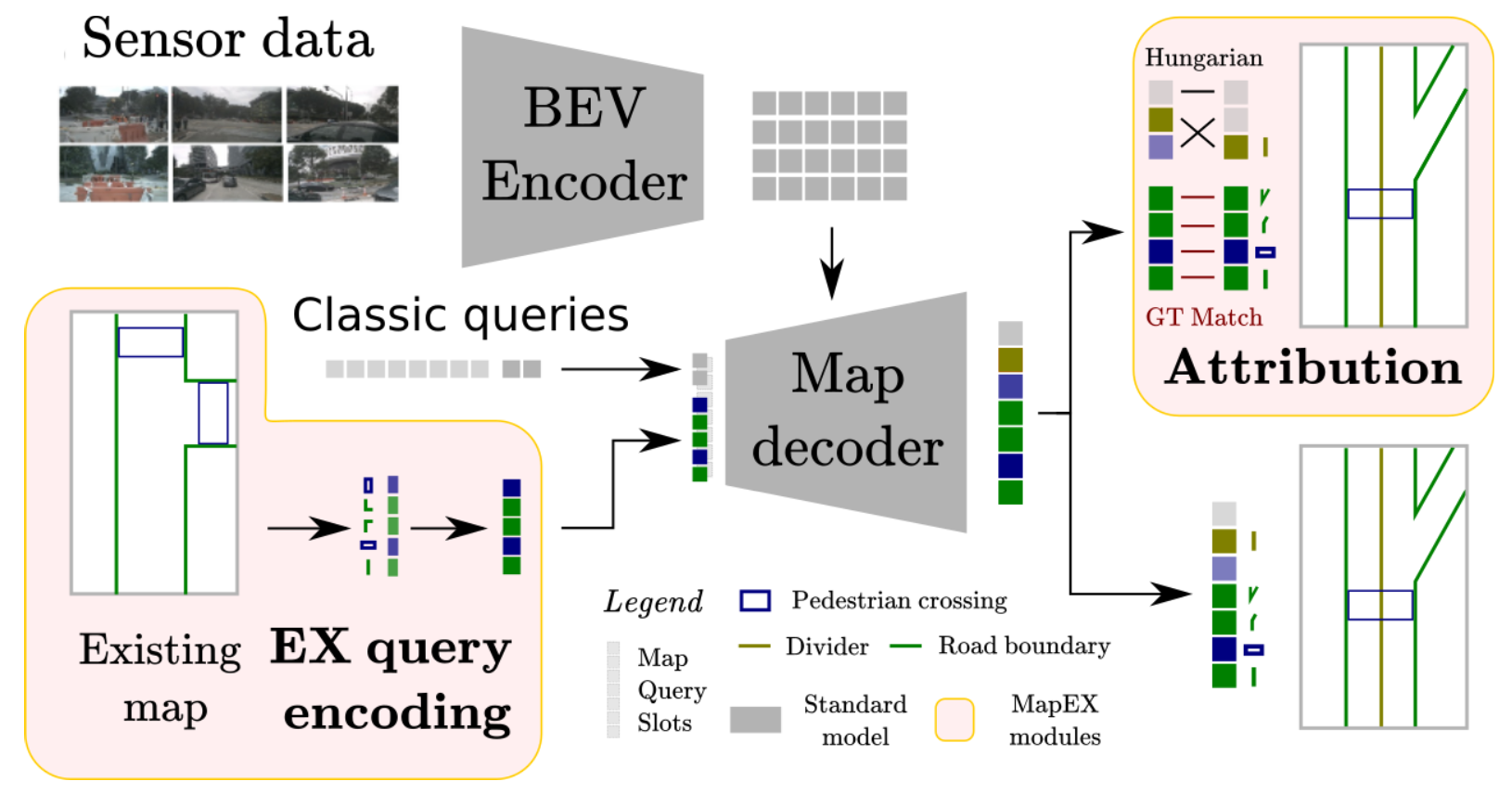
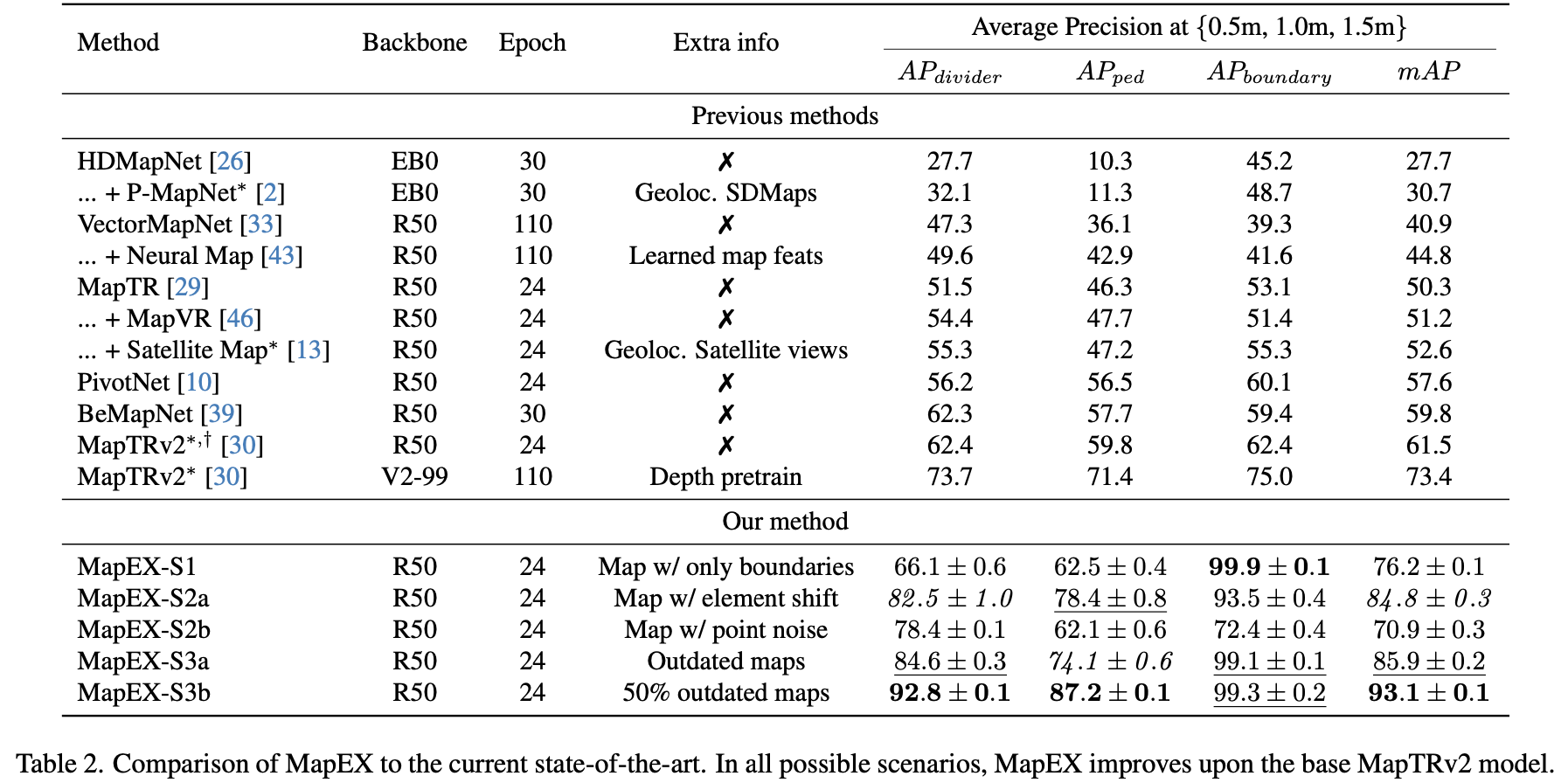
3. MapEX:Mind the map! Accounting for existing map information when estimating online HDMaps from sensor data
这篇文章是在query的维度引入SD地图,SD地图中地面元素的抽取和表达与SMERF近似,都是将点和类别组合起来得到query,由于网络都是固定query的数量,对于数量不足的情况下会在query池子中(下图中的“Classic queries”)选择对应数量的query实现数量统一。而SD地图与传感器数据的对齐和融合都通过transformer来隐式解决了,文章的具体流程结构见下图所示:
这个工作是在nuscenes上做的,再去获取对应SD地图是比较难的,文中使用删除元素、元素添加漂移量、添加噪声等方式去模拟真实SD地图中可能存在情况,效果呢见下图:
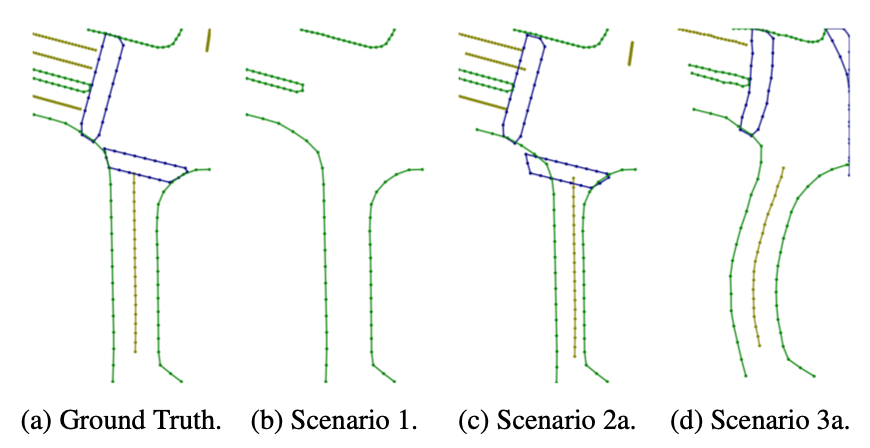
但是真实的SD地图跟文中提到的数据增广结果是存在偏差的,因而这个从标注结果模拟SD地图的方案大家就看一乐就好了。
稍微可以借鉴的是在预测结果与GT的匹配过程的改进,按照之前DETR类算法的思路使用匈牙利匹配去做匹配,但是由于在GT上做了扰动这个先验,那么可以对于那些扰动不是很大的(文中取的阈值是1m)可以之间建立这个query与GT的对应关系,这样可以使得网路收敛速度加快。但是这个思路需要结合SD地图给到的信息来综合考虑收益性,否则就比较鸡肋了。
文章的方法与之前一些在线建图方案进行比较:
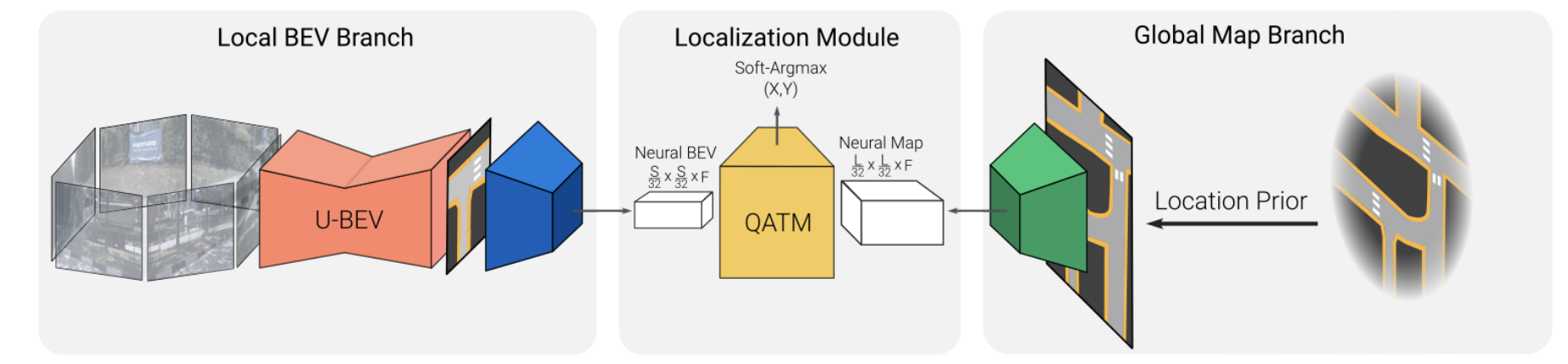
4. U-BEV: Height-aware Bird’s-Eye-View Segmentation and Neural Map-based Relocalization
在前面的内容中有使用concat、cross-attn做SD地图和BEV特征之间做交互融合的,在concat类方法中并没有考虑到定位偏差,很简单粗暴。而cross-attn方法使用attention方式从SD高维信息中去抓取,这样就依赖模型中对道路结构的理解能力,但是这个理解能力是隐式的,并没有显式约束,所以可解释性和鲁棒性不是那么强。在这篇文章中对于定位不准的问题使用模板匹配的思路去寻找最佳匹配的点,配准之后再去做融合。
这里令从图像得到的BEV特征表示为 B ∈ R S ∗ S ∗ N B\in R^{S*S*N} B∈RS∗S∗N(作为source),对应SD地图经过编码之后得到的特征表示为 M l o c ∈ R L ∗ L ∗ N M_{loc}\in R^{L*L*N} Mloc∈RL∗L∗N(作为target),这里地图是包含了自车附近300m的区域,相比感知距离是更大的。
PS:这里模板匹配使用的方法是QATM,该方法原文中使用相同编码器去编码target和source,而这篇文章中并没有并没有对这个gap做细化研究,直接进行模板匹配。并且模板匹配过程中只考虑了XY两个方向的自由度,对于yaw角的偏差没有进一步建模。
下图展示了source和target之间做匹配的流程:
按照QATM的算法流程它会生成一个匹配的概率图
M
p
r
o
b
∈
R
L
∗
L
M_{prob}\in R^{L*L}
Mprob∈RL∗L,再在这个基础上做2D的softmax操作得到
M
^
\hat{M}
M^,之后参考soft-argmax重参数化(深入浅出Sampling-Argmax)思路得到source和target的最佳匹配点
(
x
,
y
)
(x,y)
(x,y),之后在该位置处进行截取与source相同大小的特征就可以送到下游任务中去了。
5. P-MapNet: Far-seeing Map Generator Enhanced by both SDMap and HDMap Priors
在感知系统中引入先验信息是可以提升静态元素感知网络的上限的,这篇文章对SD地图采用栅格化表示(也就是图像形式),之后用CNN网络去抽取栅格化SD地图的信息,将其作为BEV特征优化时额外信息的来源(也就是做key和val)。其实还有一种SD地图表示的方法,那就是向量化描述,目前现有的文献还没有对这两种模态表示更好做过细致分析。感知的终极目的时在线构建高精地图,而感知+地图的结果只能说是在鲁棒性、稳定性上好于纯视觉的方案,对此这篇文章设计了一个refine网络,这个网络通过自监督学习(也即是MAE自编码)的方式学习栅格化的HDMap,这样使得网络参数中隐式编码了HDMap的信息。再用这个自监督得到的网络用视觉+SDMap的结果作为输入去fine-tune得到最后结果。虽然这个隐式编码能够带来一定性能提升,但是没有将静态元素信息很好挖掘。

6. BLOS-BEV: Navigation Map Enhanced Lane Segmentation Network, Beyond Line of Sight
车端相机是很难看清楚远距离目标,当目标在80m之外几乎无法辨认,无论是车辆还是车道线。因而说光靠目前主流相机配置去做自动驾驶视觉感知几乎不可能,就一个大路口车辆开过去的时候完全就跟在“海”中行驶差不多。对此,SD Map这样信息的引入就显得至关重要的了。今年(2024)的CVPR Mapless-challenge公开出来的方案也没啥借鉴价值就是去刷分儿去的。
回过头来讲这篇文章的方案,这篇文章也是用SD map作为额外信息输入去增强BEV特征,从而实现远距离感知及感知鲁棒的。传感器部分BEV特征的生成没有改动,在BEV阶段增加了SD map编码信息的引入操作,也就是下图所示:
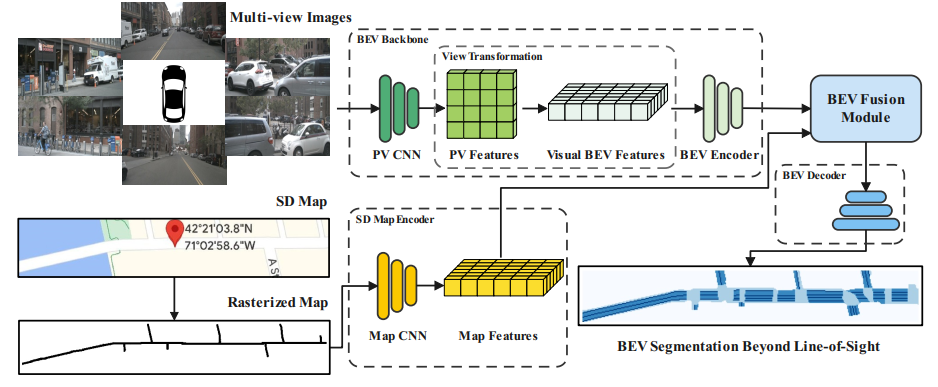
-
- 特征融合策略:它将SD map做栅格化处理之后经过CNN进行编码得到具备SD map先验信息的特征,之后与传感器的BEV特征做融合。这里对融合的多种形式(Sum、Cat、Cross-attn)进行了比较:

需要注意的是这里把SD map特征作为query,这是由于其具有超过视觉感知的先验性(作为骨架),因而在该先验性基础上使用传感器结果进行填充(Key和Val)更为合适。那么这三中不同融合方式对性能在两个数据集下的性能比较(最后定性Cross-attn方案最优):
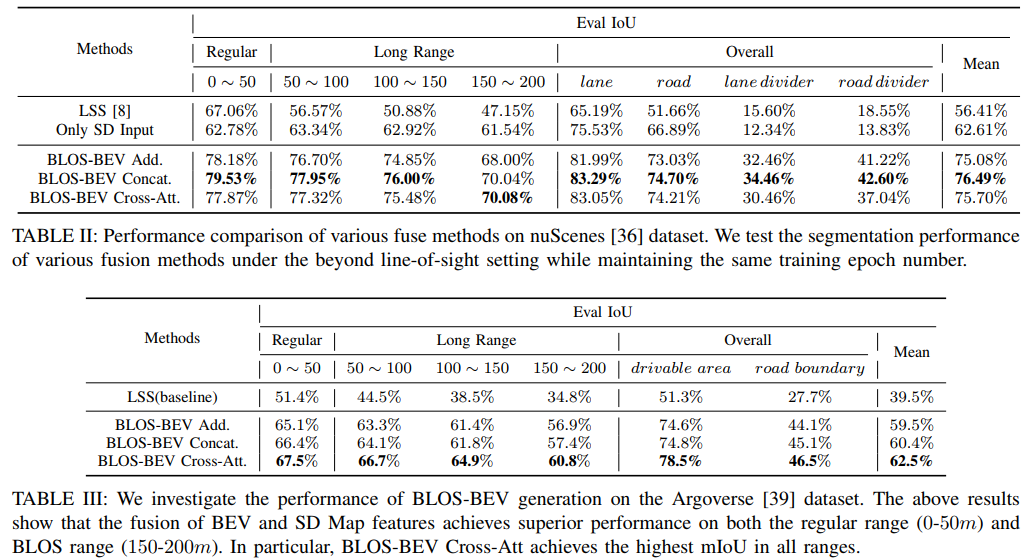
- 特征融合策略:它将SD map做栅格化处理之后经过CNN进行编码得到具备SD map先验信息的特征,之后与传感器的BEV特征做融合。这里对融合的多种形式(Sum、Cat、Cross-attn)进行了比较:
-
- SD map漂移问题:首先经过实验证明了地图漂移确实会对感知的效果存在不小影响,那么在训练的过程中对漂移噪声进行模拟:距离漂移
≤
10
m
\le 10m
≤10m,角度漂移
≤
10
°
\le 10°
≤10°,经过实验这种添加噪声的方式是能够有效提升感知结果的鲁棒性的
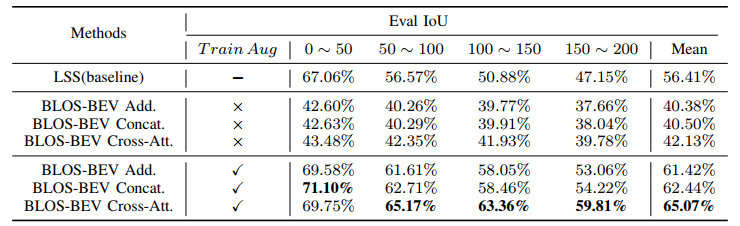
- SD map漂移问题:首先经过实验证明了地图漂移确实会对感知的效果存在不小影响,那么在训练的过程中对漂移噪声进行模拟:距离漂移
≤
10
m
\le 10m
≤10m,角度漂移
≤
10
°
\le 10°
≤10°,经过实验这种添加噪声的方式是能够有效提升感知结果的鲁棒性的
7. Enhancing Online Road Network Perception and Reasoning with Standard Definition Maps
Project Page:sdhdmap
在BEV感知中除了是使用栅格化SD map之外这篇文章将graph model引入了进来作为SD map信息的编码单元。对于栅格化SD map的使用这里是在BEV feature的维度做融合,这里将SD map中不同的类别编码为了图像中的不同class值(encoder采用传统CNN编码器,如resnet-18):
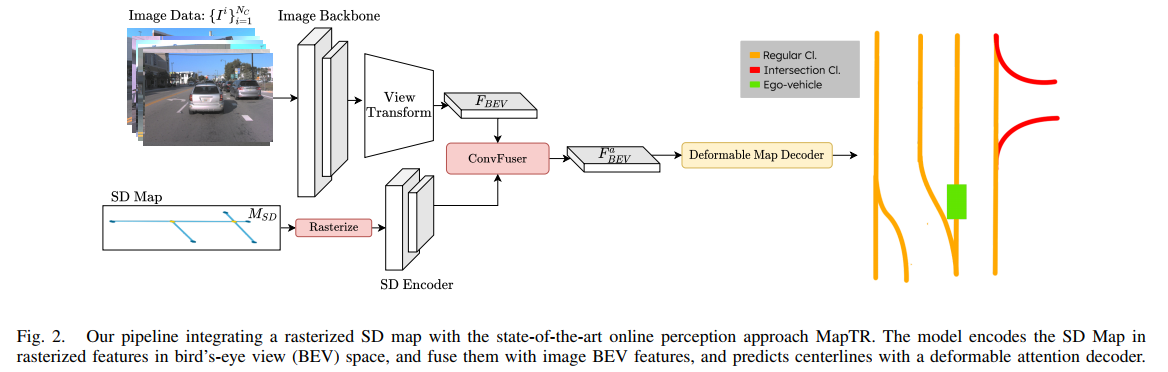
除了栅格化SD map之外还可以通过SD map中的节点与边构建graph,再用graph model在
F
B
E
V
F_{BEV}
FBEV上抽取特征。对于SD map中元素构成的图节点和边描述为
G
S
D
=
(
V
S
D
,
E
S
D
)
G_{SD}=(V_{SD},E_{SD})
GSD=(VSD,ESD),对于图中的节点是可以由其空间位置在Ego坐标系下确定位置的,假定Ego坐标系下节点的特征描述为
X
S
D
i
,
i
=
{
1
,
2
,
…
,
n
}
X_{SD}^i,i=\{1,2,\dots,n\}
XSDi,i={1,2,…,n}且位置坐标描述为
(
x
i
B
,
y
i
B
)
(x_i^B,y_i^B)
(xiB,yiB)。首先融合节点特征:
x
S
D
a
,
i
=
c
o
n
c
a
t
(
x
S
D
i
,
F
B
E
V
(
x
i
B
,
y
i
B
)
)
x_{SD}^{a,i}=concat(x_{SD}^i,F_{BEV}(x_i^B,y_i^B))
xSDa,i=concat(xSDi,FBEV(xiB,yiB))
对于节点构成的图这里使用Edge Convolution graph去抽取特征,那么节点之间的几何关联是通过MLP算子去关联的,经过周围节点优化之后的特征描述为:
X
S
D
a
,
i
=
1
N
(
i
)
∑
j
=
N
(
i
)
M
L
P
θ
(
[
x
S
D
a
,
i
,
x
S
D
a
,
j
−
x
S
D
a
,
i
]
)
X_{SD}^{a,i}=\frac{1}{\mathcal{N}(i)}\sum_{j=\mathcal{N}(i)}MLP_{\theta}([x_{SD}^{a,i},x_{SD}^{a,j}-x_{SD}^{a,i}])
XSDa,i=N(i)1j=N(i)∑MLPθ([xSDa,i,xSDa,j−xSDa,i])
得到的特征会在后续pipeline中作为K和V,如下图所示:
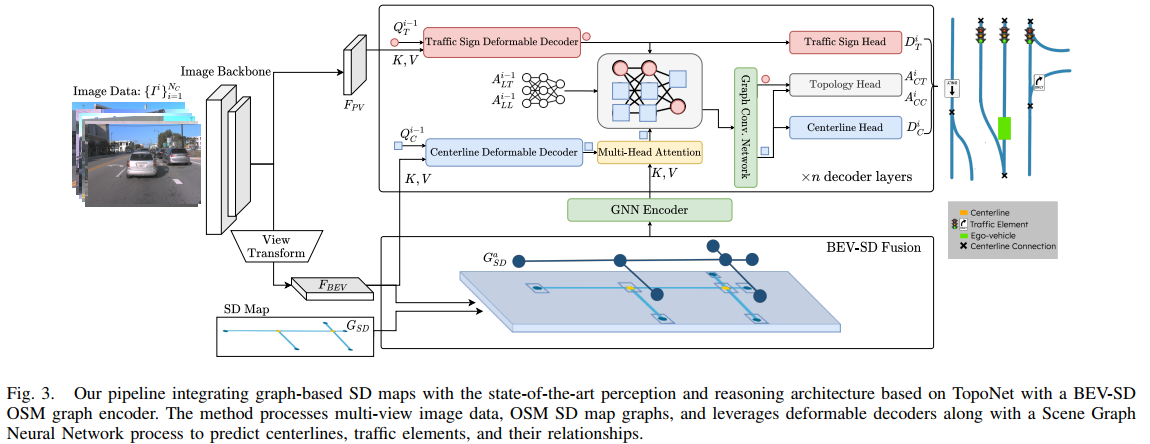
栅格化(MR)和graph(MG)不同描述方式对性能的影响:
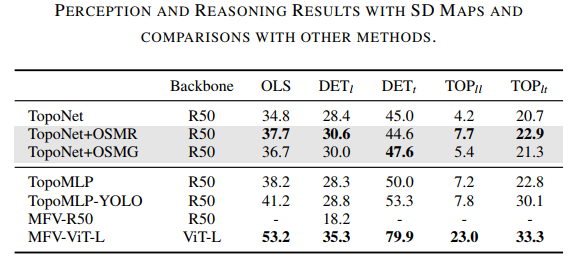
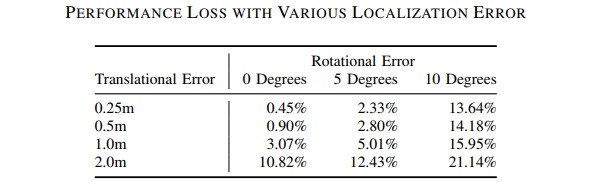
SD map的平移和旋转误差对于性能掉点影响分析:

















 5868
5868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









