









目录
0. 摘要
近期,在资源受限的的移动设备上,轻量ViTs表现出了比CNNs更好的性能和更低的延迟。研究人员发现了轻量级vit和轻量级cnn之间的许多结构联系。然而,尚未充分检查它们之间的块结构、宏观和微观设计的显着架构差异。在这项研究中,我们从 ViT 的角度重新审视轻量级 CNN 的有效设计,并强调它们对移动设备的前景。具体来说,我们通过集成轻量级 ViT 的有效架构设计,逐步增强标准轻量级 CNN(即 MobileNetV3)的移动友好性。这最终得到了一系列新的纯轻量级cnn,即RepViT。大量的实验表明,RepViT优于现有的最先进的轻量级vit,并在各种视觉任务中表现出良好的延迟。值得注意的是,在 ImageNet 上,RepViT 在 iPhone 12 上以 1.0 ms 的延迟实现了超过 80% 的 top-1 准确率,据我们所知,这是轻量级模型第一次。此外,当RepViT满足SAM时,我们的RepViT-SAM比先进的MobileSAM实现了近10倍的推理速度。
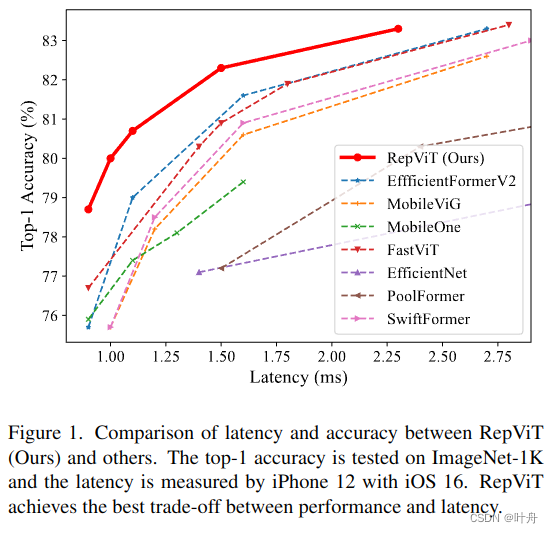
1. 引言
在计算机视觉领域,设计轻量级模型一直是以降低计算成本实现卓越模型性能的主要焦点。这对于资源受限的移动设备来说尤其重要,以便能够在边缘部署视觉模型。在过去的十年中,研究人员主要关注轻量级卷积神经网络 (CNN),并取得了重大进展。已经提出来了许多高效的设计准则,包括可分离卷积[27]、倒置残差瓶颈[53]、通道混洗[44,75]和结构重新参数化[13,14]等。这些设计原则导致了诸如MobileNets[26,27,53]、ShuffleNets[44,75]和RepVGG[14]等代表性模型的发展。
近年来,视觉Transformer(ViTs)[18]已经成为cnn学习视觉表示的一种有前途的替代方案。在各种视觉任务(如图像分类[39,63]、语义分割[6,66]和目标检测[4,34])上,与cnn相比,它们表现出了优越的性能。然而,增加 ViT 中参数数量以提高模型大小和低延迟的性能趋势 [11, 40],这使得它们不适合资源受限的移动设备 [36, 46]。虽然可以直接减小ViT模型的模型大小以匹配移动设备的约束,但它们的性能往往不如轻量级cnn[5]。因此,研究人员开始探索轻量级ViTs的设计,旨在超越轻量级 CNN。
已经提出了许多有效的设计原则来提高VITS在移动设备上的计算效率[5,35,46,49]。一些方法提出了将卷积层与 ViT 相结合的创新架构,从而产生混合网络 [5, 46]。此外,引入了具有线性复杂度[47]和维度一致设计原则[35,36]的新型自我注意操作来提高效率。这些研究表明,轻量级 ViT [35, 47, 49] 可以在移动设备上实现更低的延迟,同时优于轻量级 CNN [26, 53, 60],如图 1 所示。
尽管轻量级vit取得了成功,但由于硬件和计算库支持不足,它们继续面临实际挑战[60]。此外,vit容易受到高分辨率输入的影响,导致延迟很高[3]。相比之下,CNN 利用相对于输入的线性复杂度高度优化的卷积操作,这使得它们有利于边缘设备上的部署 [54, 73]。因此,设计高性能轻量级 CNN 变得至关重要,引人注目的是我们仔细比较现有的轻量级 ViT 和 CNN。
轻量级vit和轻量级cnn表现出一定的结构相似性。例如,它们都使用卷积神经网络模块来学习空间局部表示[46,47,49,61]。为了学习全局表示,轻量级CNN通常会扩大卷积的核大小[73],而轻量级VITS通常采用多头自我注意模块[46,47]。然而,尽管这些结构连接,但它们之间的块结构、宏观/微观设计存在显着差异,尚未得到足够的研究。例如,轻量级 ViT 通常采用 MetaFormer 块结构 [69],而轻量级 CNN 有利于倒置的残差瓶颈 [53]。这自然引出了一个问题:轻量级 ViT 的架构设计能否用于提高轻量级 CNN 的性能。为了回答这个问题,本研究从ViT的角度重新审视了轻量级cnn的设计。我们的研究旨在弥合轻量级 CNN 和轻量级 ViT 之间的差距,并强调了前者在移动设备上部署的前景后者相比更好。
为了实现这个目标,按照[41]的做法,我们从标准的轻量级 CNN 开始,即 MobileNetV3-L [26]。我们通过结合轻量级vit的高效架构设计来逐渐“现代化”其架构[35,36,38,46]。最后,对于资源受限的移动设备,我们获得了一组新的轻量级 CNN,即 RepViT,它完全由类似 ViT 的 MetaFormer 结构中的重新参数化卷积组成 [36, 69, 70]。作为纯轻量级 CNN,RepViT 相比于现有的SOTA轻量级vit[35,49]表现出卓越的性能和效率,涉及到各种计算机视觉任务,包括ImageNet[12]上的图像分类、COCO-2017[37]上的目标检测和实例分割以及ADE20k[78]上的语义分割。值得注意的是,RepViT 在 ImageNet 上达到超过 80% 的 top-1 准确率,iPhone 12 上的延迟为 1.0 ms,据我们所知,这是轻量级模型首次达到这么快。我们最大的模型 RepViT-M2.3,在只有 2.3 毫秒的延迟的情况下获得了 83.7% 的准确率。在将RepViT与SAM[33]结合后,我们的RepViT-SAM可以获得比最先进的MobileSAM[71]快近10倍的推理速度,同时具有更好的零镜头传输能力。我们希望 RepViT 可以作为强大的基线,并激发对边缘部署的轻量级模型的进一步研究。
2. 相关工作
在过去的十年中,卷积神经网络 (CNN) 因其自然的归纳偏置和平移不变性而成为计算机视觉任务的主要方法 [16, 23, 24, 43, 62, 67]。然而,标准 CNN 的广泛计算使它们不适合部署在资源受限的移动设备上。为了克服这一挑战,已经提出了许多技术来使 CNN 更加轻量级和移动友好,包括可分离卷积 [27]、倒置残差瓶颈 [53]、通道混洗 [44, 75] 和结构重新参数化 [14] 等。这些方法为开发几种广泛使用的轻量级 CNN 铺平了道路,例如 MobileNets [26,27, 53]、ShuffleNets [44, 75] 和 RepVGG [14]。
随后,引入了视觉Transformer (ViT) [18],它采用 Transformer 架构在大规模图像识别任务上实现最先进的性能,超过了 CNN [18, 58]。基于vit的竞争性能,后续工作试图结合空间归纳偏置来提高其稳定性和性能[10,22],设计更有效的自注意力操作[17,79],并使vit适应各种计算机视觉任务[19,74]。
尽管 ViT 在各种视觉任务中表现出比 CNN 更好的性能,但它们中的大多数都是参数量很多的,需要大量的计算和内存占用 [39, 58]。这使得它们不适合资源有限的移动设备[46,49]。因此,研究人员致力于探索各种技术,使vit更轻量级,对移动设备更友好[47,59]。例如,MobileViT[46]采用混合架构,结合轻量级MobileNet块和多头自注意(MHSA)块。EfficientFormer[36]提出了一种维度一致的设计范式来增强延迟性能边界。这些轻量级vit已经证明了新的SOTA和移动设备上的延迟权衡,优于以前的轻量级 CNN [53, 60]。
轻量级vit的成功通常归功于具有学习全局表示能力的多头自注意模块。然而,轻量级 CNN 和轻量级 ViT 之间的显着架构区别,包括它们的块结构,以及宏观和微观元素,通常被忽略。因此,与现有工作不同,我们的主要目标是通过整合轻量级 ViT 的架构设计来重新审视轻量级 CNN 的设计。我们的目标是弥合轻量级 CNN 和轻量级 ViT 之间的差距,并保持前者的移动设备友好性。
3. 方法
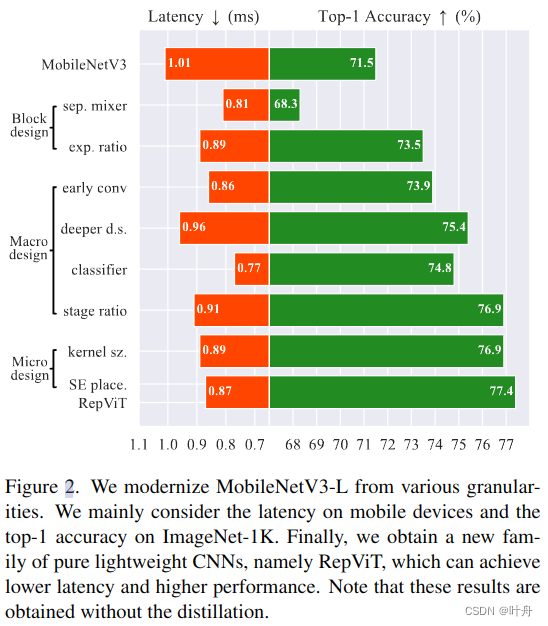
在本节中,我们从标准的轻量级 CNN 开始,即 MobileNetV3-L,然后通过结合轻量级 ViT 的架构设计逐渐从各种粒度对其进行现代化。我们首先引入度量来衡量移动设备上的延迟,然后在3.1节中将训练配方与现有的轻量级vit对齐。基于一致的训练设置,我们在第3.2节中探讨了最优块设计。我们在第3.3节中从宏观架构元素(即茎、下采样层、分类器和整体阶段比)进一步优化MobileNetV3-L在移动设备上的性能。然后,我们在第3.4节中通过分层微设计调整轻量级CNN。图2显示了我们在每个步骤中实现的整个过程和结果。最后,我们在第 3.5 节中获得了为移动设备设计的一类新的纯轻量级 CNN,即 RepViT。所有模型都在 ImageNet-1K 上进行训练和评估。
3.1. 准备工作
延迟度量:以前的工作 [5, 57] 基于浮点运算 (FLOP) 或模型大小等指标优化模型的推理速度。然而,这些指标在移动应用程序[36]中与现实世界的延迟没有很好的相关性。因此,按照 [35, 36, 46, 60]的做法,我们测量实际的设备上延迟作为基准指标。这样的策略可以为现实世界移动设备上的不同模型提供更准确的性能评估和公平的比较。在实践中,我们利用iPhone 12作为测试设备,Core ML Tools[1]作为编译器,如[35,36,60]。此外,为了避免使用 Core ML 工具不支持的功能,我们在 [36, 60] 之后在 MobileNetV3-L 模型中采用 GeLU 激活。我们测量 MobileNetV3-L 的延迟为 1.01 ms。
训练方案对齐:最近的轻量级vit[35,36,46,49]通常采用DeiT[58]的训练方案方。具体来说,他们使用AdamW优化器[42]和余弦学习率调度器,从头开始 300 个 epoch来训练模型,并使用使用RegNetY16GF[51]作为老师进行蒸馏。此外,他们采用Mixup[72]、自动增强[8]和随机擦除[77]进行数据增强。标签平滑[56]也被用作正则化方案。为了公平比较,我们将 MobileNetV3-L 的训练方案与现有的轻量级 ViT 对齐,不过排除了知识蒸馏。因此,MobileNetV3-L 获得了 71.5% 的 top-1 准确率。现在,我们默认使用此训练方案。
3.2. block设计
Separate token mixer and channel mixer:相关轻量级vit[35,36,47]研究所提出的块结构包含了一个重要的设计特征,即单独的令牌混合器(token mixer)和通道混合器(channel mixer)[70]。根据最近的研究[69],vit的有效性主要源于它们的一般令牌混合器和通道混合器架构,即MetaFormer架构,而不是配备的特定令牌混合器。鉴于这一发现,我们的目标是通过在MobileNetV3-L中拆分令牌混合器和通道混合器来模拟现有的轻量级vit。
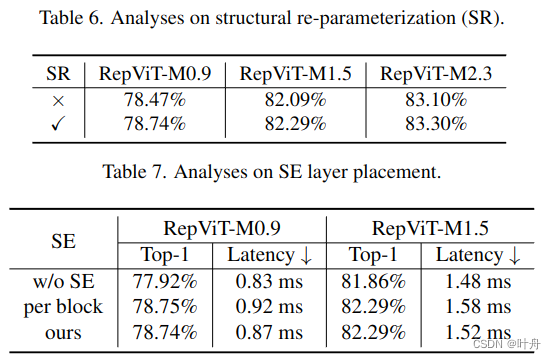
具体来说,如图 3(a) 所示,原始 MobileNetV3 块采用 1×1 扩展卷积和一个1 × 1 投影层来实现通道之间的交互(即通道混合器)。在1×1展开卷积之后配置3×3深度(DW)卷积,用于空间信息(即令牌混合器)的融合。这样的设计使得令牌混合器和通道混合器耦合在了一起。为了分离它们,我们首先向上移动 DW 卷积。可选的挤压激励 (SE) 层也移到 DW 之后,因为它取决于空间信息交互。因此,我们可以在MobileNetV3块中成功分离令牌混合器和通道混合器。我们进一步对 DW 层采用了广泛使用的结构重新参数化技术 [7, 14] 来增强训练期间的模型学习。由于结构重新参数化技术,我们可以在推理过程中消除与跳跃连接相关的计算和内存成本,这对于移动设备尤其有利。我们将此块命名为 RepViT 块(图 3.(b)),它将 MobileNetV3-L 的延迟降低到 0.81 ms,以及临时性能下降到 68.3%。
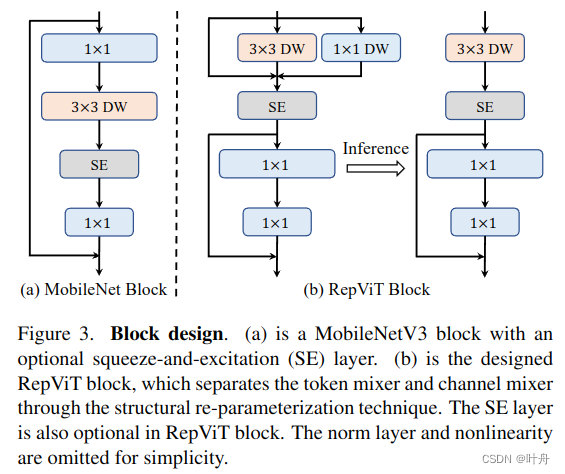
PS:对图3(b),token mixer 和 channel mixer是分别被不同的卷积层来表示的,token mixer是3*3DW+SE,channel mixer是1*1+1*1。这一点可以从源码中找到对应关系:
class RepViTBlock(nn.Module): def __init__(self, inp, hidden_dim, oup, kernel_size, stride, use_se, use_hs): super(RepViTBlock, self).__init__() assert stride in [1, 2] self.identity = stride == 1 and inp == oup assert(hidden_dim == 2 * inp) if stride == 2: self.token_mixer = nn.Sequential( Conv2d_BN(inp, inp, kernel_size, stride, (kernel_size - 1) // 2, groups=inp), SqueezeExcite(inp, 0.25) if use_se else nn.Identity(), Conv2d_BN(inp, oup, ks=1, stride=1, pad=0) ) self.channel_mixer = Residual(nn.Sequential( # pw Conv2d_BN(oup, 2 * oup, 1, 1, 0), nn.GELU() if use_hs else nn.GELU(), # pw-linear Conv2d_BN(2 * oup, oup, 1, 1, 0, bn_weight_init=0), )) else: assert(self.identity) self.token_mixer = nn.Sequential( RepVGGDW(inp), SqueezeExcite(inp, 0.25) if use_se else nn.Identity(), ) self.channel_mixer = Residual(nn.Sequential( # pw Conv2d_BN(inp, hidden_dim, 1, 1, 0), nn.GELU() if use_hs else nn.GELU(), # pw-linear Conv2d_BN(hidden_dim, oup, 1, 1, 0, bn_weight_init=0), )) def forward(self, x): return self.channel_mixer(self.token_mixer(x))
减少膨胀比并增加宽度:在 vanilla ViT 中,通道混合器中的扩展率通常设置为 4,使得前馈网络 (FFN) 模块的隐藏维数比输入维度宽 4 倍。因此,它消耗的计算资源的很大一部分,从而对整体推理时间有很大贡献[76]。为了缓解这一瓶颈,最近的工作[21,30]采用了更窄的FFN。例如,LV-ViT [30] 在 FFN 中采用 3 的扩展比。LeViT[21]将扩展比设置为2。此外,Yang等人[68]指出FFN中存在大量的信道冗余。因此,使用较小的扩展比是合理的。
在 MobileNetV3-L 中,扩展比范围从 2.3 到 6,最后两个阶段的浓度为 6,通道数较多。对于我们的 RepViT 块,我们在通道混合器中为所有阶段设置扩展比为 2,遵循 [21, 30, 38]。这导致延迟减少到 0.65 毫秒。因此,随着扩展比较小,我们可以增加网络宽度来弥补大量参数的减少。我们在每个阶段之后对通道进行双重处理,每个阶段最终得到48,96,192和384个通道。这些修改可以将 top-1 准确率提高到 73.5%,延迟为 0.89 ms。请注意,通过直接调整原始 MobileNetV3 块上的扩展率和网络宽度,我们在 0.91 ms 的类似延迟下获得了 73.0% 的 top-1 准确率的较差性能。因此,默认情况下,对于块设计,我们使用带有 RepViT 块的新扩展率和网络宽度。
3.3. 宏观设计
在这一部分中,我们对移动设备的宏观架构进行了优化,包括从网络前端到网络后端的所有环节。
Early convolutions for stem:ViT通常使用补丁操作作为stem,将输入图像划分为不重叠的补丁[18]。这个简单的stem对应于具有大内核大小(例如,内核大小 = 16)和大步幅(例如,步幅 = 16)的非重叠卷积。分层 ViT [39, 63] 采用相同的补丁操作,但补丁大小为 4。然而,最近的工作 [65] 表明,这种补丁操作很容易导致 ViT 的训练方案的非标准优化能力和敏感性。为了缓解这些问题,他们建议使用少量堆叠的 步长为2的 3×3 卷积作为stem的替代方案,称为早期卷积,提高了优化稳定性和性能,这也是其广泛应用于轻量级 ViT [35, 36]的原因。
相比之下,MobileNetV3-L 采用复杂的stem,涉及 3 × 3 卷积、深度可分离卷积和倒置瓶颈,如图 4(a) 所示。由于主干模块以最高分辨率处理输入图像,因此复杂的架构可能会受到移动设备上严重的延迟瓶颈的影响。因此,作为权衡,MobileNetV3-L 将过滤器的初始数量减少到 16,这反过来又限制了词干的表示能力。为了解决这些问题,在 [35, 36, 38, 65] 之后,我们采用早期卷积的方法 [65],简单地装备两个步长为 = 2 的 3 × 3 卷积作为词干。如图 4(b) 所示,第一个卷积中的过滤器数设置为 24,第二个卷积中的过滤器数设置为 48。整体延迟降低到 0.86 ms。同时,top-1 准确率提高到 73.9%。我们现在将使用早期卷积作为stem。
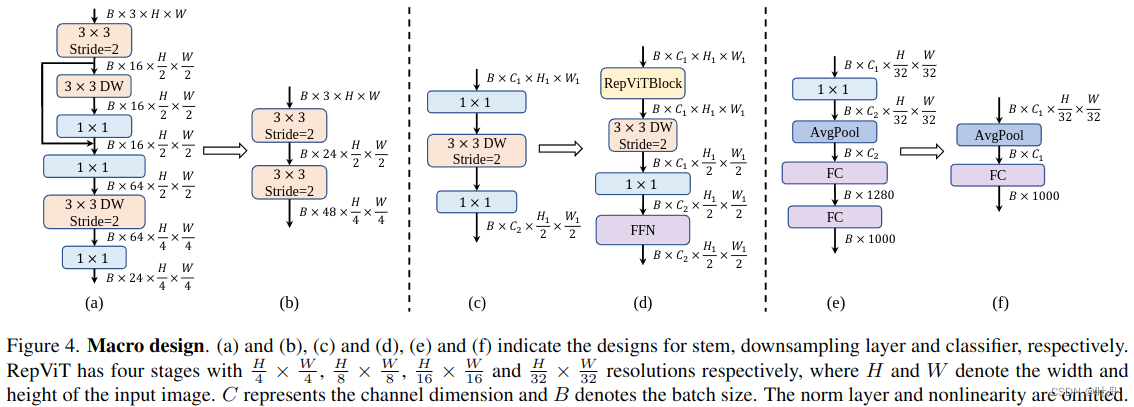
Deeper downsampling layers: 在vit中,空间下采样通常是通过一个单独的补丁合并层来实现的。如[41]所示,这种基于分离的下采样层促进了网络深度的增加,减少了分辨率降低造成的信息丢失。因此,EfficientViT [38] 采用sandwich布局来加深下采样层,实现高效有效的下采样。相比之下,MobileNetV3-L 仅通过步长为 = 2 的 DW 卷积的反向瓶颈块实现下采样,如图 4.(c) 所示。这种设计可能缺乏足够的网络深度,导致信息丢失和对模型性能的负面影响。因此,为了实现单独和更深的下采样层,我们首先使用stride = 2和pointwise 1 × 1卷积的DW卷积分别进行空间下采样和调制通道维度,如图4(d)所示。此外,我们在RepViT块前面加上一个RepViT块来进一步加深下采样层。在 1×1 卷积之后放置一个 FFN 模块来记忆更多的潜在信息。因此,这种更深的下采样层将 top-1 准确率提高到 75.4%,延迟为 0.96 ms。我们现在将利用更深的下采样层。
Simple classifier:在轻量级 ViT [21, 36, 46] 中,分类器通常由全局平均池化层和一个线性层组成。因此,这种简单的分类器对延迟很友好,尤其是对于移动设备。相比之下,MobileNetV3-L 采用复杂的分类器,其中包括一个额外的 1×1 卷积和一个额外的线性层来将特征扩展到高维空间 [9],如图 4.(e) 所示。这样的设计对于MobileNetV3-L生成丰富的预测特征[26]至关重要,特别是在最后阶段给出小输出通道。然而,这反过来又给移动设备上的延迟带来了沉重的负担。考虑到最后阶段现在在第 3.2 节中的块设计之后有更多的通道,因此我们将其替换为一个简单的分类器,即全局平均池化层和线性层,如图 4.(f) 所示。此步骤导致精度下降 0.6%,但延迟降低到 0.77 ms。我们现在将使用简单的分类器。
Overall stage ratio:阶段比表示不同阶段的块数之比,从而表示跨阶段计算的分布。以前的工作[50,51]表明,利用第三阶段更多的块在精度和速度之间取得了很好的平衡。因此,现有的轻量级vit在这个阶段通常应用更多的块。例如,EfficientFormer-L2 [36] 采用 1:1:3:1.5 的阶段比率。同时,Conv2Former [25] 表明,更极端的阶段比率和更深的布局对于小型模型表现更好。因此,他们分别采用 Conv2Former-T 和 Conv2FormerS 的 1:1:4:1 和 1:1:8:1 的阶段比率。在这里,我们对网络采用 1:1:7:1 的阶段比率。然后,我们将网络深度增加到 2:14:2,实现更深的布局。此步骤将 top-1 准确率提高到 76.9%,延迟为 0.91 ms。我们将使用这个阶段比率。
3.4. 微观设计
在本节中,我们关注轻量级 CNN 的微架构,包括内核大小选择和SE层的放置。
Kernel size selection:CNN 的性能和延迟经常受到卷积核大小的影响。例如,为了捕获 MHSA 等长期依赖关系,ConvNeXt [41] 采用大型内核大小的卷积,表现出性能提升。同样,RepLKNet [15] 展示了一种强大的范式,它利用 CNN 中的超大卷积核。然而,由于其计算复杂度和内存访问成本,大型内核化卷积对移动设备并不友好。此外,与 3 × 3 卷积相比,更大的卷积核通常不会通过编译器和计算库 [14] 进行优化。MobileNetV3-L 主要利用 3 × 3 卷积,在某些块中使用了少量 5 × 5 卷积。为了确保移动设备上的推理效率,我们在所有模块中优先考虑简单的 3 × 3 卷积。这种替换可以保持 76.9% 的top-1 准确率,同时延迟降低到 0.89 ms。我们现在将使用 3 × 3 卷积。
SE层的放置:与卷积相比,自注意力模块的一个优点是能够根据输入调整权重,称为数据驱动属性 [29, 64]。作为通道明智的注意模块,SE 层 [28] 可以弥补卷积缺乏数据驱动属性的局限性,带来更好的性能 [73]。MobileNetV3-L 在某些块中包含 SE 层,主要关注后两个阶段。然而,如[52]所示,与分辨率较高的特征图阶段相比,低分辨率特征图的相位获得了更小的精度优势。同时,随着性能提升,SE 层还引入了不可忽略的计算成本。因此,我们设计了一种以跨块方式利用 SE 层的策略,即在每个阶段的第 1、3、5 ...块中采用 SE 层,以达到以最小的延迟增量最大化准确性优势的目的。此步骤将 top-1 准确率提高到 77.4%,延迟为 0.87 ms。我们现在将使用这个跨块 SE 层放置。这带来了我们的最终模型,即 RepViT。
3.5. 网络结构
在[36,46]之后,我们开发了多个RepViT变体,包括RepViT-M0.9/M1.0/M1.1/M1.5/M2.3。后缀“-MX”表示对应模型的延迟在移动设备上为X ms,即iOS 16的iPhone 12。变体的区别在于通道的数量以及每个阶段的块数。有关详细信息,请参阅补充材料。
4. 实验
4.1. Image Classification
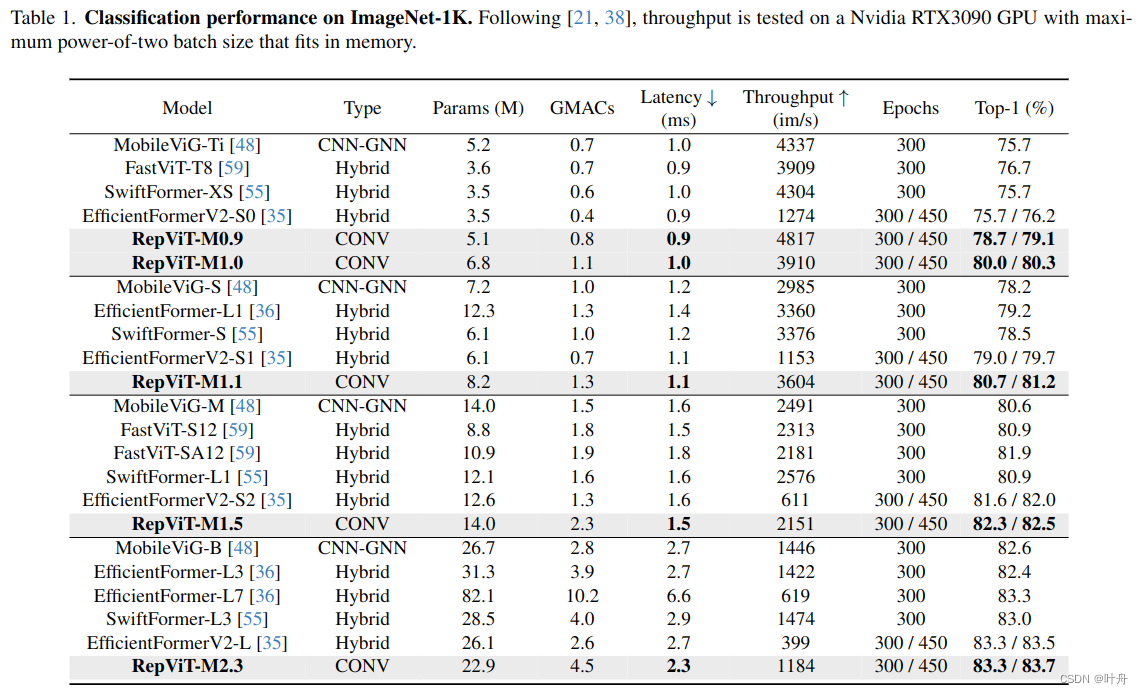
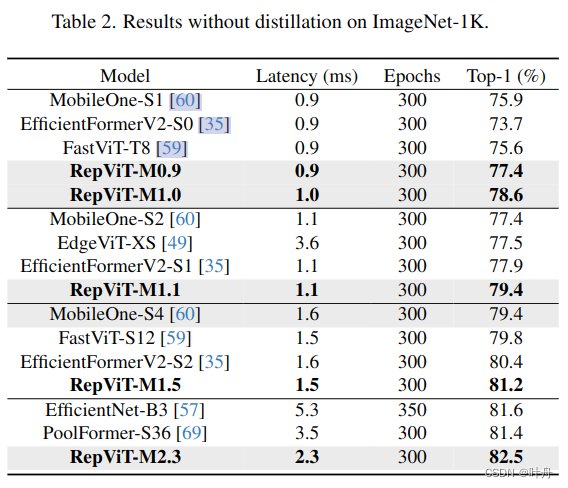
4.2. RepViT meets SAM
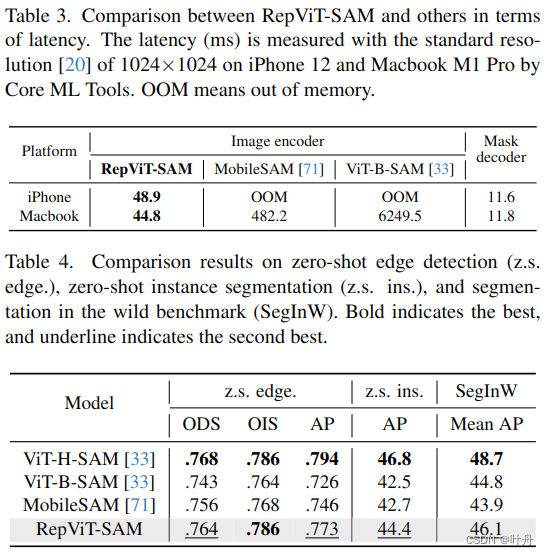
4.3. Downstream Tasks

4.4. Model Analyses
5.结论
在本文中,我们通过结合轻量级 ViT 的架构设计重新审视轻量级 CNN 的有效设计。我们最终得到了 RepViT,这是一种用于资源受限的移动设备的新型轻量级 CNN 系列。RepViT在各种视觉任务中优于现有的最先进的轻量级vit和cnn,显示出良好的性能和延迟。它突出了纯轻量级cnn在移动设备上的前景。我们希望 RepViT 可以作为强大的基线,并激发对轻量级模型的进一步研究。


















 5147
5147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











