







学习前言
MPC什么的学着也太痛苦了。

源码下载
https://github.com/alexliniger/MPCC.git
相关求解器
- Active-set methods: qpOASES, qrqp
- Interior-point methods: hpipm, OOQP, CVXGEN
- alternating direction method of multipliers (ADMM): OSQP
对于线性的mpc问题,最好是推导成dense qp形式,然后用基于active set/ADMM求解法的求解器原库计算
基本概念
MPC
- 核心思想:以最优化方法求解最优控制器,其中优化方法大多时候是二次规划(Quadratic Programming)。区别于其他控制算法的关键在于采用滚动优化、滚动实施控制。
- “三大原理”:预测模型、滚动优化、反馈矫正。
- 抽象理解:在每一个采用时刻,根据获得的当前测量信息,在线求解一个有限时间开环优化问题,并将得到的控制序列的第一个元素作用于被控对象。在下一个采样时刻,重复上述过程:用新的测量值作为此时预测系统未来动态的初始条件,刷新优化问题并重新求解 。
- 直观理解:
a. Model:System model;problem model;
b. Prediction:State space(p,v,a); Input space(F); Parameter space(环境,无限维);
c. Control: the process of choosing the best policy;

反馈控制
优点:
- 设计简单;
- 考虑了误差;
缺点:
- 对复杂系统非平凡;
- 控制系数(control gains,Kp,Kv)需要手工调整;
- 无法同时处理一组动力和约束控制;
- 不关注未来决策,反应式控制,只考虑当前,十分短视;
最优控制
- 最优控制(optimal control)指的是在一定的约束情况下达到最优状态的系统表现,其中约束情况通常是实际环境所带来的限制,例如汽车中的油门不能无限大等。
- 最优控制强调的是“最优”,一般最优控制需要在整个时间域上进行求优化(从0时刻到正无穷时刻的积分,开环),这样才能保证最优性,这是一种很贪婪的行为,需要消耗大量算力。同时,系统如果是一个时变系统,或者面临扰动的话,前一时刻得到的最优并不一定是下一时刻的最优值。
- 最优控制常用解法有: 变分法,极大值原理,动态规划,LQR;
- MPC仅考虑未来几个时间步,一定程度上牺牲了最优性。
MPC优点
- 考虑了参考与预测之间的误差;
- MPC可以处理约束,如安全性约束,上下阈值;
- MPC是一种向前考虑未来时间步的有限时域优化方法(一定的预测能力);
- 最优控制要求在整个时间优化,实际上MPC采用了一个折中的策略,既不是像最优控制那样考虑整个时域,也不是仅仅考虑当前,而是考虑未来的有限时间域,缩小了问题的规模;
- 善于处理多输入多输出系统(MIMO),对全驱动系统、冗余驱动系统及欠驱动系统均有较好的应用结果;
Linear MPC实现思路
预测模型

问题模型
目标1: 从空间中的任意位置到原点;
目标2: 轨迹平滑;
优化目标函数1:
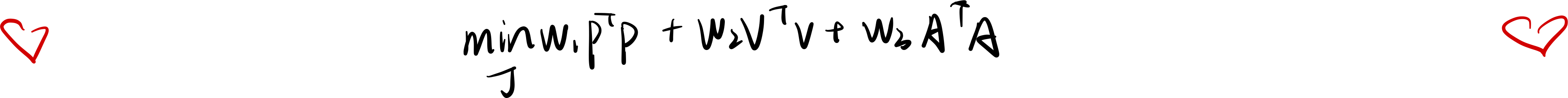
优化目标函数2:

硬约束

软约束
当约束条件不可避免的会被违反,为了防止求解器无解。引入软约束;
例如:约束②条件变为:
L足够大的话,不等式一定成立,所以要设置一个合理的L使不等式成立但也有足够的超出的风险
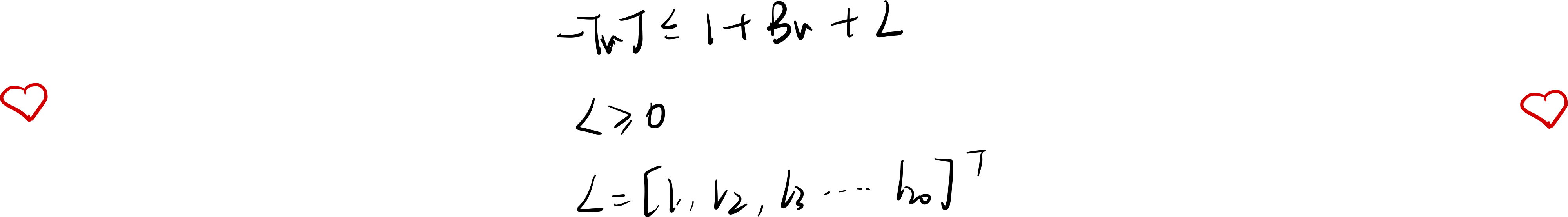
新的目标函数变为:
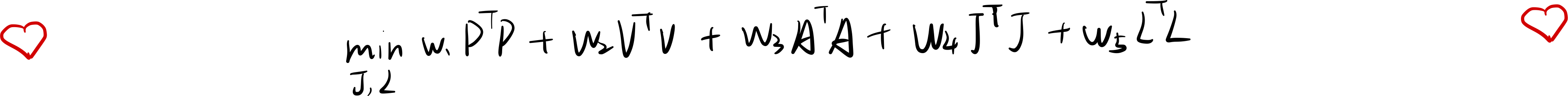
Linear MPC缺点
- 需要线性的预测模型,或者可线性化的模型(adaptiveMPC);
- 障碍物约束通常非凸;
Case Study
- Nonlinear MPC for Quadrotor Fault-Tolerant Control
- Whole-Body MPC and Online Gait Sequence Generation for Wheeled-Legged Robots
- Corridor-based Model Predictive Contouring Control for Aggressive Drone Flight (https://github.com/ZJU-FAST-Lab/CMPCC.git)
- EVA-planner: an EnVironmental Adaptive Gradient-based Local Planner for Quadrotors.(https://github.com/ZJU-FAST-Lab/EVA-planner.git)
参考资料
- 深蓝学院运动规划课程
- 【自动驾驶】模型预测控制(MPC)实现轨迹跟踪
- qpOASES使用手册: https://www.coin-or.org/qpOASES/doc/3.0/manual.pdf
- https://github.com/robotology/osqp-eigen

















 1722
1722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









