






 PubMedGPT是CRFM和MosaicML合作开发的大型语言模型,专门针对生物医学领域训练。该模型在PubMed数据集上训练,显示了特定领域LLM的潜力和优秀性能。使用MosaicML云平台和Composer库进行训练,PubMedGPT在问答基准上表现出色,挑战了专业设计系统的性能。这标志着在生物医学文本理解和交互式AI系统发展上的初步成功。
PubMedGPT是CRFM和MosaicML合作开发的大型语言模型,专门针对生物医学领域训练。该模型在PubMed数据集上训练,显示了特定领域LLM的潜力和优秀性能。使用MosaicML云平台和Composer库进行训练,PubMedGPT在问答基准上表现出色,挑战了专业设计系统的性能。这标志着在生物医学文本理解和交互式AI系统发展上的初步成功。
“我们很高兴发布一种在PubMed上训练的新生物医学模型,这是构建可支持生物医学研究的基础模型的第一步。”——CRFM主任Percy Liang
近日,斯坦福基础模型研究中心(CRFM)和MosaicML联合开发了PubMed GPT模型,一种经训练可以解释生物医学语言的大型语言模型。

目前的大型语言模型(LLM)通常使用于自然语言合成、图像合成及语音合成等,而已知在特定行业的应用很少。本文所要介绍的PubMed GPT即展示了特定行业大型语言模型的能力,尤其在生物医学领域。通过MosaicML云平台,CRFM的开发者在PubMed的生物医学数据集上训练了一个生成式预训练模型(GPT)。结果表明,特定领域的语言生成模型在实际应用中将会有很好的发展前景,同时,LLM也展现出更加优秀的性能和竞争力。注意:目前此模型仅用于研究开发,不适合生产。
PubMed GPT
模型。PubMed GPT 2.7B基于HuggingFace GPT模型,具有2.7B的参数和1024个标记的最大上下文长度。尽可能简单的设计展示了现有LLM训练方法的强大功能。
数据。采用Pile数据集的部分——PubMed Abstracts和PubMed Central。
计算。开发者选择在50B的令牌上多次训练PubMed GPT,达到一个较长的计算周期(300B)。结果表明,在数据受限的情况下仍可训练出优秀的LLM模型。
MosaicML云平台
MosaicML云。基于MosaicML云软件栈,开发者在具有128个NVIDIA A100-40GB GPU、节点间1600Gb/s网络带宽的集群上训练PubMed GPT,总训练时长约6.25天。
Composer库。由于MosaicML开源Composer库的高效性和包容性,开发者使用Composer库以及它的FSDP集成来训练模型。
流数据集。为快速、灵活且廉价地管理自定义训练数据集,开发者使用MosaicML的新StreamingDataset库来管理100GB多文本的训练数据集。
评估
开发者在几个问答基准上对PubMed GPT进行了评估。例如下面的一个医学问题摘要基准:

其对患者的疑问查询(其中会包含歧义、拼写错误等方面的信息)进行处理,并以清晰正确的格式呈现给医生。
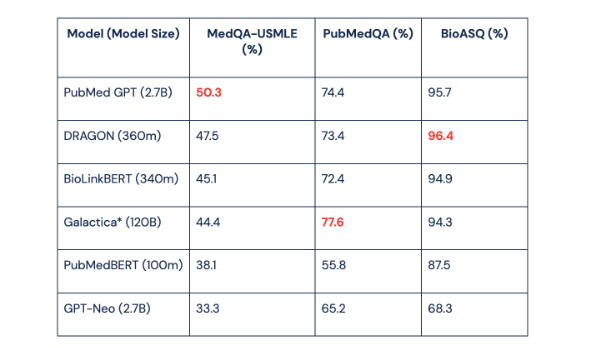
同时开发者将结果与5个模型进行了比较(如上图):DRAGON、GPT-Neo 2.7B、Galactica、BioLinkBERT、PubMedBERT。结果证明:
1、LLM非常全能,在特定领域中从头训练时其具有与专业设计的系统相当的性能;
2、针对特定领域数据的预训练胜过通用数据;
3、专注模型可以用较少的资源获得高质量结果。
总结
PubMed GPT的结果只是生物医学文本及其他领域研究的第一步,往后仍需要更多研究者来开发更加先进的成果。而且目前只是概念验证,最终的希望是在未来出现值得信赖的交互式AI系统,在与人类专家进行筛选的同时也促进可靠的交互。
参考资料
https://www.mosaicml.com/blog/introducing-pubmed-gpt
往期精品(点击图片直达文字对应教程)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|




























后台回复“生信宝典福利第一波”或点击阅读原文获取教程合集




















 1423
1423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









