







Fast RCNN 出自Ross Girshick 的2015 ICCV Fast R-CNN,对RCNN做了很大的改进,用VGG16训练,速度提升9倍多,测试速度提升213倍多,在VOC2012刷出了0.66的mAP。
这篇论文除了讲解了作者自己的模型外,还对里面应用的好多trick进行了验证,非常值得从头到尾都看完啊。
Fast RCNN的几个优势:
(1)比RCNN,SPPnet更高的mAP
(2)训练过程是单级的(single-stage),并且使用了多任务损失(multi-task loss),现在来看,各种检测模型用的都是这种多任务损失
(3)所有网络层共享参数
(4)不需要磁盘空间来暂时作为特征缓存的地方
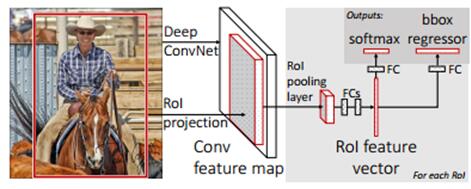
训练过程的流程如上图所示,输入图片和物体框信息,经过CNN抽取ROI,然后经过固定大小的ROI pooling layer进行随机抽取,并经过全连接FC层转化为特征向量。最终分为2部分,一部分经过softmax输出物体类别,一个经过box regress输出物体的位置信息。
多任务损失(Multi-task loss):
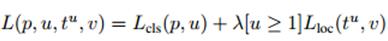
训练过程中,将类别预测的损失和物体检测位置的损失一起考虑进去,并且经过作者实际的测试,多任务损失这个框架还是很work的。平均提高0.8-1.1个mAP。

奇异值分解(SVD):
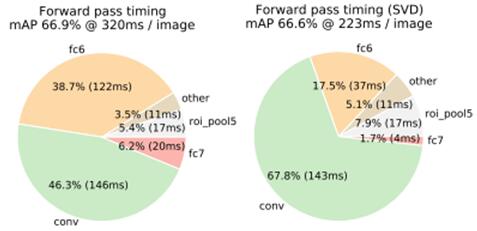
在检测阶段,时间主要是话费在卷基层,在全连接层使用的时间相比卷基层来说是少的,但是对于ROI的数量很大的情况下,这段全连接层的时间就会增加很多,因此,作者提出了SVD分解,实现上将原来的一个全连接层用2个全连接层代替,在很小的mAP损失的情况下,实现了较好的加速,具体加速和损失情况可以看下图作者在VGG16上的测试,左图为未使用SVD分解,右图为使用了SVD分解。
多尺度(Multi-scale)训练优于单一尺度(single scale)
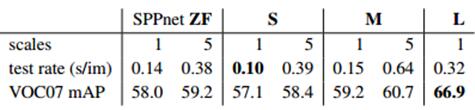
从上图作者在SPPnet,small model,middle model上可以看出,5个尺度要比1个尺度好,由于largemodel作者的GPU跑不起来,所以没有进行5个尺度的测试,但是丝毫不影响这样的结论的得出。同时也说明,大模型要不小模型更精确,当然运行速度也就相应的变慢。
more training data==better
(1)VOC2007 的trainval训练的mAP为0.669,VOC2007 trainval+ VOC2012 trainval的mAP为0.700
(2)单纯VOC2010的训练后mAP为0.661,单纯VOC2012的训练mAP为0.657,voc2007 trainval+test+VOC12 trainval训练的mAP在VOC10和VOC12上测试分别为0.688和0.684
通过作者的实际测试,训练数据越多,出的模型就会相对越好。
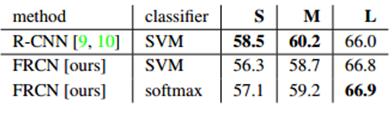
softmax比SVM好
在RCNN中使用的是SVM分类,在Fast RCNN中使用的是softmax,通过作者的测试,softmax的实际效果要不SVM好0.1个mAP
object proposals的数目不是越多越好
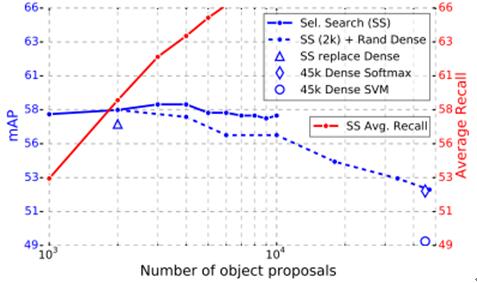
上图是作者在VOC07上的测试,蓝色实线表示mAP,红色实线表示AR(Average Recall),从走势可以看出,随着proposal数目的增多,mAP缓慢的上升,后面又急速的下降,可见,proposal的数目还是有个最佳的波峰值的,不能太少,也不能太多。另外平均召回率随着proposal数目的增多而显著的上升。但是召回率高了不等于说检测最终结果就好,最终结果还是得看mAP。
安装步骤:
安装caffe:
参考BLVC
注意,下面的这句注释必须打开,取消注释,
WITH_PYTHON_LAYER := 1
安装python包:
sudoapt-get install python-pip
sudo pipinstall cython
sudo pip install python-opencv
sudo pipinstall easydict
安装fast-rcnn:
git clone--recursive https://github.com/rbgirshick/fast-rcnn.git
cd $FRCN_ROOT/libmakecd $FRCN_ROOT/caffe-fast-rcnnmake -j8 && make pycaffe&& make matcaffecd $FRCN_ROOT./data/scripts/fetch_fast_rcnn_models.sh (0.9G大小)python运行demo
cd $FRCN_ROOT./tools/demo.py
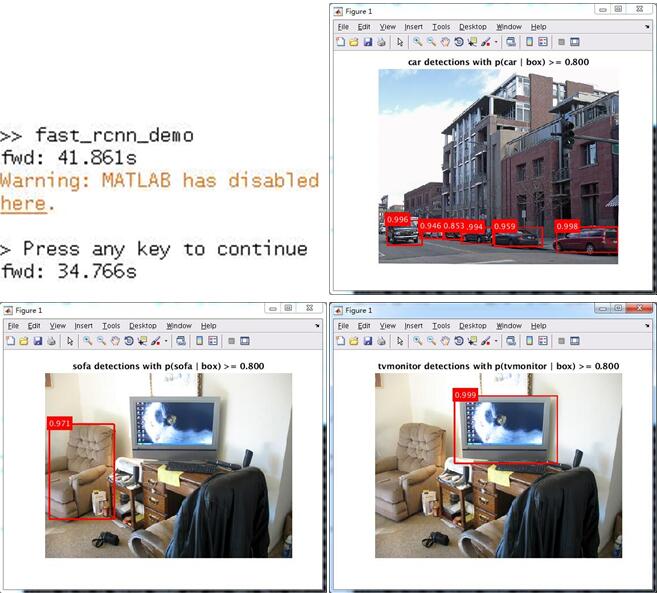
matlab运行demo
cd $FRCN_ROOT/matlabmatlab fast_rcnn_demo下面贴出的时间为cpu测试的时间,分别为上下2幅图的时间。
注意,请使用v3版本的cudnn,否则会报如下错误。
错误:
20 errors detected in the compilation of"/tmp/tmpxft_00004292_00000000-16_cudnn_conv_layer.compute_50.cpp1.ii".
make: ***[.build_release/cuda/src/caffe/layers/cudnn_conv_layer.o] 错误 1
make: *** 正在等待未完成的任务....
解决方法:
换成v3版本的cudnn
cd lib64/sudo cp lib* /usr/local/cuda/lib64/cd ../include/sudo cp cudnn.h /usr/local/cuda/include/cd /usr/local/cuda/lib64/sudo rm -r libcudnn.so libcudnn.so.3.0sudo ln -sf libcudnn.so.3.0.64 libcudnn.so.3.0sudo ln -sf libcudnn.so.3.0 libcudnn.sosudo ldconfig
整体流程:
(1)在图像中通过选择性搜索selective search方法确定确定1000-2000个roi 候选框。
(2)对整张图片进行CNN操作,得到conv5输出的feature map。
(3)找到每一个roi候选框在feature map上的映射patch,将该patch输入后续cnn网络进行特征图上提特征操作。
(4)将提取的特征分别输入2个分支,进行分类和回归操作。
总结:
(1)RCNN中需要对每一个ss提取到的区域都输入网络进行特征计算,里面存在了大量的计算冗余。fast rcnn借鉴了spp net的优点,先使用vgg直接在全图提特征。然后在第五个卷积层,基于ss的结果,通过一个patch的映射操作,直接特征图上提取特征。达到了共享计算的效果。
(2)RCNN整体流程大概分为3步(ss提取ROI区域,cnn提取特征,svm分类),这3个步骤是相互独立的。fast rcnn通过softmax和smooth l1的提出+ROI pooling,将cnn提取特征+svm分类这2步合二为一。最终fast rcnn只需要ss+cnn两步操作。
(3)RCNN中对ss提取出的roi进行resize操作,才送入cnn进行特征提取。fast rcnn中提出了roi pooling操作,可以直接实现roi区域的resize操作,从而支持了端到端训练。
(4)RCNN中使用svm进行分类,fast rcnn中使用softmax进行了改进,同时还加入了边框回归操作。分类和回归一起做,实现了多任务训练,两者相互补充,可以学习到更好的结果。
最终结果收益:
| RCNN | fast rcnn | |
| 训练时间 | 84小时 | 9.5小时 |
| 训练加速比 | 1X | 8.8X |
| 每张图平均测试时间 | 47秒 | 0.32秒 |
| 测试加速比 | 1X | 146X |















 764
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









