






近期,大语言模型(LLM)驱动的智能体(MA)取得了显著进展,集体智能表现出超越单个智能体能力的优势,主要归功于精心设计的智能体间通信拓扑。然而,现有的多智能体系统在性能上的提升是以大量的token开销和经济成本为代价的,这使得大规模部署面临挑战。为应对这一问题,该文章提出了一种经济、简洁且强大的多智能体通信优化框架——AgentPrune,它能够无缝集成到主流多智能体系统中,并剪枝冗余的通信信息,使得MA中的Agent能“少说废话”(cut the crap)。
论文:Cut the Crap: An Economical Communication Pipeline for LLM-based Multi-Agent Systems
链接:https://arxiv.org/pdf/2410.02506
作者:Wzl
来自:深度学习自然语言处理
研究背景&动机
现有大模型多智能体系统(LLM-MA)中的通信机制主要分为两种:
Intra-dialogue communication: 多个Agent在同一轮对话中的互动方式。(例:合作、教学、竞争...)
Inter-dialogue communication: 跨对话轮次的信息传递和参考。(例:总结、复制、过滤...)
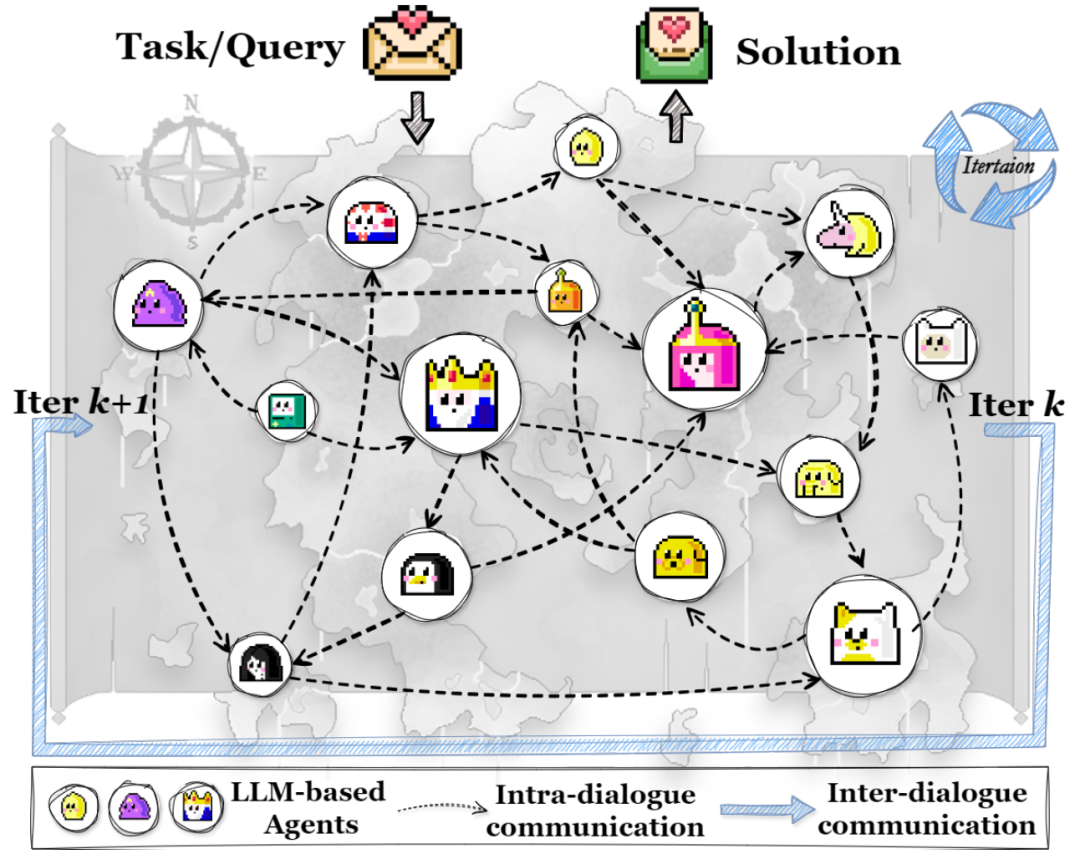
存在的问题和挑战:
Muti-agent在performance上的提升是以大量的token消耗为代价的。
目前依赖大量的token消耗的Muti-agent在部署上有限,边缘智能设备无法支持这样的token消耗。
发现&方法
首先,作者将LLM-MA定义为时空图,主要的定义为: 发现:
发现:
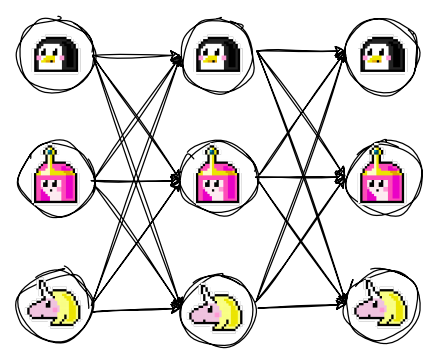
Spatial(同一轮内)使用全连接图,例如MacNet(OpenBMB);Temporal(跨轮次)类似LLM-Debate(MIT),每个agent会收到上一轮的所有回复作为输入。
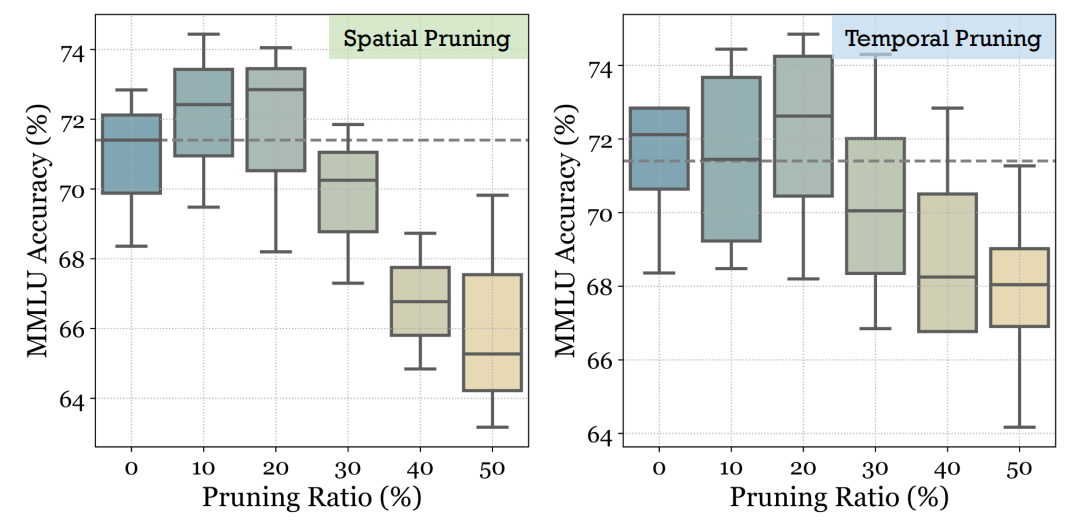
使用4个GPT-3.5作为agents,随机裁剪20-30%,性能会提升。
因此将Communication Redundancy定义为LLM-MA图中不必要的边,去掉这些边,性能变化小于一个可以接受的阈值。
Intra-dialogue communication使用全连接图:
Inter-dialogue communication中每个agent接收上一轮的所有回复:
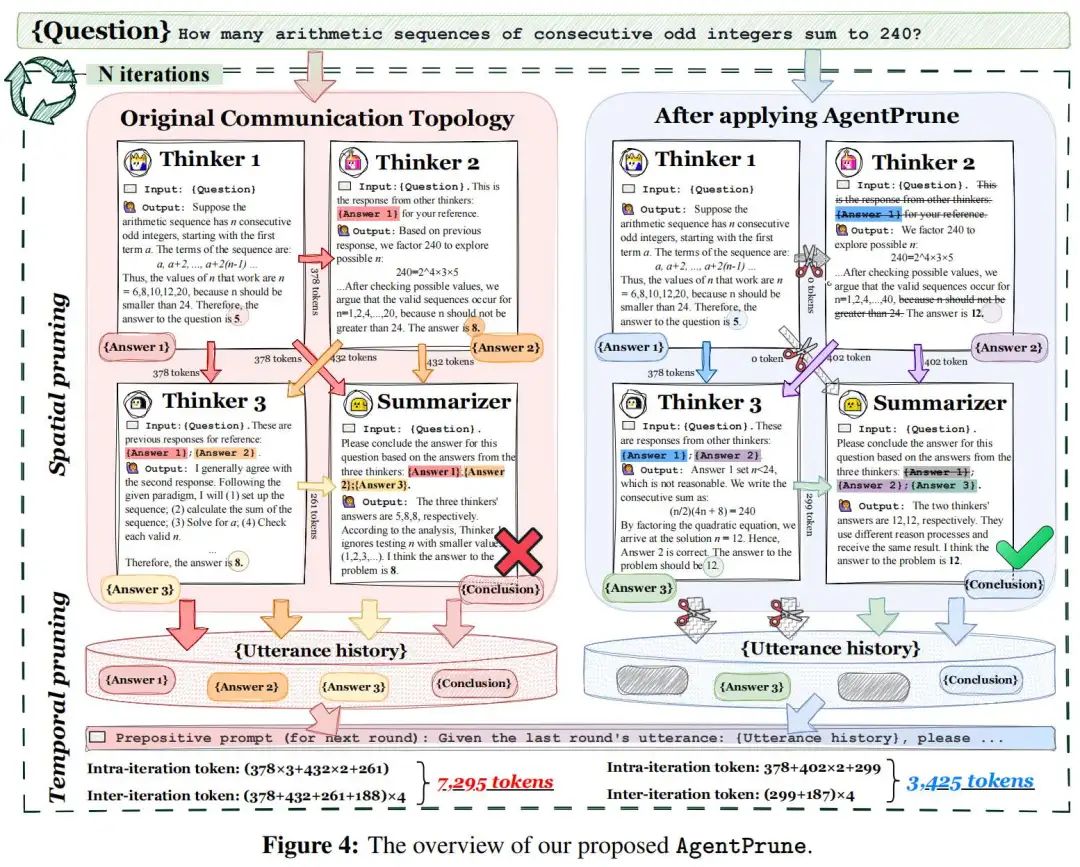
方法:
AgentPrune的目标是找到一个表现很好的子图,这个子图的目标是:近似分布,低秩稀疏性。
过程就是先通过“一次性剪枝”,进行K’次,构建高质量的子图。再利用该子图,进行之后K-K’轮的推理(K远大于K’)。
在邻接矩阵中,保留TopK通信边,与原有向无环图相比,信息进一步高质量压缩。
实验
性能表现:使用5个GPT-4作为agent,与之前的baseline相比效果较好。
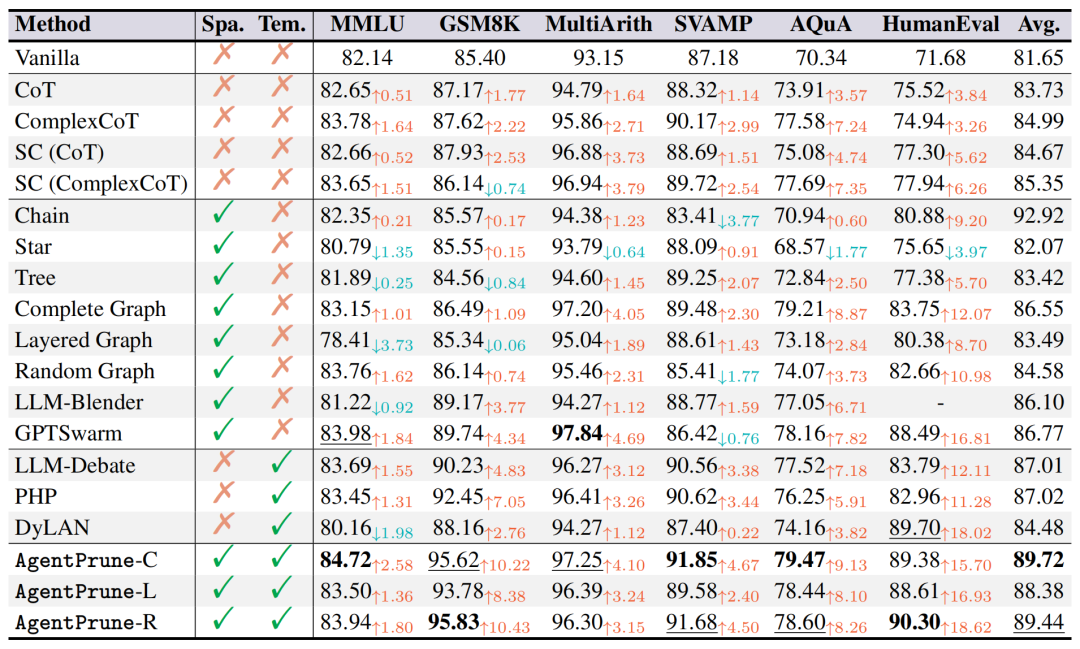
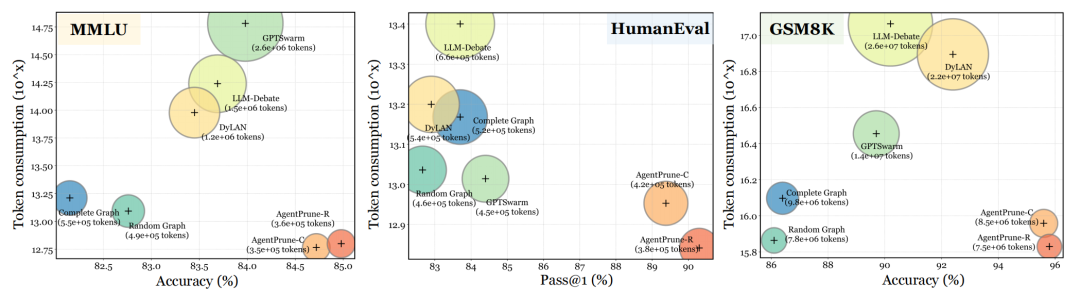
Token花费:花费的token更少,并且与其他已有的MA系统结合能降低token数。
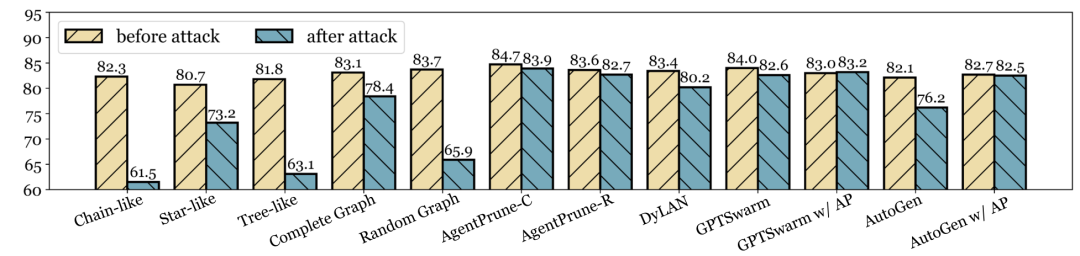
对抗攻击:
通过在六个基准测试上的实验结果,证明了AgentPrune的有效性:
在较低的成本下,能够与现有最先进的拓扑达到相当的效果。
在现有多智能体框架中无缝集成,实现28.1% ~ 72.8%的token减少。
成功防御两种类型的智能体对抗攻击,并带来3.5% ~ 10.8%的性能提升。
一些个人思考
作为第一个提出对Agent通信拓扑剪枝提高性能、效率、鲁棒性(对抗攻击)的MA系统,重点在定义MA系统通信机制中的冗余和观察到存在冗余的现象,消除冗余的方法还是简单和容易理解的,也给后续工作了一些启发和优化空间。
泛化性:关于“一次性剪枝”操作以及剪枝标准,还是可以继续优化,增强泛化性。例如在GSM8K,MMLU等场景“一次性剪枝”需要进行的训练轮次分别为8,47,分别占总测试数据的7%和18%,如果可以自适应调整的选择“一次性剪枝”的轮次,可能会减少很多前期的参数调整。以及对不同Agent数量组成的MA系统的自适应调整策略,期待后续工作可以进一步优化。
效率优化:剪枝操作之外,可以参考之前针对SC(自一致性)的减少Token花费的相关策略,以及与cache share等工作的进一步结合,优化需要很多轮次的更复杂的场景中的推理策略。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 673
673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









