






过去的大语言模型(如ChatGPT)像“知识百科”,只能一问一答。但如今的AI智能体(LLM-based agents)已经进阶为“行动派”——它们能规划任务、调用工具(比如订机票)、记住对话历史,甚至自我纠错。
但问题来了:如何判断这些AI助手是否靠谱?
就像人类需要考试,Agent也需要一套科学的评估体系。本文首次系统性梳理了Agent的“考场规则”,覆盖从基础能力到专业场景的全面测评。
论文:Survey on Evaluation of LLM-based Agents
链接:https://arxiv.org/pdf/2503.16416
四大核心能力
规划与推理
agent能否像人类一样,把复杂任务拆解成小步骤?比如解决数学题时,先列公式再计算。
经典考题:数学题(GSM8K)、多步骤问答(HotpotQA)
弱点暴露:当前agent擅长短期规划,但长期战略(如策划一周旅行)仍吃力。
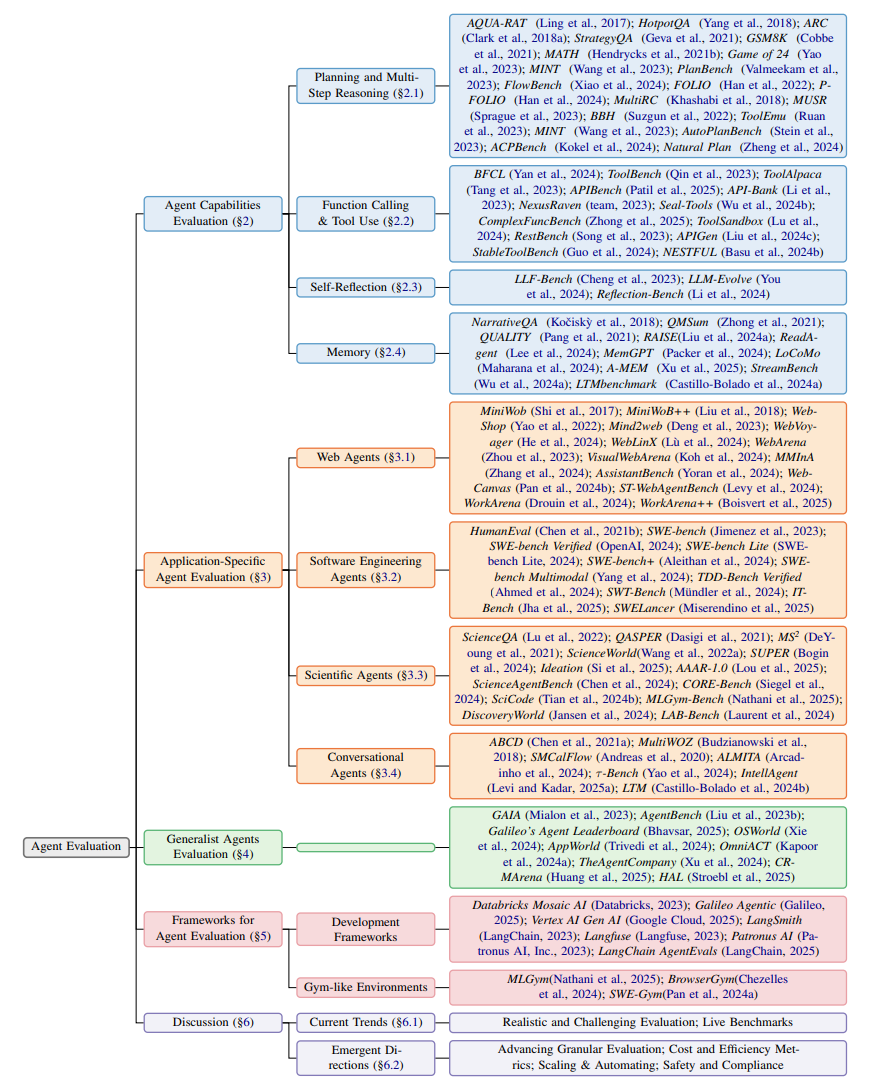
工具调用
AI需要调用外部工具(如搜索引擎、计算器)完成任务。评估重点包括:
精准匹配:用户说“订明天北京的酒店”,AI能否正确调用酒店预订API?
复杂场景:参数不明确时(如“找人均200元的餐厅”),AI能否推理出隐含条件?
案例:伯克利函数调用排行榜(BFCL)像“工具使用月考”,持续更新难度。
自我反思
AI犯错后能否通过反馈修正答案?例如:
写代码报错时,能否根据错误提示重新生成正确代码?
当前评测大多依赖粗粒度指标(最终答案是否正确),未来需细化到每一步的反思质量。
记忆系统
AI如何记住用户偏好或历史对话?
短期记忆:实时处理当前对话(如客服记录用户需求)。
长期记忆:跨会话保留关键信息(如记住用户是素食主义者)。
研究发现:某些短上下文模型+记忆系统,性能可媲美长上下文模型!
应用场景评估
网页操作
早期测试在简化环境中进行(如点击按钮),现在转向真实网页动态交互:
WebArena:模拟真实网站界面,要求AI完成购物、信息查询等任务。
致命弱点:安全性(如避免误点广告)和政策合规性仍缺乏评测。
编程助手:GitHub真实问题大考验
编程AI的评测从“刷算法题”转向解决真实GitHub问题:
SWE-bench:从GitHub抓取真实Issue,要求AI修复Bug或添加功能。
残酷现实:顶尖AI的通过率仅2%,复杂任务(如跨文件修改)仍是难关。

Agent能否替代科学家?
评测覆盖科研全流程:
创意生成(提出新研究假设)
实验设计(设计可执行的方案)
论文评审(生成同行评议反馈)
扎心结论:AI在单任务表现尚可,但跨任务切换(如边写代码边查文献)容易翻车。
对话机器人:如何让客服agent不翻车
对话AI需同时满足用户需求和公司政策:
τ-Bench:模拟航空客服场景,测试AI能否正确调用数据库并合规应答。
用户模拟器:用另一个AI扮演“刁钻用户”,考验智能体的应变能力。
通用智能体评估
GAIA基准:466道人类设计的现实问题,涵盖推理、多模态理解、网页导航等。
虚拟职场测试:
AgentCompany:模拟软件公司,AI需写代码、开会、协调同事。
SWE-Lancer:让AI接“自由职业编程任务”,按完成度赚取虚拟报酬。
结果:AI在简单任务上表现尚可,但复杂项目(如连续工作一周)漏洞百出。
评估框架
主流框架(如LangSmith、Google Vertex AI)提供三大功能:
实时监控:记录AI每一步操作(如调用哪些工具)。
多维度评分:
最终答案正确性
步骤合理性(如是否绕远路)
成本效率(耗时、API调用费用)
人工介入:允许人类审核争议结果。
未来三大挑战与机遇
从“做题家”到实战专家
当前评测仍依赖静态题库,未来需动态更新(如模拟突发网络故障)。
安全与成本:不能只看成绩单
忽视安全性的AI可能泄露隐私或执行危险操作。
成本指标(如耗电量)将影响商业落地。
自动化的终极目标
用AI自动生成测试题(如让GPT-4出题考GPT-5)。
实现全天候、低成本的“AI自我进化循环”。
最后,“评估不是为了淘汰AI,而是为了让它更懂人类。”
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 1473
1473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









