







概述
机器学习是一种人工智能技术,使计算机能够通过经验自动改进性能,主要分为监督学习(使用带标签的数据进行训练)、无监督学习(寻找无标签数据中的模式)、半监督学习(结合带标签和无标签数据)和强化学习(通过与环境交互学习)。它广泛应用于金融(信用评分)、医疗(疾病预测)、自动驾驶(路径规划)和自然语言处理(机器翻译)等领域,关键概念包括特征、模型、过拟合和交叉验证。本文我们使用ydf方法进行分别介绍。
pip install ydf -U分类(classification)
分类是预测有限可能值集合中的分类值(如枚举、类型或类)的任务。例如,从可能的颜色集合(红色、蓝色、绿色)中预测颜色是一个分类任务。分类模型的输出是可能类别的概率分布。预测的类别是概率最高的类别。当只有两个类别时,我们称之为二元分类。在这种情况下,模型只返回一个概率。分类标签可以是字符串、整数或布尔值。
训练分类模型
模型的任务(例如,分类、回归)由 task 学习者参数确定。此参数的默认值为 ydf.Task.CLASSIFICATION ,这意味着默认情况下,YDF 训练分类模型。
# 导入必要的库
import ydf # 导入 Yggdrasil 决策森林库
import pandas as pd # 导入 Pandas 库,用于加载小型数据集
# 下载分类数据集并将其加载为 Pandas DataFrame
ds_path = "https://raw.githubusercontent.com/google/yggdrasil-decision-forests/main/yggdrasil_decision_forests/test_data/dataset" # 数据集的路径
train_ds = pd.read_csv(f"{ds_path}/adult_train.csv") # 读取训练数据集
test_ds = pd.read_csv(f"{ds_path}/adult_test.csv") # 读取测试数据集
# 打印前5个训练样本
train_ds.head(5) # 显示训练数据集的前5行
#代码注释
#导入库:首先导入了 ydf 库(用于决策森林模型)和 pandas 库(用于数据处理)。
#下载数据集:指定了数据集的路径,并使用 pd.read_csv 方法从该路径下载并加载训练和测试数据集。
#显示数据:最后,使用 head(5) 方法显示训练数据集中前五个样本,以便快速查看数据的结构和内容。打印的结果
age 年龄 |
workclass 工作类别 | fnlwgt | education 教育 | education_num 教育程度 | marital_status 婚姻状况 | occupation 职业 | relationship 关系 | race 比赛 | sex 性别 | capital_gain 资本利得 | capital_loss 资本损失 | hours_per_week 每周小时数 | native_country 国籍 | income 收入 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 44 | Private 私人 | 228057 | 7th-8th 7-8 月 | 4 | Married-civ-spouse 已婚-公民配偶 | Machine-op-inspct 机械操作检查员 | Wife 妻子 | White 白色 | Female 女性 | 0 | 0 | 40 | Dominican-Republic 多米尼加共和国 | <=50K ≤50K |
| 1 | 20 | Private 私人 | 299047 | Some-college 一些大学 | 10 | Never-married 从未结婚 | Other-service 其他服务 | Not-in-family 非家族成员 | White 白色 | Female 女性 | 0 | 0 | 20 | United-States 美国 | <=50K ≤50K |
| 2 | 40 | Private 私人 | 342164 | HS-grad 高中毕业生 | 9 | Separated 分离的 | Adm-clerical 行政文员 | Unmarried 未婚 | White 白色 | Female 女性 | 0 | 0 | 37 | United-States 美国 | <=50K ≤50K |
| 3 | 30 | Private 私人 | 361742 | Some-college 大专 | 10 | Married-civ-spouse 已婚,民用配偶 | Exec-managerial 执行经理 | Husband 丈夫 | White 白色 | Male 男 | 0 | 0 | 50 | United-States 美国 | <=50K ≤50K |
| 4 | 67 | Self-emp-inc 自我激励-公司 | 171564 | HS-grad 高中毕业 | 9 | Married-civ-spouse 已婚-民事配偶 | Prof-specialty 专业特长 | Wife 妻子 | White 白色 | Female 女性 | 20051 | 0 | 30 | England 英格兰 | >50K |
# 标签列是
train_ds["income"] 22792 rows × 1 columns
22792 行 × 1 列
可以训练一个分类模型:
- 创建模型:使用
ydf.RandomForestLearner创建一个随机森林学习器。label="income":指定要预测的目标标签为 "income",即数据集中与收入相关的列。task=ydf.Task.CLASSIFICATION:指定任务类型为分类(这是默认值,因此可以省略)。
- 训练模型:调用
.train(train_ds)方法,使用之前加载的训练数据集train_ds来训练模型。训练完成后,模型将被保存在变量model中。
# 注意:ydf.Task.CLASSIFICATION 是 "task" 的默认值
model = ydf.RandomForestLearner(label="income", # 指定目标标签为 "income"
task=ydf.Task.CLASSIFICATION).train(train_ds) # 创建随机森林学习器并训练模型
evaluation = model.evaluate(test_ds)
evaluation
#评估指标可以直接在评估对象中访问。
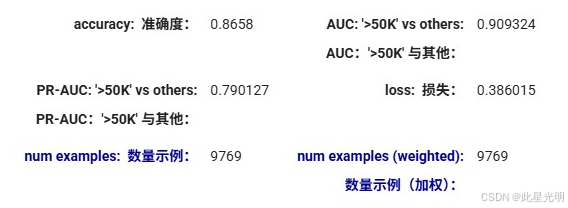
print(evaluation.accuracy)
#精度:0.8657999795270754Train model on 22792 examples Model trained in 0:00:01.808830
分类模型使用准确率、混淆矩阵、ROC-AUC 和 PR-AUC 进行评估。您可以使用 ROC 和 PR 图进行丰富的评估。
| Label \ Pred 标签 \ 预测 | <=50K ≤50K | >50K >50K |
|---|---|---|
| <=50K ≤50K | 6962 | 861 |
| >50K >50K | 450 | 1496 |
分类模型评估
Accuracy 准确率
最简单的指标。它是预测正确的百分比(与真实值匹配)。
例子:如果一个模型正确地将 90 张图像识别为猫或狗,准确率为 90%。
Confusion Matrix 混淆矩阵
一个显示以下计数情况的表格:
- True Positives (TP): Model correctly predicted positive.
真阳性(TP):模型正确预测为阳性。 - True Negatives (TN): Model correctly predicted negative.
真阴性(TN):模型正确预测为阴性。 - False Positives (FP): Model incorrectly predicted positive (a "false alarm").
假阳性(FP):模型错误地预测为阳性(“误报”)。 - False Negatives (FN): Model incorrectly predicted negative (a "miss").
假阴性(FN):模型错误地预测为负(一个“漏网之鱼”)。
Threshold 阈值
YDF 分类模型为每个类别预测一个概率。阈值决定了将某事物分类为阳性或阴性的截止点。
例子:如果阈值是 0.5,任何高于 0.5 的预测可能会被分类为“垃圾邮件”,任何低于的则被分类为“非垃圾邮件”。
ROC Curve (Receiver Operating Characteristic Curve)
受试者工作特征曲线(ROC 曲线)
在各种阈值下,绘制真实正例率(TPR)与假正例率(FPR)的图表。
- TPR (Sensitivity or Recall): TP / (TP + FN) - How many of the actual positives did the model catch?
TPR(灵敏度或召回率):TP / (TP + FN) - 模型捕捉了多少实际正例? - FPR: FP / (FP + TN) - How many negatives were incorrectly classified as positives?
FPR:FP / (FP + TN) - 有多少负例被错误地分类为正例?
解释:一个好的模型具有紧贴右上角的 ROC 曲线(高 TPR,低 FPR)。
AUC (Area Under the ROC Curve)
AUC(ROC 曲线下的面积)
一个总结 ROC 曲线整体表现的单一数值。AUC 比准确率更稳定。多分类模型评估一个类别与其他所有类别。
解释:范围从 0 到 1。完美模型的 AUC 为 1,而随机模型的 AUC 为 0.5。越高越好。
Precision-Recall Curve 精确率-召回率曲线
在各种阈值下,绘制精确率与召回率关系的图表。
- Precision: TP / (TP + FP) - Out of all the predictions the model labeled as positive, how many were actually positive?
精确率:TP / (TP + FP) - 在所有模型标记为正例的预测中,有多少实际上是正例? - Recall (same as TPR): TP / (TP + FN) - Out of all the actual positive cases, how many did the model correctly identify?
召回率(与 TPR 相同):TP / (TP + FN) - 在所有实际正例中,模型正确识别了多少?
解释:一个好的模型具有曲线保持较高的特点(高精确度和高召回率)。在处理不平衡数据集(例如,当一个类别远比另一个类别稀有时)时特别有用。
PR-AUC (Area Under the Precision-Recall Curve)
PR-AUC(精确率-召回率曲线下的面积)
与 AUC 类似,但针对精确率-召回率曲线。用一个数字总结性能。多类别分类模型评估一个类别与其他所有类别。数值越高越好。
Threshold / Accuracy Curve
阈值/准确率曲线
一张图表,展示了随着分类阈值的改变,模型准确率的变化情况。
Threshold / Volume Curve 阈值/体积曲线
一张图表,展示了随着阈值的改变,被分类为正例的数据点数量的变化。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3435
3435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











