







现在,我们已经了解了强化学习工作流,在这篇文章中,我想展示如何利用该工作流,设置RL智能体使双足机器人行走。我们将使用来自MATLAB和Simulink Robotics Arena的行走机器人示例,你可以在GitHub上找到(mathworks/msra-walking-robot: Example files for MATLAB and Simulink Robotics Arena walking robot videos. (github.com)),也可以通过后面链接找到该资源(基于MATLAB和SimulinkRoboticsArena的行走机器人示例-机器学习文档类资源-CSDN文库)。本例附带一个环境模型,你可以在其中调整训练参数、训练智能体并显示结果。
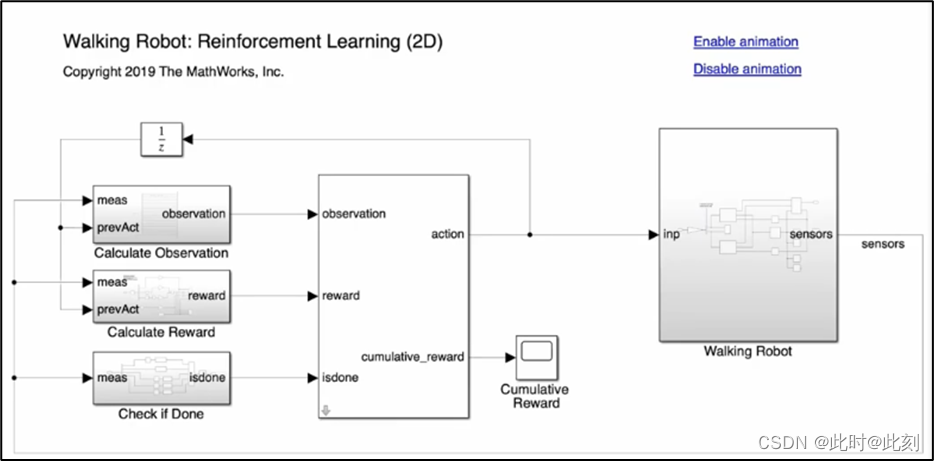
在本节,我们还将介绍如何修改此示例,使它看起来和设置传统控制问题的过程更相似,然后说明此设计的一些局限性。所以,我希望你能坚持下来, 因为我认为,这将帮助你理解如何在典型的控制应用程序中使用强化学习。
让我们先快速概述一下这个问题。高级目标是让两条腿的机器人走路,以一种与人类相似的行走方式。作为设计师,我们的工作是确定正确移动机器人腿和躯干的动作。我们可以控制每个关节的马达扭矩指令,包括左脚踝和右脚踝,左膝盖和右膝盖,左髋关节和右髋关节。所以,在任意时刻,我们需要发送共六个不同的扭矩指令。机器人的躯干和腿,以及它所处的世界,构成环境。来自环境的观测值,基于传感器的类型和位置以及软件生成的任何其他数据。在这个例子中,我们使用31个不同的观测值。包括躯干位置的Y和Z轴坐标值,沿X、Y和Z方向的躯干速度,及躯干旋转角度和角速度,还有6个关节的角度和角速度,以及脚和地面之间的接触力。这些是感知到的观测值。我们还会反馈上一个时间步中输出的6个动作指令,这些动作存储在软件的缓存区中。
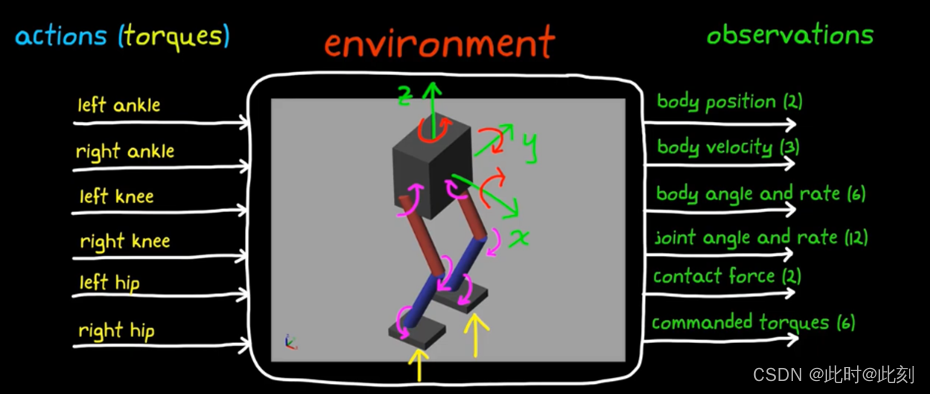
总之,我们的控制系统会接收这31个观测值,并必须连续不断地计算6个马达扭矩值。所以你了解到,即使对于这个非常简单的系统,逻辑也非常复杂。
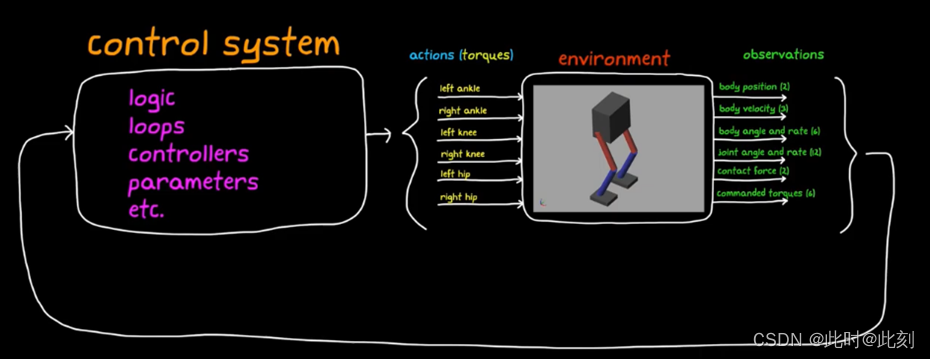
正如我在之前的文章中提到的,不同于用传统控制理论工具,来设计逻辑、循环、控制器、参数以及所有这些东西,我们可以用一个强化学习智能体,端到端地来取代整个庞大的函数,它使用一个执行器网络将这31个观测值映射到6个动作,使用另一个评价器网络,让训练执行器更有效率。
正如我们所了解的那样,训练过程需要奖励函数,告诉智能体如何行动,以便它从自己的动作中学习。我想推断奖励函数中应该包含什么,通过分析行走机器人所需的重要条件。如果你不知道创建奖励函数应该从哪里入手,可以考虑这种方法。现在,我将展示通过构建这个函数得到的训练结果,这样你就可以看到这些更改将如何影响结果。
好了,让我们看下奖励。从哪里开始呢?我们显然希望机器人的躯干向前移动,否则它只能站在那里。但是,我们不选择距离,而是奖励机器人的前进速度,这样一来,机器人将走得更快而不是更慢。在用这个奖励进行训练后,我们可以看到机器人向前俯冲,在开始时获得了较快的爆发速度,然后摔倒,并没有真正的进展。在这个奖励设定下,智能体可能最终会想出如何让机器人走得更远,但这需要很长时间才能收敛,而无法取得很大进展。所以让我们考虑一下,可以通过添加些什么,来帮助机器人训练。
我们可以惩罚机器人的摔倒,这样向前俯冲就没有那么吸引人了。因此,如果机器人站立的时间越长,或者在模拟结束之前经过了更多个采样周期,那么智能体应该得到更多奖励。这个奖励函数的效果是:它一开始有点跳跃,最后又摔倒了。也许如果我让这个智能体训练的时间长一点,我就能拥有一个像青蛙一样到处蹦蹦跳跳的机器人。这很酷,但那不是我想要的。
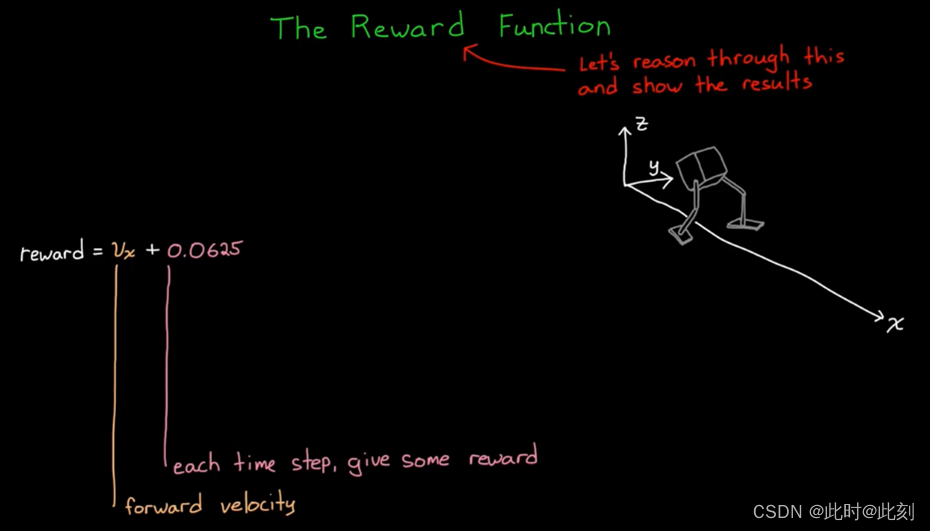
仅仅让机器人向前移动而不摔倒是不够的,我们希望它看起来像是在走路,而不是跳跃或蹲着走路。因此,为了解决这个问题,我们也应该给予其奖励,让机器人的躯干能够尽量保持站立的高度。

上面这个奖励函数的效果看起来好多了,但是解决方案看起来并不自然。它偶尔会停下并来来回回地抖动它的腿,大多数时候它会像僵尸一样拖着右腿,把所有的驱动力都放在左腿上。这种方式并不理想,如果我们将作动器的磨损考虑在内,或者运行机器人所需要的能量。我们希望两条腿能做同样的工作,不要做大量的抖动动作而过度使用作动器。为了解决这个问题,我们可以奖励智能体,使其降低作动器的使用成本。这应该可以减少额外抖动,平衡使用成本,使每条腿都能分担重量。让我们看看这个训练好的智能体。

好了,我们快要成功了,这看起来很不错。现在我们还有最后一个问题: 我们想让机器人沿着一条直线移动,而不是像上面这样,向左偏或向右偏,所以我们应该奖励它,使其靠近x轴。
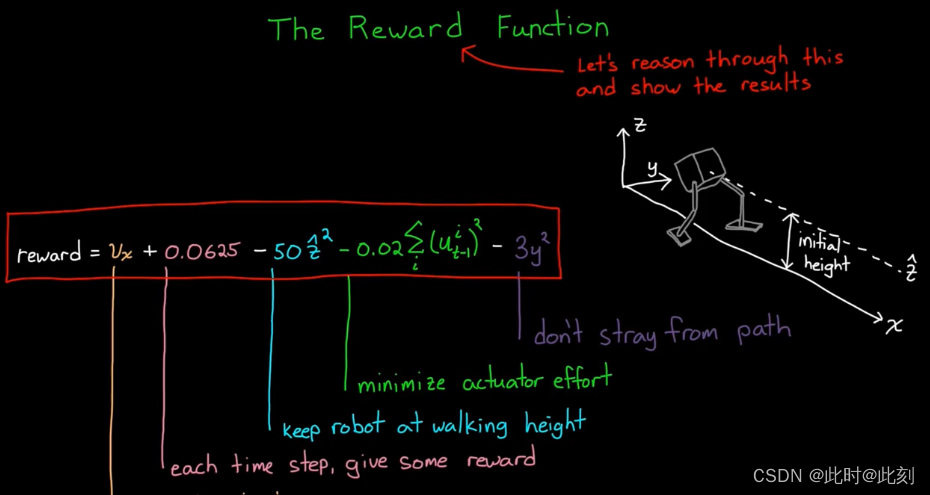
这是我们最后的奖励项,训练需要大约3500次仿真。因此,如果我们在模型中设置了这一项,并在多核计算机、GPU或计算机集群上进行仿真,那么在经过几个小时的训练后,我们就会有一个解决方案, 一个像人类一样走直线的机器人。

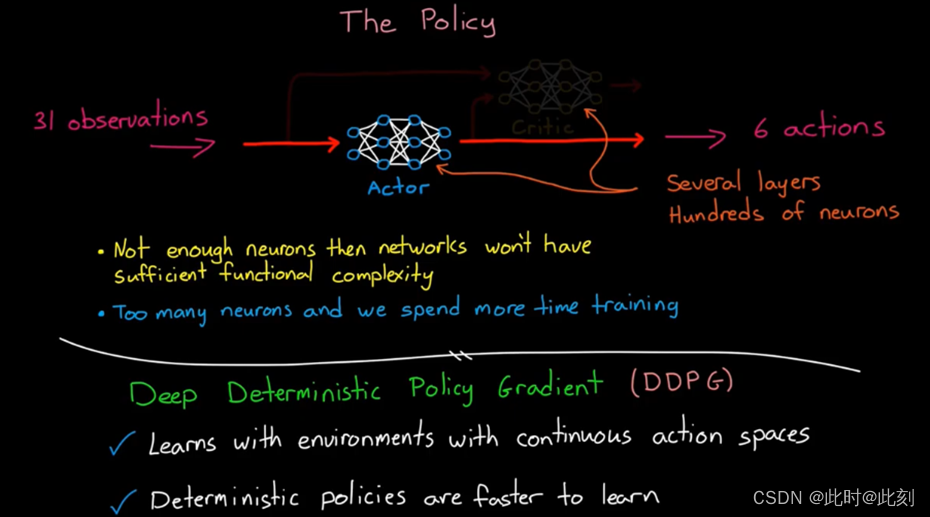
设置好奖励函数后,让我们来看看策略。我说过,策略是一个执行器神经网络,相伴其左右的是一个评价器神经网络。每一个网络都有几个隐藏的层,每一层都有数百个神经元,所以需要进行大量的计算。如果我们没有足够的神经元,那么,这个网络将永远无法拟合这个非线性环境所需要的高维函数,将31个观察值映射到6个动作。另一方面,如果神经元过多,我们将花费更多的时间训练得到一个过拟合的逻辑。此外,网络的结构在功能复杂性方面非常重要。这包括网络层的数量,各层是如何连接的,以及每一层神经元的数量等等。因此,需要一些经验和知识来找到最佳平衡点,使训练成为可能并有效。幸运的是,正如我们所知,我们不需要手动求解网络中成百上千个权重和偏置,我们让训练算法来做这些。在本例中,我们使用一种的执行器-评价器训练算法,称为深度确定性策略梯度(DDPG)。原因是,这个算法可以在具有连续动作空间的环境中学习,就像我们可以把连续范围的扭矩指令作用在马达上一样。而且,由于它估计的是确定性策略,所以学习起来要比随机策略快得多。
我知道这一切听起来相当复杂和抽象,但对我来说最酷的事情是,大部分的复杂性都出现在策略的训练中。一旦我们有了一个完全训练好的智能体,我们只需将执行器网络部署到目标硬件。记住,执行器是将观测值映射到动作的函数,它决定要做什么,这是策略。评价器和学习算法,只是用来帮助确定执行器中的参数。
对此,你可能会有疑问。当然,我们可以用RL让机器人走直线,但是,这个策略不会只做这一件事吧? 例如,如果我部署此策略,并启动我的机器人,它就立即开始走直线,并且一直如此。

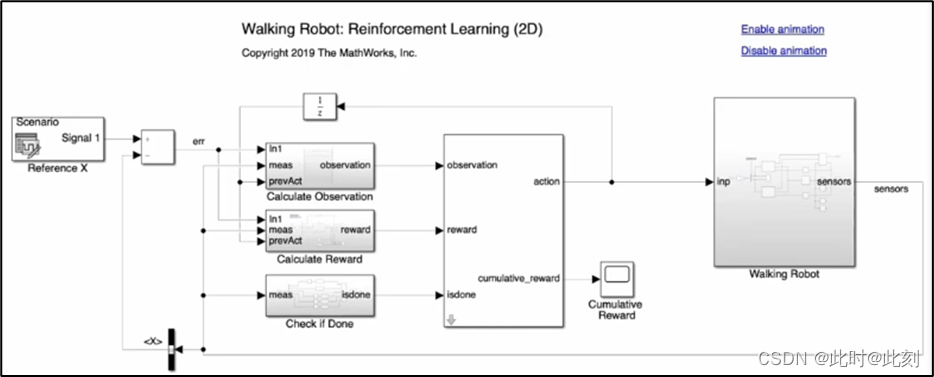
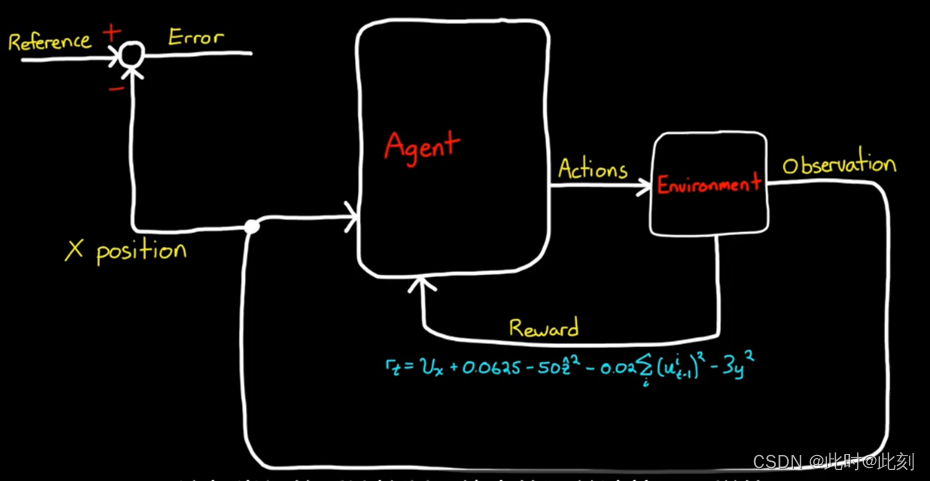
那么,我该如何学习一种策略,允许我向机器人发送指令,让它走到我想让它去的地方? 好吧,让我们思考一下。现在,这就是我们的系统(如下图所示)。我们有可生成观测值和奖励的环境,然后我们有可执行动作的智能体。我们没有办法将任何外部指令注入这个系统,我们的智能体也没有办法作出响应,即使存在指令。因此,我们需要在智能体之外编写一些额外的逻辑,接收参考信号并计算误差项。误差是从环境中得到的当前X位置与参考值之间的差。这与常规的反馈控制系统中的误差计算是一样的。
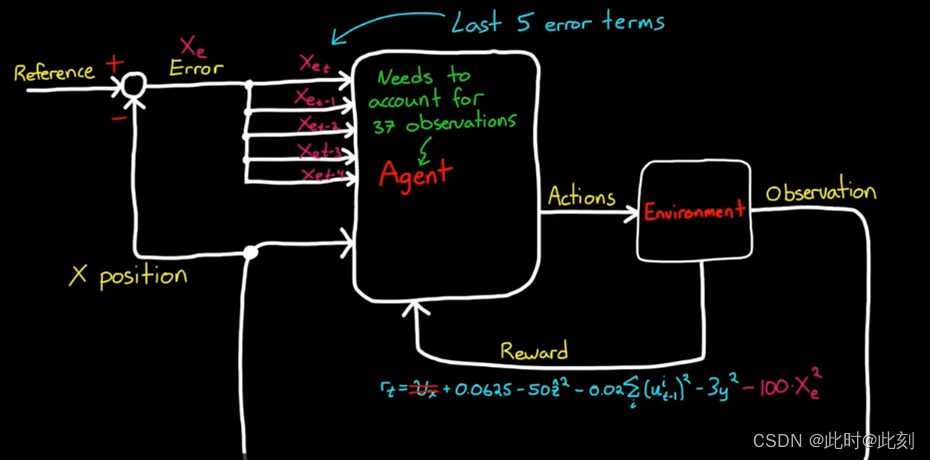
现在,与其奖励智能体在X方向的高速度,不如奖励它的低误差。这将激励机器人朝着指示的X参考值走去,并保持在该参考值上。对于观测值,我们需要为智能体提供一种查看误差项的方法,以便它据此制定策略。考虑到,获取误差变化率和其他更高阶的导数,也许能帮助我们的智能体,所以我将输入前五个采样周期的误差。这将允许策略在必要时生成导数。最终的策略是:如果误差是正的,则以指定的速率前进,由于我们现在获得对智能体的36个观测值,我们需要调整执行器网络来处理额外的输入。
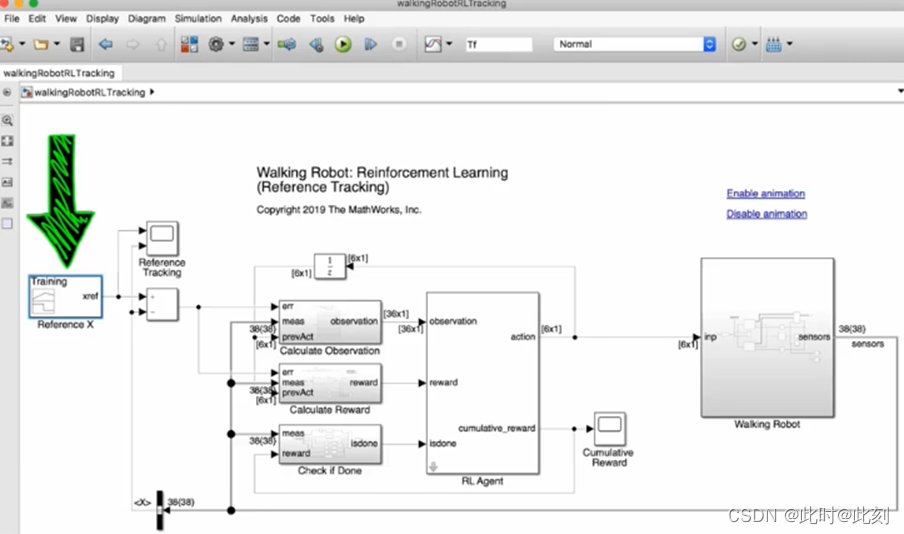
我已经用新的误差项更新了Simulink中的默认模型,并将其输入到观测值模块和奖励模块中。
我已经用这个特定的曲线,对这个智能体进行了几千个周期的训练,所以它应该很擅长跟踪这个曲线。但人们希望,经过训练的策略将足够鲁棒,能够跟踪其它具有类似速度和加速度的曲线。
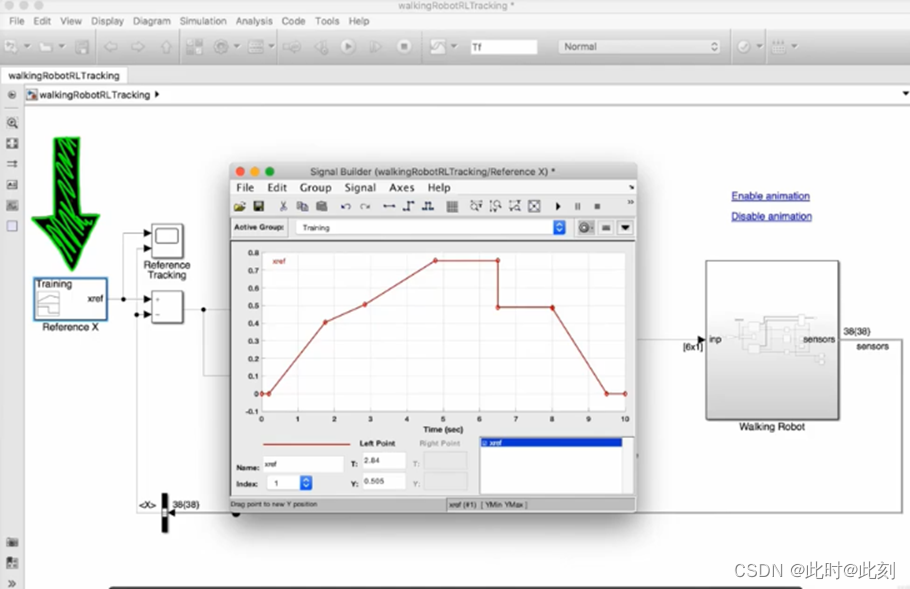
所以让我们试一试。我让它向前走,暂停一会儿,然后向后走。
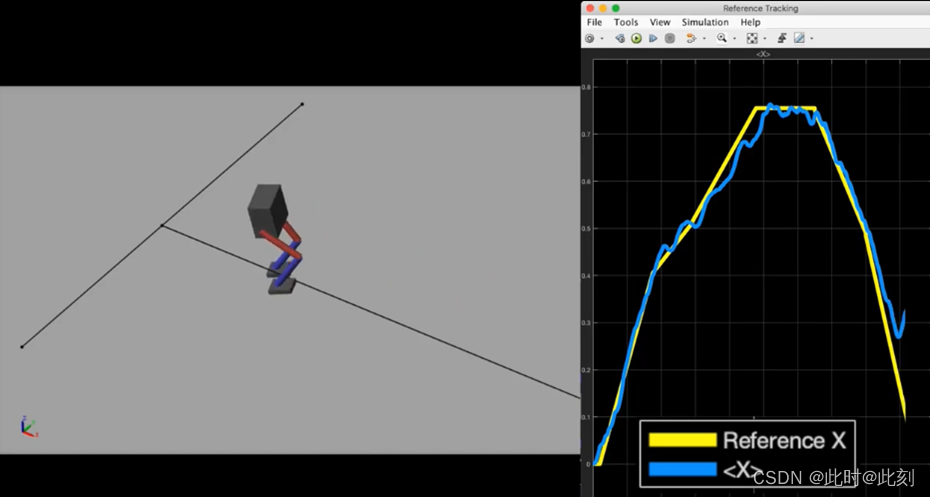
当它倒着走的时候看起来有点滑稽,但总的来说是一个很好的尝试。通过一些奖励调整,或者花更多时间进行训练,可能会得到更好的效果。所以,通过这种方式,你可以开始了解如何使用RL智能体来替换控制系统的一部分。不同于学习单个行为的函数,我们可以提取高级的参考信号,并让智能体消除误差,这样我们就可以保留发送指令的能力。我们还可以从智能体中移除低级功能。例如,不将6个关节中各关节处的扭矩值选定为动作,智能体可以学习应该将脚放在地面上的哪个位置。所以,动作的定义是把左脚放在躯干坐标系的某个位置。这个动作可以作为底层传统控制系统的参考指令,用于驱动关节马达。你知道,可能前馈一个扭矩指令,根据你对系统动态特性的了解,并反馈一些信号以保证性能和稳定性。这是有益的,因为我们可以使用特定领域的知识来解决简单的问题,这将为我们赋予对设计的洞察力和控制权,然后我们可以将强化学习保留用于更为棘手的问题。
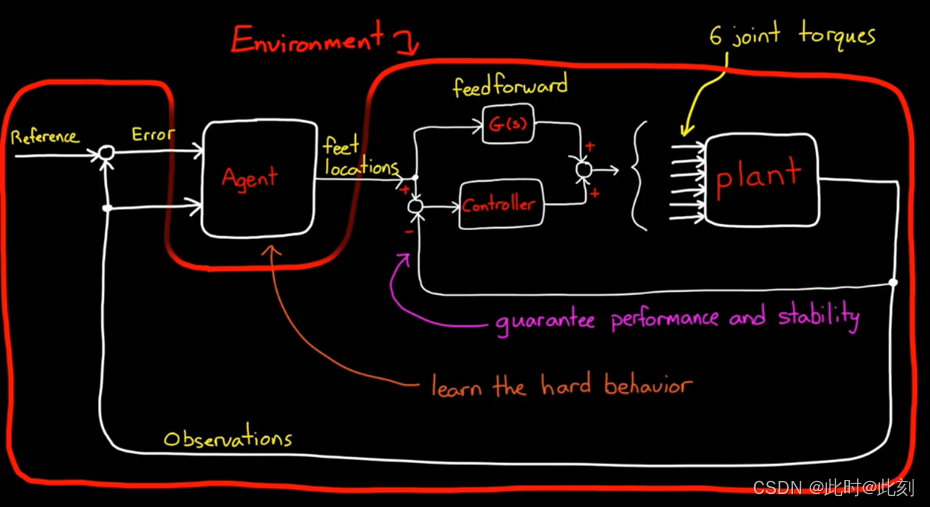
关于我们的最终行走解决方案需要注意的是,它实际上只对自己的状态具有鲁棒性。你知道,它可以四处走动而不摔倒,这很好,但只是在一个完全平坦、没有特殊地貌的平地上。
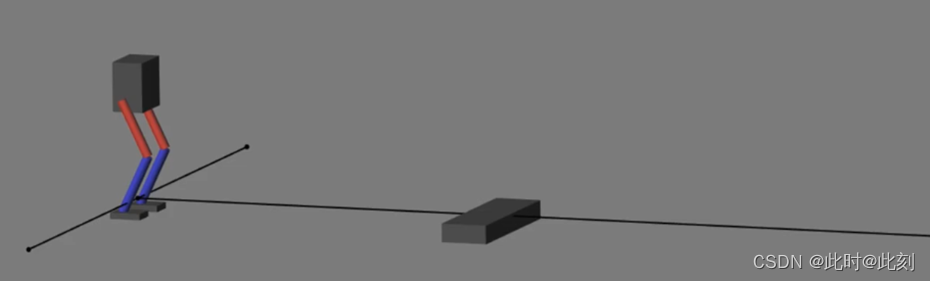
它没有考虑机器人以外的世界中的任何部分,所以它实际上是一个相当脆弱的设计。例如,让我们看看,如果我们在机器人的路径上设置一个障碍物会发生什么。嗯,这是意料之中的。问题在于,我们没有给智能体任何识别环境状态的方法,除了机器人自身的运动状态。无法感知这些障碍,因此无法避开它们。
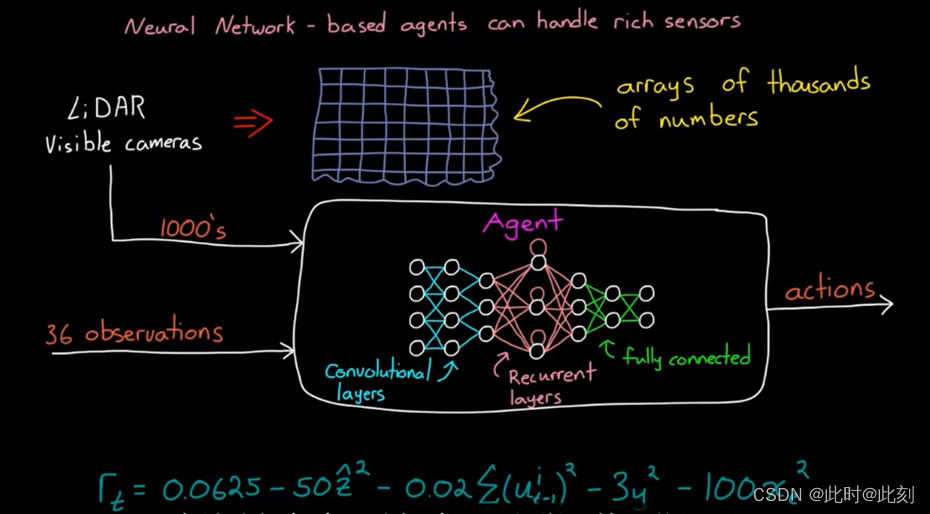
但事情是这样的,基于神经网络的智能体的优点在于,它们可以处理传感器采集的丰富信息。例如,激光雷达和可见光摄像头,它们不会产生像角度这样的单一测量值,而是返回数值数组,代表数千个距离值或不同光强度的像素点。因此,我们可以在机器人上安装一个见可光摄像头和一个激光雷达传感器,并将1000个左右的新值作为附加观测值,输入到我们的智能体中。你可以想象,这个函数的复杂性需要如何增长,随着我们的观测值从36个增加到数千个。我们可能会发现,一个简单的全连接网络并不理想,因此我们可能会添加一些额外的层,以包含专门的逻辑,例如,可最小化连接的卷积网络,或可增加内存的递归网络。这些网络层更适合处理大型图像数据和高动态环境。不过,我们可能不需要改变奖励函数,以让机器人避开这些障碍物,智能体仍然可以学习到,虽然偏离路径会获得较低的奖励,但这可以让机器人继续行走而不会摔倒,从而获得更多的总奖励。
在这篇文章中,我解决了强化学习的一些问题,并展示了如何修正这个问题,即通过将传统控制设计与强化学习的优点相结合。在下一篇文章中,我们将进一步扩展这一点,并将讨论强化学习的其他缺点,以及我们可以做些什么来弥补这些缺点。
文章内容的视频链接如下:


















 645
645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











