









学习教程来自:【技术美术百人计划】图形 3.7 移动端TB(D)R架构基础
移动端GPU的TB(D)R架构
1. 当前移动端GPU概况

1.1 移动端和桌面端功耗对比
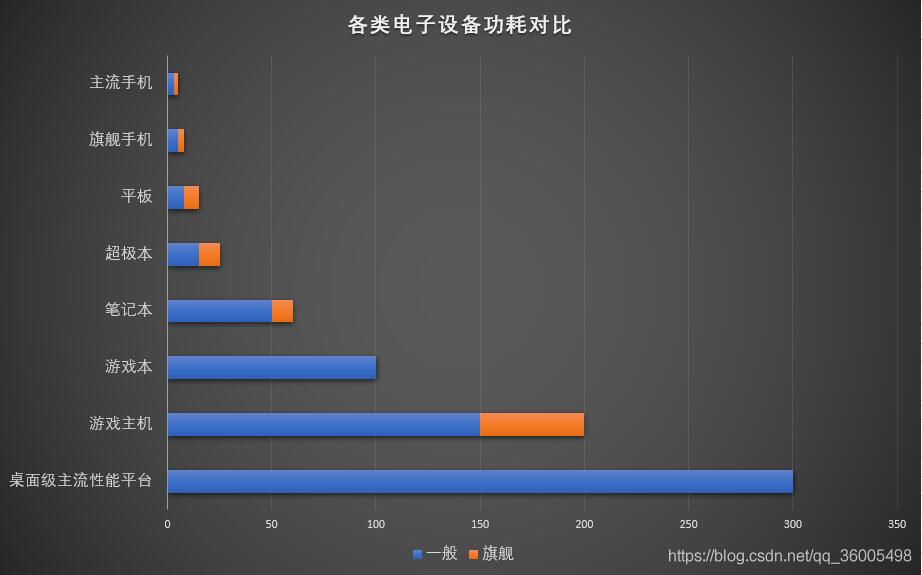
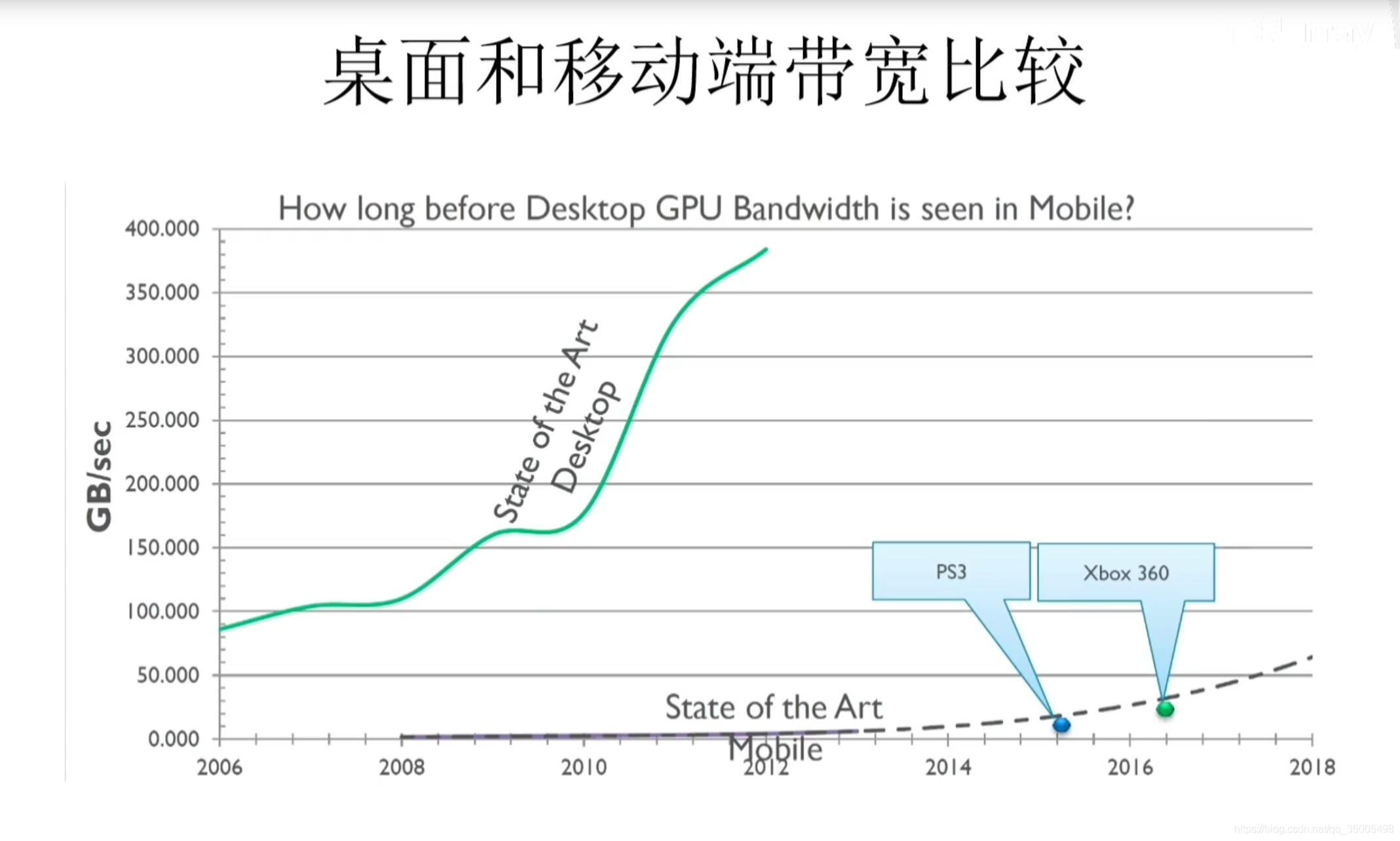
1.2 移动端和桌面端带宽对比
2. 名词解释
SoC(System on Chip):芯片。把CPU GPU 内存 通信基带 GPS模块等整合在一起的芯片
System Memory:手机内存。CPU和GPU共用的一块片内LPDDR物理内存,一般有几个G
On-chip Memory:缓存。CPU和GPU的高速SRAM的Cache缓存,一般几百K到几M,比内存快几倍到几十倍,他们都共享内存地址空间(桌面端是分开的)。在TB(D)R架构下会存储Tile的颜色、深度和模板缓冲
Stall:GPU必须串行的2次计算之间的等待过程
FillRate:ROP运行时钟频率 X ROP个数 X 每个时钟ROP可以处理的像素个数
TB(D)R/Tile-Based(Deferred)Rendering:主流的移动GPU渲染架构,对应PC的IMR(Immediate Mode Rendering)。屏幕被分成16或32的像素块渲染
TBR流程:VS-Defer-RS-PS
TBDS流程:VS-Defer-RS-Defer-PS(见7、8描述2个defer过程)
Defer:延迟,阻塞+批处理待渲染的一帧中的多个数据,然后一起处理
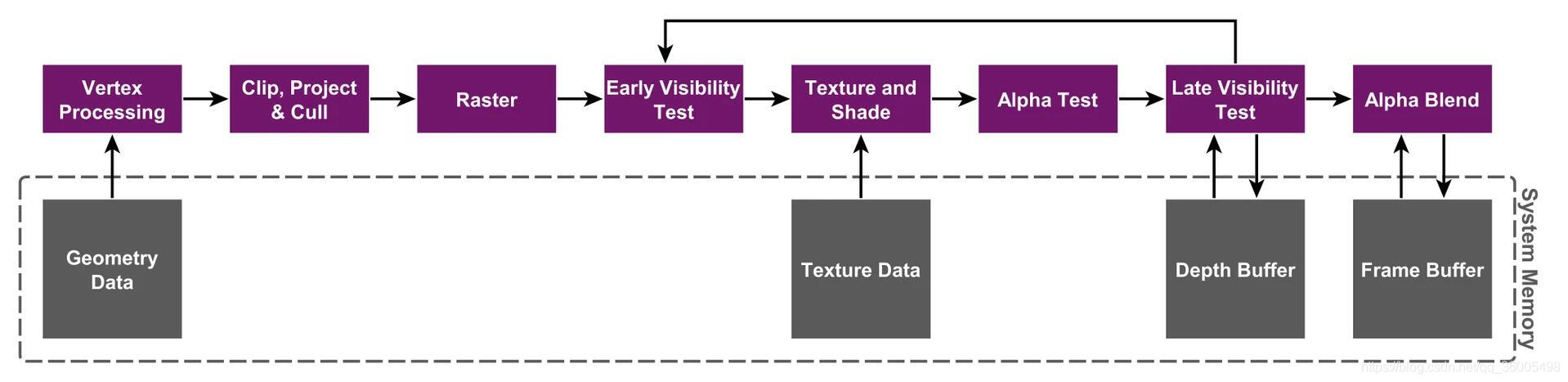
3. 立即渲染(IMR)
4. 基于块元的渲染TB(D)R
- 逐个图元(顶点着色+图元加入TileList):阶段1执行几何相关的处理,生成Primitive List/图元列表,确定Tile上的图元有哪些
- 逐个分块(片元着色等):逐Tile执行光栅化和后续处理,完成后将Frame Buffer从Tile Buffer写回System Memory中
5. TB(D)R的硬件渲染顺序

6. IMR和TB(D)R对比
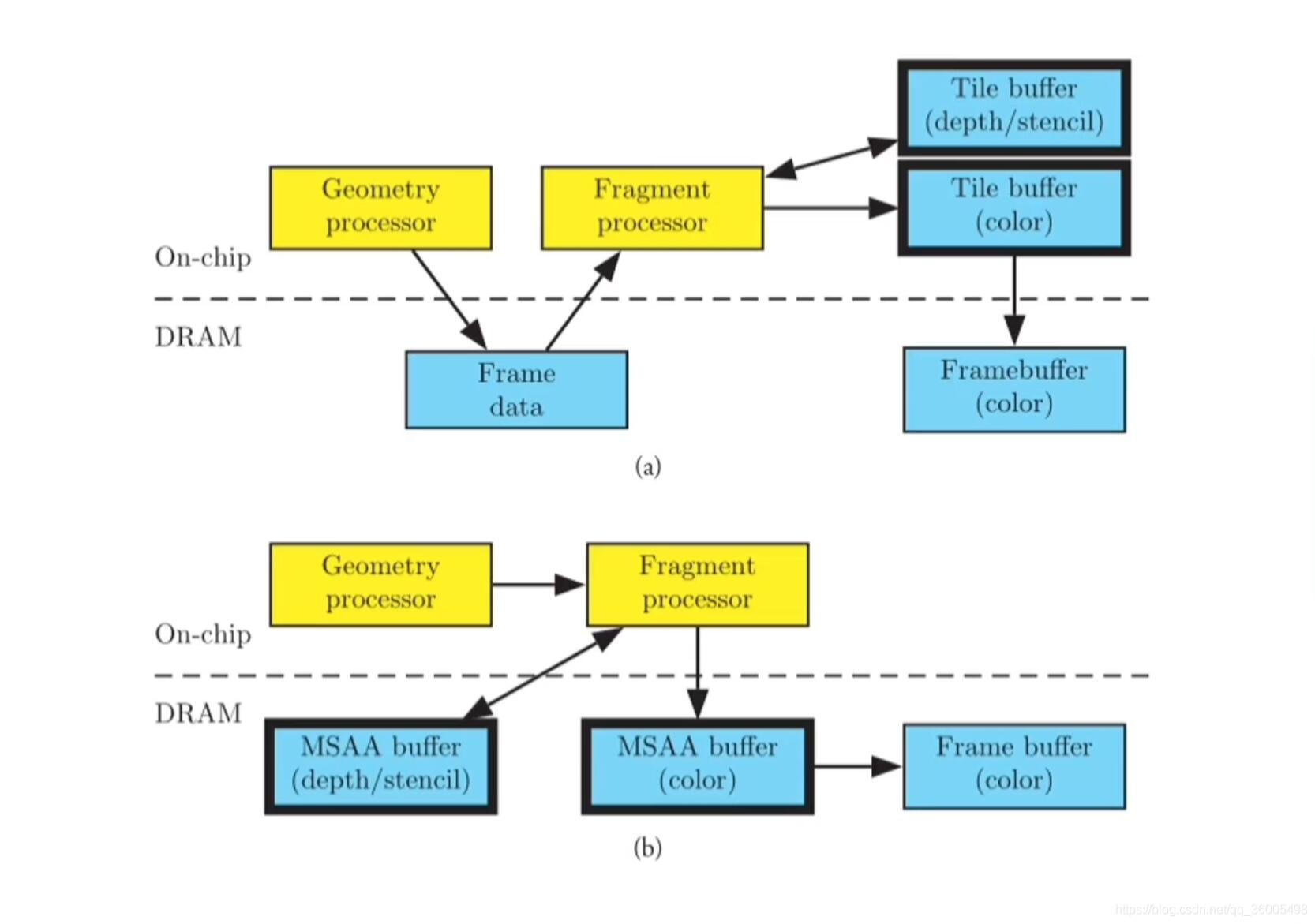
总体上看,TBR降低了功耗和带宽,但帧率上并不比IMR快
TBR的优缺点:
优点:
- TBR有利于消除OverDraw,其中PowerVR的HSR技术和Mali的Forward Pixel Killing技术,都最大限度的减少了被遮挡像素的texturing和shading
- Cached Friendly,在缓存中的读写速度远高于全局内存,以降低render rate的代价,减低了带宽和功耗。
缺点:
- binning过程:在VS过程后输出几何数据到DDR,然后被FS读取,几何数据过多的情况下可能在此处产生性能瓶颈
- 当三角形覆盖在多个tile上时,需要绘制很多次,此时性能低于IMR模式
7. Binning过程(第一个Defer)
过程:图元分配到对应的块元

测试工具:Adreno Profiler
8. 不同GPU的Early-Depth-Test(第二个Defer)
8.1 Qualcomm Adreno的LDR(Android)
硬件的occlusion culling:在正常渲染管线之前,VS生成低精度depth texture,剔除不可见的三角形
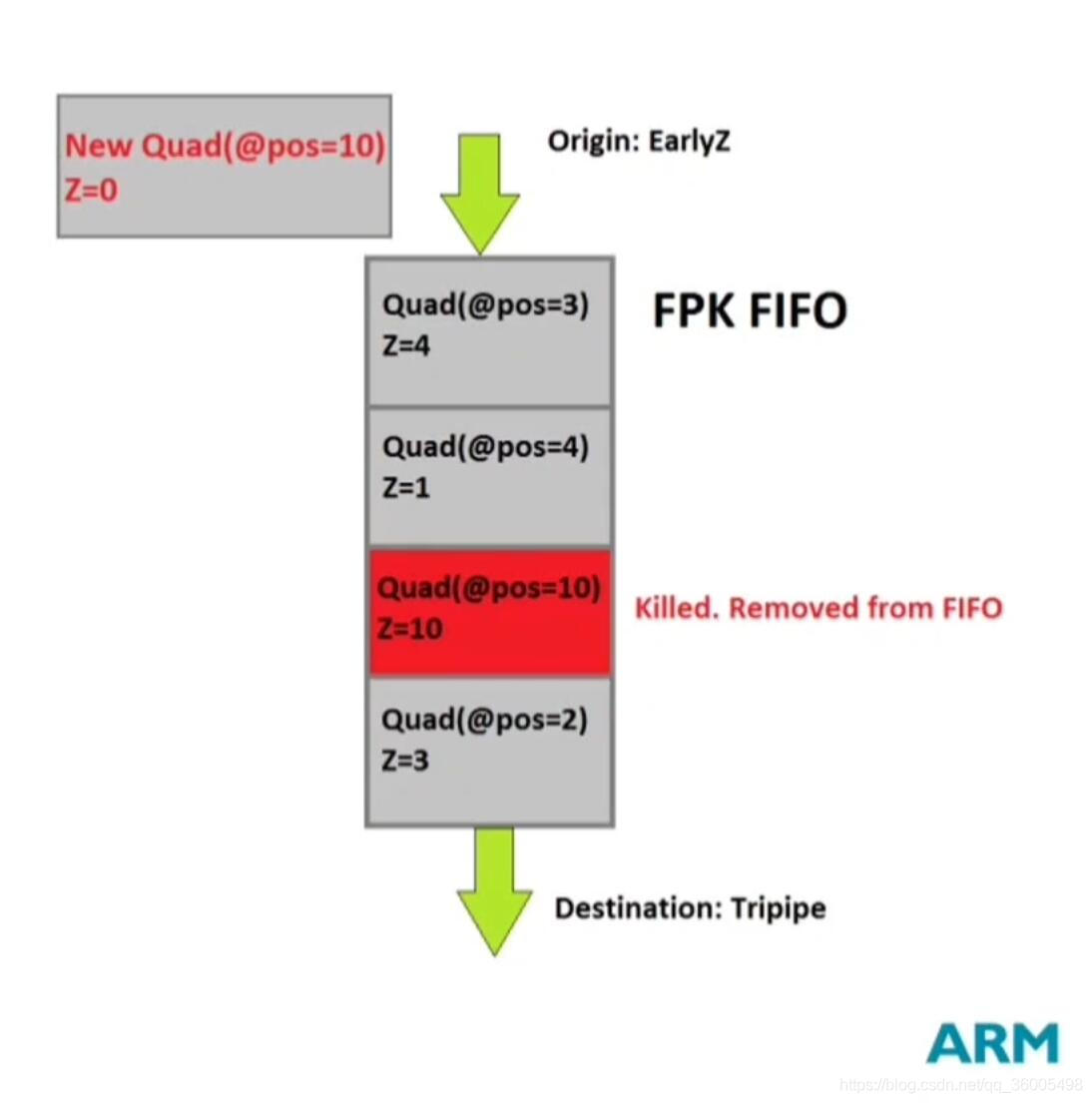
8.2 Mali的FPK(Android)
Forward Pixel Kill技术:在Early-Z阶段之后,使用一个FIFO队列抛弃被遮挡的Quad(例子中是2*2的像素)
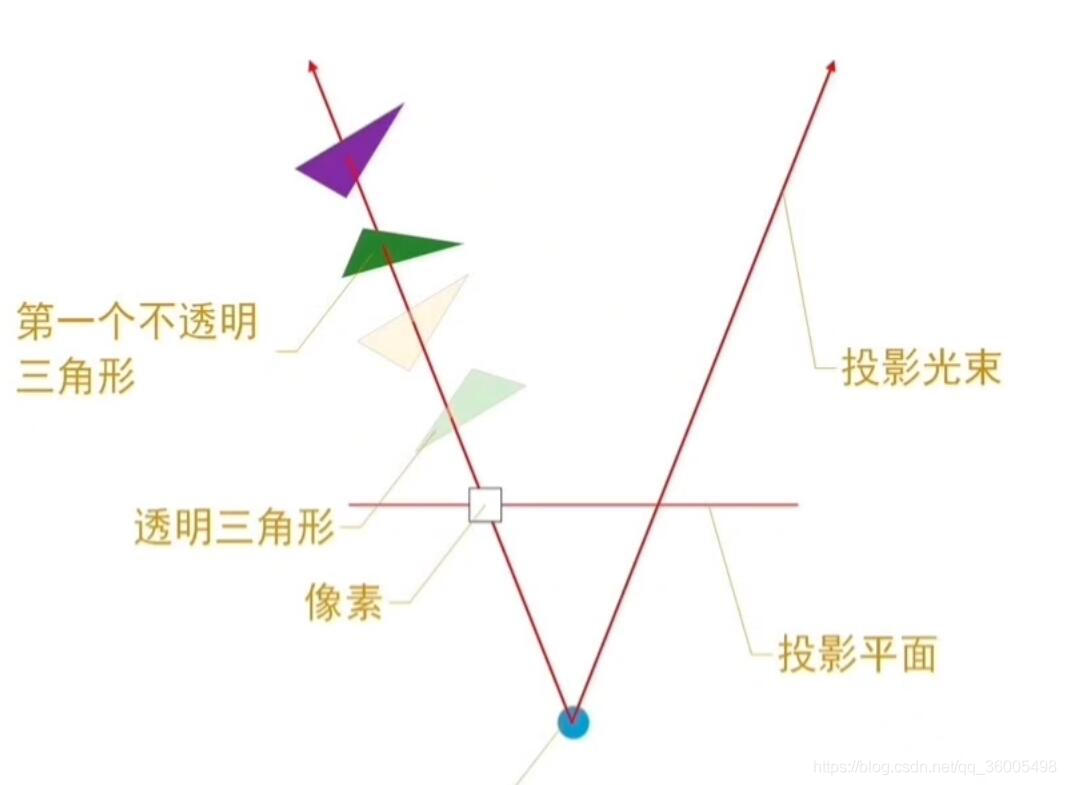
8.3 Power-VR的HSR(IOS)
Hidden Surface Removal技术:沿一条射线从第一个不透明片元向后剔除被遮挡的片元
9. 优化建议
- 不使用FrameBuffer时及时Clear或Discard:清空了在tile buffer上的中间数据。Unity中,不适用RT时调用Discard。OpenGL ES中善用glClear、glInvalidateFrameBuffer,避免不必要的Resolve(tile buffer刷新到系统内存)行为
- 减少一帧中FrameBuffer绑定的频繁切换:减少了tile buffer和系统内存之间的stall操作
- 考察Alpha Test和Alpha混合的实际表现,合理使用。减少Alpha混合实现透明时的混合范围(例如将透明区域的Mesh裁剪掉替换为多边形)
- 使用Alpha Test时先进行提前深度测试
- 图片尽量压缩,例如ASTC ETC2
- 图片尽量开启mipmap
- 贴图采样:UV值尽量使用VS中传出的Varying变量(VS向PS中传递的变量)(连续),不要再FS中动态计算UV(非连续),造成CacheMiss
- 在延迟渲染中尽量利用Tile Buffer
- 项目配置中不同的配置导致的帧率变化,可能是带宽占用的问题
- MSAA在TBDR下消耗很小:硬件速度快
- 减少FS中Clip(HLSL)、discard(GLSL)、gl_FragDepth的使用:会打断Early-DT的执行
- 区分使用float、half、fix:1). 降低带宽占用 2). 减少GPU周期提高并行程度 3). 降低统一变量寄存器数量,从而降低寄存器数量溢出风险,参考Unity3D shader优化技巧集合
- 减少FrameData压力:顶点处理部分容易成为瓶颈,应避免使用曲面细分shader、置换贴图等负操作。提倡使用模型LOD,且尽早进行遮挡剔除(如umbra)
作业
题目:打包场景到Android平台,对比优化前和优化后的结果
测试环境:2.84 GHz 骁龙865八核 8GB运存
提前总结:以下优化效果测试了贴图大小的影响,关闭了一些影响不大的后处理效果,没有进行shader的修改(菜~~ 没找到shader的位置,之后再完善吧)。
0. 优化前
场景来自Unity Asset 资源链接
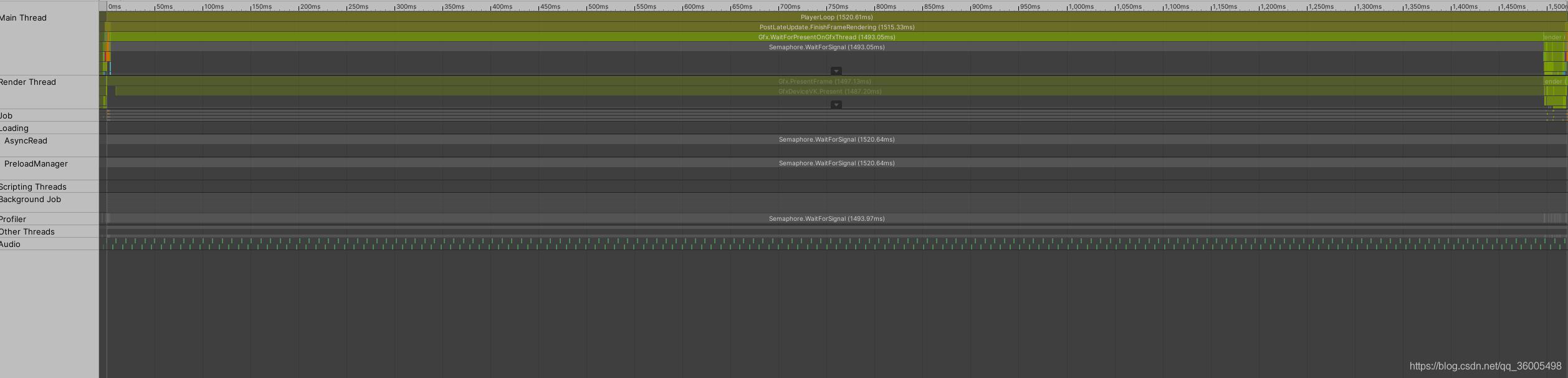

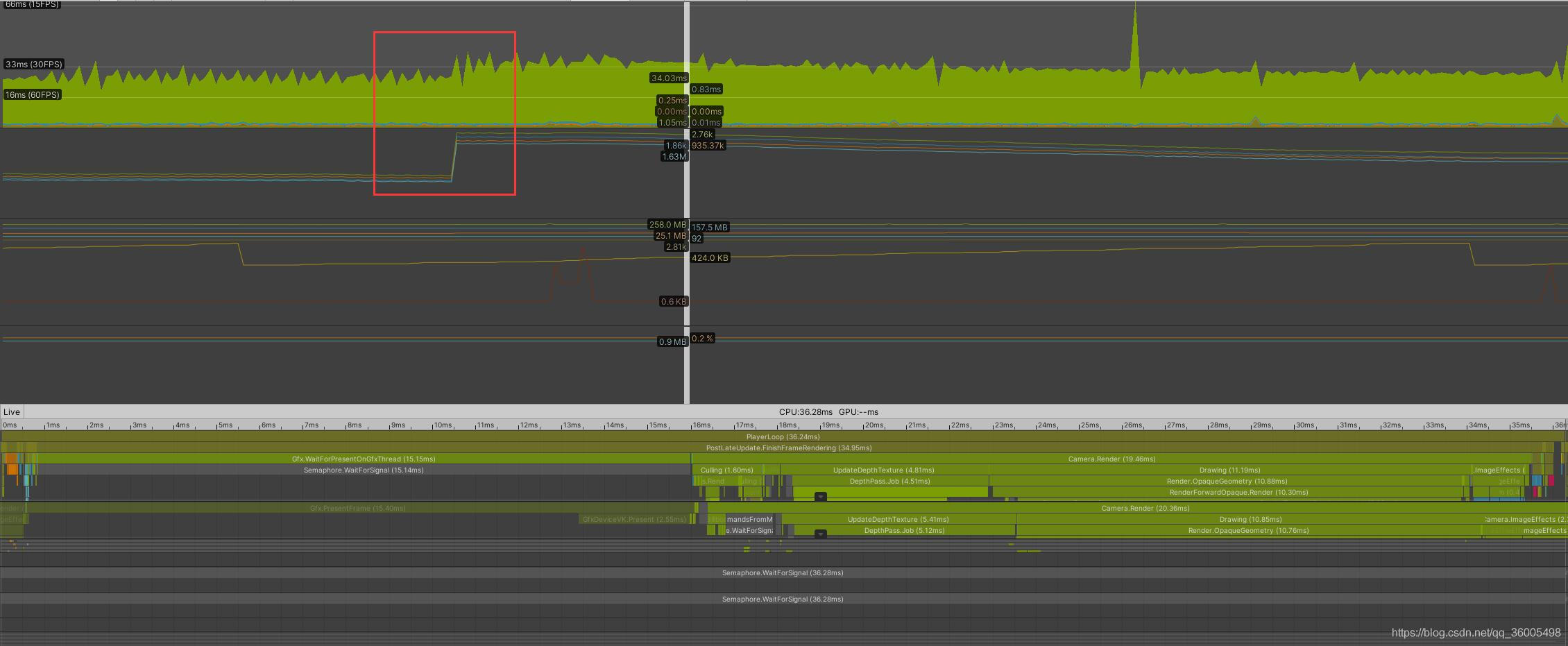
优化1:从上边的图看,瓶颈在GPU。经过尝试后关闭了摄像机中一个后处理(远处场景模糊处理),
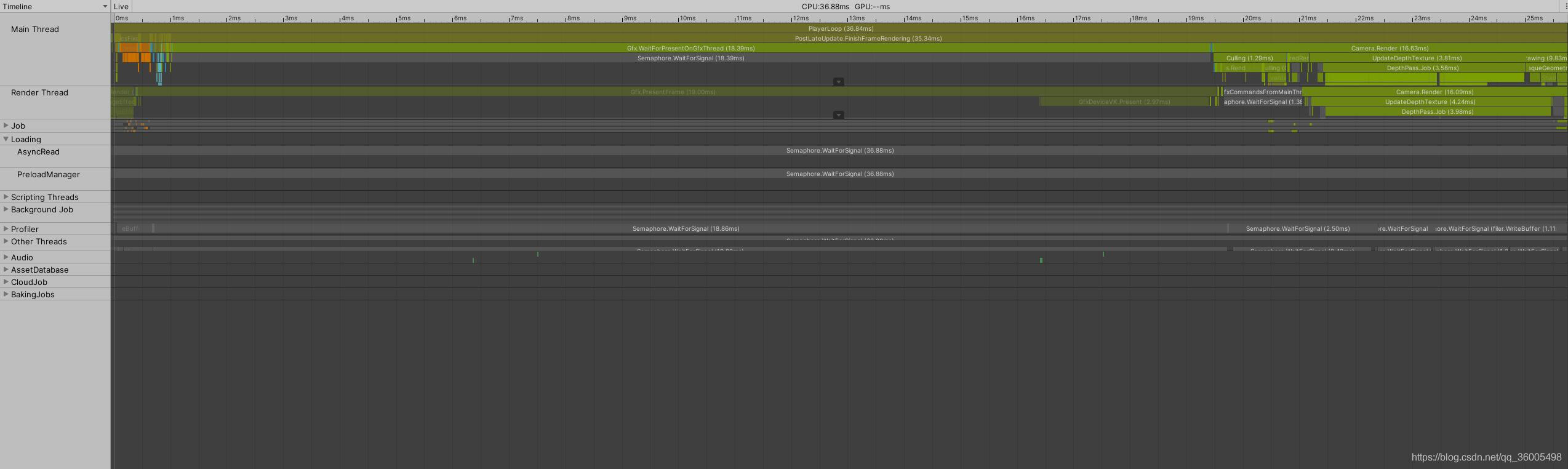
1. 关闭耗时的后处理
2. 贴图调整

- Texture Compression设置为ETC:没啥效果,依旧为38ms,看来默认就会有一些压缩
- Max Size 2048 -> 256 -> 32:差别不大,降低了5ms左右,画质变差了很多。可能由于开启了MipMap,远处的贴图降低了分辨率,近处的物体也不是很多。还有可能由于手机的性能瓶颈不在这里,故调整贴图大小差别不大
3. Shader
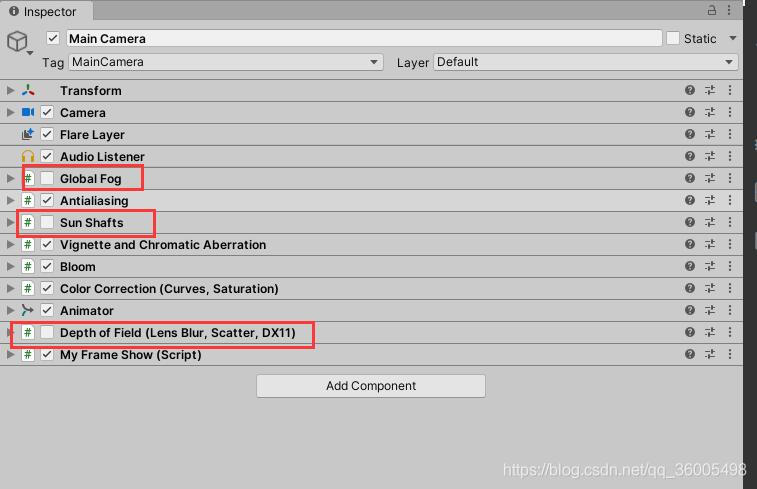
4. 一些后处理效果的删除
经测试,关掉这些后处理效果能在最终效果差别不大的情况下提升帧率(贴图在2048分辨率下)
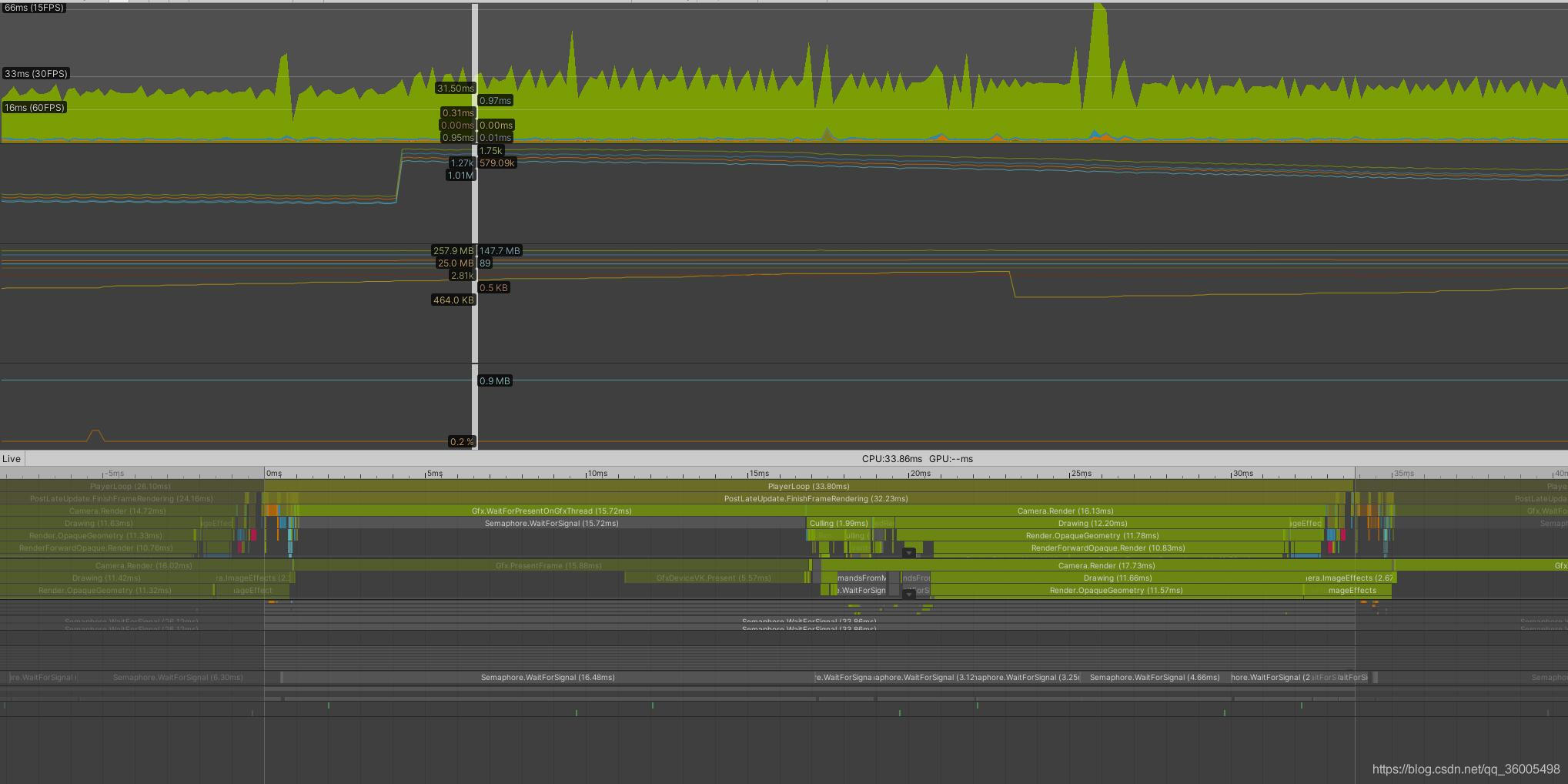



















 3766
3766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









