







1. Inception v1
参考文献:Going deeper with convolutions

Inception v1的亮点总结如下:
(1)卷积层共有的一个功能,可以实现通道方向的降维和增维,至于是降还是增,取决于卷积层的通道数(滤波器个数),在Inception v1中11卷积用于降维,减少weights大小和feature map维度。
(2)11卷积特有的功能,由于11卷积只有一个参数,相当于对原始feature map做了一个scale,并且这个scale还是训练学出来的,无疑会对识别精度有提升。
(3)增加了网络的深度
(4)增加了网络的宽度
(5)同时使用了11,33,55的卷积,增加了网络对尺度的适应性
这里有2个地方需要注意:
(1) 最后一个全连接层之前使用的是global average pooling,全局pooling使用的好了,还是有好多地方可以发挥的。
(2)在残差网络未出现之前,训练深度网络是很困难的, 整个网络为了保证收敛,有3个softmax损失函数,中间监督器可以增大被回传的梯度信号(类似残差连接思路)。在训练过程中,它们的损失加权到网络的总损失中(辅助分类器的损失加权0.3)。在测试时,这些辅助网络被丢弃。

2 . Inception v2 / v3
参考文献:Rethinking the InceptionArchitecture for Computer Vision
Inception v2的网络,代表作为加入了BN(Batch Normalization)层,并且使用2个33替代1个55卷积的改进版GoogleNet。

Inception v2的亮点总结如下:
(1)加入了BN层,减少了Internal Covariate Shift (内部神经元的数据分布发生变化),使每一层的输出都规范化到一个N(0, 1)的高斯,从而增加了模型的鲁棒性,可以以更大的学习速率训练,收敛更快,初始化操作更加随意,同时作为一种正则化技术,可以减少dropout层的使用。缺点就是增加了25%的weights和30%的计算消耗
(2)用2个连续的33 conv替代inception模块中的55,从而实现网络深度的增加,网络整体深度增加了9层。
Inception v3网络
主要在v2的基础上,提出了卷积分解(Factorization),代表作是Inceptionv3版本的GoogleNet。Inception v3的亮点总结如下:
(1) 作者将 nn 的卷积核尺寸分解为 1×n 和 n×1 两个卷积。例如,一个 3×3 的卷积等价于首先执行一个 1×3 的卷积再执行一个 3×1 的卷积。他们还发现这种方法在成本上要比单个 3×3 的卷积降低 33%。更加精细设计了3535/1717/88的模块。
(2)增加网络宽度,网络输入从224224变为了299299。
这一结构如下图所示

3 . Inception-v4:
参考文献:Inception-ResNet and the Impact of Residual Connections on Learning
Inception v4主要利用残差连接(Residual Connection)来改进v3结构,代表作为,Inception-ResNet-v1,Inception-ResNet-v2,Inception-v4
resnet中的残差结构如下,这个结构设计的就很巧妙,简直神来之笔,使用原始层和经过2个卷基层的feature map做Eltwise。Inception-ResNet的改进就是使用上文的Inception module来替换resnet shortcut中的conv+11 conv。

--------(ResNet改进版) ----------- (Inception-ResNet-A) --------------(Inception-ResNet-B)
Inception v4的亮点总结如下:
(1)将Inception模块和Residual Connection结合,提出了Inception-ResNet-v1,Inception-ResNet-v2,使得训练加速收敛更快,精度更高。
(2)设计了更深的Inception-v4版本,效果和Inception-ResNet-v2相当。
(3)网络输入大小和V3一样,还是299299
4 . ResNeXt
参考文献:Aggregated ResidualTransformations for Deep Neural Networks
这篇提出了resnet的升级版。ResNeXt,the next dimension的意思,因为文中提出了另外一种维度cardinality,和channel和space的维度不同,cardinality维度主要表示ResNeXt中module的个数,最终结论
(1)增大Cardinality比增大模型的width或者depth效果更好
(2)与 ResNet 相比,ResNeXt 参数更少,效果更好,结构更加简单,更方便设计
其中,左图为ResNet的一个module,右图为ResNeXt的一个module,是一种split-transform-merge的思想。

这个全新的结构有三个等价形式:

5 . Xception:
参考文献: DeepLearning with Depthwise Separable Convolutions
这篇文章主要在Inception V3的基础上提出了Xception(Extreme Inception),基本思想就是通道分离式卷积(depthwise separable convolution operation)。最终实现了
先说,卷积的操作,主要进行2种变换,
(1)spatial dimensions,空间变换
(2)channel dimension,通道变换
而Xception就是在这2个变换上做文章。Xception与Inception V3的区别如下:

(1)卷积操作顺序的区别
Inception V3是先做11的卷积,再做33的卷积,这样就先将通道进行了合并,即通道卷积,然后再进行空间卷积,而Xception则正好相反,先进行空间的33卷积,再进行通道的11卷积。
(2)RELU的有无
这个区别是最不一样的,Inception V3在每个module中都有RELU操作,而Xception在每个module中是没有RELU操作的。
• 整个网络结构具有14个模块,36个卷积
结论;不带激活函数的网络结构,效果更好
注:和《InceptionV3》中的结论相反,可能和特征空间的深度有关
网络特征比较深的时候,非线性激活有帮助
网络结构比较浅的时候,非线性激活反而有害
6 . MobileNets:
参考文献:EfficientConvolutional Neural Networks for Mobile Vision Applications
MobileNets其实就是Exception思想的应用。区别就是Exception文章重点在提高精度,而MobileNets重点在压缩模型,同时保证精度。
depthwis eseparable convolutions的思想就是,分解一个标准的卷积为一个depthwise convolutions和一个pointwise convolution。简单理解就是矩阵的因式分解。
传统卷积和深度分离卷积的区别如下,

假设,输入的feature map大小为H*W,维度为M,滤波器的大小为K * K,维度为N,并且假设padding为1,stride为1。则原始的卷积操作,需要进行的矩阵运算次数为K·K·M·N·H·W,卷积核参数为K·K·N·M depthwise separable convolutions需要进行的矩阵运算次数为K·K ·M·H·W + M·N·H·W,卷积核参数为K·K·M+N·M,由于卷积的过程,主要是一个spatial dimensions减少,channel dimension增加的过程,即N>M,所以参数数量对应减少,K·K·N·M> K·K·M+N·M。
7 . ShuffleNet:
参考文献:AnExtremely Efficient Convolutional Neural Network for Mobile Devices
这篇文章在mobileNet的基础上主要做了1点改进:mobileNet只做了33卷积的deepwise convolution,而11的卷积还是传统的卷积方式,还存在大量冗余,ShuffleNet则在此基础上,将1*1卷积做了shuffle和group操作,实现了channel shuffle 和pointwise group convolution操作,最终使得速度和精度都比mobileNet有提升。
( a ) 是原始的mobileNet的框架,各个group之间相互没有信息的交流。
( b ) 将feature map做了shuffle操作
( c ) 是经过channel shuffle之后的结果。如下图所示,

ShuffleNet Units 的结构如下,
( a ) 是一个带depthwise convolution (DWConv)的bottleneck unit
( b ) 在( a )的基础上,进行了pointwise group convolution (GConv) and channel shuffle
( c ) 进行了AVG pooling和concat操作的最终ShuffleNetunit

8 . MobileNetV2:
参考文献:Inverted Residuals and Linear Bottlenecks
主要贡献有2点:
1,提出了逆向的残差结构(Inverted residuals)
由于MobileNetV2版本使用了残差结构,和resnet的残差结构有异曲同工之妙,源于resnet,却和而不同。

由于Resnet没有使用depthwise conv,所以,在进入pointwise conv之前的特征通道数是比较多的,所以,残差模块中使用了0.25倍的降维。而MobileNet v2由于有depthwise conv,通道数相对较少,所以残差中使用 了6倍的升维。
总结起来,2点区别
(1)ResNet的残差结构是0.25倍降维,MobileNet V2残差结构是6倍升维
(2)ResNet的残差结构中33卷积为普通卷积,MobileNet V2中33卷积为depthwise conv

MobileNet v1,MobileNet v2 有2点区别:
(1)v2版本在进入33卷积之前,先进行了11pointwise conv升维,并且经过RELU。
(2)1*1卷积出去后,没有进行RELU操作
2,提出了线性瓶颈单元(linear bottlenecks)
Why no RELU?
首选看看RELU的功能。RELU可以将负值全部映射为0,具有高度非线性。下图为论文的测试。在维度比较低2,3的时候,使用RELU对信息的损失是比较严重的。而单维度比较高15,30时,信息的损失是比较少的。

MobileNet v2中为了保证信息不被大量损失,应此在残差模块中去掉最后一个的RELU。因此,也称为线性模块单元。
9. Attention Mechanism
Attention机制的本质来自于人类视觉注意力机制。人们视觉在感知东西的时候一般不会是一个场景从到头看到尾每次全部都看,而往往是根据需求观察注意特定的一部分。而且当人们发现一个场景经常在某部分出现自己想观察的东西时,人们会进行学习在将来再出现类似场景时把注意力放到该部分上。
注意力机制在卷积神经网络中过程如下图所示:

对于空间注意力机制;以往的每个像素点由卷积过程得到,所有像素点生成过程是具有相同权重,空间注意力机制将通过学习计算所有像素点的权重,对更加感兴趣的区域给予更多关注(即大的权重),将学习得到的像素权重矩阵乘以每个特征图即得到spatial attention model Φs
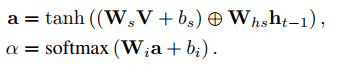
对于通道注意力机制;以往每个特征图通道贡献相同的权重,其各个通道的权重是通过网络学习出来的学到的,学到的权重再然后对应乘以每个特征图即得到channel-wise attention model Φc
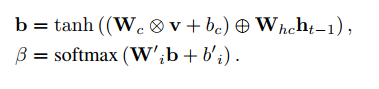
代码实现
################################空间注意机制 #############################
def spatial_attention(feature_map, K=1024, weight_decay=0.00004, scope="", reuse=None):
with tf.variable_scope(scope, 'SpatialAttention', reuse=reuse):
# 默认数据输入格式BHWC.
_, H, W, C = tuple([int(x) for x in feature_map.get_shape()])
w_s = tf.get_variable("SpatialAttention_w_s", [C, 1],
dtype=tf.float32,
initializer=tf.initializers.orthogonal,
regularizer=tf.contrib.layers.l2_regularizer(weight_decay))
b_s = tf.get_variable("SpatialAttention_b_s", [1],
dtype=tf.float32,
initializer=tf.initializers.zeros)
spatial_attention_fm = tf.matmul(tf.reshape(feature_map, [-1, C]), w_s) + b_s
spatial_attention_fm = tf.nn.sigmoid(tf.reshape(spatial_attention_fm, [-1, W * H]))
attention = tf.reshape(tf.concat([spatial_attention_fm] * C, axis=1), [-1, H, W, C])
attended_fm = attention * feature_map
return attended_fm
################################通道注意机制 ############################
def channel_wise_attention(feature_map, K=1024, weight_decay=0.00004, scope='', reuse=None):
with tf.variable_scope(scope, 'ChannelWiseAttention', reuse=reuse):
_, H, W, C = tuple([int(x) for x in feature_map.get_shape()])
w_s = tf.get_variable("ChannelWiseAttention_w_s", [C, C],
dtype=tf.float32,
initializer=tf.initializers.orthogonal,
regularizer=tf.contrib.layers.l2_regularizer(weight_decay))
b_s = tf.get_variable("ChannelWiseAttention_b_s", [C],
dtype=tf.float32,
initializer=tf.initializers.zeros)
transpose_feature_map = tf.transpose(tf.reduce_mean(feature_map, [1, 2], keep_dims=True),
perm=[0, 3, 1, 2])
channel_wise_attention_fm = tf.matmul(tf.reshape(transpose_feature_map,
[-1, C]), w_s) + b_s
channel_wise_attention_fm = tf.nn.sigmoid(channel_wise_attention_fm)
attention = tf.reshape(tf.concat([channel_wise_attention_fm] * (H * W),
axis=1), [-1, H, W, C])
attended_fm = attention * feature_map
return attended_fm
####来源SCA-CNN: Spatial and Channel-Wise Attention in Convolutional Networks for Image Captioning














 9195
9195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









