






HW2(2) TVLQR(时变LQR)汽车轨迹跟踪
题目需求
本问题中我们使用时变LQR(time-varying LQR)来跟踪一个简化汽车非线性模型的轨迹。因为是tracking问题而不是stablization问题,因此使用时变LQR而不是时不变LQR,但是,在Riccati recursion看来,推导过程并没有什么区别。
流程:
- 系统模型与离散化
- 参考轨迹
- 实现TVLQR
- 无噪声
- 带控制误差仿真
- 带模型误差仿真
- Monte-Carlo收敛性分析
模型与离散化
本问题中,我们使用单车模型来近似车辆,使用前驱动轮的形式,以汽车的中点为中心建模(自动驾驶中的车辆运动学模型 - 知乎 (zhihu.com)),将汽车的两个前轮和两个后轮合并。
x
=
[
p
x
p
y
θ
δ
]
,
u
=
[
v
ϕ
]
,
x
˙
=
[
v
cos
(
θ
+
β
)
v
sin
(
θ
+
β
)
v
cos
β
tan
δ
L
ϕ
]
(1)
\begin{align} x = \begin{bmatrix} p_x \\ p_y \\ \theta \\ \delta \end{bmatrix}, \quad u = \begin{bmatrix} v \\ \phi \end{bmatrix}, \quad \dot{x} = \begin{bmatrix} v \cos{(\theta + \beta)} \\ v \sin{(\theta + \beta)} \\ \frac{v \cos{\beta} \tan{\delta}}{L} \\ \phi \end{bmatrix} \end{align}\tag{1}
x=
pxpyθδ
,u=[vϕ],x˙=
vcos(θ+β)vsin(θ+β)Lvcosβtanδϕ
(1)
其中,
p
x
p
y
p_x \ p_y
px py是车辆中心的位置,
θ
\theta
θ是车辆本体的yaw角,
δ
\delta
δ是方向盘角度(车轮角度,steering angle),
ϕ
\phi
ϕ是打角变化率,
v
v
v是线速度,
β
=
atan2
(
δ
l
r
,
L
)
\beta = \text{atan2}(\delta l_r, L)
β=atan2(δlr,L)是滑移角(Slip angle),表示车子中心的实际线速度方向与车子本体方向
θ
\theta
θ的夹角,
l
r
l_r
lr是车子中心到后轮的距离,
l
f
l_f
lf是车子中心到前轮的距离,
L
L
L是前后轮的距离。
model = BicycleModel() # 模型来自RobotZoo
# Evaluate the continuous and discrete dynamics
x0 = SA[0,0,0,0] #初始位置
u0 = SA[0,0]
t0 = 0.0
dt = 0.1 # 离散时间
dynamics(model, x0, u0)
discrete_dynamics(RK4, model, x0, u0, t0, dt) # use rk4 for integration
# Evaluate the continuous and discrete Jacobians
z0 = KnotPoint(x0,u0,dt,t0) # create a `KnotPoint` type that stores everything together
∇f = RobotDynamics.DynamicsJacobian(model)
jacobian!(∇f, model, z0) # 获得雅可比函数J(x,u)
discrete_jacobian!(RK4, ∇f, model, z0) # 带入雅可比函数得到实际的雅可比值
# Extract pieces of the Jacobian
A = ∇f.A #线性化的模型。但是本文中是TVLQR,每个参考轨迹点处都会线性化一遍的
B = ∇f.B;
参考轨迹
参考轨迹我们直接load已经有的,在实际中,轨迹往往是由规划器给出交给控制器(如TVLQR\MPC)去执行,对于复杂的轨迹,仅仅用一个reactive controller(如PID,LQR)是比较难跟踪好的,必须要加上预测功能。
本文要跟踪的轨迹如下,包括控制量和状态量(假如不给控制量只给状态量的话,则做线性化时,默认在输入 u = 0 u=0 u=0处线性化,此时若状态变化量太大导致会有一个大的 u u u,将会导致线性化模型不准,控制效果不佳,因此给出的控制量相当于是一个前馈的作用)。
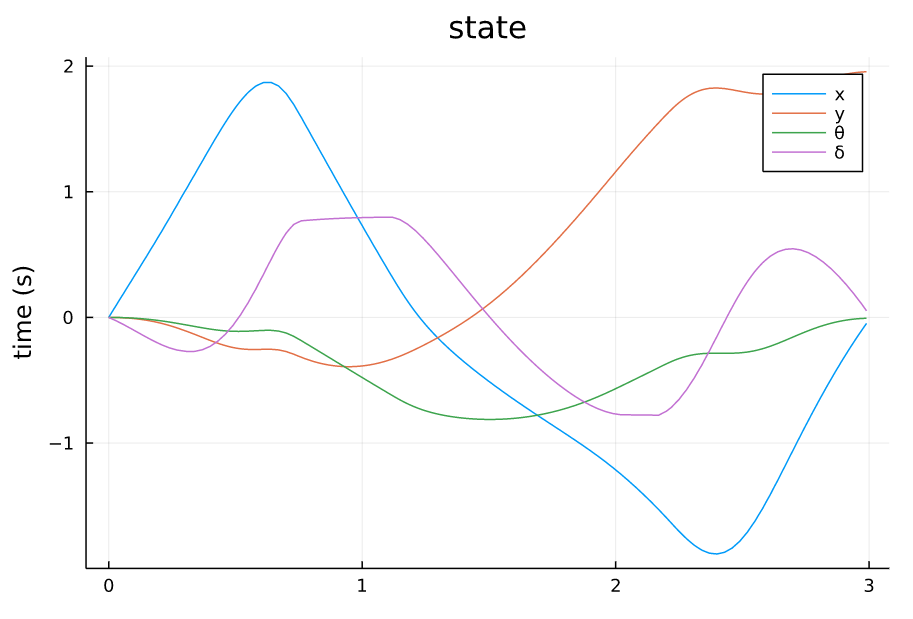
TVLQR参考状态量 |
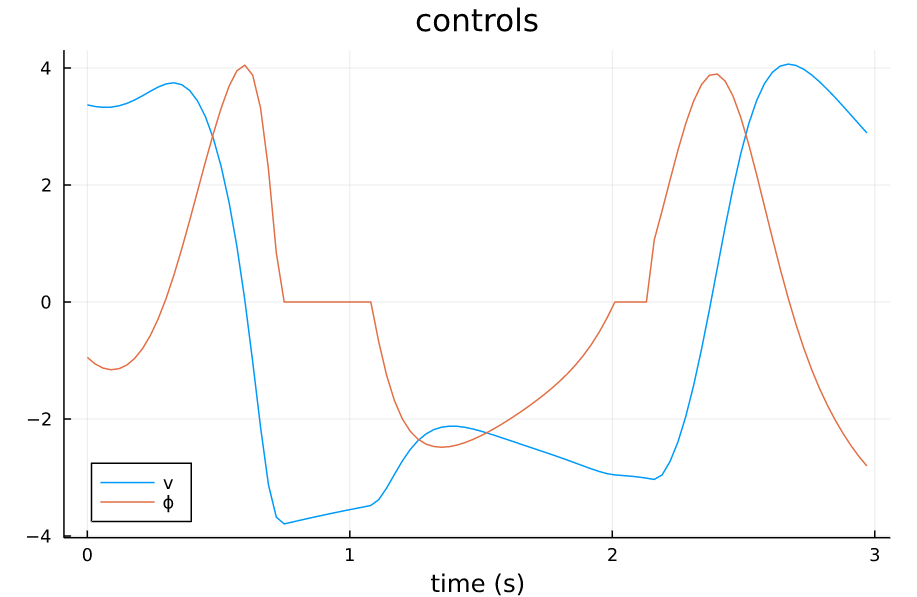
TVLQR参考控制量 |
实现TVLQR
TVLQR与常规LQR的区别就是,在TILQR中,线性化的点是平衡点,是固定的,而在TVLQR中,线性化的点是轨迹上的点,有点类似DDP在每个点都线性化了.与DDP不同的是,TVLQR的Cost函数就是在线性化点最好(因为理想目标就是完美跟踪这一条轨迹),因此得到的一定是只有反馈的最优控制率(任何偏离参考轨迹的行为都将会被控制器拉回来),而DDP的Cost函数不一定是在线性化点最好,因此会得到一个前馈+反馈的控制率,只有当DDP完全收敛时,得到的才是一个TVLQR反馈控制率。
function linearize!(ctrl::TVLQR) # 沿着参考轨迹线性化整个系统
∇f = RobotDynamics.DynamicsJacobian(model) #得到雅可比矩阵函数J(x,u)
# loop over all the time steps in the reference trajectory
for k = 1:N-1
# some boilerplate code...
dt = ctrl.times[k+1] - ctrl.times[k] #得到dt
z = KnotPoint(X[k], U[k], dt, ctrl.times[k]) #stack成一个大变量来evaluate雅可比矩阵的值
# evaluate the discrete jacobian at the current time step
discrete_jacobian!(RK4, ∇f, model, z)
# store the pieces in the controller
ctrl.A[k] .= ∇f.A # 每个轨迹点处都会有一个A B
ctrl.B[k] .= ∇f.B
end
end
function calc_gains!(ctrl::TVLQR) # Riccati recursion得到所有K和P
# TODO: Implement Riccati recursion for TVLQR
P[N] = ctrl.Qf # 从最后一个变量开始
for k=(N-1):-1:1 # 迭代式子参考Lecture 7
K[k] .= (R + B[k]' * P[k+1] * B[k]) \ (B[k]' * P[k+1] * A[k])
P[k] .= Q + A[k]' * P[k+1] * A[k] - A[k]' * P[k+1] * B[k] * K[k]
end
return nothing # 所有变量都存储在TVLQR问题的大类中,不需要返回
end
function get_control(ctrl::TVLQR, x, t)
u = zero(ctrl.U[1]) # 初始化
k = get_k(ctrl, t) # 看看此时的t对应那个离散时间段,获得参考输入
u = ctrl.U[k] - ctrl.K[k] * (x - ctrl.X[k]) #零阶保持的形式输出,线性化点为参考点
return u
end
结果分析
利用TVLQR闭环控制器仿真结果
function simulate(model::BicycleModel, x0, ctrl; tf=ctrl.times[end], dt=1e-2, ν=0.0, w=0.00)
times = range(0, tf, step=dt)
X = [@SVector zeros(n) for k = 1:N] #初始化
U = [@SVector zeros(m) for k = 1:N-1]
X[1] = x0 #起始状态
for k = 1:N-1
U[k] = get_control(ctrl, X[k], times[k]) + SA[randn(), randn()]*ν # 模拟控制误差
X[k+1] = discrete_dynamics(RK4, model, X[k], U[k], times[k], dt) + SA[0,0,0,randn()*w] #模拟系统模型误差
end
return X,U,times
end
从仿真结果中可以看出:
- 系统对控制误差的容差比较大,噪声的强度给到1.0甚至状态轨迹都能基本保持原本的形状,噪声为0.5的时候,轨迹基本不受影响。
- 系统对来自模型的误差比较敏感,因为模型噪声给到的是steering angle处,而对车来说,这个角度是一个非线性的量,而且会影响所有状态的转移。
- 整体来讲,TVLQR轨迹跟踪的效果还不错
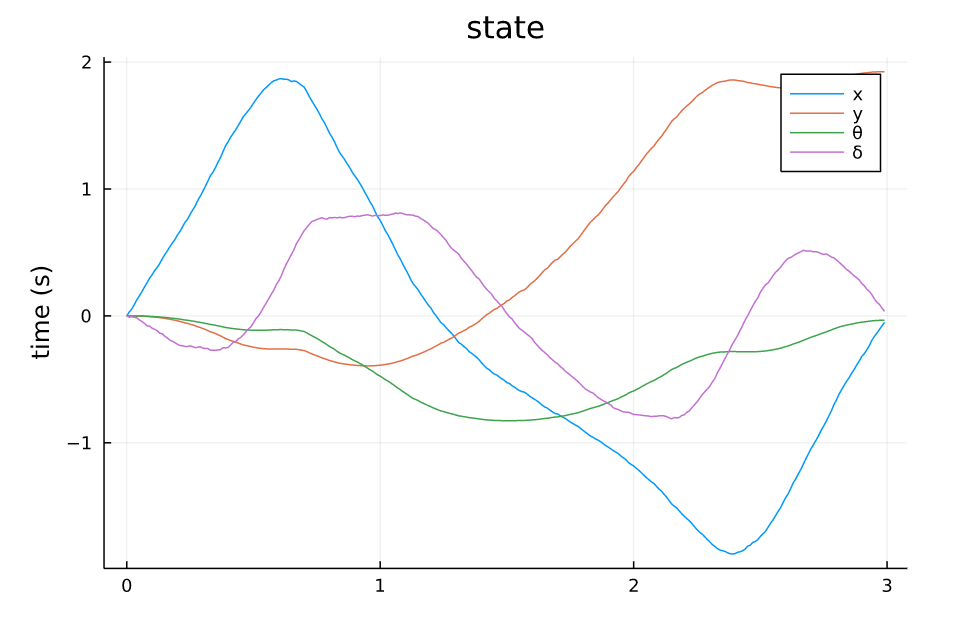
TVLQR State v=0.5 w=0 |
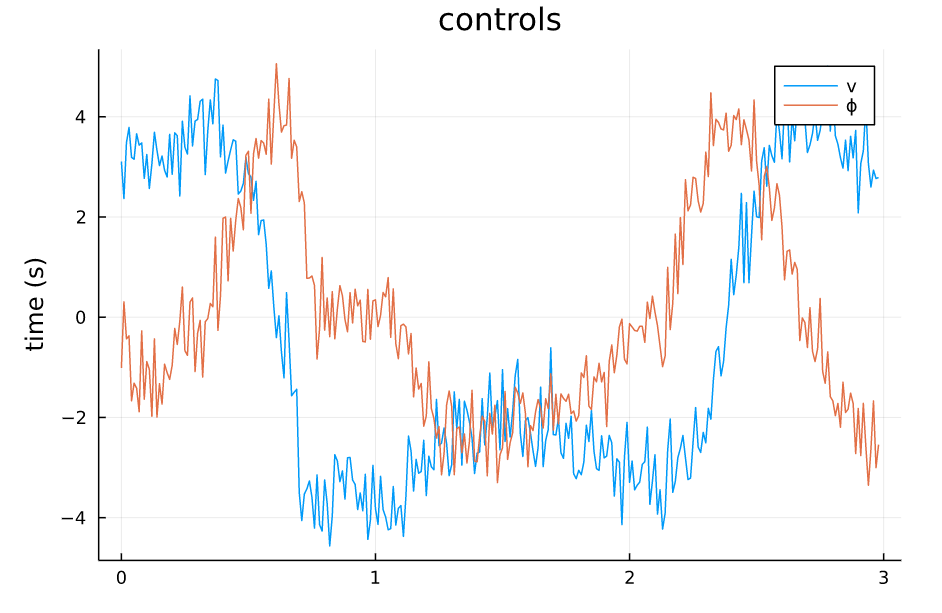
TVLQR Control v=0.5 w=0 |
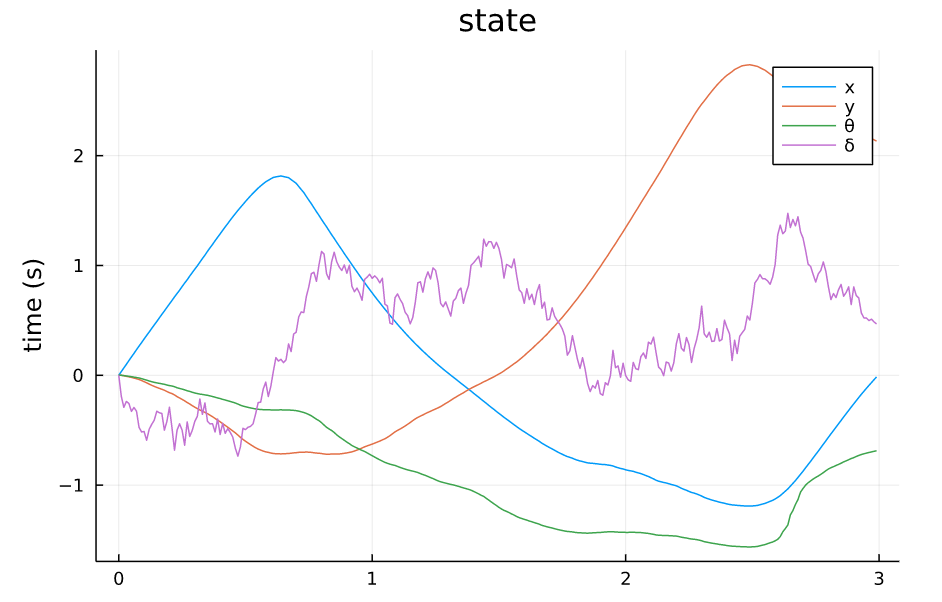
TVLQR State v=0 w=0.1 |
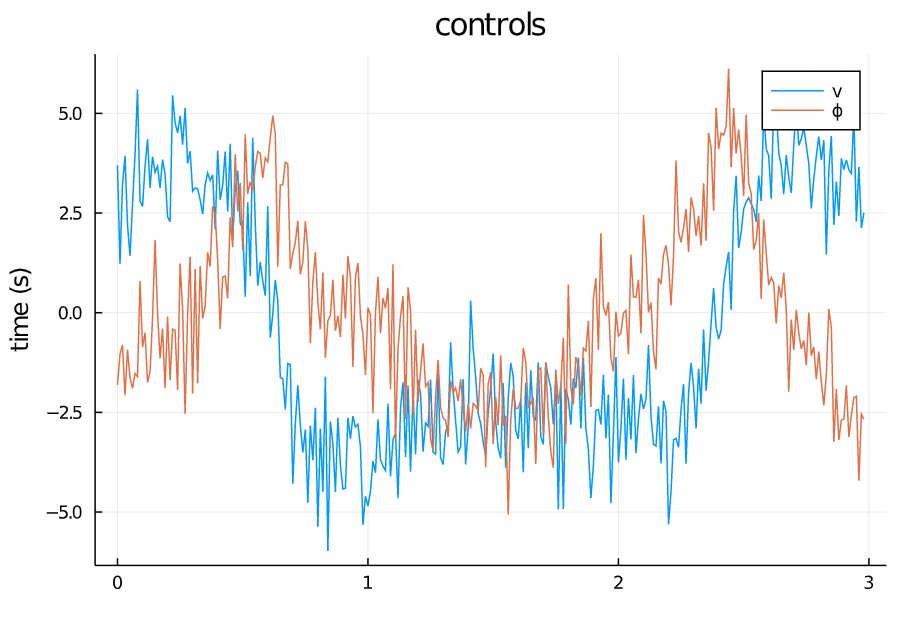
TVLQR Control v=0 w=0.1 |
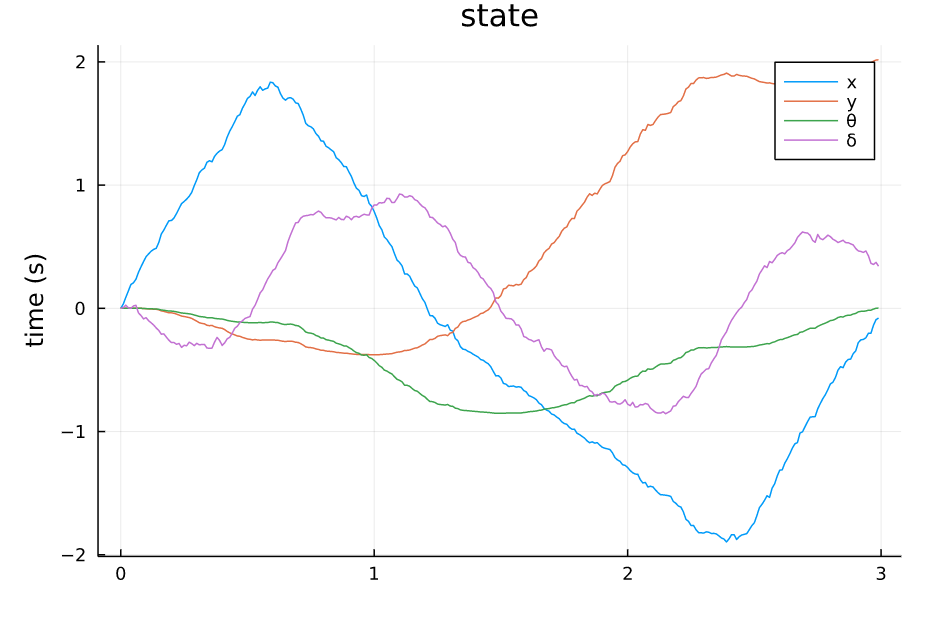
TVLQR State v=1.0 w=0.0 |
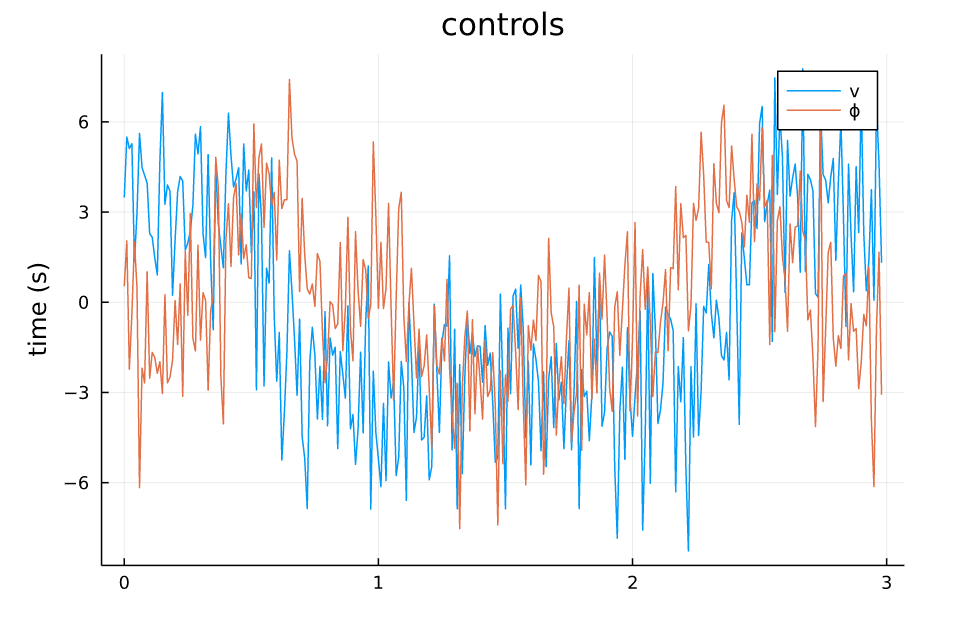
TVLQR Control v=1.0 w=0.0 |
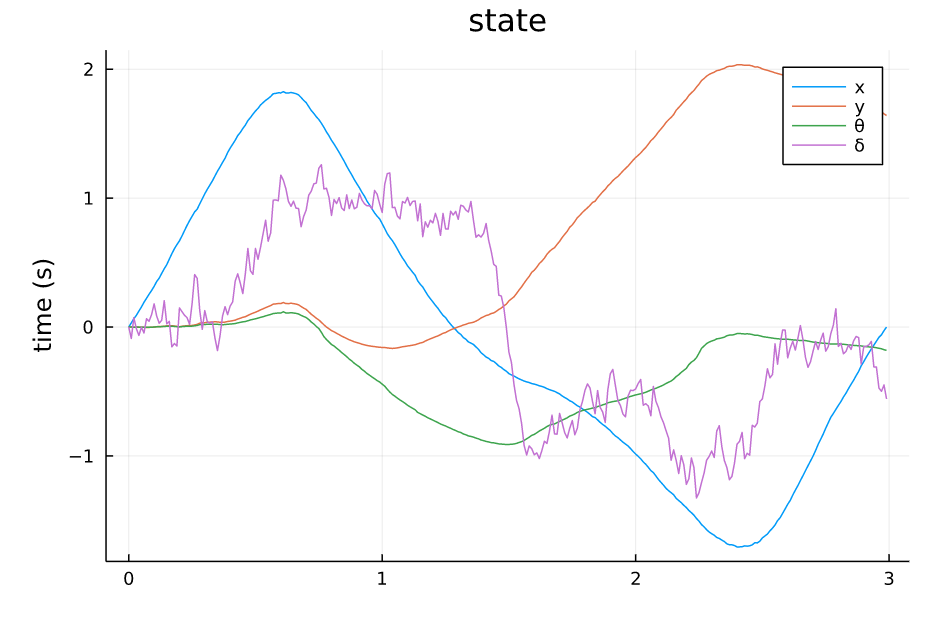
TVLQR State v=0.5 w=0.1 |
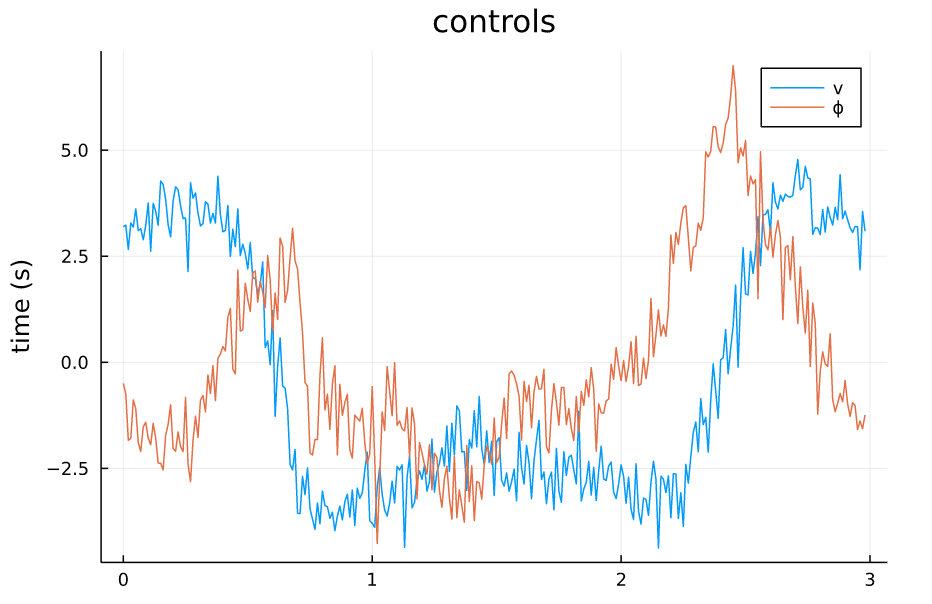
TVLQR Control v=0.5 w=0.1 |
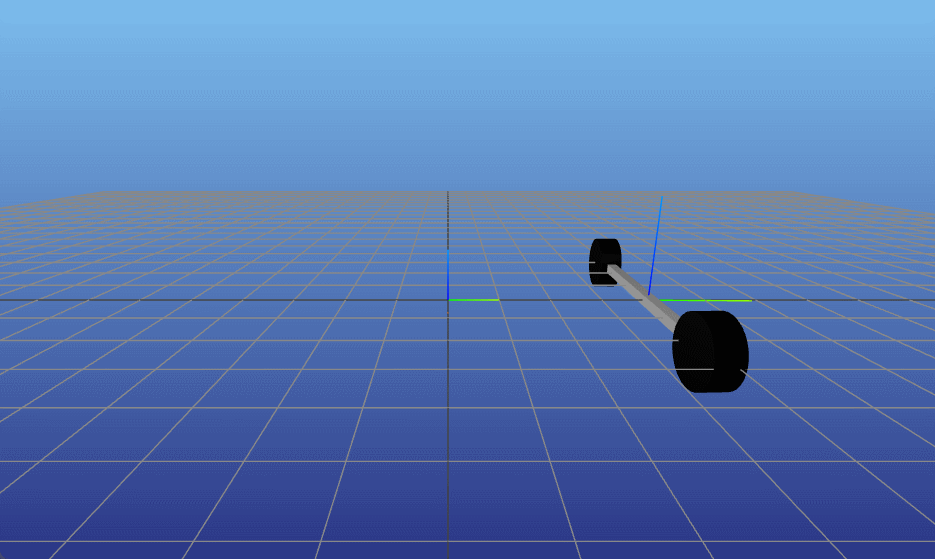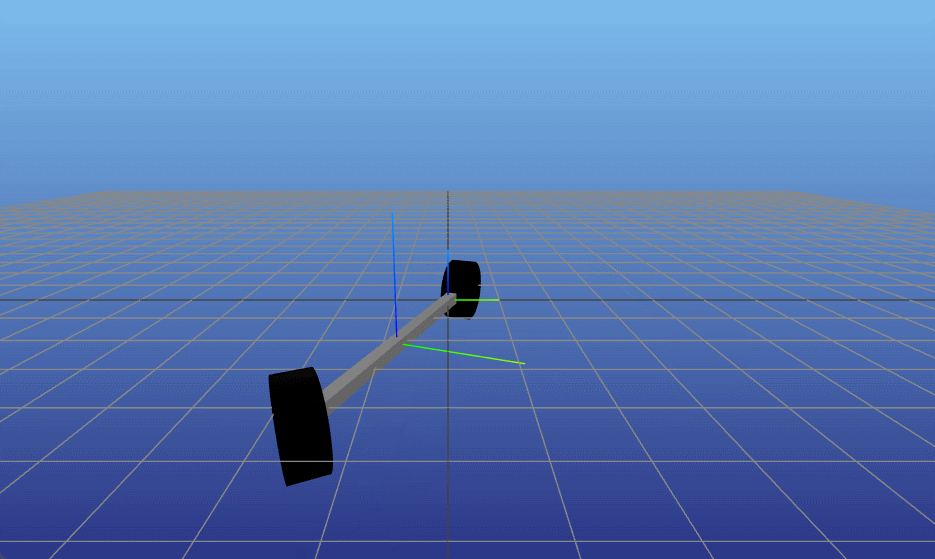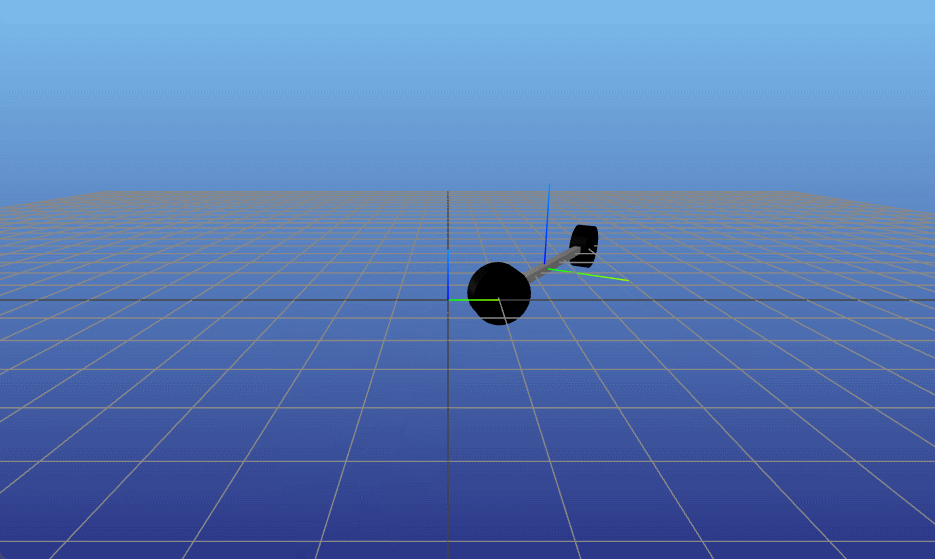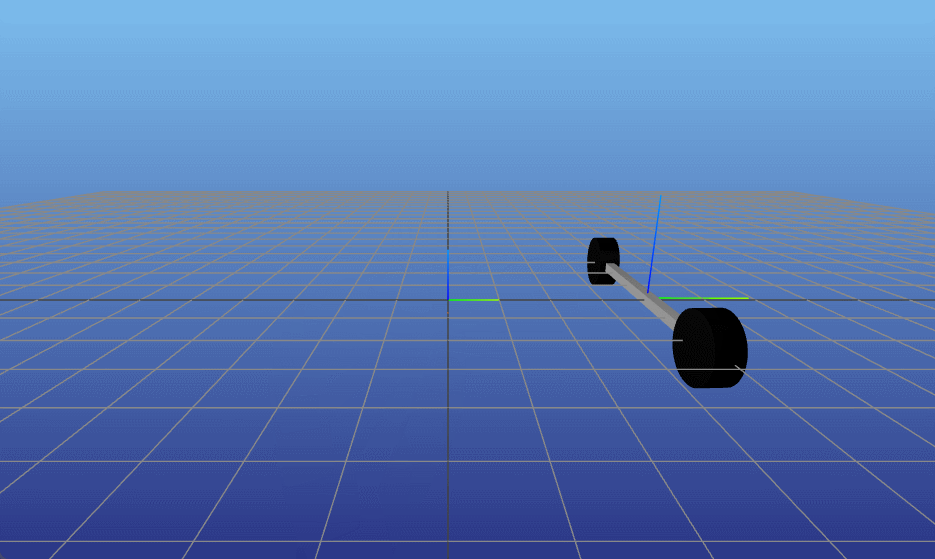
TVLQR v=0.5 w=0 |

TVLQR v=0 w=0.1 |
Monte-Carlo收敛性分析
接着,我们更深层次分析一下,TVLQR控制器能够在什么起始位置收敛,即原本该TVLQR控制器是针对一条特定的轨迹和输入来设计的,但是当起始位置变化时,它还能不能work呢?(收敛于终点)。因此我们做一个简单的Monte-Carlo分析,在原本起始位置 x 0 x_0 x0的前后左右 Δ x Δ y \Delta x \ \Delta y Δx Δy,然后利用该TVLQR分析其收敛(起始状态的 θ δ \theta \ \delta θ δ都是0)。
结果如下,在仅仅 x x x变化的大部分范围内,控制器都是能收敛的(指标是 ∣ X r e f , N − X N ∣ 2 < 0.2 |X_{ref,N} - X_N |_2 < 0.2 ∣Xref,N−XN∣2<0.2)<在 y y y大概正负1的范围内,控制器能收敛。这也是符合想象的,假如起始位置在 x 0 x_0 x0前后,那么可以通过TVLQR控制器直接输出一个向前向后的负反馈输出,那么可以很快就收敛回去原本的状态附近。但是假如是在 x 0 x_0 x0左右两边,此时对于车来说要回到原本的状态时需要进行侧移的,对于带有non-holonomic的车来说,这是一个很高难度的动作,因此较难完成(对于TVLQR生成的控制器来说)。
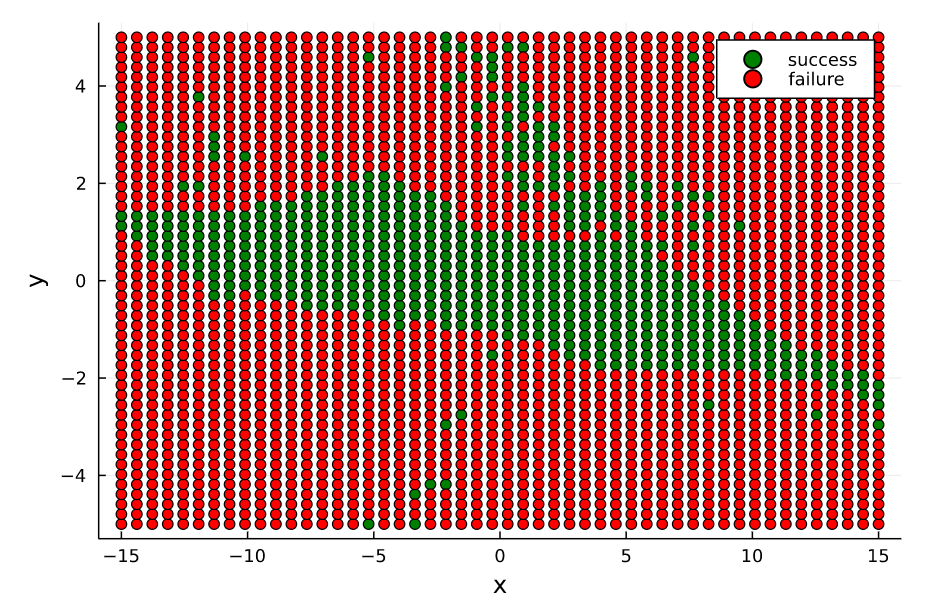
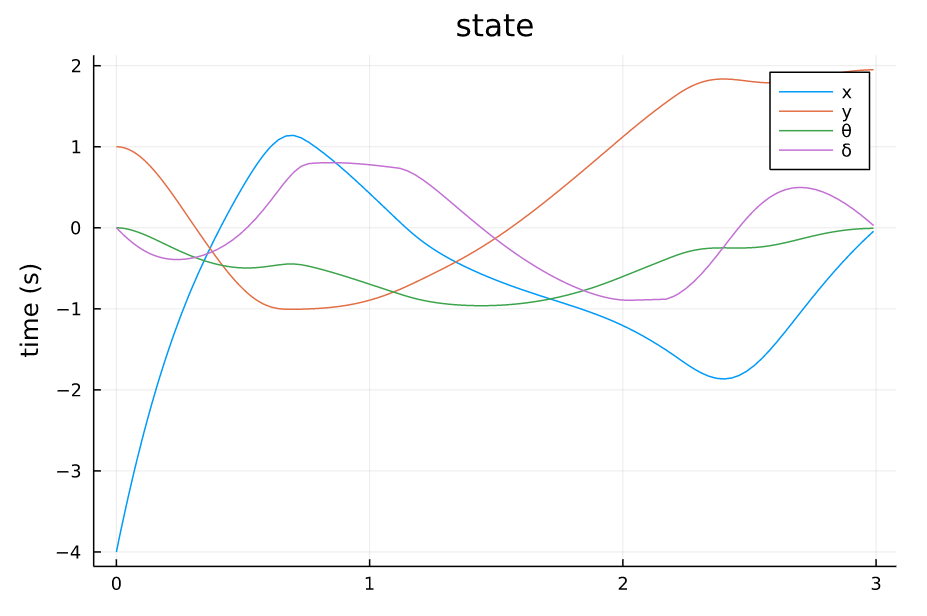
TVLQR 起点(-4,1) |
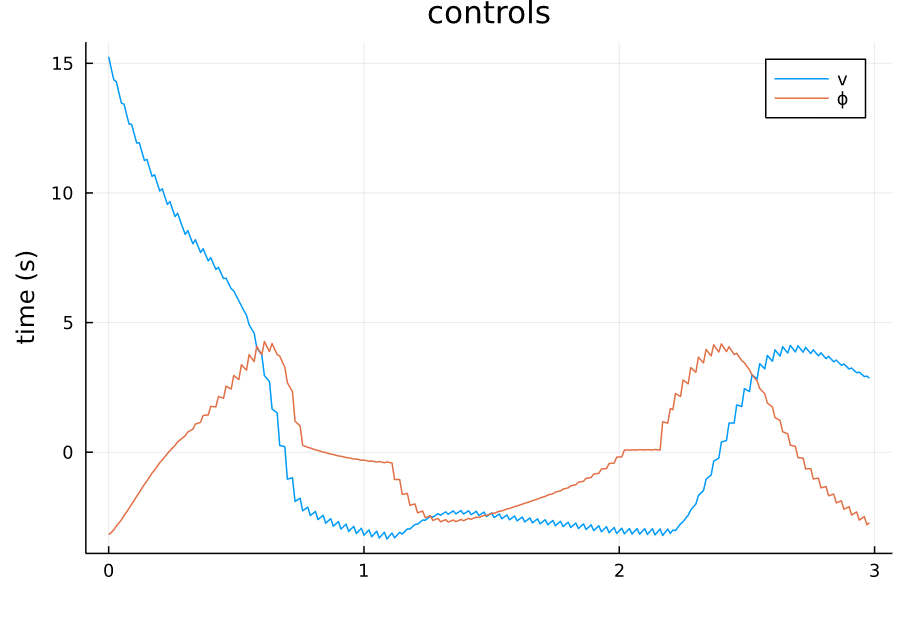
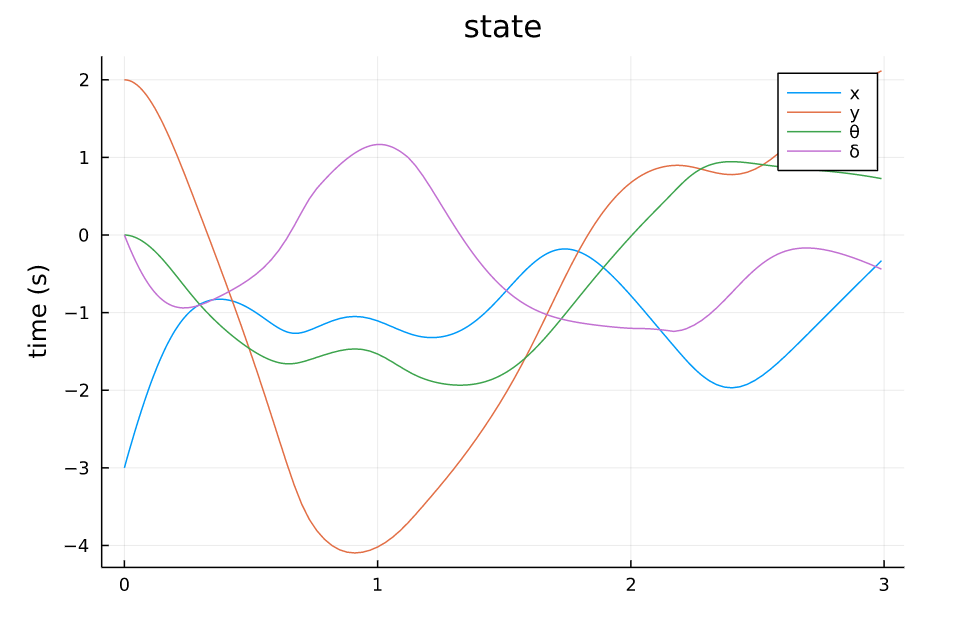
TVLQR 起点(-4,1) |
TVLQR 起点(-3,2) |
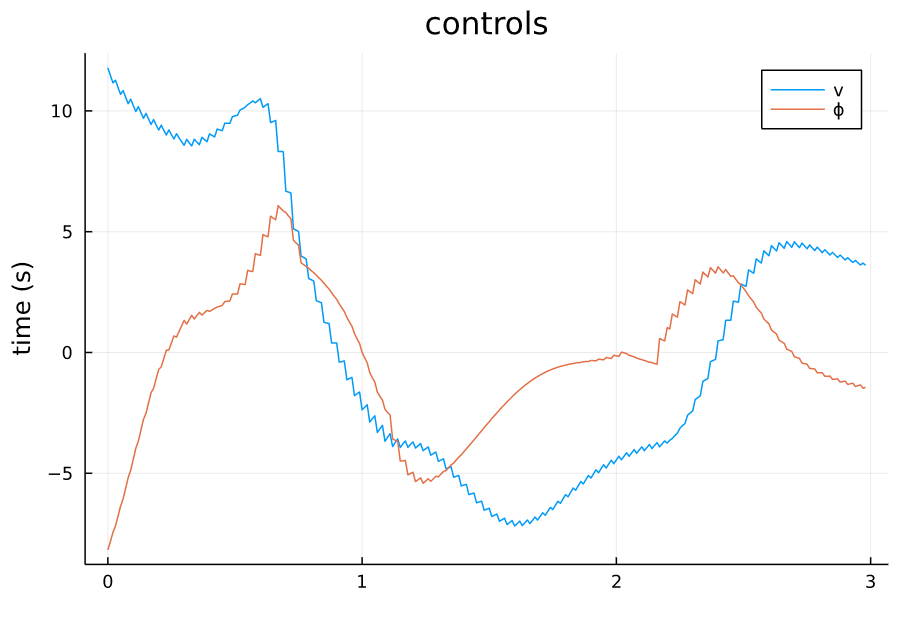
TVLQR 起点(-3,2) |
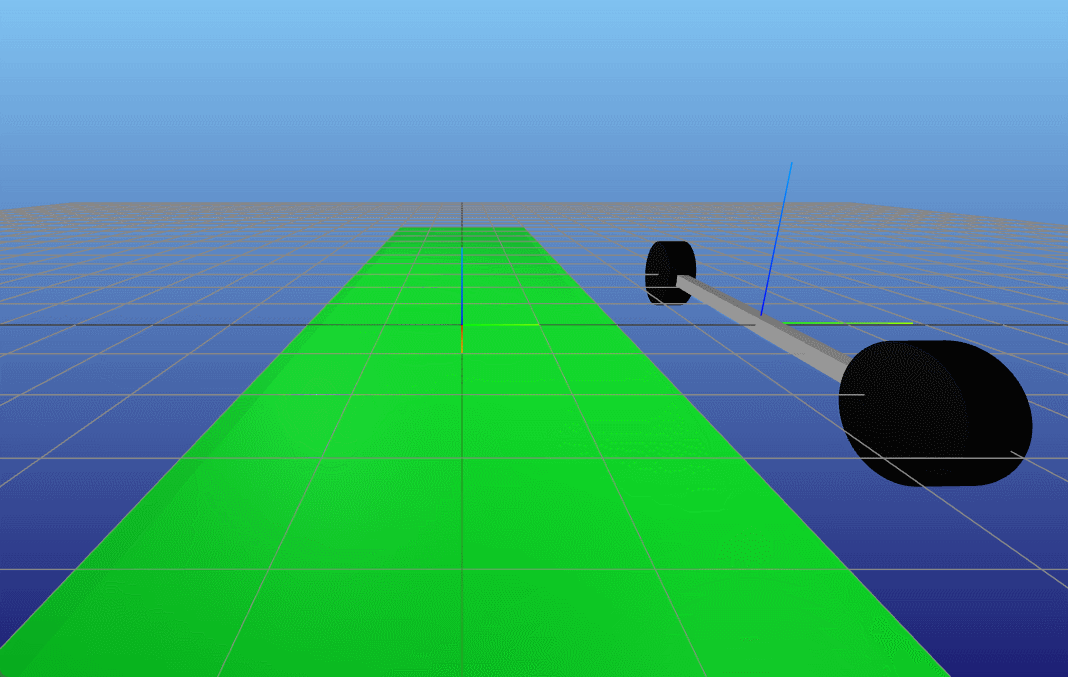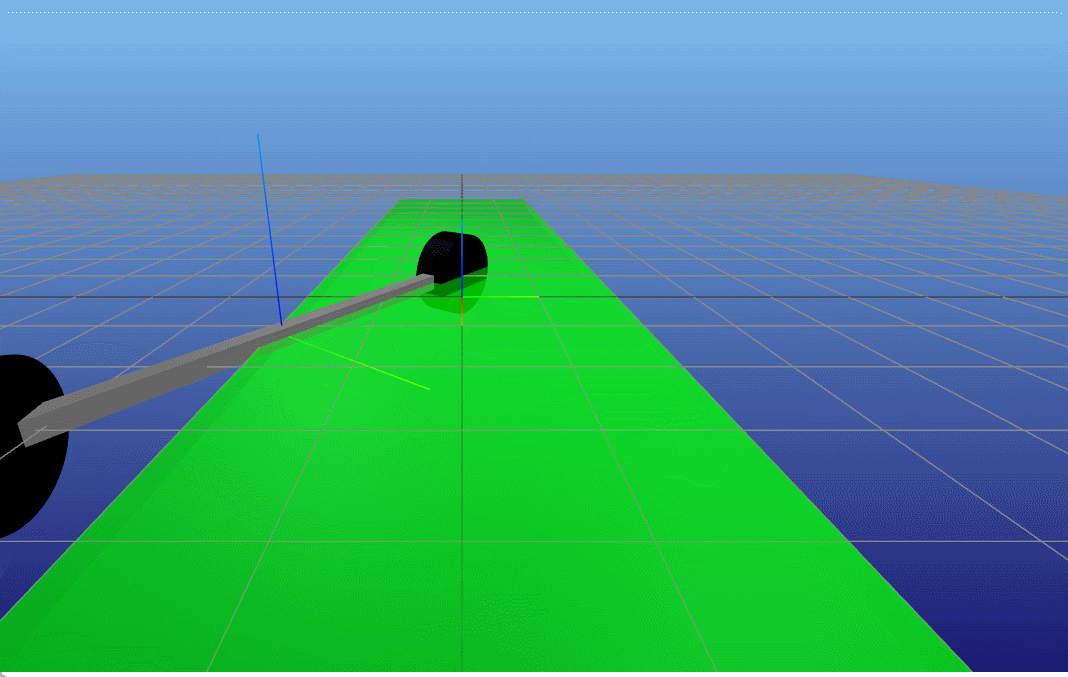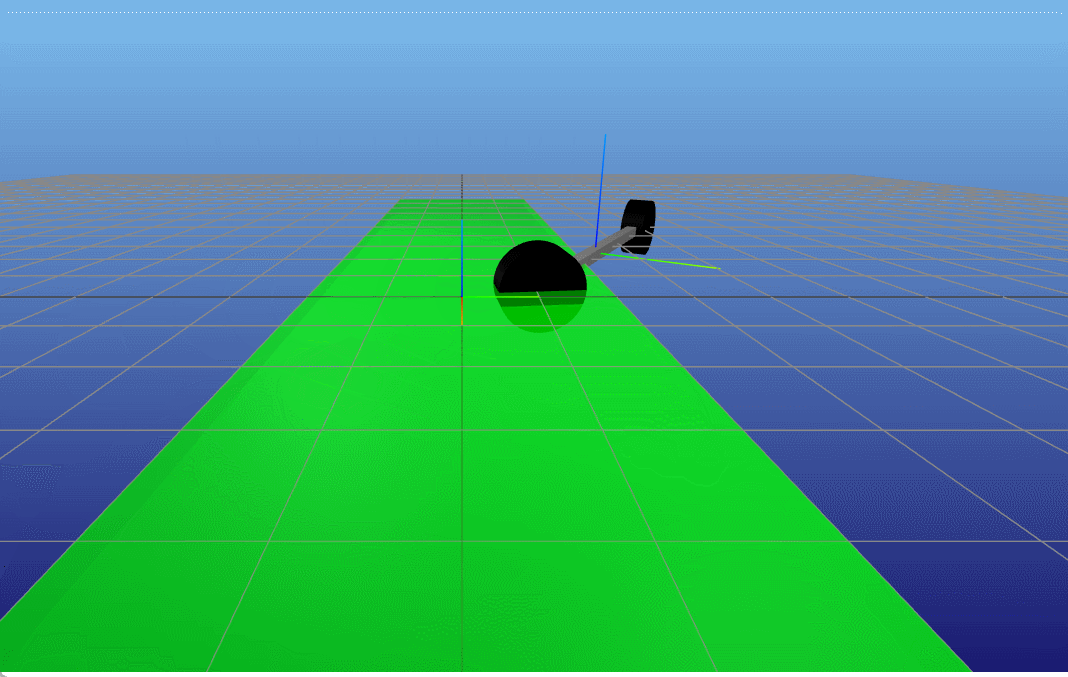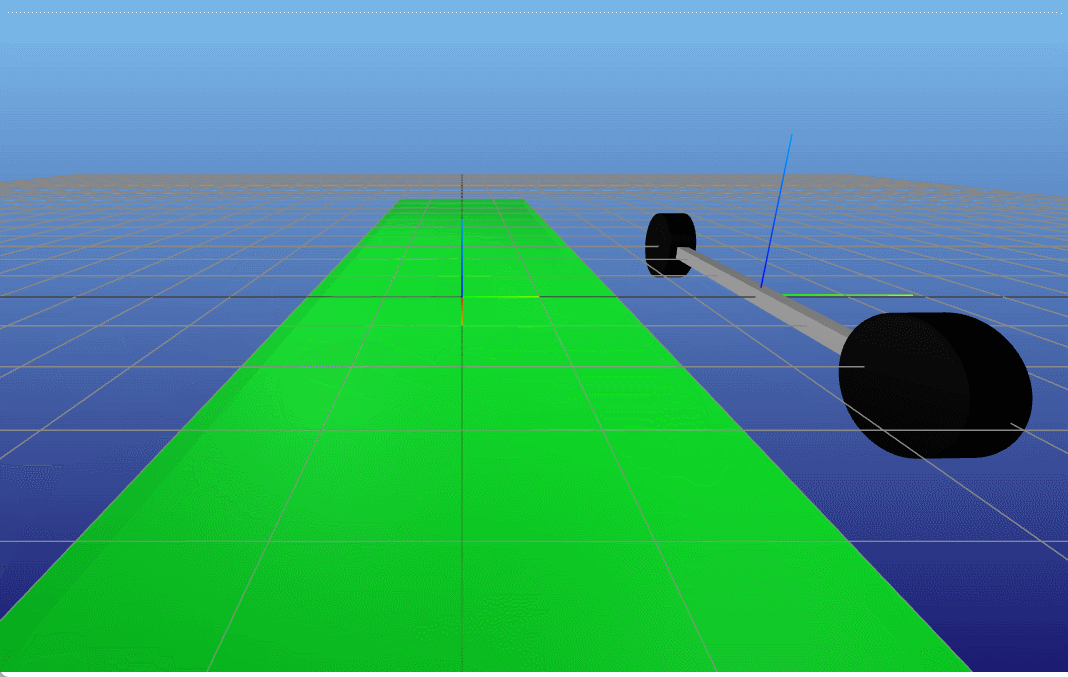
TVLQR 起点(-4,1) |
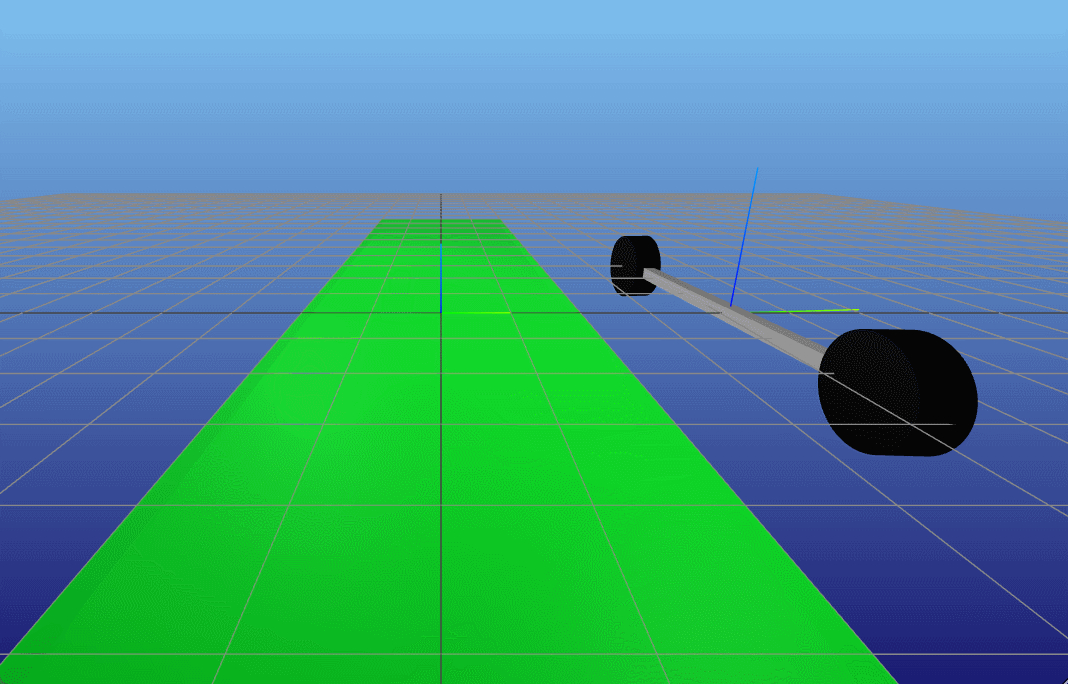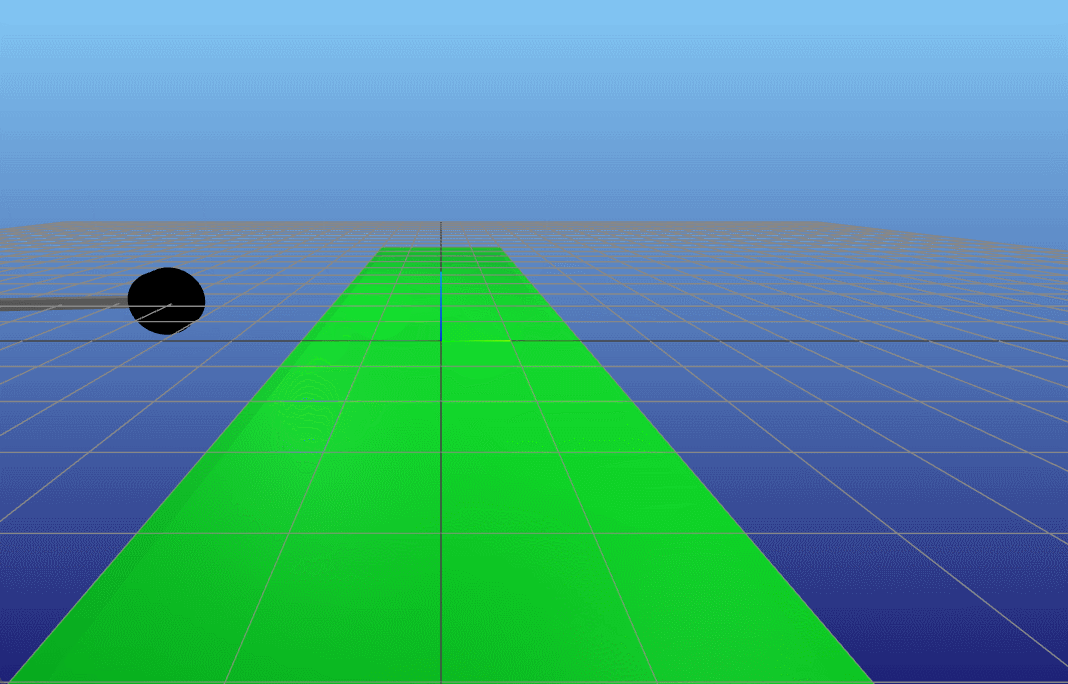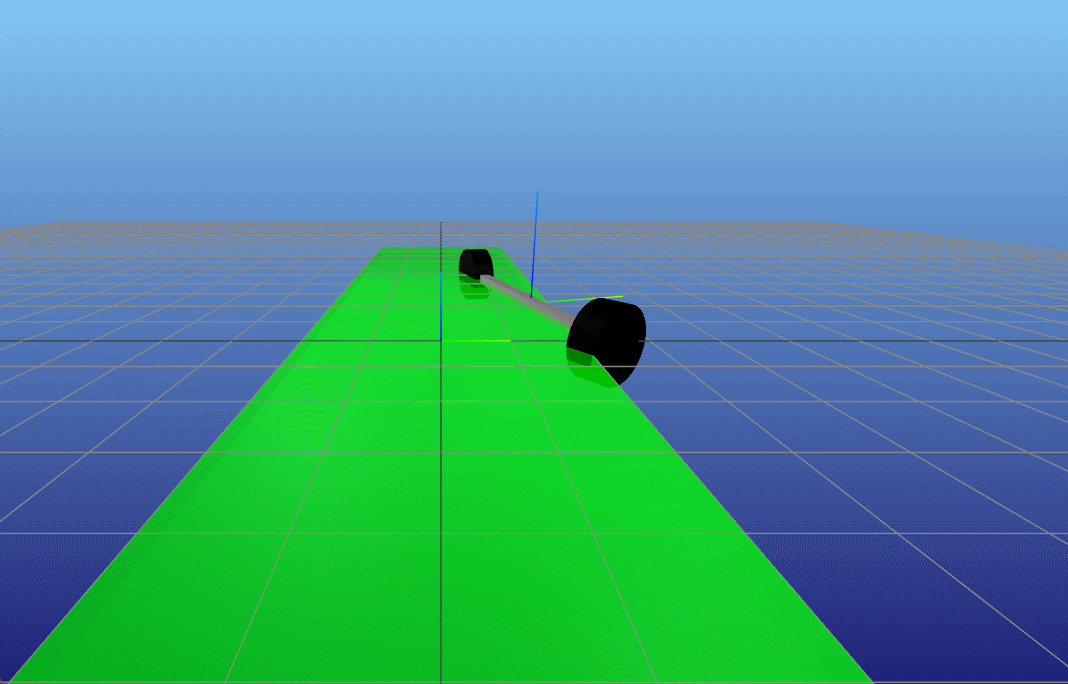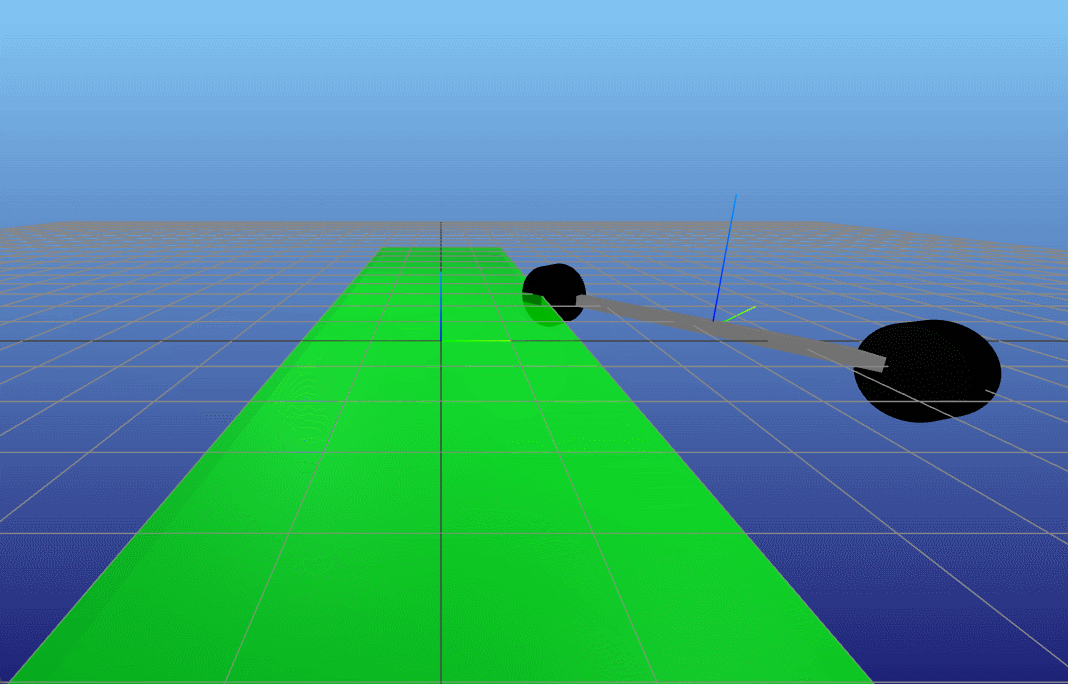
TVLQR 起点(-3,2) |















 1407
1407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









