







文章目录
发展现状
多模态大模型时间发展线
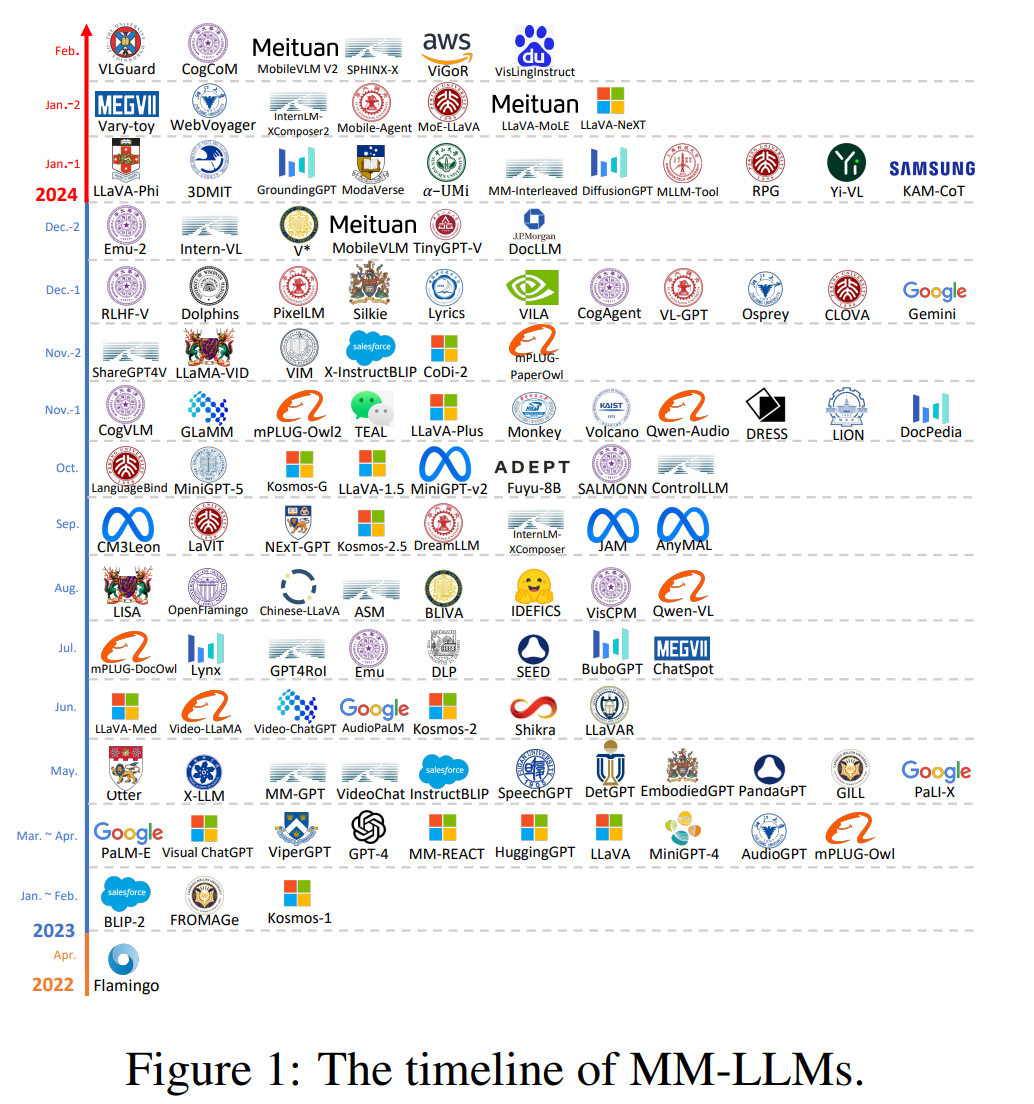
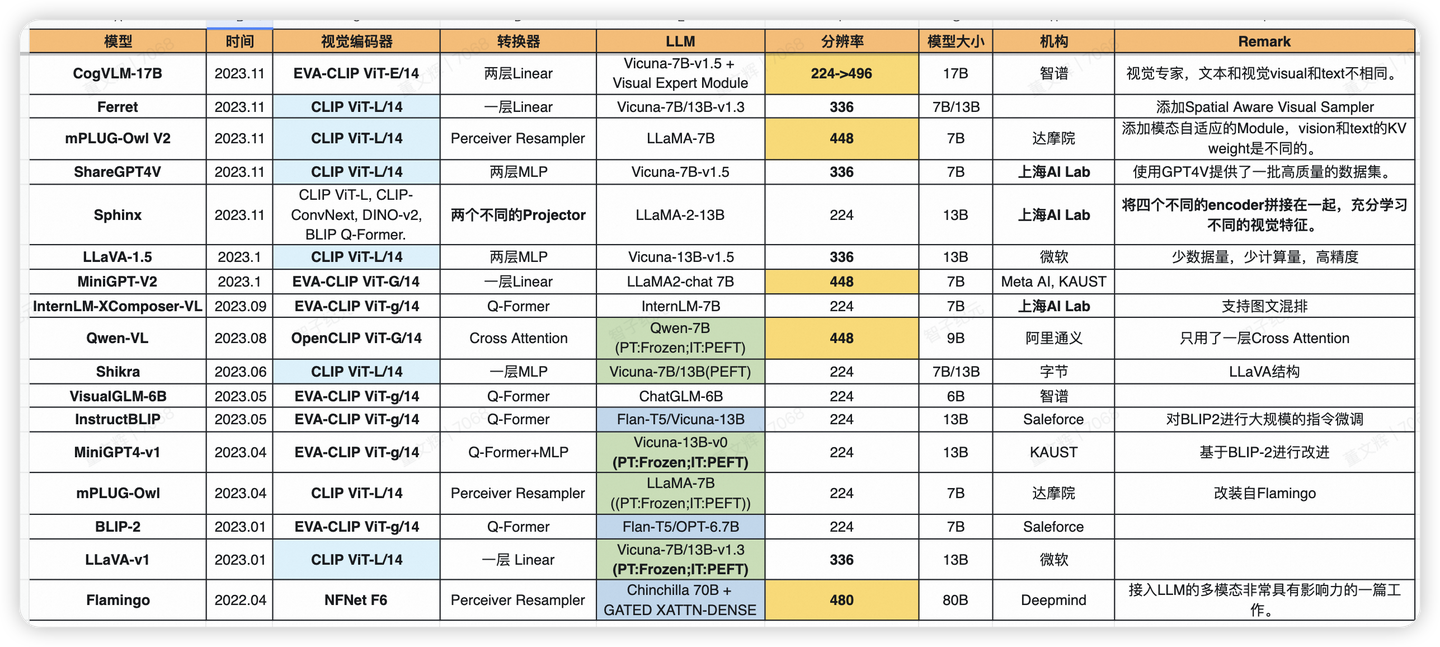
知名多模态大模型的介绍
多模态模型的构成
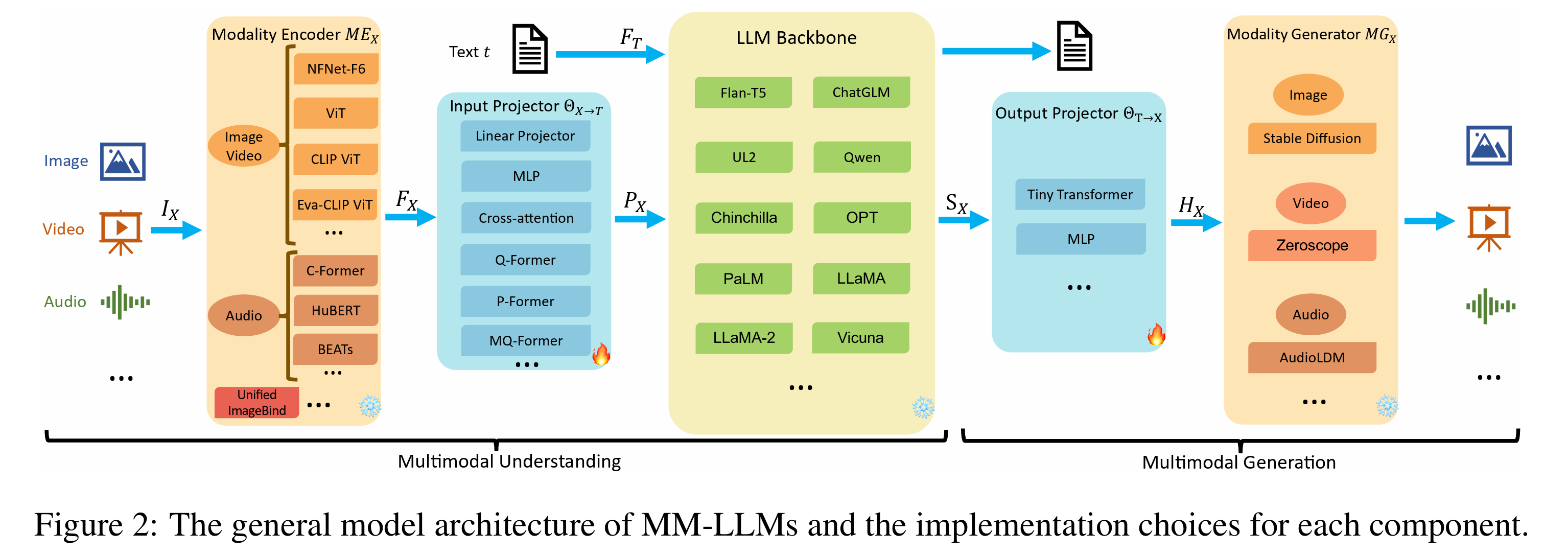
一般的多模态模型包含五大组件:1.模态编码器;2.输入投影器;3.LLM骨干网络;4.输出投影器;5.模态生成器。
在早期的多模态模型训练时,通常是会将模态编码器、LLM骨干网络、模态生成器的参数冻结,只训练输入和输出的投影器部分,投影器部分的参数量占整个模型的参数的比重很小。但是目前的多模态大模型,也会对encoder,甚至是LLM骨干网络进行训练,来提升模型的整体能力。
模态编码器
目的:该部分的主要目的是将不同的模态信息进行encoder,例如对image,video,audio等的编码。
-
视觉编码器:
NFNet-F6、ViT、CLIP-ViT、Eva-CLIP ViT、BEiT-3、Grounding-DINO-T、
DINOv2、SAM-HQ、RAM++、InternViT、VCoder等;
-
语音编码器:
C-Former、HuBERT、BEATs、Whisper、CLAP;
- 通用编码器:ImageBind;
F X = M o d a l i t y E n c o d e r ( I X ) F_X=Modality Encoder(I_X) FX=ModalityEncoder(IX)
输入投影器
目的:该部分的目的是将其他模态编码后的特征与文本特征进行对齐。这里的对齐指的是如何将视觉编码器提取到的特征如何映射到LLM能够处理的特征空间。
LLM是以文本语义为目标进行训练的,而视觉编码器是以视觉语义为目的进行训练的,视觉编码器即便经过了语义对齐,如通过CLIP等方式进行跨模态语义对齐,其语义和LLM之间也会存在较大的区别,如何融合这两种语义信息,是MLLM模型必须解决的问题,
最简单的输入投影器可以采用MLP(Multi-Layer Percepron).
比较复杂的输入投影器:Cross-attention(Flamingo)、Q-Former(BLIP2)、P-Former、MQ-Former ;
P X = θ X − > T ( F X ) P_X=\theta _{X->T}(F_X) PX=θX−>T(FX)
与文本空间特征 F T F_T FT对齐后的 P X P_X PX与 F T F_T FT一同送入到LLM的Backbone网络中。对于给定的多模态数据X{I_x,t}
a r g m i n L t x t − g e n ( L L M ( P X , F T ) , t ) argmin L_{txt-gen}(LLM(P_{X},F_{T}),t) argminLtxt−gen(LLM(PX,FT),t)
LLM骨干网络
MM-LLM 使用 LLM 作为核心智能体,因此也继承了 LLM 的一些重要特性,比如零样本泛化、少样本上下文学习、思维链(CoT)和指令遵从。LLM 骨干网络的任务是处理各种模态的表征,其中涉及到与输入相关的语义理解、推理和决策。它的输出包括 (1) 直接的文本输出,(2) 其它模态的信号 token(如果有的话)。这些信号 token 可用作引导生成器的指令 —— 是否生成多模态内容,如果是,则指定所要生成的内容。
t , S X = L L M ( P X , F T ) t,S_X=LLM(P_X,F_T) t,SX=LLM(PX,FT)
Sx为其他模态的输出特征信号,后续可作为对应模态生成器的输入。
MM-LLM 中常用的 LLM :** Flan-T5、ChatGLM、UL2、Qwen、Chinchilla、OPT、PaLM、LLaMA、LLaMA2、Vicuna。**
输出投影器
将来自 LLM 骨干网络输出的其他模态的信号 token 表征映射成可被后续模态生成器理解的特征。
如何做到的?
模态生成器
生成对应模态的输出。目前的研究工作通常是使用现有的隐扩散模型(LDM),例如使用 Stable Diffusion 来合成图像、使用 Zeroscope 来合成视频、使用 AudioLDM-2 来合成音频。
多模态中的视觉模态的特征表征
视觉模态特征和文本模态如何进行对齐和融合?
对于图文多模态来说,视觉表征有两个方向:CNN系列和ViT系列,二者分别都有各自的表征、预训练以及多模态对齐的发展过程。 CNN 和 ViT 聚合不同类型的视觉特征,CNN更多关注相邻依赖关系,而Transformer则偏向token之间的长距离或者是全局信息的交互。
CNN系
CNN视觉表征
采用CNN来做骨干网络提取图像特征,然后对于不同的视觉任务,骨干网络后接上不同的分类头、检测头等完成具体的视觉任务。经典的骨干网络有:ResNet等。
CNN视觉预训练
在CNN视觉表征体系下,早期的视觉预训练有另一个叫法是迁移学习,在BERT的预训练+微调范式流行之前就已经被广泛应用。迁移学习中,传统CNN视觉模型在做具体任务训练之前,先在大量的图像任务数据集上进行预先训练(如ImageNet分类任务数据集等)。然后使用预训练的CNN权重初始化Backbone,并增加一些任务定制网络模块,完成在下游任务上的微调(如Backbone+全连接层做分类任务)。
CNN体系下的多模态融合和预训练
视觉和文本模态的对齐和融合有两种方式:
1.采用各自模态的经典特征表示方法进行表征,然后通过对比学习的方式来实现视觉和文本在同一空间的距离度量;
2.采用各自模态的经典特征表示方法进行表征,然后通过交互性的网络结构融合成多模态表征;
视觉表征方面,由于CNN已经验证了有效性,大多数的工作在都考虑使用CNN做视觉特征抽取,得到高级语义特征,然后将高级语义表征作为输入,和文本Token Embedding序列一起输入到多模态融合模块。不同工作的差异主要集中在视觉特征提取CNN Backbone以及Modality Interaction两个模块。
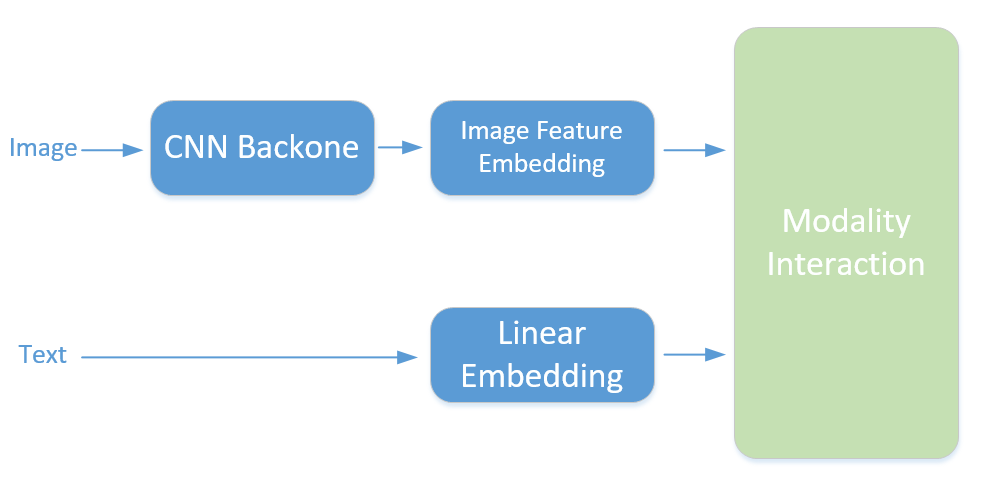
如何对视觉特征进行有效编码?
如何对视觉特征进行有效编码,得到和文本一样的Token Embedding序列作为模型输入?
在CNN体系下,有两种主要的方式:
1.ROI Feature Base: 先通过基于CNN的目标检测识别图像中的关键目标,并提取目标区域的表征作为Transformer模型的视觉输入Embedding序列。这么做的动机是,每个ROI区域,都有明确的语义表达(人、建筑、物品等),方便后续和文本特征的对齐。比较有代表性的工作如LXMERT、VL-BERT和UNITER等;
2.Grid Feature Base: 对关键区域进行表征,虽然理论上比较合理,但是也存在遗漏区域信息,而且比较依赖前置的目标检测模型的准确度。也有一些工作尝试不进行目标检测,直接使用CNN提取到的高层深度特征作为多模态交互中的视觉信息。比较有代表性的工作如Pixel-Bert等。
LXMERT(EMNLP2019)
https://arxiv.org/abs/1908.07490
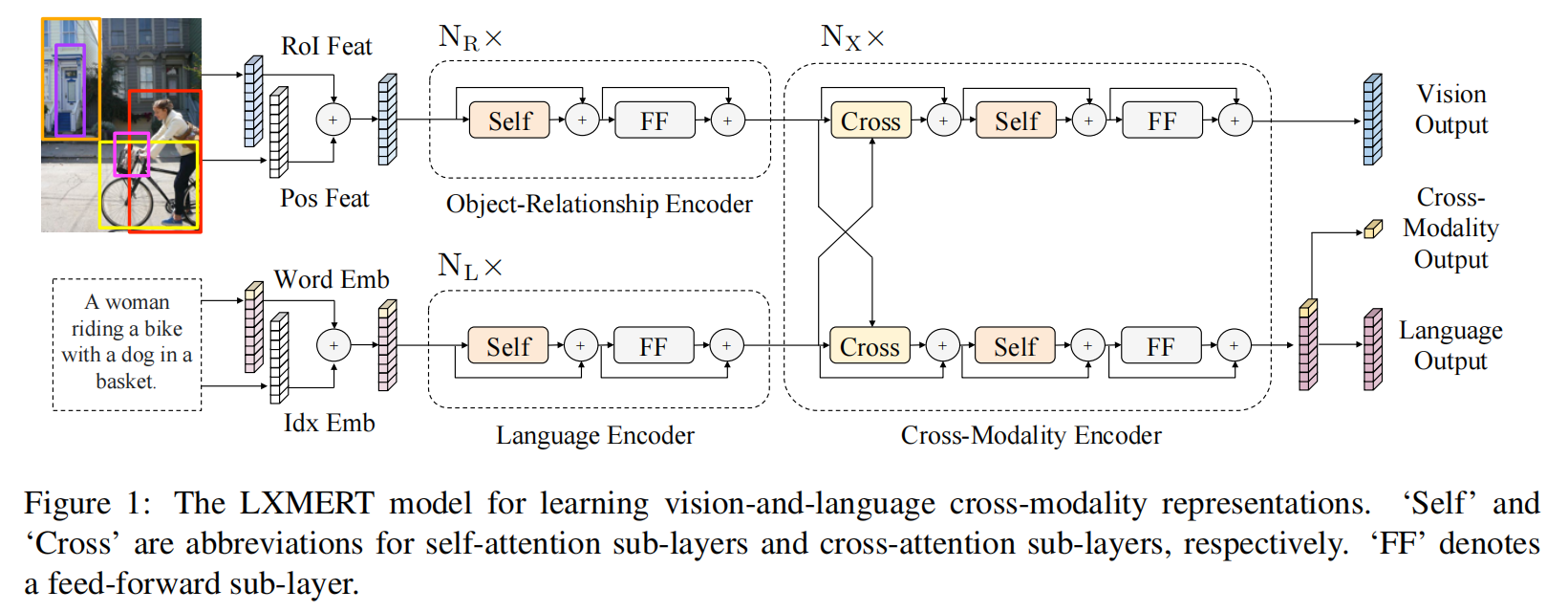
该文是图文多模态经典之作,在模态表征阶段采用二路结构即:视觉模态测采用CNN的目标检测模型得到ROI区域的特征序列,并且通过一个两层的全连接层学习一个位置编码,二者相加后然后经过Transfomrer进行进一步的编码序列token之间的关系(Object-Relationship Encoder);文本模态侧,先将一段句子通过WordPiece tokenizer拆分成子词或者单词,然后对词进行编码和位置编码,相加后得到 index-aware word embedding,最后采用BERT结构对文本序列的token进行编码(language Encoder)。
在模态融合阶段采用深层Transformer结构做交叉Attention,该部分被称为跨模态编码器(Cross-Modality Encoder)。
VL-BERT(ICLR2020)
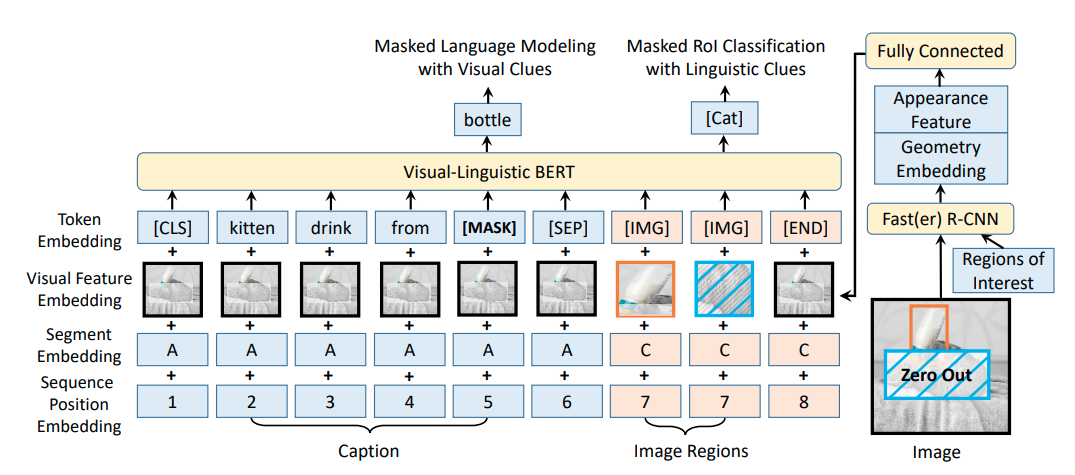
与LXMERT不同的是,VL-BERT属于单路输入模式,视觉特征在经过目标检测模型( Faster R-CNN)进行ROI特征提取后,直接和文本Embedding一起拼接输入到Transformer网络中进行多模态的交叉Attention。
Pixel-BERT
https://arxiv.org/abs/2004.00849
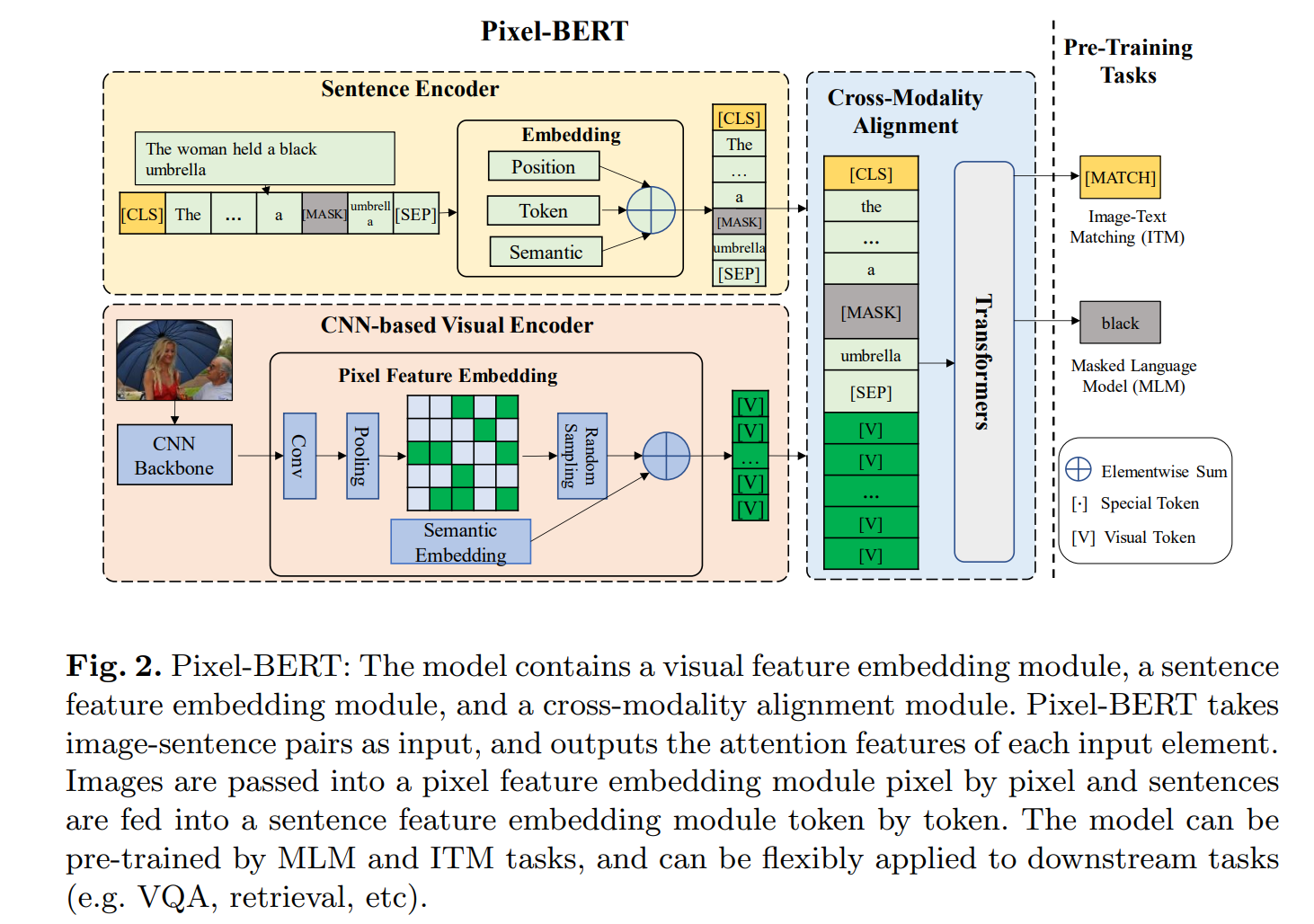
Pixel-BERT不需要使用目标检测模型进行ROI区域的特征抽取,而是直接通过卷积网络提取图片的像素级别特征和文本特征一起输入到下游的Transformer网络进行特征融合。这种不需要依赖目标检测模型,同时也缓解了视觉语义label与文本语义的不均衡问题,因为检测模型网络支持的类别为上千个类别,而文本语义所表达的含义远远超过上千。
多模态中CNN视觉编码器的趋势
在Transformer的encoder的影响下,单独的CNN架构的视觉编码器作为多模态中的视觉处理模块越来越少见了,现在主流的多模态大模型中的视觉编码器大都都采用的ViT架构,或者是采用多个混合的视觉编码器,CNN架构作为其中一个视觉编码器。
多模态中ViT(Transformer)系的视觉编码器
ViT
以ViT为基础的视觉模型可以通过Transformers 中的encoder对视觉进行有效表征,这种方法也逐渐成为目前视觉信息编码的主流手段。
CLIP
CLIP模型是OpenAI 2021发布的多模态对齐方法.其核心思路是通过对比学习的方法进行视觉和自然语言表征的对齐。CLIP使用了一个双塔结构的神经网络,其中一塔是文本编码器,另一塔是图像编码器,分别对文本和图像进行特征抽取,文本侧采用的Encoder为预训练BERT,视觉侧的Encoder可以使用传统的CNN模型,也可是ViT结构,则称为CLIP-ViT。分别得到图文表征向量后,在对特征进行标准化(Normalize)后计算图文Pair对之间的余弦距离,通过Triple Loss或InfoNCELoss等目标函数拉近正样本对之间的距离,同时使负样本对的距离拉远。等训练完成后,视觉侧的 image Encoder就可以作为多模态模型中的视觉编码器。
CLIP简洁原理:
用图像编码器把图像编码成向量 a; 用文本编码器把文本编码成向量 b; 计算 a·b, 如果 a 和 b 来自一对儿配对的图和文字,则让 a·b 向 1 靠近; 如果 a 和 b 来自不配对儿的图和文字,则让 a·b 向 0 靠近;
CLIP** 用途:**
根源用途: 把图片和文字编码到同一空间,计算图像和文本的语义相似度; 扩展用途: 1)图文搜索(根据图像搜索对应文本、或根据文本搜索对应图像); 2)协助完成相关的多模态任务(例如在 Stable Diffusion 里作为文本编码器); 3)作为评测工具(例如文生图任务中,计算生成图像与文本之间的相似度)
CLIP运行时的图像和文本数据流变化:

Eva-CLIP ViT
https://arxiv.org/abs/2303.15389
用最新的表征学习, 优化策略,增强 使得EVA-CLIP在同样数量的参数下比之前的CLIP模型要好,且花费更小的训练资源。
CLIP是一个强大的视觉-语言基础模型,通过对比图像-文本预训练来学习丰富的视觉表示。但训练CLIP模型面临高计算成本和训练不稳定的挑战。EVA-CLIP提出了一系列技术来显著降低训练成本、稳定训练过程并提高零样本性能。
具体采用的技术如下:
- 初始化:使用预训练的EVA模型来初始化CLIP的图像编码器,加速收敛并提高特征表示;
- 优化器(https://arxiv.org/abs/1904.00962):使用LAMB优化器,专为大批量训练设计,通过自适应元素级更新和层级学习率来提高训练效率;
- 高效训练(https://arxiv.org/abs/2212.00794):Fast Language-Image Pre-training (FLIP),是一种高效的语言视觉模型训练方法,在训练的过程中随机地mask部分图像块,不仅能提高模型的学习能力,而且这样占用的空间和计算量就会减少,batch_size就可以设置的更大;
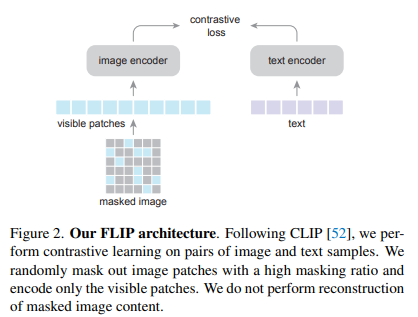
- flash attention(https://arxiv.org/pdf/2205.14135.pdf) :通过优化注意力机制的计算过程来减少内存占用和加速训练过程。
CLIP、Eva-CLIP和openCLIP的区别
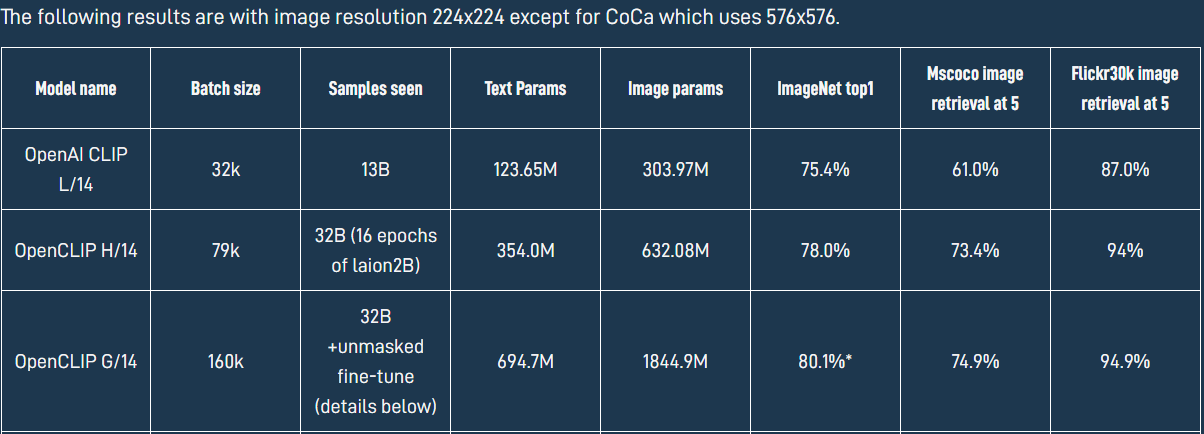
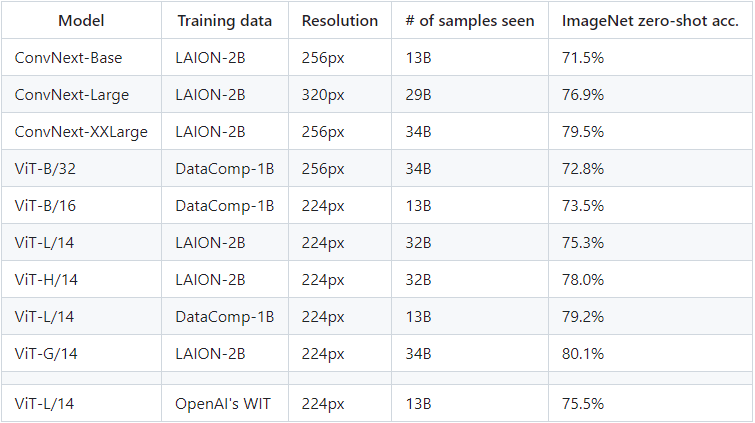
| 模型 | 时间 | 机构 | 介绍 | 源码 |
|---|---|---|---|---|
| CLIP | 2021年初 | OpenAI | 利用4亿张互联网上找到的图文对WebImageText (WIT)训练的图文多模态模型,核心思想是将视觉和语言的表示方式相互联系起来从而实现图像任务。CLIP模型由两个主体部分组成:Text Encoder和Image Encoder。这两部分可以分别理解成文本和图像的特征提取器。 | https://github.com/OpenAI/CLIP。 |
| OpenCLIP | 2022 年 9 月 | LAION | LAION机构利用AION-5B 数据集的子集对CLIP论文完成了开源实现即OpenCLIP。训练了三个大型 CLIP 模型:ViT-L/14、ViT-H/14 和 ViT-g/14(与其他模型相比,ViT-g/14 的训练周期仅为三分之一左右),OpenCLIP原理和CLIP一样,只是在不同数据集上的实现。在 ImageNet数据集上,原版CLIP的准确率只有75.4%,而OpenCLIP实现了80.1% 的zero-shot准确率,在 MS COCO 上实现了74.9% 的zero-shot图像检索(Recall@5)。 | https://github.com/mlfoundations/open_clip |
| Eva-CLIP | 2023年3月 | 北京人工智能研究院和华中科技大学 | 旨在提高大规模训练时的效率和效果。通过结合新的表示学习、优化和增强技术,实现了与具有相同参数数量的先前CLIP模型相比更优的性能,同时显著降低了训练成本。 | https://github.com/baaivision/EVA/tree/master/EVA-CLIP |
总结:
CLIP是指CLIP模型本身,而OpenCLIP则是指CLIP模型的开源实现。两者有着紧密的联系,OpenCLIP是对CLIP模型的应用和推广,使更多的人可以使用CLIP模型进行相关的研究和开发。Eva-CLIP则是利用一些最新的训练技术、数据masked增强和高效计算等方法进一步提高了CLIP的性能。
DINOv2-ViT
DINOv1:https//arxiv.org/pdf/2104.14294.pdf
DINOv2:https://arxiv.org/pdf/2304.07193.pdf
DINOv1 是一种用于自监督视觉学习的深度学习模型,于 2021 年由 Meta 提出。DINO 是最先探讨基于Transformer 架构的自监督学习代表作之一,其通过在无标签图像上进行自监督训练来学习视觉特征表示。
DINOv1 是采用自蒸馏(self-distillation)的方法学习的,其整体框架包含两个相同的架构,分别为教师网络和学生网络,具体的架构可以是 ViT 等 vision transformer 或者是 ResNet 等 CNNs 特征提取器。通过论文中的消融实验表明还是 ViT 的潜力更大。首先,作者使用了多种数据增强策略得到不同的视图,从给定的图像中生成一组不同视图 。这个集合包含两个全局视图 和 以及几个分辨率较小的局部视图。所有局部视图输入给学生模型,全局视图输入给教师模型。分辨率为 224×224 的2个全局视图覆盖原始图像的大 (比如大于 50%) 部分区域,分辨率为 96×96 的局部视图仅仅可以覆盖原始图像的小区域 (比如小于 50%)。两个网络具有相同的架构但参数不同。教师网络的输出通过一个 Batch 的平均值进行 centering 操作,每个网络输出一个 K维的特征,并使用 Softmax 进行归一化。然后使用交叉熵损失作为目标函数计算学生模型和教师模型之间的相似度。在教师模型上使用停止梯度 (stop gradient, sg) 算子来阻断梯度的传播,只把梯度传给学生模型使其更新参数。教师模型使用学生模型的 EMA 进行更新。
DINOv2作为一种先进的自监督学习模型,能够在没有人工标注的情况下,从海量图像数据中提取出鲁棒性强的视觉特征,为各种下游任务如分类、分割、图像检索和深度估计等提供了强大的支持。主要是借鉴最近在自然语言处理方面的一些技术和进展,如语言模型的预训练,可以更好地理解语言信息。
Grounding-DINO
https://arxiv.org/abs/2303.05499
开放世界图像目标检测模型来对视觉图像进行表征。
在Grounding DINO中,作者想要完成的任务是根据人类文字输入去检测任意类别的目标,这被称作开放世界目标检测问题(open-set object detection)。
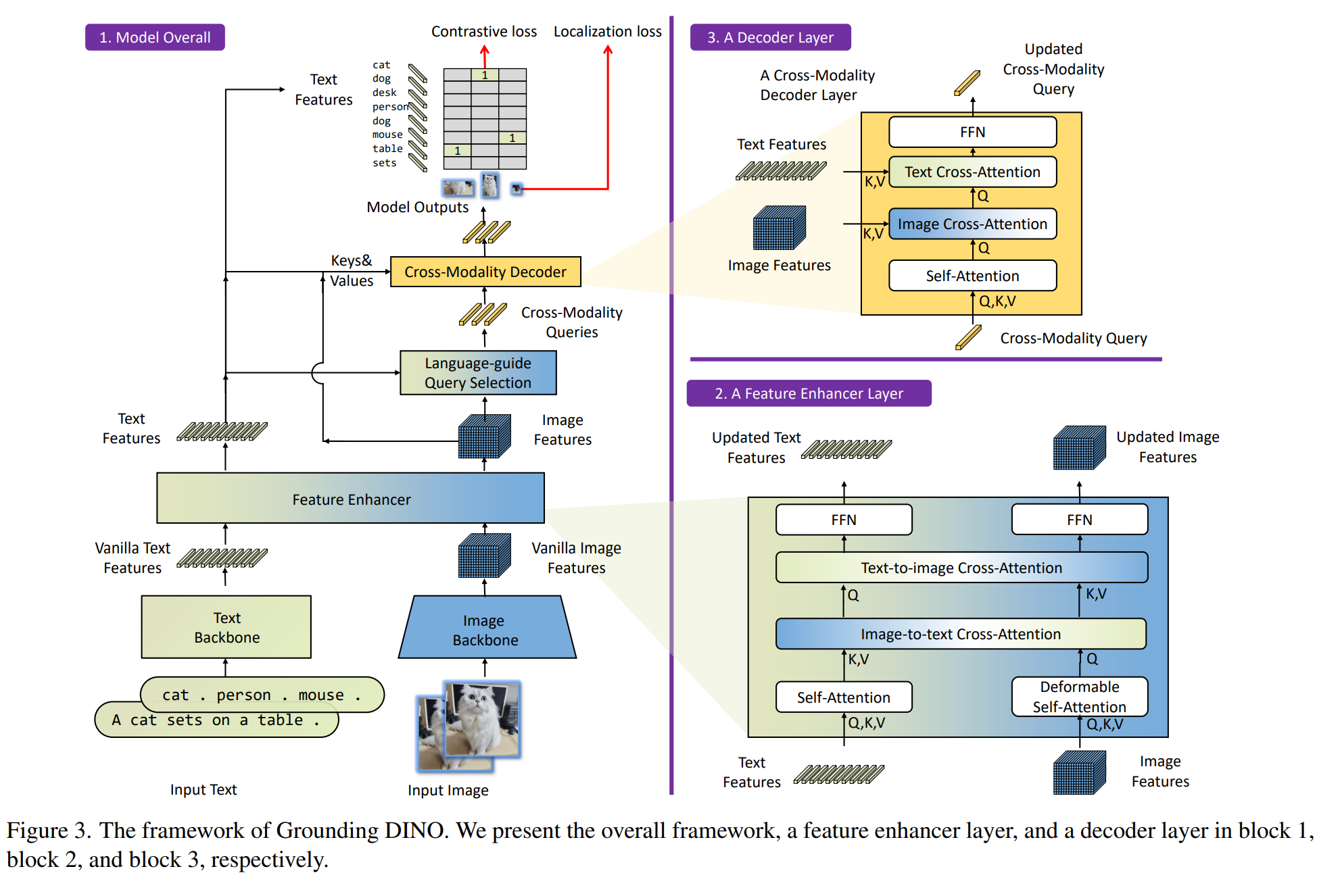
在特征提取方面,作者采取Swin Transformer作为image backbone,BERT作为text backbone。像DETR系列模型中设计的那样,image backbone提取了multi-scale的图像特征。提取完image features和text features后,作者将它们输入到一个feature enhancer中以融合跨模态特征。采用L1 loss和GIOU loss用作box regression,计算预测目标和文字token之间的contrastive loss用于分类。在完成跨模态的的开放世界目标检测任务训练后,其中的图像编码器可用来做多模态大模型中的图像编码器。
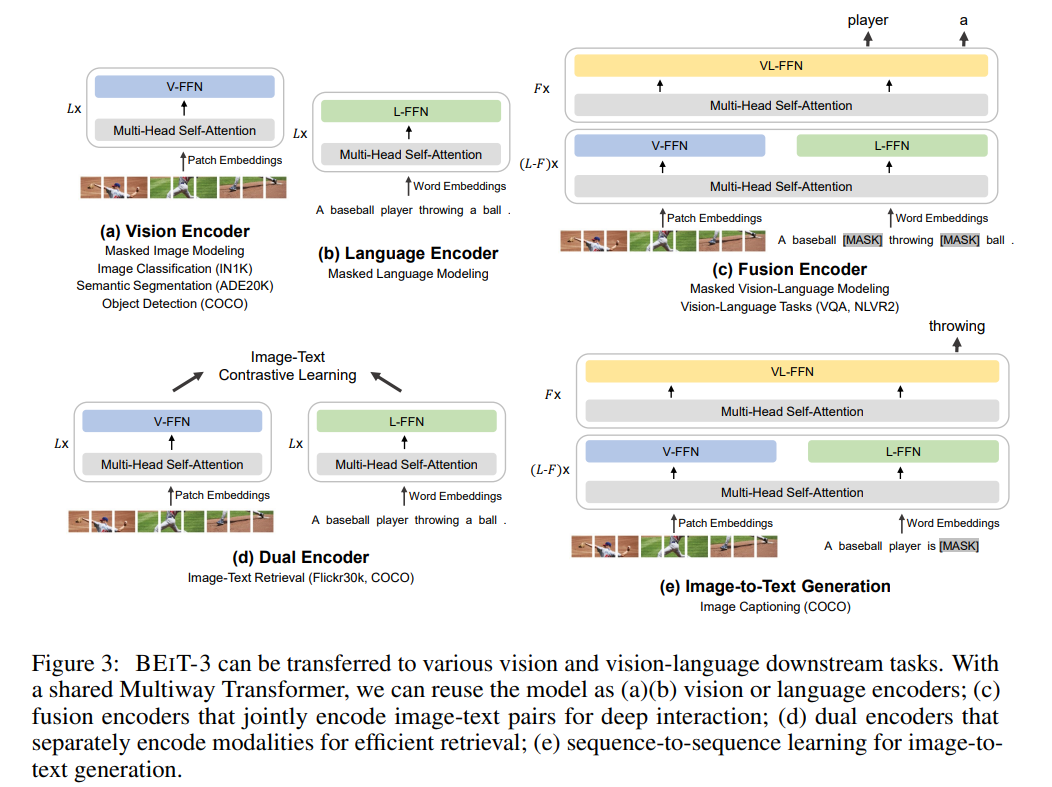
BEiT-3
http://arxiv.org/pdf/2208.10442.pdf
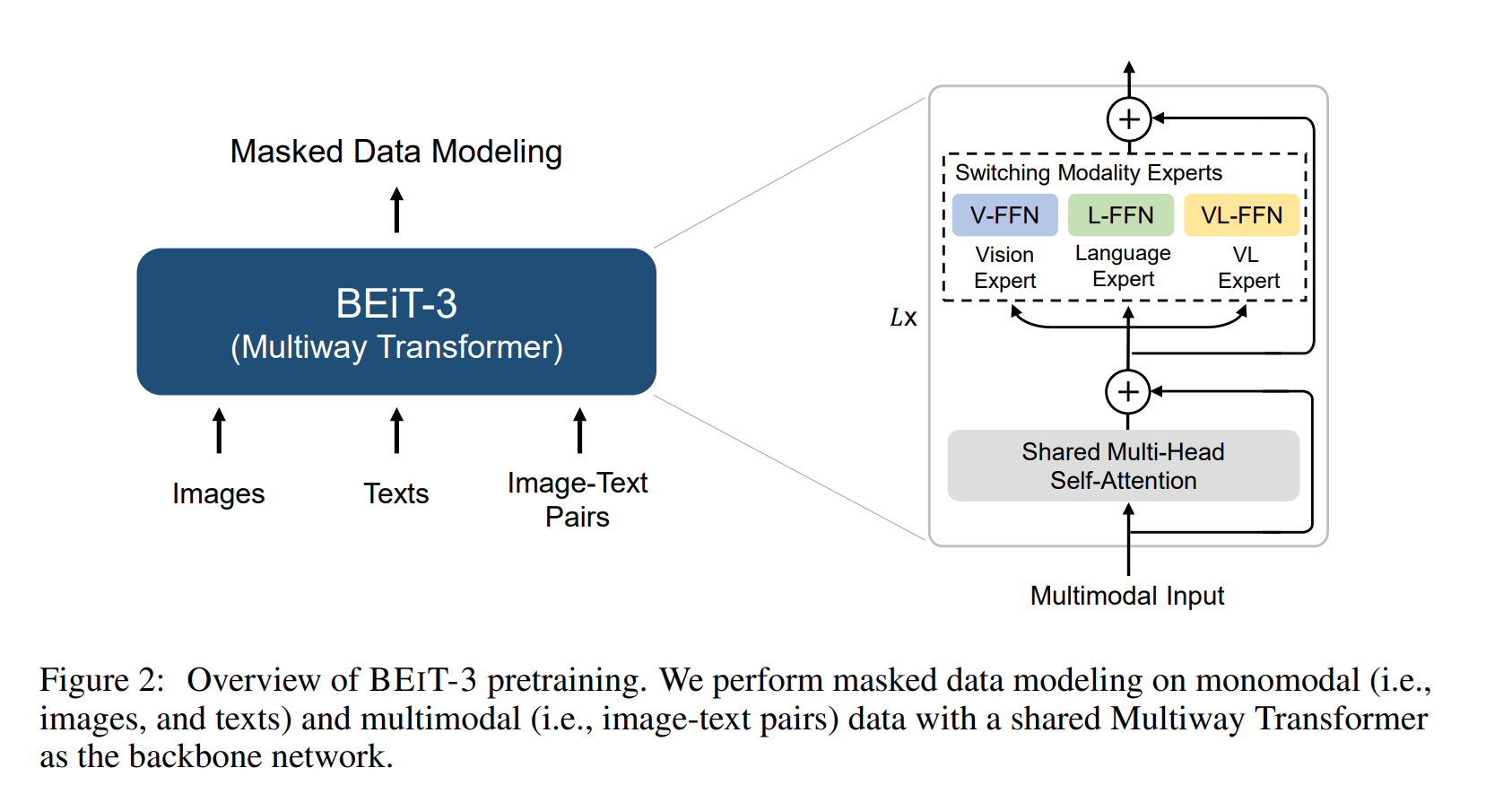
BEiT-3使用掩码数据建模的训练方式,借助 Transformer 这一方便处理图片和文本的模型架构,统一进行训练,在多个纯视觉任务和视觉-文本任务中都取得了 SOTA 性能。关键词就是:大一统,用一个模型架构和一个训练任务,打造出多模态领域的集大成者。即视觉的表征,文本的表征和多模态的表征都采用Transformer架构。
那么BEiT-3是如何用一种结构对文本、图像、多模态进行编码呢?Transformer中的encoder部分包含了两个核心部分:Self-Attention和FFN。所有模态都共享其中的Self-Attention部分的参数,然后根据模态的不同,采用不同的FFN:Vision FFN,Language FFN 和 Vision-Language FFN 。后续根据不同的下游任务,可进行组合,如下图所示。
SAM-HQ
https://arxiv.org/abs/2306.01567
图像分割一切模型(Segment Anything Model)来对视觉图像进行表征。
RAM++
图像识别一切模型来对视觉图像进行表征。
Recognize Anything识别任何事物模型(RAM):一个用于图像标记的强大基础模型。
Swin-transformer作为图像编码器,因为它在视觉语言和标记领域都表现出比 ViT 更好的性能。用于文本生成的编解码器是12层transformer,标签识别解码器是2层transformer。我们利用CLIP中的现成文本编码器并执行提示合成以获得文本标签查询。采用 CLIP 图像编码器提取图像特征,通过图文特征对齐进一步提高了模型对未知类别的识别能力。
RAM具有识别能力,本质上是图片标记任务(image tagging),是一个增强型的 Tag2Text,分割一切模型(SAM)的Zero Shot能力很强,但其只有定位能力(location),没有识别能力(SAM只能给出分割Mask,没法指定该Mask的类别)。因此RAM旨在于提供强大的识别能力(包含Zero Shot的识别能力)。作者也将RAM和定位模型(SAM、Grounding-DINO)进行了结合,具体在Grounded-SAM项目中,这样就能同时达到定位+识别了。
InternViT
https://arxiv.org/abs/2312.14238
在线测试:https://internvl.opengvlab.com/
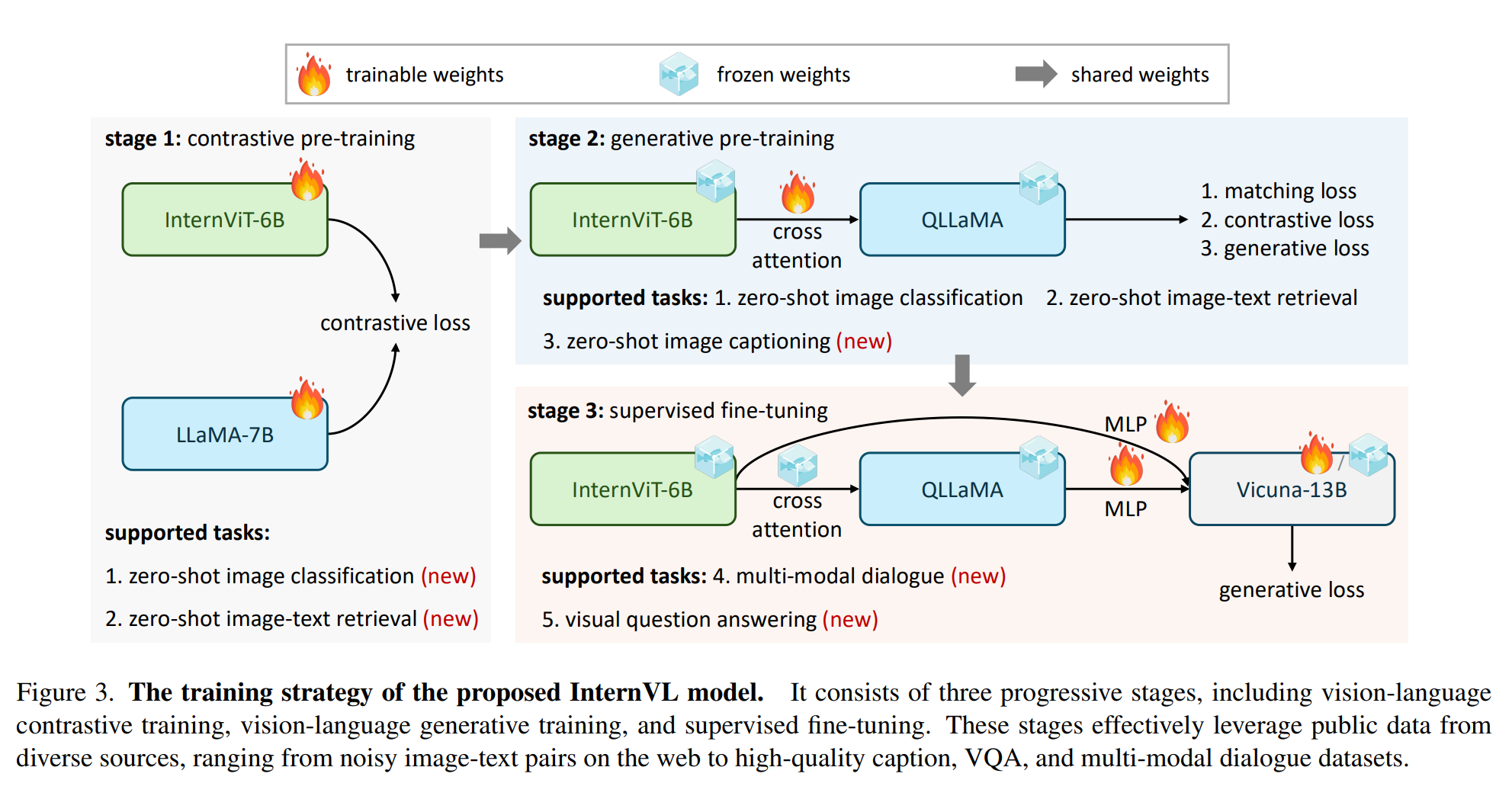
设计了一个大规模的视觉-语言基础模型(InternVL),将视觉基础模型(视觉编码器)的参数扩展到60亿,并逐步与LLM对齐,利用来自不同来源的网络规模的图像-文本数据。该模型可广泛应用于32个通用视觉-语言基准,包括图像级别或像素级别的识别等视觉感知任务,以及零样本图像/视频分类、零样本图像/视频-文本检索等视觉-语言任务,并与LLM相结合以创建多模式对话系统。它具有强大的视觉能力,可以成为ViT-22B的良好替代品。
提出的InternVL采用了一个视觉编码器InternViT-6B(ViT)和一个语言中间件QLLaMA。具体地,InternViT-6B是一个具有60亿参数的视觉Transformer,通过自定义,实现了性能和效率之间的良好平衡。QLLaMA是一个具有80亿参数的语言中间件,初始化使用多语增强的LLaMA。它可以为图像-文本对比学习提供稳健的多语言表示,或者作为连接视觉编码器和现成的LLM解码器的桥梁。
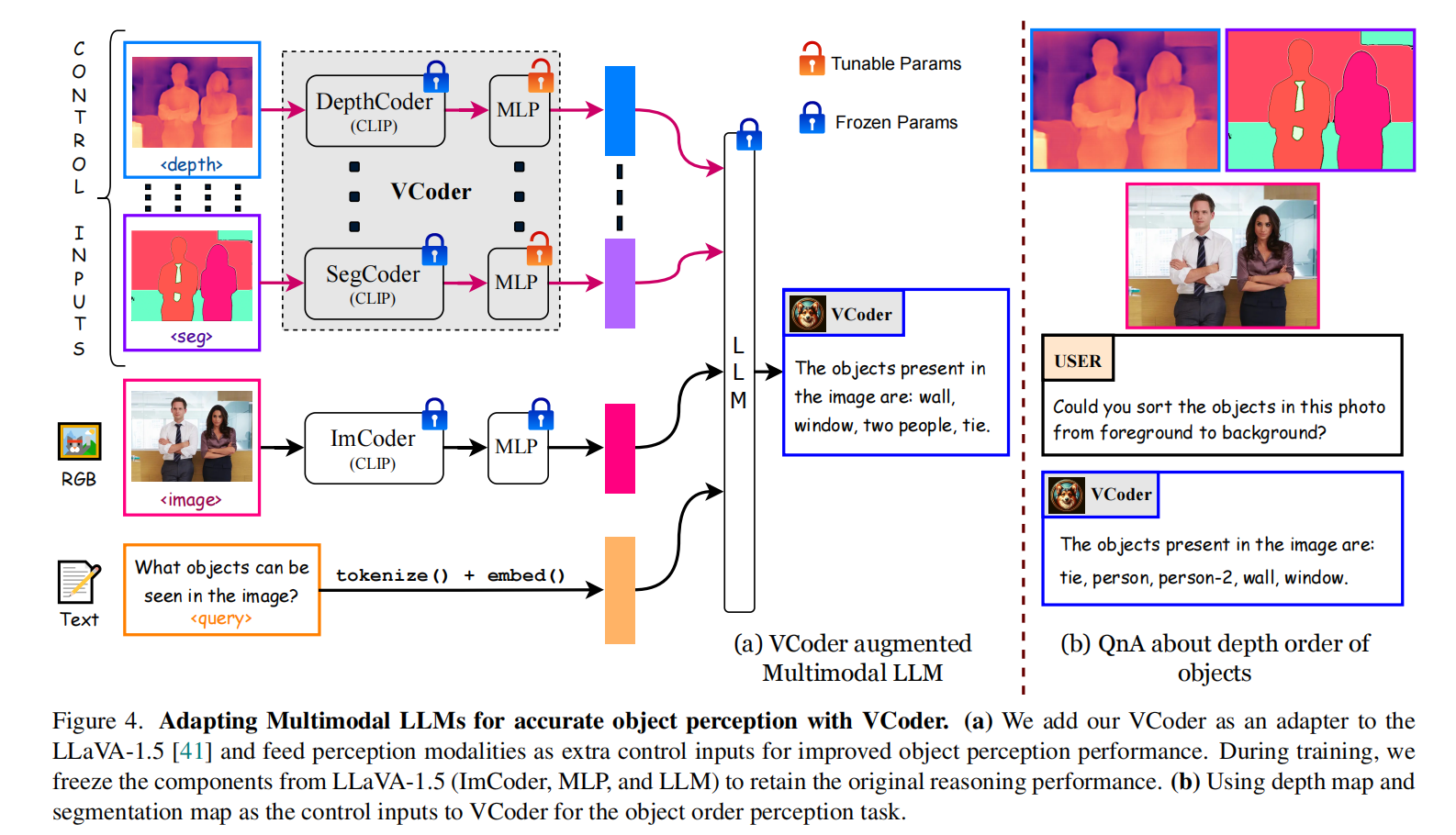
VCoder(CVPR 2024)
https://praeclarumjj3.github.io/vcoder/
提出多功能视觉编码器(VCoder)作为多模态LLM的视觉感知。与之前的多模态视觉编码不同,VCoder不仅对RGB图进行视觉编码作为输入,还通过图像分割模型和图像深度检测模型获取分割图和深度图对其进行编码作为视觉输入的一部分,提高了MLLM对图片的对象级别感知能力。视觉编码器部分其实采用的还是CLIP中 pretrained ViT。
多模态中图像的分辨率
在训练多模态大模型时,通常都需要冻结住预训练的视觉编码器,为了保留原始预训练的视觉编码器对图像的感知能力,一般都采用224x224大小的分辨率作为多模态大模型的输入分辨率。
直接输入高分辨图像一般是不可取的,原因如下:
- 为了对齐图像大小,需要对 ViT 中预训练的位置编码矢量进行相应的上采样,这会损害先前的空间能力。
- ViT 的计算复杂度与输入图像大小呈二次方关系,因此直接上采样会导致推理时间和 GPU 显存消耗的增加。
Sphinx
LLaVA-UHD
https://arxiv.org/pdf/2403.11703.pdf
InternLM-XComposer2-4KHD
相比于其他多模态大模型不超过1500x1500的分辨率限制,该工作将多模态大模型的最大输入图像提升到超过4K (3840 x1600)分辨率,并支持任意长宽比和336像素~4K动态分辨率变化。
https://mp.weixin.qq.com/s?__biz=MzIzNjc1NzUzMw==&mid=2247726125&idx=3&sn=1f94e3250bdb2f393f8a03b57a5873c2&chksm=e9bf73f793ddfd0177cb8cede02ba16d25a23d17784378147bd684070657e29a8180478dbea9&scene=132&exptype=timeline_recommend_article_extendread_samebiz&show_related_article=1&subscene=132&scene=132#wechat_redirect
多模态中视觉编码器的优劣势和趋势
总结
19年20年的时候,早期的多模态工作采用了Object-Text对来提升多模态模型对图片的理解能力。Object detection的引入,不可避免的需要一个笨重的检测器,去检测各种框,使得视觉编码器显得比较笨重。而且检测器模型不可避免的会存在漏检的问题。
到了21年22年,去掉检测器成了主流,ViLT,ALBEF,VLMo,BLIP 等等都抛弃了检测器,彻底摆脱了CNN网络,全面拥抱Transformer,当然这也得益于本身ViT模型在CV领域的大放光彩,让视觉模态和文本模型的有机融合成为了可能。ViT系列视觉编码器,其相同点是网络结构基本都是采用Transformer中的Encoder,不同的在于这些编码器是如何进行预训练的,又或者是信息的颗粒度不同。
原始的ViT是做图像分类任务的,在大规模的图像数据上进行了训练学习到了如何提取图像的有效特征能力,但这时并没有将图片和文字进行联系;而CLIP是通过图文pair对进行预训练的,那它的视觉编码器部分就融入一部分对文本相关的理解;而DINO系列则是采用自监督和蒸馏的方式来让其学生网络充分学习到对视觉编码的能力。Grounding-DINO则增加了文本编码器部分与其视觉编码器进行交互,以达到可以进行开放世界的目标检测任务,待训练完成后,其视觉编码器可以用来作为多模态模型中的视觉编码。BEiT-3的视觉编码器、文本编码器采用统一的Transformer架构,共享Self-Attention部分的参数,只是其中的FFN部分有各自的参数,其视觉编码器也拥有了一部分对文本信息的理解能力。SAM-HQ和RAM++则是利用其对图像的分割能力和识别能力做视觉编码。VCoder则为了提升多模态大模型对图像的目标感知能力,不仅将RGB作为视觉信息输入,同时也将分割图或者是深度图也作为视觉信息的一部分。
现在也有多模态大模型中的视觉编码器采用多个视觉编码器进行集成。将多个encoder进行拼接,来实现更高的性能,如:
**Sphinx(2023,),**其视觉编码器采用了 4 个模型,分别为 CLIP-ViT、CLIP-ConvNeXt、DINOv2-ViT 和 BLIP2 Q-Former。为什么要采用不同的视觉encoder?作者的解释:
- 模型结构不同: CNN 和 ViT 聚合不同类型的视觉特征,即相邻依赖关系和远程交互。
- 不同的预训练范式: 监督训练可以从文本描述或类别标签中加强显式语义信息,而自监督(DINOv2)则强制模型探索隐式信息。
- 信息粒度不同:CLIP-ViT、CLIP-ConvNeXt、DINOv2-ViT 都在 Patch 级别产生视觉 Token,BLIP2 Q-Former 通过 Query 从全局上下文中总结视觉 embedding。
**DeepSeek-VL(2024,https://arxiv.org/abs/2403.05525),**其视觉编码器采用了混合视觉编码器,并且可以对高分辨图像进行编码;
对比
| 多模态中视觉编码器的预训练方式 | 多模态中的视觉编码器 | 优劣势 | |
|---|---|---|---|
| 视觉表征训练(即仅采用图像进行训练) | ViT | 其是图像分类模型,利用其在大规模的图像数据集上训练后获得对图像特征抽取的能力来对图像进行编码; | |
| DINOv2 | 自监督学习模型,能够在没有人工标注的情况下,从海量图像数据中提取出鲁棒性强的视觉特征;其优势在于训练数据的获取成本比较低; | ||
| SAM-HQ | 万物分割模型,采用其作为多模态的视觉编码器,能够提高多模态模型对图像中的目标感知能力; | ||
| 多模态预训练 | CLIP | 通过对比学习的方法进行视觉和自然语言表征的对齐。训练完成后其视觉编码器对图像进行编码的特征在一定程度上拥有一定的文本模态的信息; | |
| ENV-CLIP-VIT | 即采用一些增强和优化策略,视觉编码器的网络结构采用ViT的结构,其性能更好于CLIP; | ||
| BEiT-3 | 大一统架构;即视觉模态和文本模态都采用的Transformer架构,共享其中的self-attention模块,但是各自拥有其FFN模块;好处是实现了架构上的统一; | ||
| RAM++ | 识别万物模型(可以对图片中所有的元素给出标签),利用其能识别万物的视觉编码能力作为多模态的视觉编码器; | ||
| InternViT | 超大的视觉编码器InternViT-6B,通过一个语言中间件QLLaMA将视觉编码器和LLM进行对齐; | ||
| Vcoder | 多输入的视觉编码器,不仅采用RGB,也输入分割图和深度图,可以显著提高多模态模型对图像的目标感知能力,但是同时也导致了视觉编码器的臃肿和计算量提升; | ||
趋势:
- 如何对大分辨图像进行编码;
- 混合视觉编码器,提高多模态模型对视觉图像的感知能力;
- 如何对视频信息进行更加高效的编码,同时能减少模型的计算量;
- 多模态中面对的挑战就像是需要处理和理解来自世界各地、不同设备拍摄的数以百万计的图片和视频。这些视觉数据在分辨率、宽高比、色彩深度等方面都存在差异。如何将这些不同类型视觉数据转换为统一表示形式的方法;
多模态模型的训练过程
MM-LLM的训练流程主要包括多模态预训练(MM PT)和多模态指令调优(MM IT)两个阶段。
- 多模态预训练(MM PT): 在预训练阶段,通常利用X-Text数据集来训练输入投影器和输出投影器,以实现不同模态之间的对齐。对于多模态理解模型,只需优化输入投影器的目标函数。对于多模态生成模型,则需要优化输入投影器、输出投影器和模态生成器的目标函数。
- 多模态指令调优(MM IT): 在指令调优阶段,通常利用一组以指令格式组织的数据集对预训练的MM-LLMs进行微调。这个阶段包括监督式微调(SFT)和基于人类反馈的强化学习(RLHF),旨在更好地与人类意图保持一致,并增强模型的交互能力。SFT将部分预训练阶段的数据转换为指令感知格式,然后使用相同的优化目标对预训练模型进行微调。SFT数据集可以组织成单轮问答或多轮对话。在SFT之后,RLHF会进一步微调模型,利用自然语言反馈(NLF)对模型的响应进行反馈,从而训练模型根据NLF生成相应的响应。RLHF数据集通常包括人类标注或自动生成的NLF。
多模态的多图输入如何处理
Flamingo
对多图分别用视觉编码器进行提取特征,在对应的文本中的特定位置会嵌入特殊符号。
具体来说就是在文本序列中插入特殊的标记来表示这个位置有一个图像/视频内容。直接输入到模型中的是包含这些特殊标记的文本序列,不同的视觉信息则是通过交叉注意力机制来注入到模型中,并且通过mask来限制每段文本能感知到其对应的视觉内容(一段文本对应一个图像/视频)。
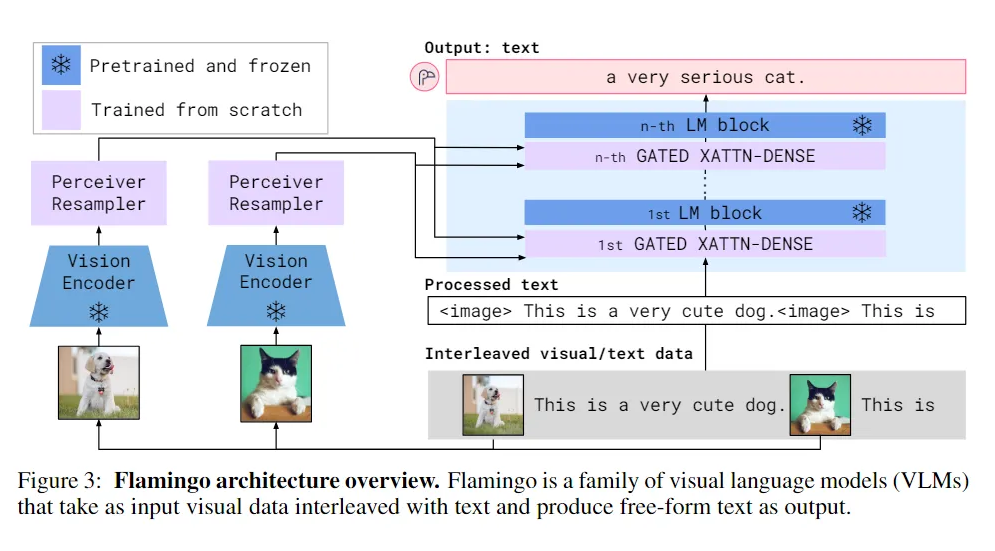

首先通过在文本中的视觉数据位置插入 image 标签以及特殊标记 BOS 表示“序列开始”或 EOC 表示“块结束”来处理文本。图像由 Vision Encoder 和 Perceiver Resampler 独立处理以提取视觉标记。对于给定的文本token,模型仅与该段文本对应的最后一个图像or视频对应的视觉标记进行交叉关注。𝜑 指示该段文本可以关注的图像/视频的序号,若文本没有图像需要关注时标记为 0。
阿里的Qwen-VL
https://arxiv.org/abs/2308.12966
输入的图片经过ViT提取图像特征,之后通过Adapter的交叉注意力机制得到图像的256个query embedding向量,之后和文本embedding向量一起作为LLM的输入,得到对应的文本输出。在图像输入模型的时候,会在图像前后加入特殊的token:以便和文本输入作区分。
此外为了描述图片中的区域信息的输入,以bounding box的坐标的形式给出,这些坐标值归一化到[0,1000]之间,得到字符序列的表达 (x_topleft,y_topleft)(x_bottomright,y_bottomright),这样的字符串会经过tokenizer得到token id,并经过Embedding层得到描述区域的特征向量,在这些特征向量的前后也会增加特殊的token,即 和 ,这些区域对应的文本描述也会用特殊的token 和 加以区分。
Qwen-VL是把视觉内容的 token 序列直接和文本的 token 序列交叉合并在一起输入到模型中而不是通过交叉注意力机制注入进去,这样同时也就支持了多图输入的能力。另外也采用了特殊的标记符合来表示哪些token是图像的token内容。为了提升模型对细粒度视觉理解和定位的能力,Qwen-VL在训练中涉及了区域描述(bound ing box)、及检测数据。
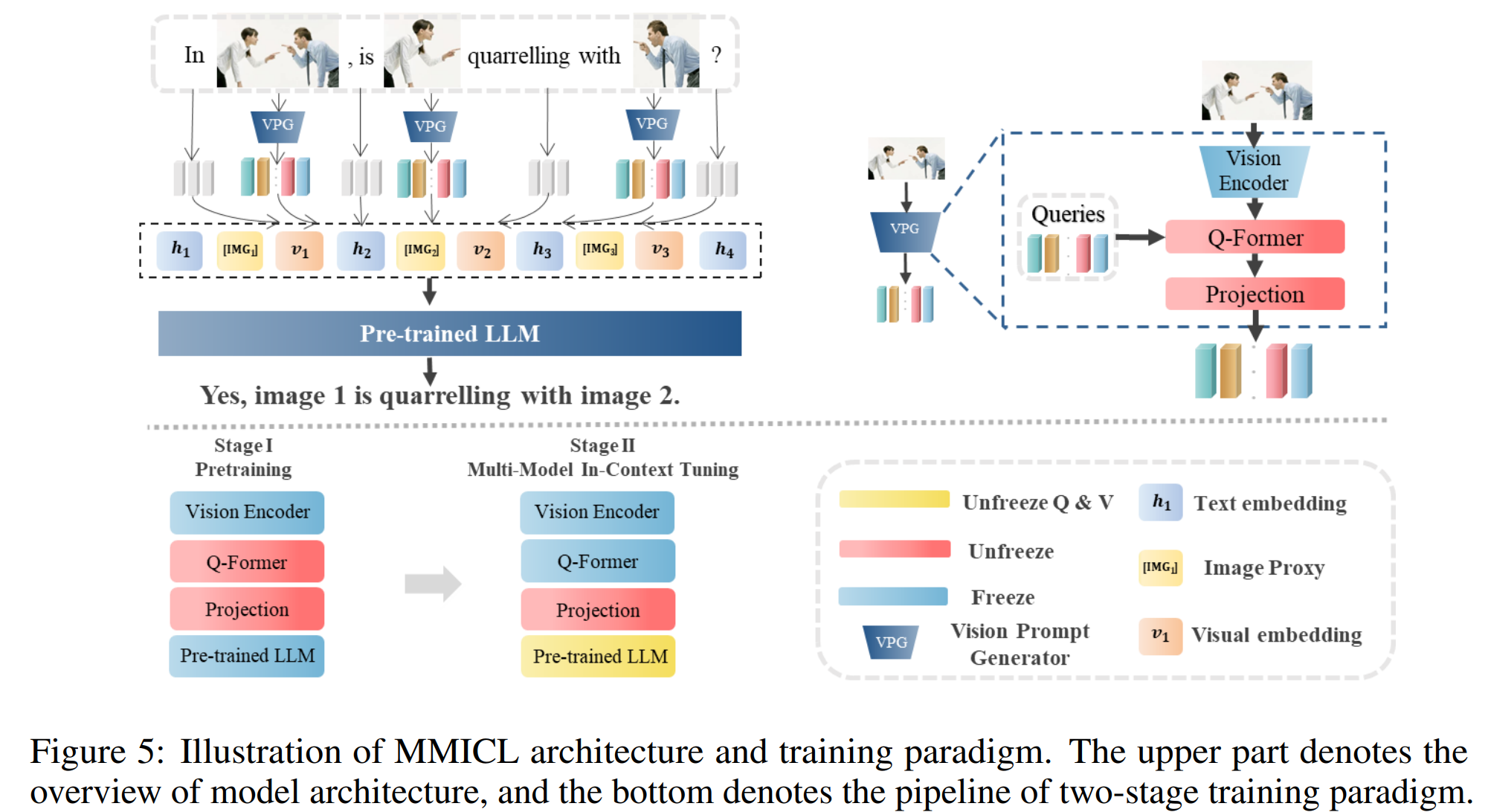
MMICL
https://arxiv.org/abs/2309.07915
图像和文本的embedding通过interleaved的方式进行连接(和阿里的Qwen-VL类似),作为LLM的输入,得到对应的输出。
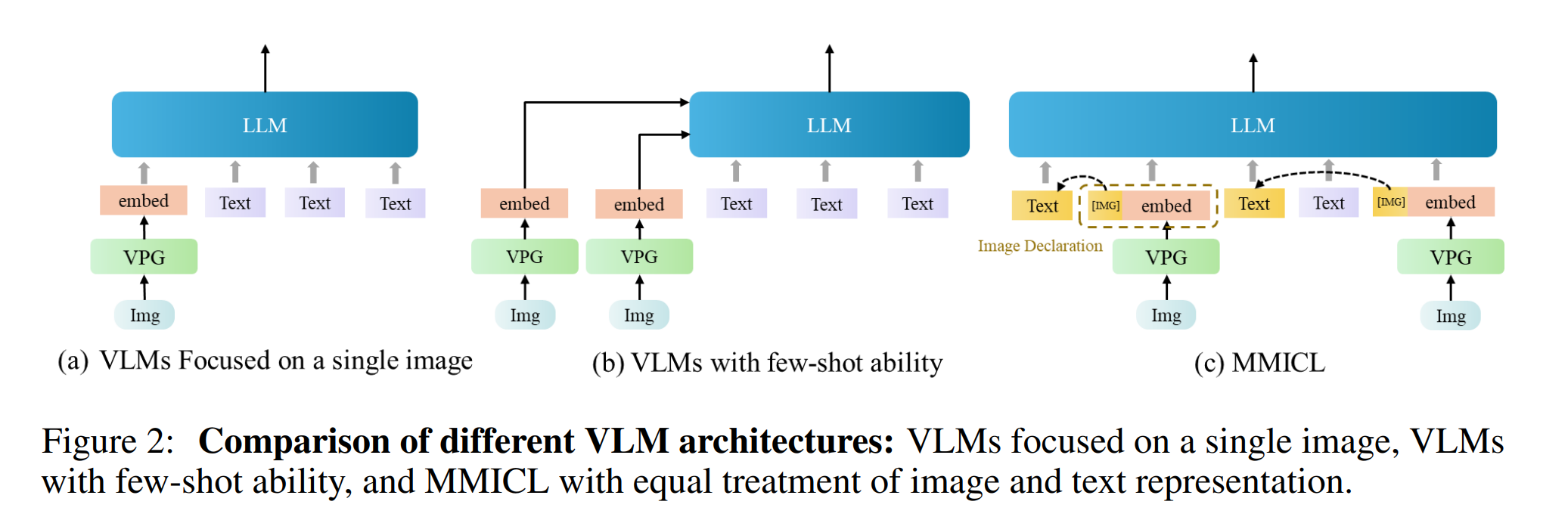
一般只支持单图输入的多模态模型,直接将提取到的图像token和文本(指令or prompt)token拼接后送入模型即可。
如果有多图输入,并且和文本是以交错的形式出现,还采用简单的拼接的话,一般泛化能力不太好,Flamingo论文中消融实验也证明,进行交错文本和图像的训练,能大大提高模型的性能。
MMICL为了支持多图输入,则采用了如下图的改进,将视觉的token按照原本的位置和文本token进行穿插的排列,同时也加入图像标记符号。
面对视频这种不定长视觉数据多模态模型如何处理?
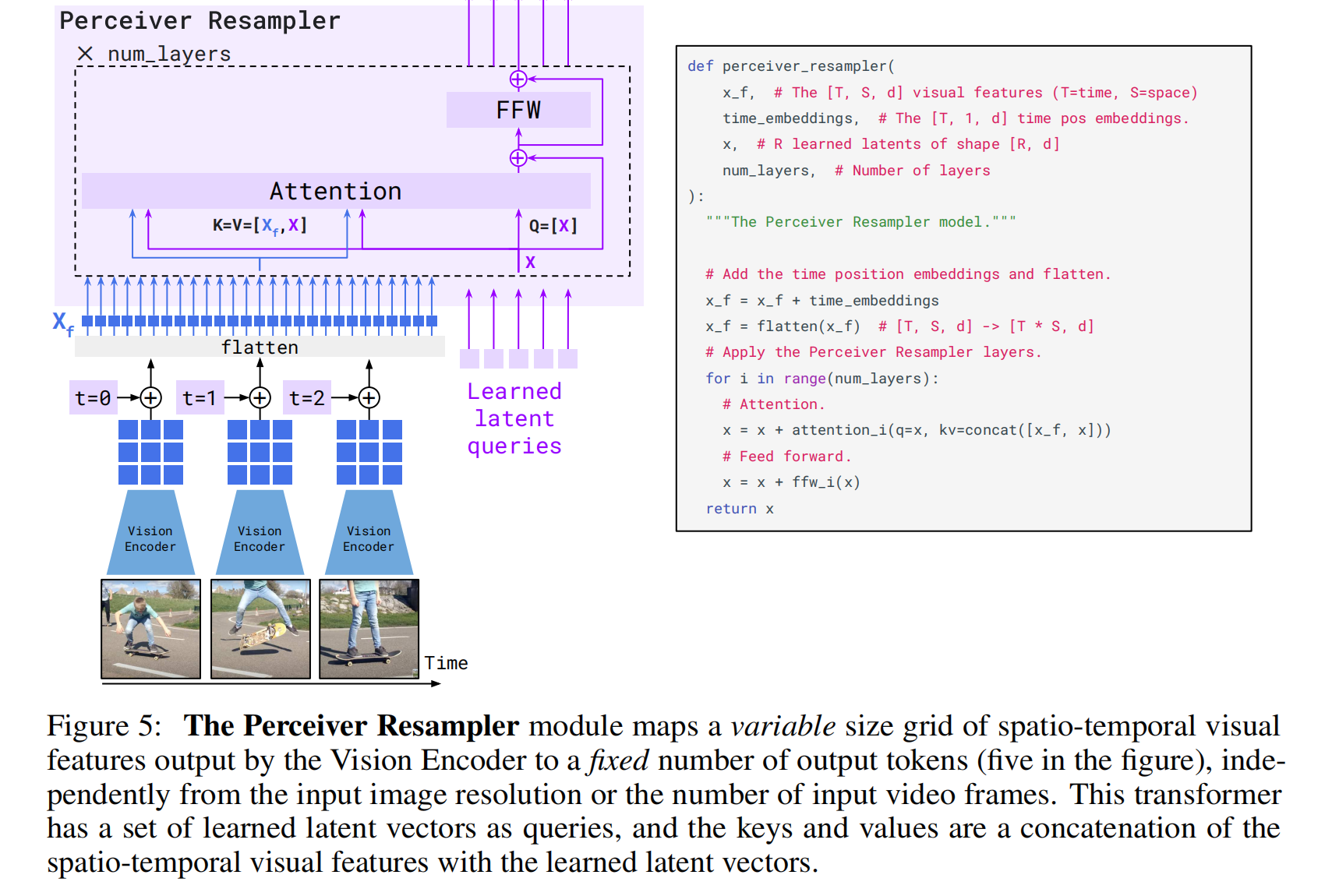
Flamingo 中Perceiver Resampler的设计解决了这个问题。
Perceiver Resampler采用learnable latent queries作为交叉注意力中的Q,而将视频帧/图片帧进行特征提取后展开表示为X_f ,和Q拼接起来作为交叉注意力中的K和V,通过这种方法将learnable latent queries对应位置的Transformer输出作为视觉特征聚合表示,这样变长的视频帧特征就规整为了固定大小的特征,方便了后续的处理。这个模块将视觉编码器连接到冻结的语言模型,如上图所示。它以视觉编码器中的图像或视频特征的可变数量作为输入,并产生固定数量的视觉输出(64 个token),从而降低了视觉-文本交叉注意力的计算复杂度。
如何将视觉编码器提取到视觉特征可以让LLM处理
这一部分的工作其实就是MMLLM中的输入投影器模块的功能。
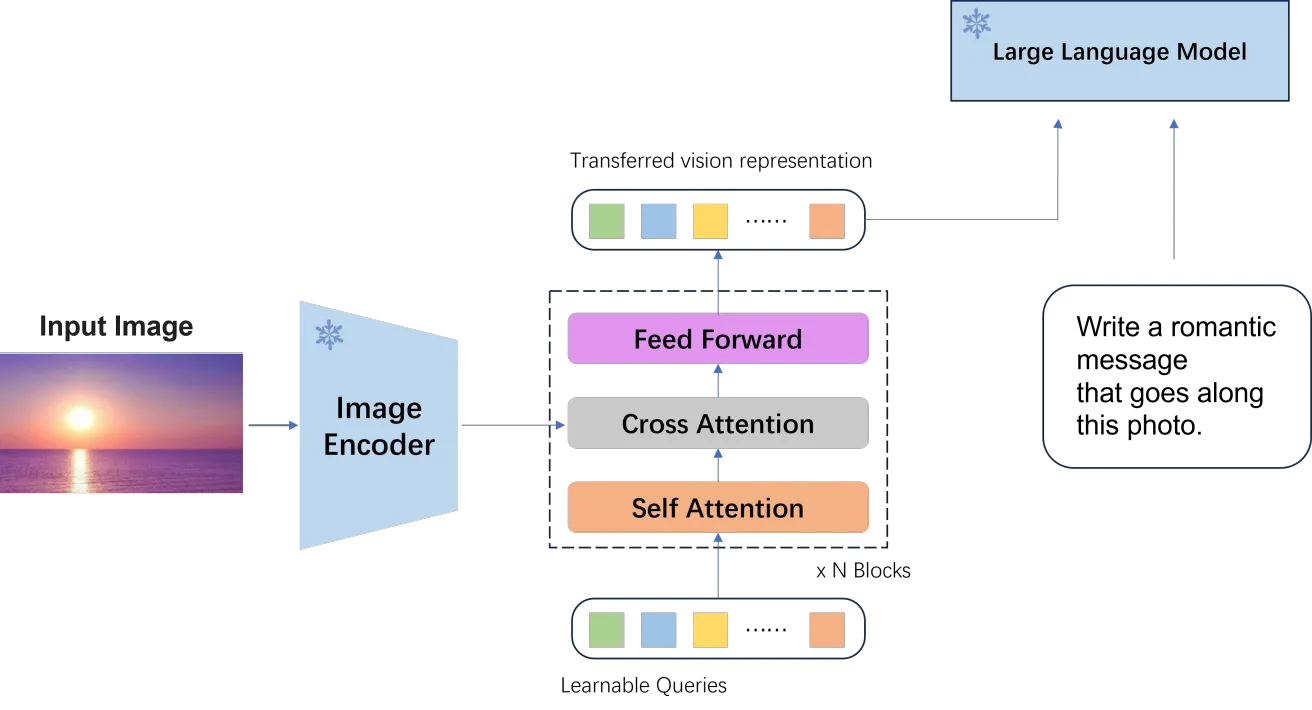
BLIP-2利用已经充分训练好的图片编码器和LLM模型,通过Q-Former巧妙地融合在一起,在引入少量待学习参数的同时,取得了显著的效果。
LLM是以文本语义为目标进行训练的,而视觉编码器是以视觉语义为目的进行训练的,视觉语义即便经过了语义对齐,如通过CLIP等方式进行跨模态语义对齐,其语义和LLM之间也会存在较大的区别,如何融合这两种语义信息,是MLLM模型必须解决的问题,而BLIP2 就提出了采用Q-Former的方法进行解决。Q-Former将视觉编码器提取的视觉特征迁移到了LLM bcakbone可以处理的文本语义特征。同时还有一个好处:它能够从图像编码器中提取固定数量的输出特征,与输入图像分辨率无关。(固定数量的token取决于Query embedding的数量)。
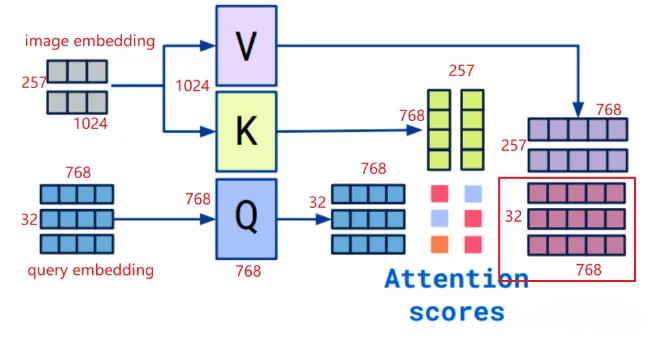
多模态应用场景
多模态下游任务类型
- Video Action Recognition
- Image Text Retrival
- Image Caption
- Visual QA
- Visual Reasoning
- Visual Entailment
- Image Retrival
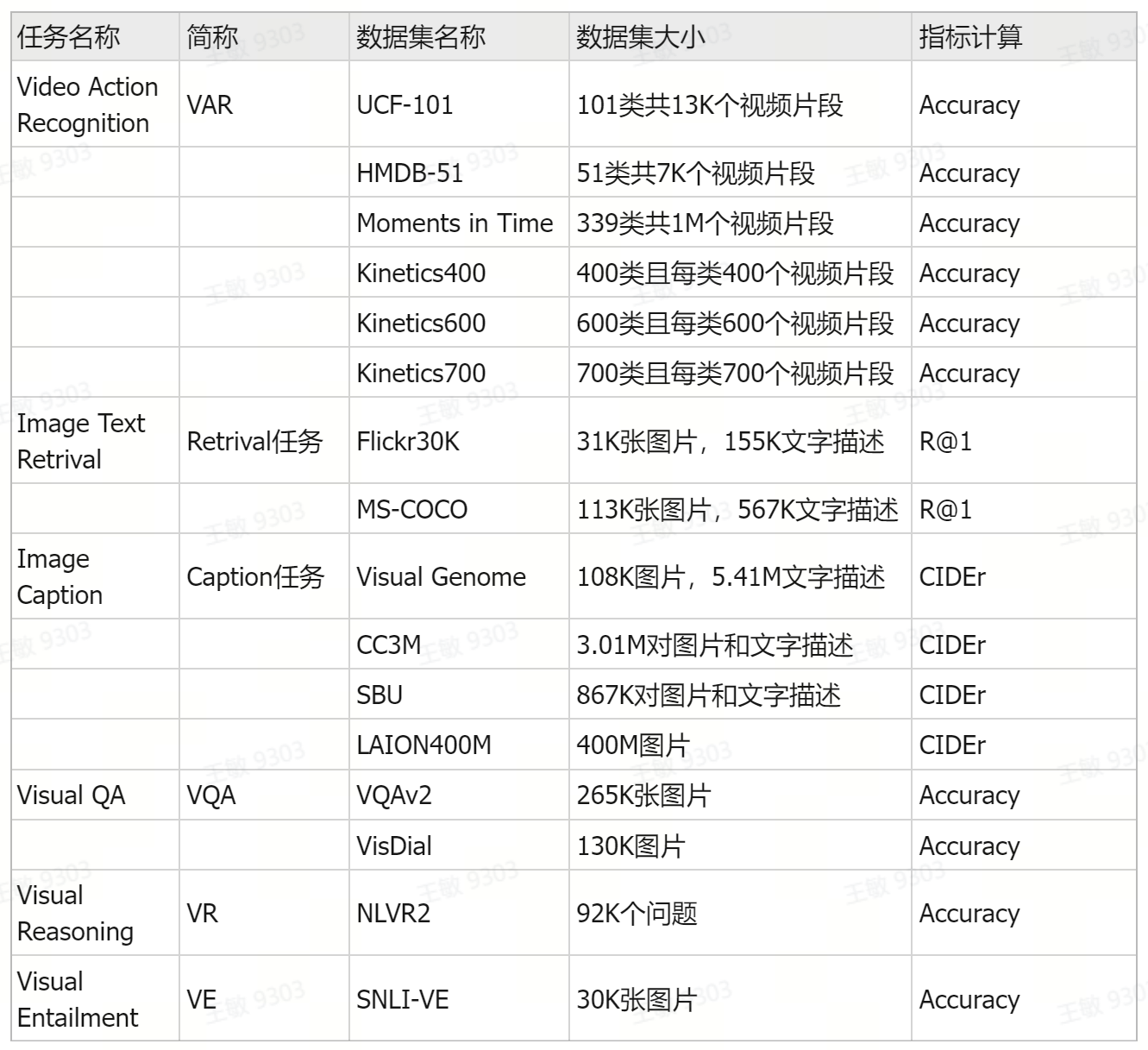
常见多模态模型评测数据集
多模态应用方向
总的来说多模态主要有两个应用方向:理解式和生成式。
- 理解式:图片问答、图片理解推理、图文检索、图片描述、OCR+信息抽取
- 生成式:文生图、文生视频、文生音乐、文字+草图生图、
行业应用场景:1.电商客服;2.图片内容审核、短视频内容审核;3.营销文案创作;4.图像、视频内容创作;5音乐合成等等;
ChatGPT4-V的能力
ChatGPT-4V支持的输入:纯文本、单个图像-文本对、交错图像-文本输入,多帧输入。
文本图像识别能力
用户上传了包含三张账单的图片,并要求计算支付的税收金额。ChatGPT展现了出色的文本图像内容提取能力,能够准确地识别每张账单上的具体金额、税收等数据。ChatGPT将每张账单上的税收数值单独计算出来,最后将三张账单的总税收金额汇总并呈现给用户。这一过程充分展示了ChatGPT在文本图像处理领域的强大能力。
图像逻辑推理能力
用户上传食物和菜单图片,需要ChatGPT根据菜单价格计算食物费用。ChatGPT能够准确地识别菜单上每个食物对应的价格,同时识别出图片中的食物数量,然后根据数量乘以单价精确计算出总价。
文字图像信息抽取能力
用户要求ChatGPT处理多张身份证和护照图片,提取相关信息并以JSON格式输出。ChatGPT凭借强大的文字图像识别能力,成功从证件照片中准确提取姓名、出生日期、身份证号码等文字信息,并以结构化的JSON格式输出。
人脸识别
用户上传了一张明星的照片,ChatGPT精确地展现出了强大的人脸识别功能,迅速准确地识别出了图片中明星的姓名。
医学图像识别
用户可以上传x光片,而ChatGPT能够准确地识别图像中的骨折、肿瘤等医学问题,并给出相应的处理建议。
这展示了ChatGPT在专业领域的图像理解能力,以及其在医学领域的应用潜力。
多模态论文最新进展
https://mm-llms.github.io/

















 1144
1144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









