







目录
前言
我下的是在 2021.09.28 发布月度版本:v2.17.0
本文会讲解以下内容:
- mmDetection训练核心组件
- mmDetection测试核心组件
- 使用上面的核心组件搭建faster rcnn的配置文件
- 使用上面的核心组件搭建retinanet的配置文件
这里并不涉及具体代码实现,主要是熟悉框架训练阶段和测试阶段的主要组件以及配置文件中一些参数的解读。
一、mmDetection构建流程和思想
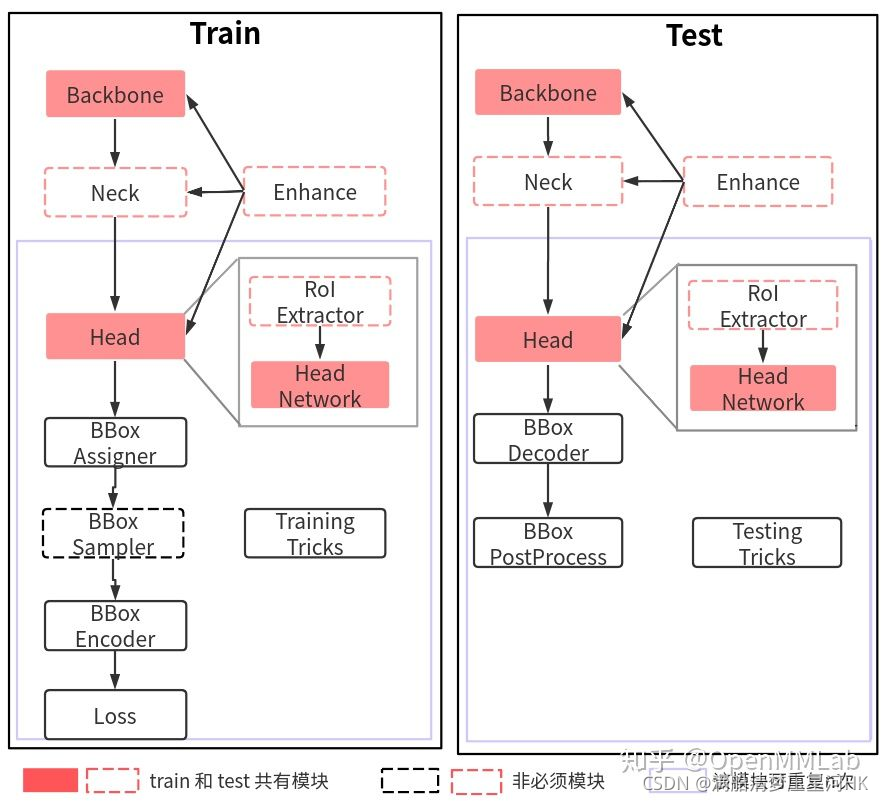
二、训练核心组件
必不可少的组件有:Backbone、Head、BBox Assign、BBox Encoder、Loss、Train Tricks。
目标检测所有的网络模型训练总体流程:
- Backbone:任何一个batch的图片先输入backbone中进行特征提取,典型的backbone有ResNet
- Neck:输入的单尺度或者多尺度feature map输入到neck模块中进行特征融合或者增强,典型的neck有FPN
- Head:将融合或增强后的feature map输入到head部分,进行分类和回归预测
- Enhance:整个网络构建阶段可以引入一些即插即用的增强算子来增强网络的特征提取能力,典型的比如SPP、DCN等
- Bbox Asssigner、Bbox Sampler:目标检测head输出的一般是feature map,对于分类任务而言存在严重的正负样本不均衡,可以通过正负样本分配和采样控制,均衡正负样本
- Bbox Encoder:为了方便收敛和平衡多分支,一般会对gt bbox进行编码
- Loss:最后一步定义分类和回归损失loss,进行训练
- Train Tricks:在训练过程中也包括非常多的tricks,例如优化器选择,参数调参等
2.1、Backbone
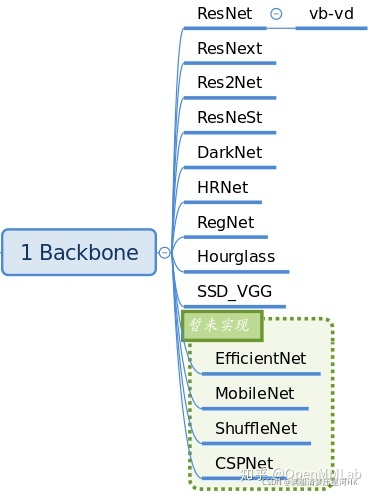
backbone的作用主要是特征提取,存放在mmdet/models/backbones中。当前版本已经实现的backbone网络骨架如下:
__all__ = [
'RegNet', 'ResNet', 'ResNetV1d', 'ResNeXt', 'SSDVGG', 'HRNet',
'MobileNetV2', 'Res2Net', 'HourglassNet', 'DetectoRS_ResNet',
'DetectoRS_ResNeXt', 'Darknet', 'ResNeSt', 'TridentResNet', 'CSPDarknet',
'SwinTransformer', 'PyramidVisionTransformer', 'PyramidVisionTransformerV2'
]
最常用的是ResNet系列,如果需要对Backbone进行扩展,可以继承上述网络,然后通过注册器机制注册使用。一个典型用法为在配置文件中:
# 以下都是backbone配置
backbone=dict(
# backbone类型
type='ResNet',
# 网络层数 模型深度 使用ResNet50
depth=50,
# resnet的Stage(残差模块)个数 resnet总体包括stem + 4个stage输出
num_stages=4,
# 表示本模块输出的特征图索引 (0, 1, 2, 3)表示这四个stage都会输出送入后面的fpn中
# 其 stride 分别为 (4,8,16,32),channel 分别为 (256, 512, 1024, 2048)
out_indices=(0, 1, 2, 3),
# 冻结哪些stage的参数 即该stage参数不参加训练
frozen_stages=1,
# 归一化层(norm layer)的配置项 归一化层的类别通常是BN或GN 这里使用BN且要训练BN中的gamma和beta参数
norm_cfg=dict(type='BN', requires_grad=True),
# backbone所有的BN层的均值和方差都直接采用全局预训练值 不进行更新
norm_eval=True,
# 网络代码风格 如果设置pytorch,则stride为2的层是conv3x3的卷积层;如果设置caffe,则stride为2的层是第一个conv1x1的卷积层
style='pytorch',
# 使用 pytorch 提供的在 imagenet 上面训练过的权重作为预训练权重
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
通过 MMCV 中的注册器机制,你可以通过 dict 形式的配置来实例化任何已经注册的类,非常方便和灵活。
2.2、Neck
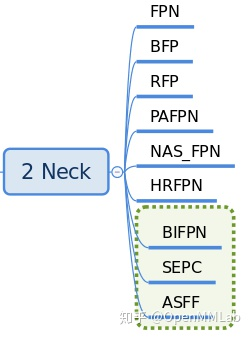
Neck主要负责对backbone的特征进行高效融合和增强,能够对输入的单尺度或多尺度特征进行融合、增强输出等。存放在:mmdet/model/necks文件中。当前版本已实现的neck结构有:
__all__ = [
'FPN', 'BFP', 'ChannelMapper', 'HRFPN', 'NASFPN', 'FPN_CARAFE', 'PAFPN',
'NASFCOS_FPN', 'RFP', 'YOLOV3Neck', 'FPG', 'DilatedEncoder',
'CTResNetNeck', 'SSDNeck', 'YOLOXPAFPN'
]
最常用的应该是 FPN,一个典型用法是在配置文件中:
# 以下都是neck配置
neck=dict(
# neck类型是FPN 同样支持'NASFPN', 'PAFPN'等
type='FPN',
# 输入通道数 与backbone的各个位置输出通道数一致
in_channels=[256, 512, 1024, 2048],
# neck每一层的输出通道数
out_channels=256,
# 这里使用一个额外的特征图 使用更高层的特征图 产生更大尺寸的提议框 即总共使用num_outs个多尺度特征图
num_outs=5),
2.3、Head

目标检测的输出一般包括分类和框坐标回归两个分支,不同算法head模块的复杂程度不同,比较灵活。在网络构建方面,理解目标检测算法主要是要理解 head 模块。MMDetection将head划分为two-stage的ROIHeads存放在mmdet/models/roi_heads 和 one-stage的DenseHead,存放在mmdet/models/dense_heads中。
如:dense_heads中的rpn_head:
rpn_head=dict(
# rpn_head类型是RPNHead 也支持'GARPNHead'等
type='RPNHead',
# RPN输入的维度 就是上面FPN每层输出的维度256
in_channels=256,
# 第一个卷积层的通道数
feat_channels=256,
# 锚点(Anchor)生成器的配置 产生不同尺度的anchor
anchor_generator=dict(
# 类型是AnchorGenerator是使用最多的anchor生成器 SSD使用的是SSDAnchorGenerator
type='AnchorGenerator',
# 锚点的基本比例,特征图某一位置的锚点面积为 scale * base_sizes
scales=[8],
# anchor w h比
ratios=[0.5, 1.0, 2.0],
# 锚生成器的步幅(降采样率) 这与FPN特征步幅一致 如果未设置base_sizes 则当前步幅值将被视为base_sizes
strides=[4, 8, 16, 32, 64]),
# 在训练和测试期间就需需要对框进行编码和解码
bbox_coder=dict(
# 框编码器的类别 'DeltaXYWHBBoxCoder' 是最常用的 详情看:mmdet/core/bbox/coder/delta_xywh_bbox_coder.py
type='DeltaXYWHBBoxCoder',
# 用于编码和解码框的均值
target_means=[.0, .0, .0, .0],
# 用于编码和解码框的标准方差
target_stds=[1.0, 1.0, 1.0, 1.0]),
# rpn子网络的分类分支的损失函数配置
loss_cls=dict(
# 使用交叉熵损失 也支持FocalLoss等 PN通常进行二分类 所以通常使用sigmoid函数 分类分支的损失权重=1
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
# rpn子网络的回归分支的损失函数配置 使用L1Loss 还支持IoU Losses和Smooth L1-loss等 详情看:mmdet/models/losses/smooth_l1_loss.py
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
roi_heads:
roi_head=dict(
# RoI head的类型 更多细节参考:mmdet/models/roi_heads/standard_roi_head.py
type='StandardRoIHead',
# 第一步:把提议框内的特征图从全图特征图中裁剪出来 输出 256x7x7
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
# 采用RoI-Align算法 使用双线性插值 无论裁剪的提议框多大 都会产生一个7x7的输出
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
# 输出的通道不变 还是256
out_channels=256,
# 指定特征图上一像素位移对应原图多少位移
featmap_strides=[4, 8, 16, 32]),
# 第二步:将裁剪出来统一大小的feature map送入bbox head 做分类+回归
bbox_head=dict(
# 2个全连接层类型的head
type='Shared2FCBBoxHead',
# 输入 256x7x7
in_channels=256,
# 通过两个全连接层输出通道变为1024
fc_out_channels=1024,
# 候选区域(Region of Interest)特征的大小
roi_feat_size=7,
# 分类的类别数量
num_classes=80,
# 第二阶段使用的bbox编码器
bbox_coder=dict(
# 还是使用最常用的 DeltaXYWHBBoxCoder 同上rpn_head
type='DeltaXYWHBBoxCoder',
# 同上rpn_head
target_means=[0., 0., 0., 0.],
# 同上rpn_head
target_stds=[0.1, 0.1, 0.2, 0.2]),
# 回归是否与类别无关
reg_class_agnostic=False,
# roi网络的分类分支的损失函数配置 同上rpn_head
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
# roi网络的分类分支的损失函数配置 同上rpn_head
loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
2.4、Enhance
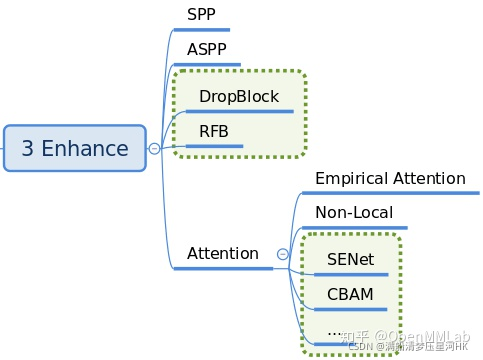
enhance 是即插即用、能够对特征进行增强的模块。具体代码可以通过dict形式注册到backbone、neck和head中,非常方便。放在mmdet/models/
这部分的内容比较杂乱,不同的enhance方法,调用的方法也不同如ResNet 骨架中的 plugins,这个部分暂不解读,读放在具体算法模块中讲解。
2.5、BBox Assigner
正负样本属性分配模块作用是进行正负样本定义或者正负样本分配。正样本就算前景样本(可以是任何类别),负样本就是背景样本。因为目标检测是一个同时进行分类和回归的问题,而分类场景必须需要正负样本才能进行训练。这个模块至关重要,不同的正负样本分配策略会带来显著的性能差异。一些典型的分配策略如下:
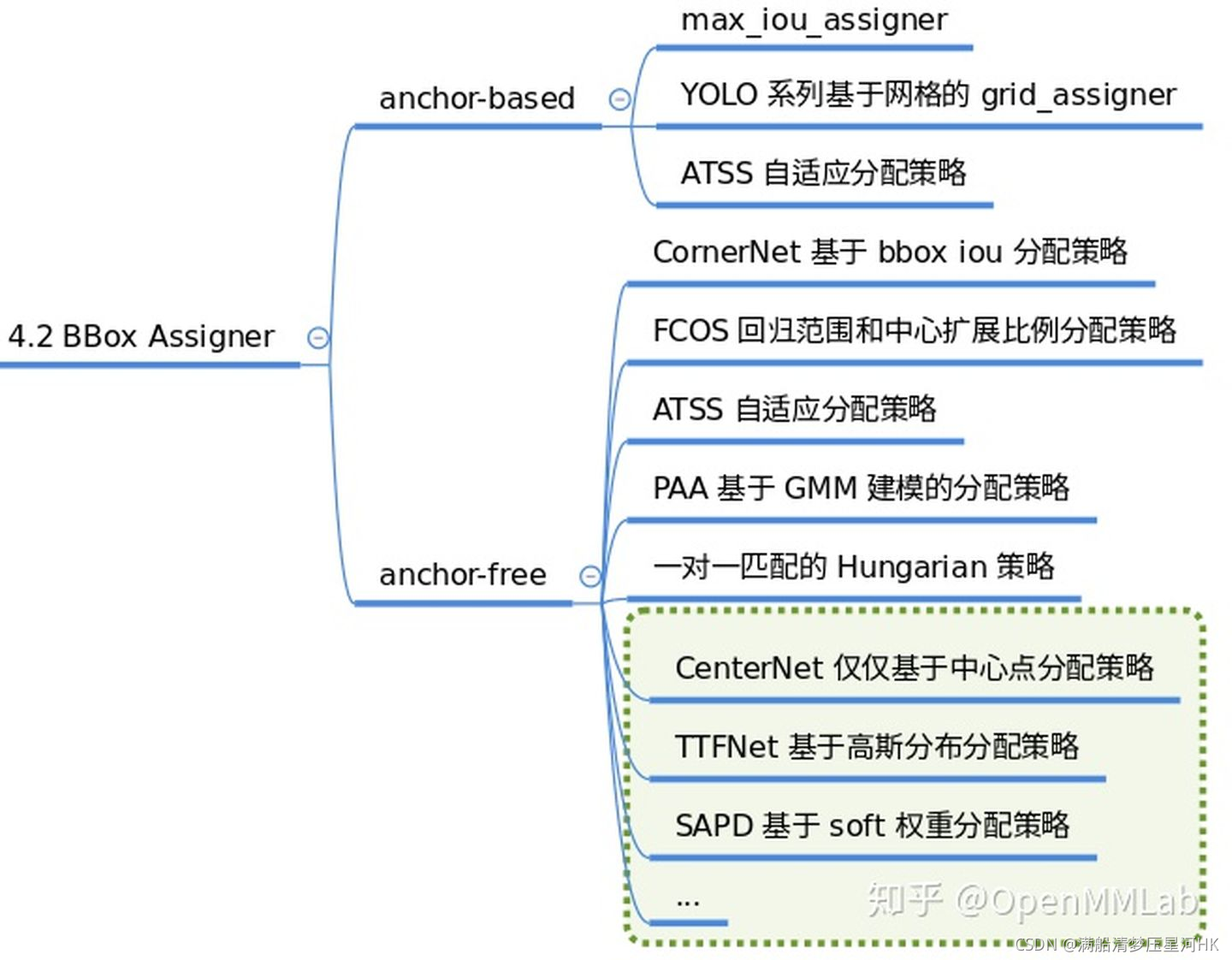
对应代码放在mmdet/core/bbox/assigners中。当前版本实现的正负样本匹配策略有:
__all__ = [
'BaseAssigner', 'MaxIoUAssigner', 'ApproxMaxIoUAssigner', 'AssignResult',
'PointAssigner', 'ATSSAssigner', 'CenterRegionAssigner', 'GridAssigner',
'HungarianAssigner', 'RegionAssigner', 'UniformAssigner', 'SimOTAAssigner'
]
一个典型用法是在配置文件中:
assigner=dict(
# 分配器的类型 MaxIoUAssigner 基于iou的分配方法 用于许多常见的检测器通常会使用
type='MaxIoUAssigner',
# IoU >= 0.7(阈值) 被视为正样本
pos_iou_thr=0.7,
# IoU < 0.3(阈值) 被视为负样本 0.3-0.7不管
neg_iou_thr=0.3,
# 将框作为正样本的最小IoU阈值 ?
min_pos_iou=0.3,
# 是否匹配低质量的框(更多细节见 API 文档)
match_low_quality=True,
# 忽略bbox的IoF阈值 ?
ignore_iof_thr=-1),
2.6、BBox Sampler
在确定了每个样本的正负属性之后,可能还需要进行样本平衡操作。因为一般在目标检测中gt bbox都是很少的,正负样本比例会远远小于1。而这往往会带来一个后果:在数据集不平衡的情况下:比如负样本远大于正样本的个数),那么整个训练过程往往会被负样本所操作,损失函数也会被负样本所左右。为了克服这个问题,适当的正负样本采样策略是非常有必要的。典型的采样策略有:
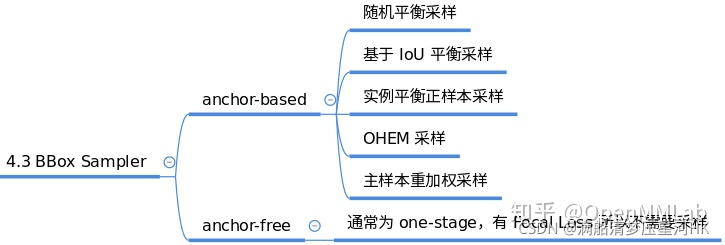
对应代码在:mmdet/core/bbox/samplers中,当前版本实现的正负样本采样策略有:
__all__ = [
'BaseSampler', 'PseudoSampler', 'RandomSampler',
'InstanceBalancedPosSampler', 'IoUBalancedNegSampler', 'CombinedSampler',
'OHEMSampler', 'SamplingResult', 'ScoreHLRSampler'
]
一个典型用法是在配置文件中:
sampler=dict(
# 采样器类型 这里使用随机采用RandomSampler 还支持PseudoSampler和其他采样器 详看mmdet/core/bbox/samplers/
type='RandomSampler',
# 采样数量
num=256,
# 正样本呢占总样本的比例
pos_fraction=0.5,
# 基于正样本数量的负样本上限
neg_pos_ub=-1,
# 采样后是否添加GT作为proposal
add_gt_as_proposals=False),
2.7、BBox Encoder
在回归部分,如果直接预测框的xywh或者xyxy坐标,往往会很难预测,坐标的大小难以统一在一个范围内,对于网络来说是很难预测到精确的位置的。所以为了更好的收敛和平衡多个loss,可以使用bbox编码策略对正样本的gt bbox采用某种编码变换(反操作就是bbox解码),最简单的编码策略是对gt bbox的xy坐标分别除以图像高宽进行归一化,对wh进行log处理,以更好的做回归预测。一些典型的编解码策略如下:
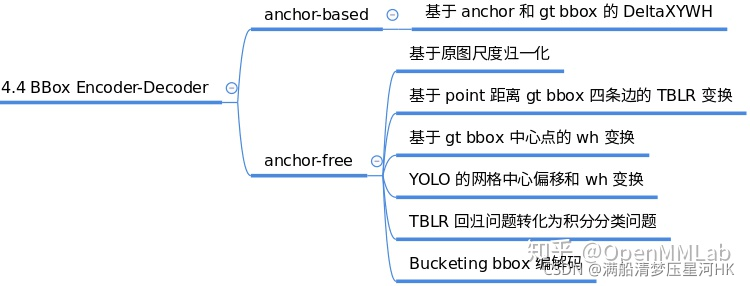
对应代码在mmdet/core/bbox/coder中,当前版本实现的gt bbox编解码策略有:
__all__ = [
'BaseBBoxCoder', 'PseudoBBoxCoder', 'DeltaXYWHBBoxCoder',
'LegacyDeltaXYWHBBoxCoder', 'TBLRBBoxCoder', 'YOLOBBoxCoder',
'BucketingBBoxCoder'
]
一个典型用法是在配置文件中:
bbox_coder=dict(
# 还是使用最常用的 DeltaXYWHBBoxCoder 同上rpn_head
type='DeltaXYWHBBoxCoder',
# 同上rpn_head
target_means=[0., 0., 0., 0.],
# 同上rpn_head
target_stds=[0.1, 0.1, 0.2, 0.2]),
2.8、Loss
Loss模块一般分为分类loss和回归loss,是对网络head得到的预测值和bbox encoder得到的targets进行梯度下降迭代训练。loss 的设计也是各大算法重点改进对象,常用的 loss 如下:

对应的代码放在:mmdet/models/losses中,当前版本包含的损失函数有:
__all__ = [
'accuracy', 'Accuracy', 'cross_entropy', 'binary_cross_entropy',
'mask_cross_entropy', 'CrossEntropyLoss', 'sigmoid_focal_loss',
'FocalLoss', 'smooth_l1_loss', 'SmoothL1Loss', 'balanced_l1_loss',
'BalancedL1Loss', 'mse_loss', 'MSELoss', 'iou_loss', 'bounded_iou_loss',
'IoULoss', 'BoundedIoULoss', 'GIoULoss', 'DIoULoss', 'CIoULoss', 'GHMC',
'GHMR', 'reduce_loss', 'weight_reduce_loss', 'weighted_loss', 'L1Loss',
'l1_loss', 'isr_p', 'carl_loss', 'AssociativeEmbeddingLoss',
'GaussianFocalLoss', 'QualityFocalLoss', 'DistributionFocalLoss',
'VarifocalLoss', 'KnowledgeDistillationKLDivLoss', 'SeesawLoss', 'DiceLoss'
]
一个典型用法是在配置文件中:
# roi网络的分类分支的损失函数配置 同上rpn_head
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
# roi网络的分类分支的损失函数配置 同上rpn_head
loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
2.9、Training trick
训练技巧非常多,常说的调参很大一部分工作都是在设置这部分超参。这部分内容比较杂乱,很难做到完全统一,目前主流的 tricks 如下所示: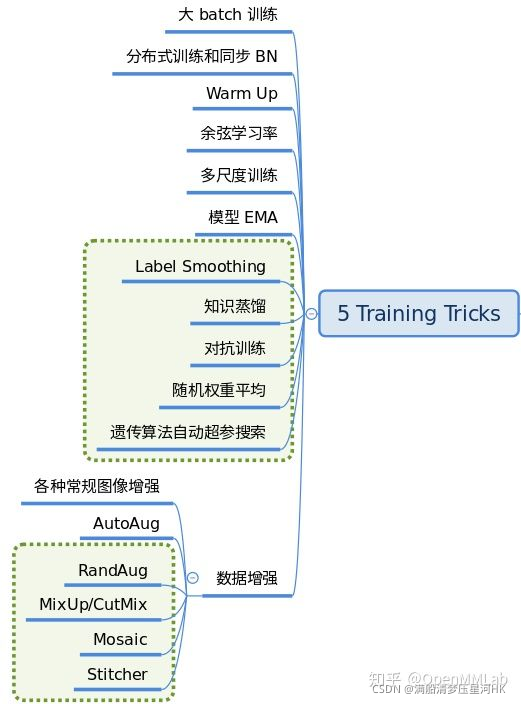
MMDetection 目前这部分还在完善当中。
三、测试核心组件
测试核心组件和训练非常类似,但是简单很多,除了必备的网络构建部分外( backbone、neck、head 和 enhance ),不需要正负样本定义、正负样本采样和 loss 计算三个最难的部分,但是其额外需要一个 bbox 后处理模块和测试 trick。
3.1、BBox Decoder
训练的时候对gt bbox进行了编码,测试的时候同样要对其进行解码。编码不同,解码相应也不相同。例如:训练的时候编码是对xy除以wh进行归一化,相应的解码就要乘以wh,得到相对原图的预测框。代码同样放在编码文件夹中,放在mmdet/core/bbox/coder中。
3.2、BBox PostProcess
得到相对原图的预测框后,由于可能会出现重叠bbo现象,所以一般都要进行后处理,常见的后处理方式是nms及其变种。对应的代码在mmdet/core/post_processing中。当前版本实现的后处理方式有:
__all__ = [
'multiclass_nms', 'merge_aug_proposals', 'merge_aug_bboxes',
'merge_aug_scores', 'merge_aug_masks', 'mask_matrix_nms', 'fast_nms'
]
3.3、Testing Tricks
为了提高测试性能,测试阶段也会采用 trick。这个阶段的 tricks 也非常多,难以完全统一,常见的测试策略如下:
在这里插入图片描述
最典型的是多尺度测试以及各种模型集成手段,典型配置如下:
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=True,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
四、搭建Faster rcnn模型配置文件
有了上面的组件我们就可以很轻松的搭建一个目标检测框架的配置文件了,我们这里以faster rcnn为例。
# model settings
model = dict(
# model模型类型
type='FasterRCNN',
# Backbone配置信息
backbone=dict(
# backbone类型
type='ResNet',
# 网络层数 模型深度 使用ResNet50
depth=50,
# resnet的Stage(残差模块)个数 resnet总体包括stem + 4个stage输出
num_stages=4,
# 表示本模块输出的特征图索引 (0, 1, 2, 3)表示这四个stage都会输出送入后面的fpn中
# 其 stride 分别为 (4,8,16,32),channel 分别为 (256, 512, 1024, 2048)
out_indices=(0, 1, 2, 3),
# 冻结哪些stage的参数 即该stage参数不参加训练
frozen_stages=1,
# 归一化层(norm layer)的配置项 归一化层的类别通常是BN或GN 这里使用BN且要训练BN中的gamma和beta参数
norm_cfg=dict(type='BN', requires_grad=True),
# backbone所有的BN层的均值和方差都直接采用全局预训练值 不进行更新
norm_eval=True,
# 网络代码风格 如果设置pytorch,则stride为2的层是conv3x3的卷积层;如果设置caffe,则stride为2的层是第一个conv1x1的卷积层
style='pytorch',
# 使用 pytorch 提供的在 imagenet 上面训练过的权重作为预训练权重
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
# Neck配置信息
neck=dict(
# neck类型是FPN 同样支持'NASFPN', 'PAFPN'等
type='FPN',
# 输入通道数 与backbone的各个位置输出通道数一致
in_channels=[256, 512, 1024, 2048],
# neck每一层的输出通道数
out_channels=256,
# 这里使用一个额外的特征图 使用更高层的特征图 产生更大尺寸的提议框 即总共使用num_outs个多尺度特征图
# 输入FPN产生的5层特征图 并基于这五层特征图产生提议框
num_outs=5),
# RPN_Head配置信息 封装了两步(two-stage)/级联(cascade)检测器的第一步 从backbone产生特征图中提取候选区域
rpn_head=dict(
# rpn_head类型是RPNHead 也支持'GARPNHead'等
type='RPNHead',
# RPN输入的维度 就是上面FPN每层输出的维度256
in_channels=256,
# 第一个卷积层的通道数
feat_channels=256,
# 锚点(Anchor)生成器的配置 产生不同尺度的anchor
anchor_generator=dict(
# 类型是AnchorGenerator是使用最多的anchor生成器 SSD使用的是SSDAnchorGenerator
type='AnchorGenerator',
# 锚点的基本比例,特征图某一位置的锚点面积为 scale * base_sizes
scales=[8],
# anchor w h比
ratios=[0.5, 1.0, 2.0],
# 锚生成器的步幅(降采样率) 这与FPN特征步幅一致 如果未设置base_sizes 则当前步幅值将被视为base_sizes
strides=[4, 8, 16, 32, 64]),
# 在训练和测试期间就需需要对框进行编码和解码
bbox_coder=dict(
# 框编码器的类别 'DeltaXYWHBBoxCoder' 是最常用的 详情看:mmdet/core/bbox/coder/delta_xywh_bbox_coder.py
type='DeltaXYWHBBoxCoder',
# 用于编码和解码框的均值
target_means=[.0, .0, .0, .0],
# 用于编码和解码框的标准方差
target_stds=[1.0, 1.0, 1.0, 1.0]),
# rpn子网络的分类分支的损失函数配置
loss_cls=dict(
# 使用交叉熵损失 也支持FocalLoss等 PN通常进行二分类 所以通常使用sigmoid函数 分类分支的损失权重=1
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
# rpn子网络的回归分支的损失函数配置 使用L1Loss 还支持IoU Losses和Smooth L1-loss等 详情看:mmdet/models/losses/smooth_l1_loss.py
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
# ROI-Head配置信息 RoIHead 封装了两步(two-stage)/级联(cascade)检测器的第二步
# ROI-Head会基于RPN-Head产生的提议框和原图的特征图进行预测 总体分两步 bbox_roi_extractor + bbox_head
roi_head=dict(
# RoI head的类型 更多细节参考:mmdet/models/roi_heads/standard_roi_head.py
type='StandardRoIHead',
# 第一步:把提议框内的特征图从全图特征图中裁剪出来 输出 256x7x7
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
# 采用RoI-Align算法 使用双线性插值 无论裁剪的提议框多大 都会产生一个7x7的输出
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
# 输出的通道不变 还是256
out_channels=256,
# 指定特征图上一像素位移对应原图多少位移
featmap_strides=[4, 8, 16, 32]),
# 第二步:将裁剪出来统一大小的feature map送入bbox head 做分类+回归
bbox_head=dict(
# 2个全连接层类型的head
type='Shared2FCBBoxHead',
# 输入 256x7x7
in_channels=256,
# 通过两个全连接层输出通道变为1024
fc_out_channels=1024,
# 候选区域(Region of Interest)特征的大小
roi_feat_size=7,
# 分类的类别数量
num_classes=80,
# 第二阶段使用的bbox编码器
bbox_coder=dict(
# 还是使用最常用的 DeltaXYWHBBoxCoder 同上rpn_head
type='DeltaXYWHBBoxCoder',
# 同上rpn_head
target_means=[0., 0., 0., 0.],
# 同上rpn_head
target_stds=[0.1, 0.1, 0.2, 0.2]),
# 回归是否与类别无关
reg_class_agnostic=False,
# roi网络的分类分支的损失函数配置 同上rpn_head
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
# roi网络的分类分支的损失函数配置 同上rpn_head
loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
# model training and testing settings 采样训练配置 测试nms配置
# 配置模型在训练过程中一些模块的行为
train_cfg=dict(
# rpn模块训练行为配置
rpn=dict(
# 1、第一阶段分配正负样本 训练的时候需要将gt box与RPN产生的提议框(anchor)进行比较,为提议框分类和回归的目标值
assigner=dict(
# 分配器的类型 MaxIoUAssigner 基于iou的分配方法 用于许多常见的检测器通常会使用
type='MaxIoUAssigner',
# IoU >= 0.7(阈值) 被视为正样本
pos_iou_thr=0.7,
# IoU < 0.3(阈值) 被视为负样本 0.3-0.7不管
neg_iou_thr=0.3,
# 将框作为正样本的最小IoU阈值 ?
min_pos_iou=0.3,
# 是否匹配低质量的框(更多细节见 API 文档)
match_low_quality=True,
# 忽略bbox的IoF阈值 ?
ignore_iof_thr=-1),
# 2、第一阶段正负样本采样 从rpn得到的分配了上千个正负样本提议框 但是不是所有都会参与训练 而是随机采样256个提议框进行训练
sampler=dict(
# 采样器类型 这里使用随机采用RandomSampler 还支持PseudoSampler和其他采样器 详看mmdet/core/bbox/samplers/
type='RandomSampler',
# 采样数量
num=256,
# 正样本呢占总样本的比例
pos_fraction=0.5,
# 基于正样本数量的负样本上限
neg_pos_ub=-1,
# 采样后是否添加GT作为proposal
add_gt_as_proposals=False),
# 填充有效锚点后允许的边框 ?
allowed_border=-1,
# 训练期间正样本的权重
pos_weight=-1,
# 是否设置调试(debug)模式
debug=False),
# rpn产生候选框行为配置:从rpn训练得到2000个候选框 经过nms最多得到1000个候选框 再从1000中选择256个进行训练
rpn_proposal=dict(
# NMS前的box数
nms_pre=2000,
# NMS后要保留的最大box数量
max_per_img=1000,
# nms配置 nms类别=nms NMS中iou的阈值
nms=dict(type='nms', iou_threshold=0.7),
# 允许的最小box尺寸
min_bbox_size=0),
# rcnn模块训练行为配置
rcnn=dict(
# 1、第二阶段分配正负样本 配置解读同上
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.5,
match_low_quality=False,
ignore_iof_thr=-1),
# 2、第二阶段采样正负样本 配置解读同上
sampler=dict(
type='RandomSampler',
num=512,
pos_fraction=0.25,
neg_pos_ub=-1,
add_gt_as_proposals=True),
pos_weight=-1,
debug=False)),
# 测试阶段的一些参数 控制测试行为 配置解读同上
test_cfg=dict(
rpn=dict(
nms_pre=1000,
max_per_img=1000,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100)
# soft-nms is also supported for rcnn testing
# e.g., nms=dict(type='soft_nms', iou_threshold=0.5, min_score=0.05)
))
五、搭建retinanet的配置文件
# model settings
model = dict(
type='RetinaNet',
backbone=dict(
# backbone使用ResNet50
type='ResNet',
# ResNet50
depth=50,
# 使用ResNet50中全部的4个stage的卷积层
num_stages=4,
# 输出这4个stage的特征作为FPN结构的输入
out_indices=(0, 1, 2, 3),
# 训练时冻结都一个stage的卷积层参数
frozen_stages=1,
# 使用BN层
norm_cfg=dict(type='BN', requires_grad=True),
# 冻结BN层的统计量 所有的BN层的均值和方差都直接采用全局预训练值 不进行更新
norm_eval=True,
# 网络代码风格 如果设置pytorch,则stride为2的层是conv3x3的卷积层;如果设置caffe,则stride为2的层是第一个conv1x1的卷积层
style='pytorch',
# 使用 pytorch 提供的在 imagenet 上面训练过的权重作为预训练权重
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
neck=dict(
# neck采用的是FPN结构
type='FPN',
# 每级FPN的输入特征图的通道数
in_channels=[256, 512, 1024, 2048],
# FPN输出通道 全部层都是固定256
out_channels=256,
# 在backbone的第二个stage开始搭建FPN
start_level=1,
# 在backbone的最高层特征图上使用卷积层生成额外的特征图 更小的分辨率 产生更大的提议框或检测框
add_extra_convs='on_input',
# 使用5层的FPN结构
num_outs=5),
bbox_head=dict(
# One-Stage neck后直接接一个head 这里使用RetinaHead
type='RetinaHead',
# 输出类别数
num_classes=80,
# FPN输入的特征图通道数 上面提到FPN所有层输出通道数都是256
in_channels=256,
# 检测头中重复的卷积层的个数
stacked_convs=4,
# 这些卷积中间特征通道数
feat_channels=256,
# 锚框生成器
anchor_generator=dict(
type='AnchorGenerator',
# 8的4倍 也就是32
octave_base_scale=4,
# [1-2]这个区间分为3份 也就是32-64这个区间按照等比例分为3个部分
# 也就是说会在一个特征图上产生32, 32x2^(1/3), 32x2^(2/3)边长的3种锚框
# 每种锚框再用下面的长宽比 产生不同的长宽比锚框
scales_per_octave=3,
# 锚框的长宽比
ratios=[0.5, 1.0, 2.0],
# 不同尺度特征图对应的锚框在原图上的步长 因为我们这里为FPN新增了一个高维特征图
strides=[8, 16, 32, 64, 128]),
# gt bbox编码器 对检测框和锚框的偏移量进行编码
bbox_coder=dict(
type='DeltaXYWHBBoxCoder', # rcnn的编码方式
target_means=[.0, .0, .0, .0], # 偏移量的归一化均值
target_stds=[1.0, 1.0, 1.0, 1.0]), # 偏移量的归一化标准差
# 分类损失函数
loss_cls=dict(
type='FocalLoss', # 使用focal loss
use_sigmoid=True, # 使用sigmoid激活函数
gamma=2.0, # 超参
alpha=0.25, # 超参
loss_weight=1.0), # 分类损失权重
# 回归损失函数 类型L1Loss 回归损失权重
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
# model training and testing settings
# 配置模型在训练过程中一些模块的行为
train_cfg=dict(
# 1、第一阶段分配正负样本 训练的时候需要将gt box与RPN产生的提议框(anchor)进行比较,为提议框分类和回归的目标值
assigner=dict(
# 分配器的类型 MaxIoUAssigner 基于iou的分配方法 用于许多常见的检测器通常会使用
type='MaxIoUAssigner',
# IoU >= 0.5(阈值) 被视为正样本
pos_iou_thr=0.5,
# IoU < 0.4(阈值) 被视为负样本 0.4-0.5不管
neg_iou_thr=0.4,
# 将框作为正样本的最小IoU阈值?
min_pos_iou=0,
# 忽略bbox的IoF阈值?
ignore_iof_thr=-1),
# 填充有效锚点后允许的边框 ?
allowed_border=-1,
# 训练期间正样本的权重
pos_weight=-1,
# 是否设置调试(debug)模式
debug=False),
# 测试阶段的一些参数 控制测试行为 配置解读同上
test_cfg=dict(
# NMS前的box数
nms_pre=1000,
# 允许的最小box尺寸
min_bbox_size=0,
# nms score阈值
score_thr=0.05,
# nms配置 nms类别=nms NMS中iou的阈值
nms=dict(type='nms', iou_threshold=0.5),
# NMS后要保留的最大box数量
max_per_img=100))
Reference
官方文档.
官方知乎解读.
官方b站解读:【通用视觉框架 OpenMMLab 字幕版】第四讲 目标检测 & MMDetection(下)—陈恺博士.

















 993
993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









