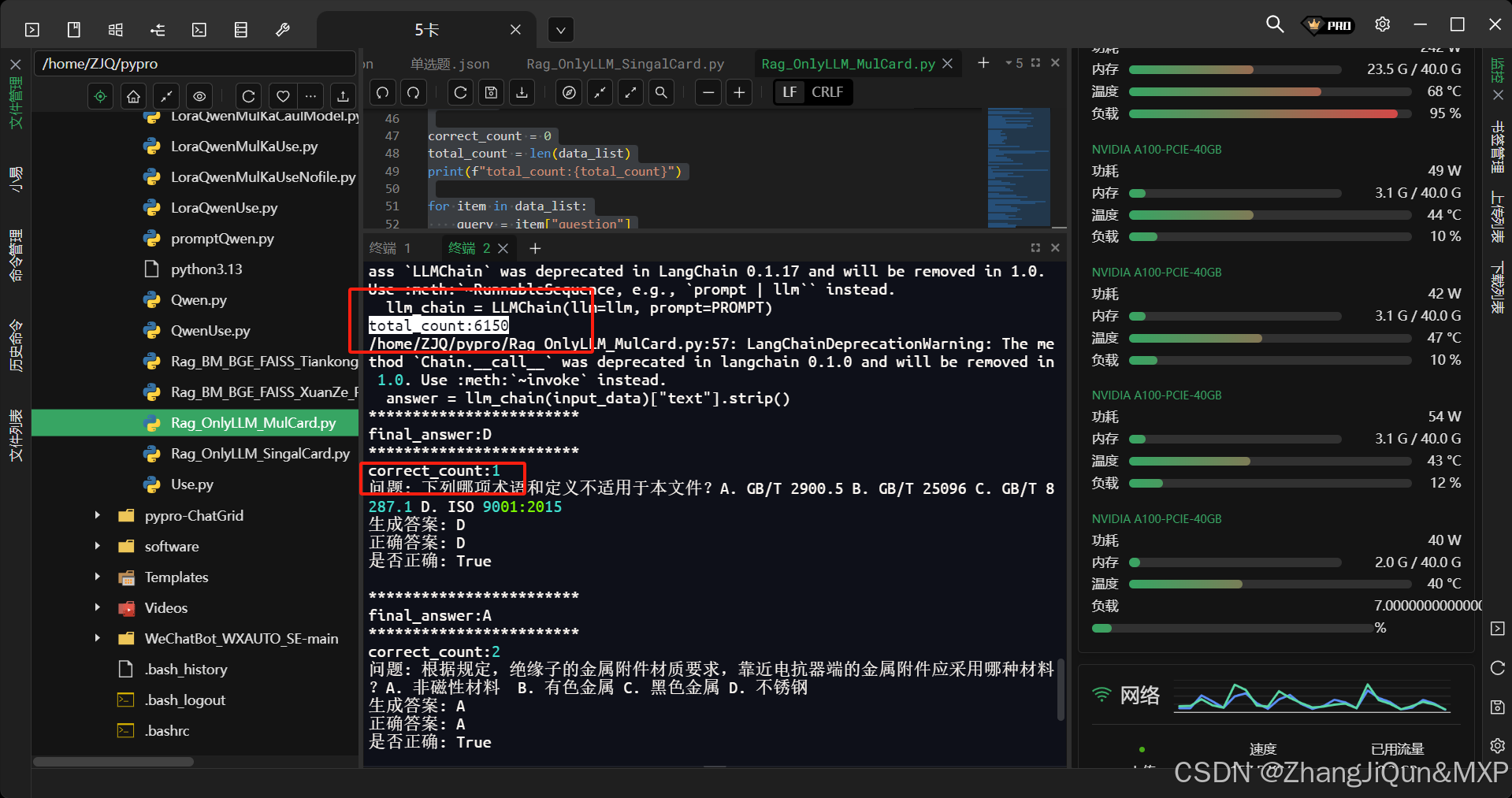
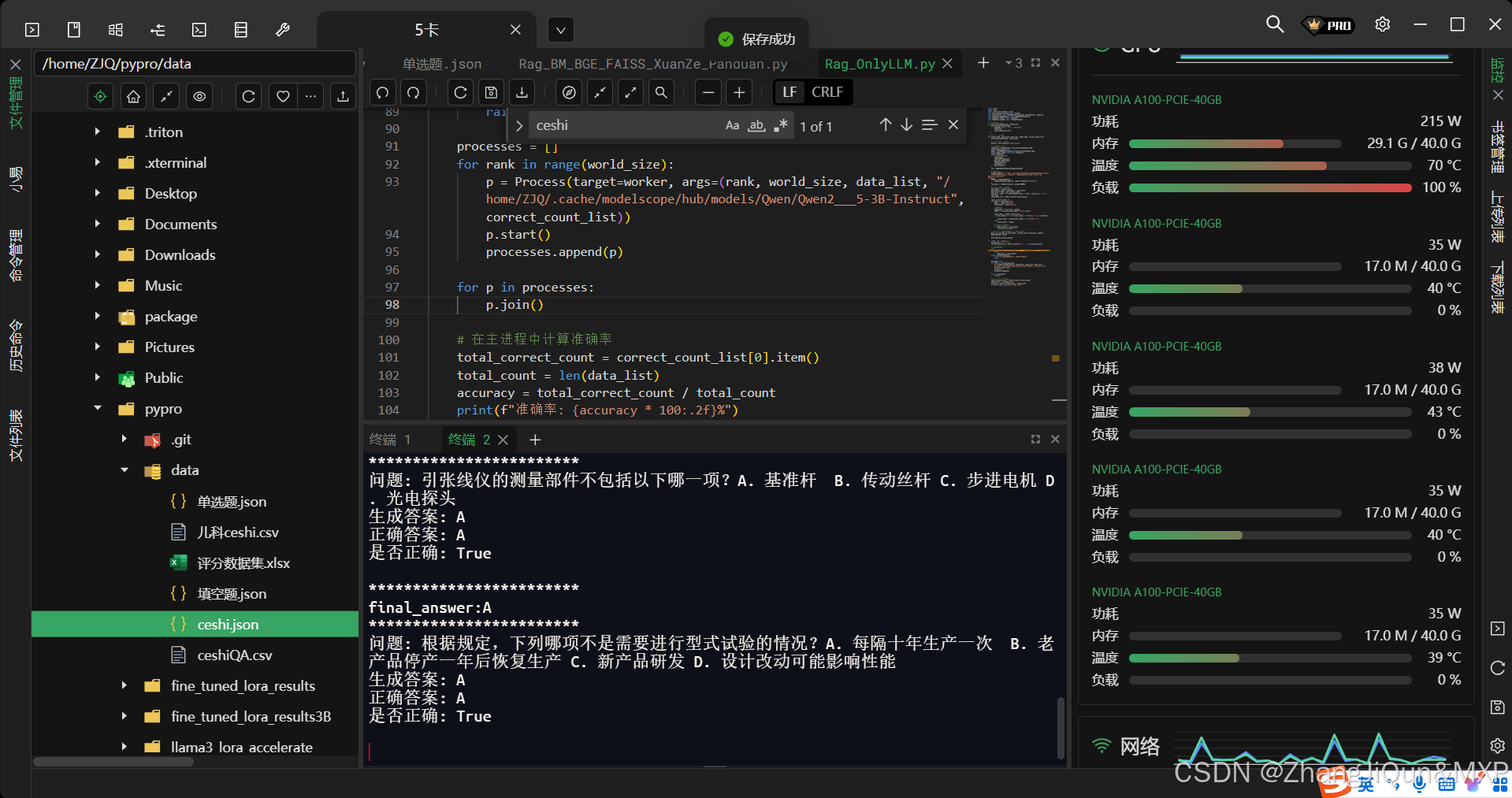
本机实现LLM调用,测试Qwen3B模型回答问题准确率:多卡执行,单卡执行 单卡执行: import torch import json from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline from langchain_huggingface import HuggingFacePipeline from langchain.<


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言














 订阅专栏 解锁全文
订阅专栏 解锁全文


















 841
841







