







1 过拟合介绍
如果模型设计的太复杂,可能会过拟合

下图的1~5分别代表最高项为1~5次幂的线性回归问题:
当模型太复杂的时候,虽然训练集上我们得到较小的误差,但是在测试集上,误差就奇大无比

复杂模型的model space涵盖了简单模型的model space,因此复杂模型在training data上的错误率更小,但并不意味着在testing data 上错误率更小。模型太复杂会出现overfitting。
1.1 高维小样本问题

1.2 造成过拟合的原因
- 模型过于复杂,参数量过多
- 数据中的噪声,造成了如果完全拟合的话,与真实情景的偏差更大
- 数据量有限,这使得模型无法真正了解整个数据的真实分布
2 处理过拟合的方法
机器学习笔记:误差的来源(bias & variance)_UQI-LIUWJ的博客-CSDN博客
处理过拟合主要有几种方法:
- 增加数据量(数据量大了之后,根据某种规则去掉一些特征,来实现降维)
- 特征提取(eg,主成分分析PCA,作用也是实现降维)
- 正则化(通过给损失函数增加惩罚项来避免过拟合)
- 减低模型的复杂度
2.1 正则化
这是一种解决过拟合的办法——>使曲线平滑一点(这样如果测试集的输入有一点噪声的话,扰动也不会太大)
注:正则项里面不包括偏差表示,只包括影响梯度的那些函数



- λ越大,表示越平滑,训练集上的error越大(因为我们越倾向于考虑w的数值大小,而不是我们预测值和实际值之间的error)
- 【λ太小可能过拟合,λ太大可能欠拟合】
2.1.1 L1正则化(Lasso)

L1正则化每次更新的数值是恒定的(等值更新)
2.1.2 L2正则化(ridge)
机器学习笔记:岭回归(L2正则化)_UQI-LIUWJ的博客-CSDN博客
L2正则化每次w更新的比例是恒定的(等比例更新)
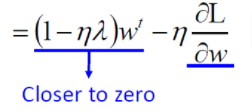
L2正则化在w值很大的情况下,下降速度很快;在w很小的情况下,下降速度很慢
2.2 Dropout
以概率p丢弃部分神经元,即使得被丢弃的神经元输出为0
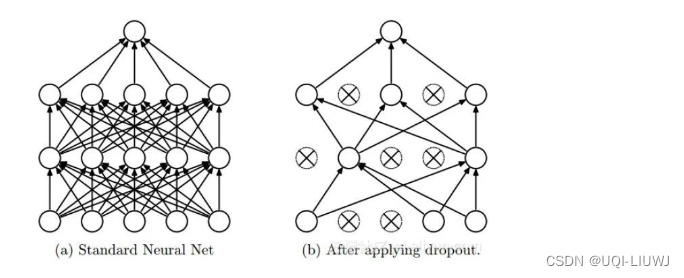
2.2.1 Dropout的正则化效果
-
在Dropout每一轮训练过程中随机丢失神经元的操作相当于多个DNNs进行取平均,因此用于预测时具有vote的效果。
-
减少神经元之间复杂的共适应性。
-
当隐藏层神经元被随机删除之后,使得全连接网络具有了一定的稀疏化,从而有效地减轻了不同特征的协同效应。
-
有些特征可能会依赖于固定关系的隐含节点的共同作用,而通过Dropout的话,就有效地阻止了某些特征在其他特征存在下才有效果的情况,增加了神经网络的鲁棒性。
-
-
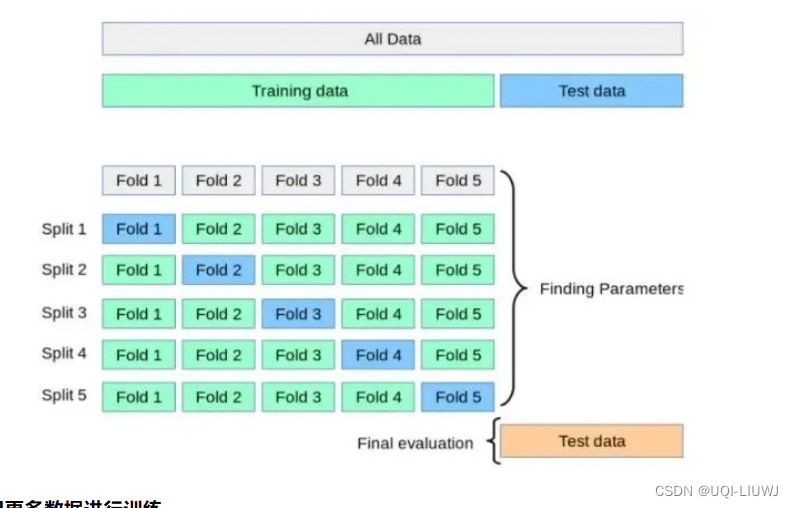
2.3 交叉验证
将数据分成 k 个子集,用其中一个子集进行验证,其他子集用于训练算法
计算成本较高,但不会浪费太多数据
3 欠拟合和过拟合

欠拟合:
1)模型不足以表达数据所有的特点
2)没有充分学习观测数据的特点
过拟合:
1)模型不仅表达了数据所有的特点,还把数据特定的噪声也表达了出来
2)在训练集和验证集/测试集 上的表现差异巨大
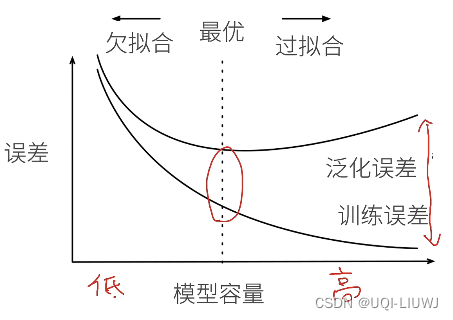
(模型容量可以理解成模型的复杂度【参数个数/参数值的选择范围】)
3.1 处理欠拟合的方法
继续训练模型,如果效果提升不显著的话,修改模型,让模型更复杂一些
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











