







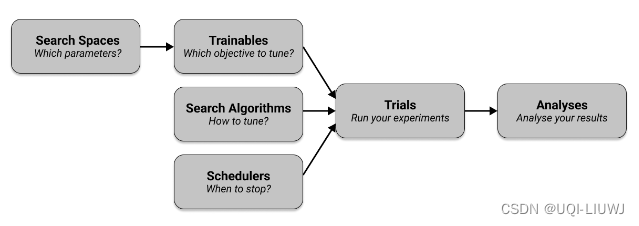
1 ray-tune 整体流程
- 在搜索空间(search space)中定义要调整的超参数
- ——>将它们传递到指定要tune的目标的可训练对象中(trainable)
- ——>选择一种搜索算法(search algorithm)来有效地优化您的参数(是mean-accuracy还是loss?最大化还是最小化?)
- 可选择使用调度程序(scheduler)提前停止搜索并加快实验
- 与其他配置一起,trainable、search algorithm和scheduler被传递到 tune.run(),它会运行实验并创建试验(trial)。
- ——>在分析中使用这些试验来检查您的trail结果。
2 Trainable
Trainable 是一个传递给 Tune 的对象。
Ray Tune 有两种定义可训练对象的方法, Function API 和 Class API。
假设我们想要优化一个简单的目标函数,例如 ,其中 a 和 b 是我们想要调整以最小化目标的超参数。 由于目标也有一个变量 x,我们需要测试不同的 x 值。 给定 a、b 和 x 的具体选择,我们可以评估目标函数并获得最小化分数。
2.1 Function API
创建一个接收超参数字典的函数(在下面的例子中是trainable函数,pytorch 笔记:使用Tune 进行调参_UQI-LIUWJ的博客-CSDN博客_pytorch 自动调参 中是train函数)。
这个函数在“训练”的过程中中计算一个分数,并将这个分数报告给 Tune:
from ray import tune
def objective(x, a, b):
return a * (x ** 0.5) + b
#目标函数
def trainable(config):
#将超参数字典config作为trainable函数的参数传进来
for x in range(20):
score = objective(x, config["a"], config["b"])
tune.report(score=score) # Send the score to Tune.
#将每一个x对应的score直接传递给tune
上面的代码使用使用 tune.report(...) 来report训练循环中的中间分数,这在许多机器学习任务中很有用。
如果只想在此循环之外报告最终分数,您可以简单地在Trainable函数的末尾使用 return {"score": score} 。
也可以使用 yield {"score": score} 代替 tune.report(score=score)。
2.2 Class API
from ray import tune
def objective(x, a, b):
return a * (x ** 2) + b
#定义目标函数
class Trainable(tune.Trainable):
def setup(self, config):
# config (dict): A dict of hyperparameters
self.x = 0
self.a = config["a"]
self.b = config["b"]
def step(self):
score = objective(self.x, self.a, self.b)
self.x += 1
return {"score": score}
#注:Class API不能用tune.report
3 搜索空间
为了优化你的超参数,你必须定义一个搜索空间。 搜索空间定义了超参数的有效值,并可以指定这些值的采样方式(例如,从均匀分布或正态分布)。
tune.uniform(a, b) | a,b之间的均匀分布 |
tune.quniform(a,b,c) | a,b之间的离散均匀分布,以c为增量 |
tune.loguniform(a,b) | log空间上的均匀分布 |
tune.qloguniform(a,b,c) | log空间上a,b之间的离散均匀分布,以c为增量 |
tune.randn(a,b) | 以a为均值,b为标准差的正态分布 |
tune.qrandn(a,b,c) | 以a为均值,b为标准差的离散正态分布,以c为增量 |
tune.randint(a, b) | a,b之间的随机整数 |
tune.qrandint(a,b,c) | a,b之间的随机整数(包括b),以c为增量 |
tune.choice(["a", "b", "c"] | 均匀地选择一个 |
tune.sample_from(
lambda function
) | 自定义一个分布(建议由前面的那些组成) |
4 Trials
使用 tune.run 来执行和管理超参数调整并生成Trial。
tune.run() 至少接受一个Trainable作为第一个参数,以及一个配置字典来定义搜索空间。
tune.run(
trainable,
config={"a": tune.uniform(-2,2),
"b": tune.uniform(-2,2)})默认情况下,tune.run 将执行,直到所有Trial停止或出错。
可以通过指定样本数 (num_samples) 运行 num_samples次Trial。 Tune 会自动确定并行运行的Trial次数。
4.1 tune.run 的时候发生了什么?
这一小节我们用如下的例子:
space = {"x": tune.uniform(0, 1)}
tune.run(my_trainable,
config=space,
num_samples=10)这里 使用不同的超参数(从 uniform(0, 1) 采样)并行对 my_trainable进行多次评估。
- 每个 tune.run都由“driver 进程”和许多“worker 进程”组成。
- “driver 进程”是调用 tune.run 的 python 进程。 Tune 驱动程序进程运行脚本的节点上运行(调用 tune.run的地方)
- “driver 进程”产生并行“worker 进程”(Ray actor),负责使用其超参数配置和提供的可训练来评估每个Trail
- 当 Trainable 正在执行时,“driver 进程” 与每个 Actor(“worker 进程”)进行通信,以接收中间训练结果并在一定情况下暂停/停止 Actor
- 当 Trainable 终止(或停止)时,相应的actor(“worker 进程”) 也终止。
- 而 Ray Tune 可训练的“worker 进程”在任何节点上运行
- 当实例化作为 Ray Actor 的类时,Ray 将在同一台机器(或另一台分布式机器,如果运行 Ray 集群)上的单独进程上启动该类的实例。 然后这个actor可以异步执行方法调用并维护它自己的内部状态。
- Tune 使用 Ray Actor 并行化多个超参数配置的Trail。 每个参与者都是一个 Python 进程,它执行用户提供的 Trainable 的一个实例。
- 用户提供的 Trainable 的定义发送到每个“worker 进程”。 每个 Ray Actor 将启动一个待执行的 Trainable 实例。
- 如果 trainable 是函数(Function API),它将在单独的执行线程上的 Ray actor 进程上执行。
- 每当调用 tune.report 时,执行线程就会暂停,等待“driver 进程” 的结果。如果没有pause或stop,actor 的执行线程会自动恢复。
- “driver 进程”是调用 tune.run 的 python 进程。 Tune 驱动程序进程运行脚本的节点上运行(调用 tune.run的地方)
4.2 Trail的“生命周期”
| 初始化 | Trial 首先作为超参数样本生成,其参数根据 tune.run 中提供的内容进行配置。 然后将Trail放入要执行的队列中(状态为 PENDING)。 |
| PENDING | Pending 的Trail是要在机器上执行的Trail。 只要 Trial 的资源值可用,Tune 就会运行 Trial(通过启动一个持有配置和训练函数的 ray actor)。 |
| RUNNING | 一个正在运行的 Trial 被分配到一个 Ray Actor。 可以有多个并行运行的Trail。 |
| ERRORED | 如果正在运行的 Trial 引发异常,Tune 将捕获该异常并将 Trial 标记为错误。 请注意,异常可以从“worker 进程”传播到主 Tune “driver 进程”。 如果设置了 max_retries,在一定次数后Tune 会将Trail设置回“PENDING”,然后从最后一个检查点开始。 |
| TERMINATED | 如果一个 Trial 被 Stopper/Scheduler 停止,它就会被终止。 如果使用函数 API,则在函数停止时也会终止Trail。 |
| PAUSED | Trail scheduler可以暂停Trail。 这意味着这个“worker 进程”将被停止。 稍后可以从最近的checkpoint恢复暂停的Trail。 |
4.3 恢复一个tune.run()
在tune.run()的过程中,如果摁下ctrl+C暂停,那么Ray Tune会停止训练,并保存当下最终的checkpoint。
那么,有什么办法可以resume嘛
是有的,我们多传入两个参数即可
tune.run(
train,
# other configuration
name="my_experiment",
resume=True
)name是 get_best_logdir返回结果父路径类型的内容(往往是带时间后缀的,如my_trainable_2021-01-29_10-16-44)
name的内容在之前ctrl+C之后输出的内容中,也有体现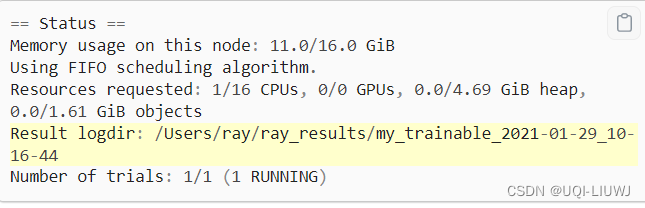
4.4 自动停止tune.run()
4.2中使用手动ctrl+C的防止停止tune.run()那么有没有什么方法可以自动停止tune.run()呢?
——>使用字典
在下面的示例中,每次试验将在完成 10 次迭代或达到 0.98 的平均准确度时停止。 假设这些指标正在增加。
tune.run(
my_trainable,
#other parameters
stop={"training_iteration": 10, "mean_accuracy": 0.98}
)4.4.1 第一次failure之后停下所有的trail
默认情况下,tune.run 将继续执行,直到所有试验终止或出错。 要在出现任何试用错误时立即停止整个 Tune 运行,可以:
tune.run(trainable,
#。。。。
fail_fast=True)4.5 设置log文件的位置和trainable的名字
tune.run( trainable, name="example-experiment", #。。。)

这样出来的文件就不再是默认的那一套字符串了,而是自己指定的内容
tune.run(trainable,
num_samples=2,
local_dir="./results",
name="test_experiment")这样两个Trail folder的位置就是
./results/test_experiment/trial_name_1 和 ./results/test_experiment/trial_name_2
4.6 设置Trail folder文件的名称
def trial_name_string(trial):
return str(trial)[:5]
tune.run(
trainable,
trial_name_creator=trial_name_string
)通过传入一个函数名称的方式,来设置Trail folder文件的名称
4.7 和TensorBoard结合
找到我们要可视化的Trianable的路径
tensorboard --logdir=~/example-experiment4.8 重定向输出和报错内容的路径
tune.run( trainable, log_to_file=True)
通过设置log_to_file=True,stdout和stderr将会被分别写入对应的
trial_logdir/stdout和trial_logdir/stderr
如果想指定输出文件,可以传递
- 一个文件名,将存储组合输出的位置,
- 两个文件名,分别用于 stdout 和 stderr
tune.run( trainable, log_to_file="std_combined.log") tune.run( trainable, log_to_file=("my_stdout.log", "my_stderr.log"))
4.9 并行和资源相关
并行度由 resources_per_trial(默认每次Trial使用 1 个 CPU, 0 个 GPU)和 Tune 可用的资源决定
默认情况下,Tune 会自动运行 N 个并发Trial,其中 N 是机器上的 CPU(内核)数量。
比如我们的代码是tune.run(trainable, num_samples=10),但我们机子上是4个CPU,那么我们一次是跑4个并行的Trial
这种默认的并行度可以用 resources_per_trial重写
tune.run(trainable, num_samples=10, resources_per_trial={"cpu": 2}) #每个Trial用两块CPU,所以对于四核电脑来说,一次并发两个Trail tune.run(trainable, num_samples=10, resources_per_trial={"cpu": 4}) #每个Trial用四块CPU,所以对于四核电脑来说,一次并发一个Trail tune.run(trainable, num_samples=10, resources_per_trial={"cpu": 0.5}) #每个Trial用半块CPU,所以对于四核电脑来说,一次并发八个Trail
4.10 GPU相关
要使用 GPU,必须在 tune.run(resources_per_trial) 中设置 gpu。 这将为每个Trail自动设置 CUDA_VISIBLE_DEVICES。
分配方式和cpu很类似,当然也可以同时设置
tune.run(trainable, num_samples=10, resources_per_trial={"gpu": 1})
tune.run(trainable, num_samples=10, resources_per_trial={"cpu": 2, "gpu": 1})5 Search Algorithm
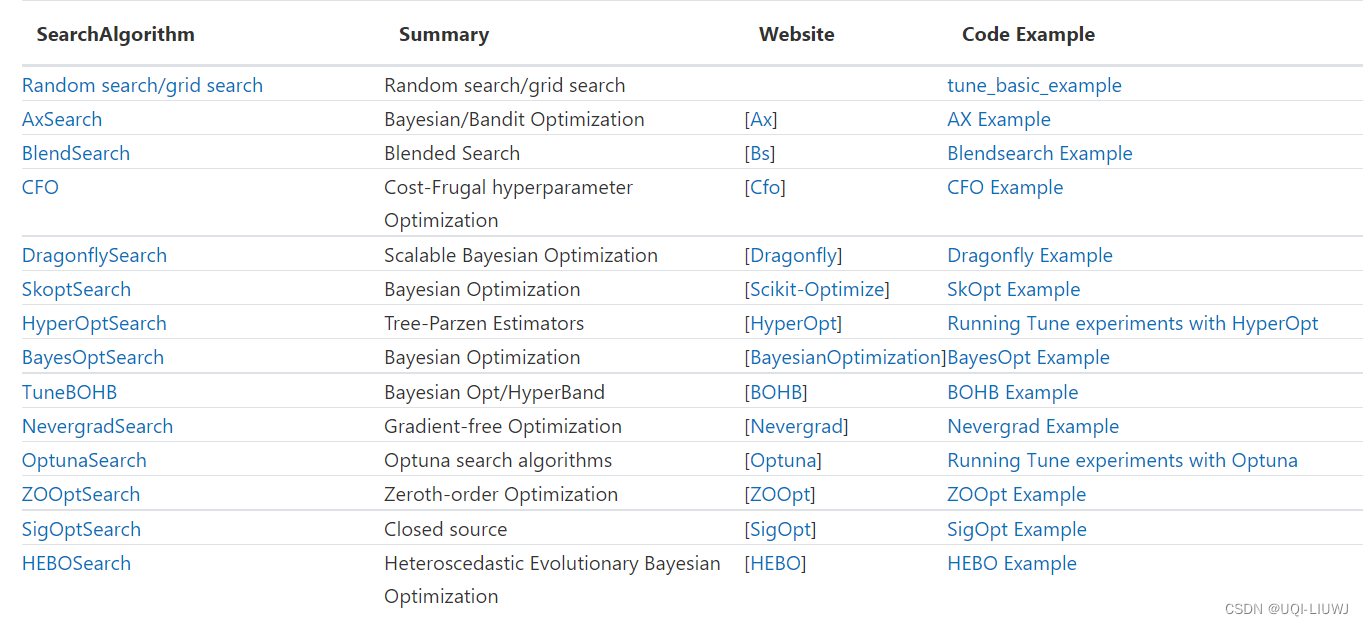
- 要优化训练过程的超参数,可以使用建议超参数配置的搜索算法。
- 如果不指定搜索算法,Tune 将默认使用随机搜索。
- 例如,如果要通过 bayesian-optimization 包,通过使用简单的贝叶斯优化来调参(首先需要 pip install bayesian-optimization),我们可以使用 BayesOptSearch 定义一个算法。 只需将 search_alg 参数传递给 tune.run:
from ray.tune.suggest.bayesopt import BayesOptSearch
# 定义搜索空间
search_space = {"a": tune.uniform(0, 1), "b": tune.uniform(0, 20)}
algo = BayesOptSearch(random_search_steps=4)
#贝叶斯优化来进行调参
tune.run(
trainable,
config=search_space,
search_alg=algo
)所有tune支持的搜索算法如下:
6 Schedulers
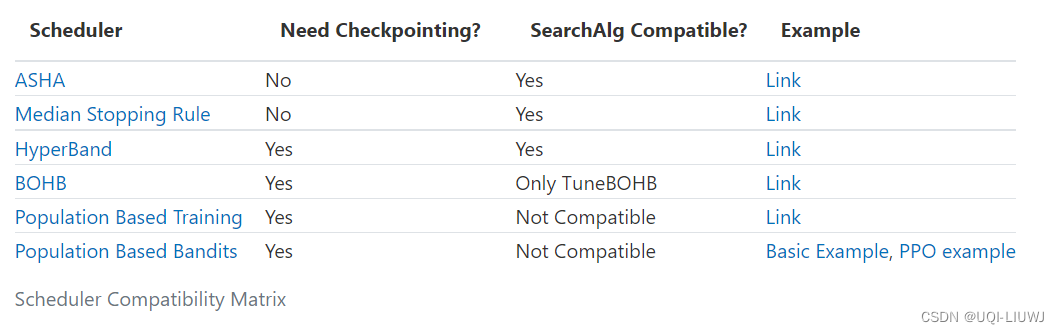
schedulers可以停止、暂停或调整运行试验的超参数,从而可能使超参数调整过程更快。
要使用schedulers,只需将schedulers参数传递给 tune.run()
最容易的调度程序是 ASHAScheduler,它将积极终止低性能试验。
使用schedulers时,您可能会遇到兼容性问题,如下面的兼容性矩阵所示。 某些schedulers不能与搜索算法一起使用,并且某些schedulers需要实现checkpoint。
7 Analyses
tune.run 返回一个 ExperimentAnalysis 对象,其中包含可用于分析训练的方法。
令result是tune.run的返回结果
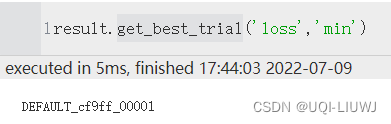
| result.get_best_trial(metric,mode) | 最好的trail
|
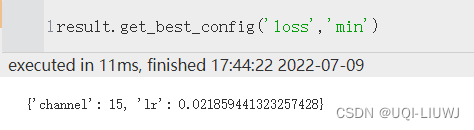
| get_best_config | 调参最好的结果(最佳配置)
|
| get_best_logdir | 调参最好的结果对应的路径 |
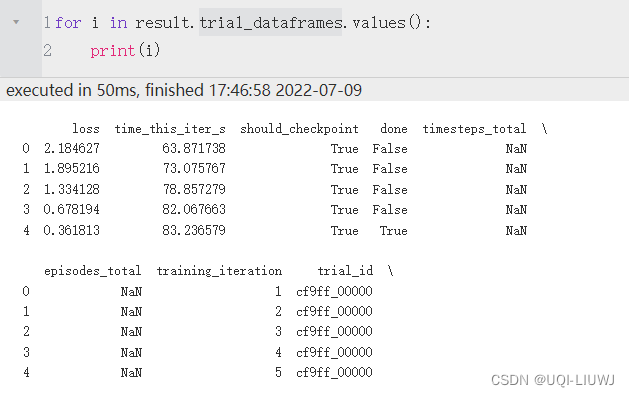
| trial_dataframes | 各trail每一轮epoch的信息
|
参考资料


















 628
628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











