







往期回顾:YOLOv8改进目录_convnextv2与yolov8-CSDN博客
目录
一.论文说明
1.论文地址:https://arxiv.org/pdf/2212.01593.pdf

2.论文内容
尽管深度神经网络在视觉[4, 12, 17, 19, 35]、语言[6, 40]和语音[13]方面取得了巨大成功,但模型压缩已成为迫切需要的问题,特别是考虑到数据中心功耗的急剧增长和全球资源受限的边缘设备数量的大幅增加。网络量化[14, 15]是最有效的方法之一,因为它具有较低的内存成本和固有的整数计算优势。
然而,在神经架构设计中,量化感知并不是首要任务,因此在很大程度上被忽视。然而,如果量化是最终部署的必要操作,这可能会带来负面影响。例如,许多著名的架构存在量化崩溃问题,如MobileNet [20, 21, 36]和EfficientNet [38],这需要解决设计或采用高级量化方案,如[26, 37, 45]和[2, 16]。
最近,神经架构设计中最具影响力的方向之一是重参数化[8, 11, 46]。其中,RepVGG [11] 在训练期间将标准的Conv-BN-ReLU重新设计为其相同的多分支结构,这带来了强大的性能提升,同时在推理过程中不会增加任何额外的成本。由于其简单性和推理优势,它受到许多最近的视觉任务的青睐[10, 22, 28, 39, 41, 44]。然而,基于重参数化的模型面临着众所周知的量化困难,这是一种固有的缺陷,阻碍了行业应用。结果表明,使这种结构合适地量化并不是易事。一个标准的训练后量化方案将RepVGG-A0的准确性从72.4%大大降低到了52.2%。与此同时,采用量化感知训练[7]也并非易事。
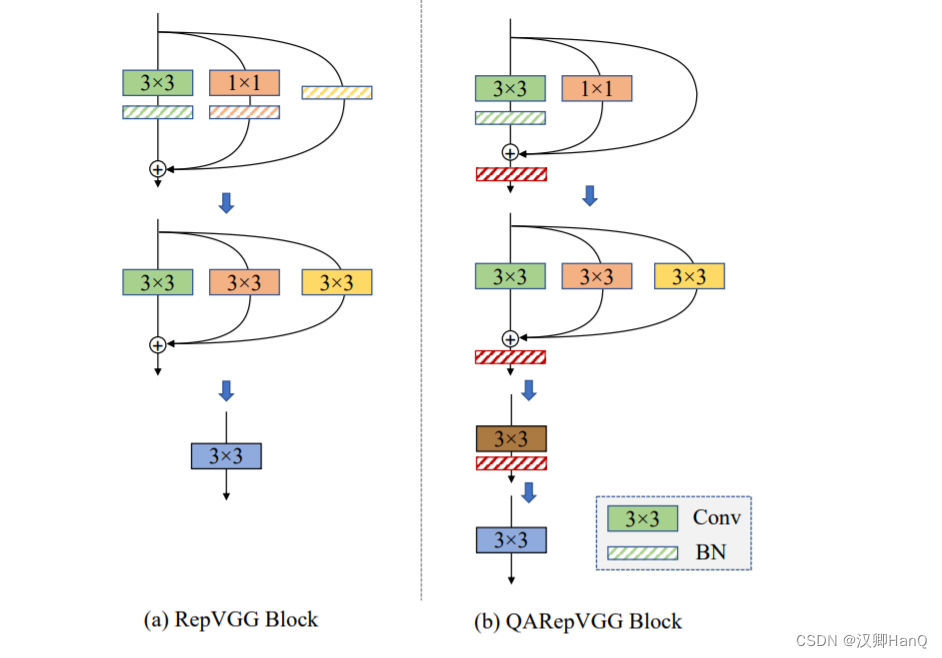
在这里,我们特别关注RepVGG [11]的量化困难。为了解决这个问题,我们探索了基础的量化原则,通过深入分析典型的重参数化架构来指导我们。也就是说,为了使网络具有更好的量化性能,权重的分布以及任意分布的处理数据都应该是“量化友好”的。这两者对确保更好的量化性能都至关重要。更重要的是,这些原则引导我们设计了一个全新的架构,我们称之为QARepVGG(即Quantization-Aware RepVGG,量化感知repvgg),它不会遭受严重的量化崩溃,其构建块如图1所示,其量化性能得到了大幅提升。
二.代码改进
2.1新建qarepvgg.pt
import cv2
import numpy as np
import pandas as pd
import requests
import torch
import torch.nn as nn
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
result = nn.Sequential()
result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding, groups=groups,
bias=False))
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return result
class RepVGGBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3,
stride=1, padding=1, dilation=1, groups=1, padding_mode='zeros', deploy=False, use_se=False):
super(RepVGGBlock, self).__init__()
self.deploy = deploy
self.groups = groups
self.in_channels = in_channels
padding_11 = padding - kernel_size // 2
self.nonlinearity = nn.SiLU()
self.se = nn.Identity()
if deploy:
self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=True,
padding_mode=padding_mode)
else:
self.rbr_identity = nn.BatchNorm2d(
num_features=in_channels) if out_channels == in_channels and stride == 1 else None
self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, groups=groups)
self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride,
padding=padding_11, groups=groups)
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def forward(self, inputs):
if self.deploy:
return self.nonlinearity(self.rbr_dense(inputs))
if hasattr(self, 'rbr_reparam'):
return self.nonlinearity(self.se(self.rbr_reparam(inputs)))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out))
class QARepVGGBlock(RepVGGBlock):
"""
RepVGGBlock is a basic rep-style block, including training and deploy status
This code is based on https://arxiv.org/abs/2212.01593
"""
def __init__(self, in_channels, dim, kernel_size=3,
stride=1, padding=1, dilation=1, groups=1, padding_mode='zeros', deploy=False, use_se=False):
super(QARepVGGBlock, self).__init__(in_channels, dim, kernel_size, stride, padding, dilation, groups,
padding_mode, deploy, use_se)
if not deploy:
self.bn = nn.BatchNorm2d(dim)
self.rbr_1x1 = nn.Conv2d(in_channels, dim, kernel_size=1, stride=stride, groups=groups, bias=False)
self.rbr_identity = nn.Identity() if dim == in_channels and stride == 1 else None
self._id_tensor = None
def forward(self, inputs):
if hasattr(self, 'rbr_reparam'):
return self.nonlinearity(self.bn(self.se(self.rbr_reparam(inputs))))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.nonlinearity(self.bn(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)))
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel = kernel3x3 + self._pad_1x1_to_3x3_tensor(self.rbr_1x1.weight)
bias = bias3x3
if self.rbr_identity is not None:
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
id_tensor = torch.from_numpy(kernel_value).to(self.rbr_1x1.weight.device)
kernel = kernel + id_tensor
return kernel, bias
def switch_deploy(self):
if hasattr(self, 'rbr_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.rbr_reparam = nn.Conv2d(in_channels=self.rbr_dense.conv.in_channels,
out_channels=self.rbr_dense.conv.out_channels,
kernel_size=self.rbr_dense.conv.kernel_size, stride=self.rbr_dense.conv.stride,
padding=self.rbr_dense.conv.padding, dilation=self.rbr_dense.conv.dilation,
groups=self.rbr_dense.conv.groups, bias=True)
self.rbr_reparam.weight.data = kernel
self.rbr_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('rbr_dense')
self.__delattr__('rbr_1x1')
if hasattr(self, 'rbr_identity'):
self.__delattr__('rbr_identity')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
self.deploy = True
def _fuse_extra_bn_tensor(self, kernel, bias, branch):
assert isinstance(branch, nn.BatchNorm2d)
running_mean = branch.running_mean - bias # remove bias
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
class QARepNeXt(nn.Module):
'''
QARepNeXt is a stage block with qarep-style basic block
'''
def __init__(self, in_channels, out_channels, n=1, isTrue=None):
super().__init__()
self.conv1 = QARepVGGBlock(in_channels, out_channels)
self.block = nn.Sequential(*(QARepVGGBlock(out_channels, out_channels) for _ in range(n - 1))) if n > 1 else None
def forward(self, x):
x = self.conv1(x)
if self.block is not None:
x = self.block(x)
return x2.2修改task.py的fuse函数
def fuse(self):
"""
Fuse the `Conv2d()` and `BatchNorm2d()` layers of the model into a single layer, in order to improve the computation efficiency.
Returns:
(nn.Module): The fused model is returned.
"""
LOGGER.info('Fusing layers... ')
for m in self.model.modules():
if hasattr(m, 'switch_deploy'):
m.forward = m.forward_fuse # update forward
elif isinstance(m, (Conv, DWConv)) and hasattr(m, 'bn'):
m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
delattr(m, 'bn') # remove batchnorm
m.forward = m.forward_fuse # update forward
self.info()
return self2.3task.py的parse_model函数进行注册
找到ultralytics/nn/tasks.py,修改parse_model函数
elif m in [QARepNeXt]:
c1, c2 = ch[f], args[0]
if c2 != nc: # if not outputss
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [QARepNeXt]:
args.insert(2, n) # number of repeats
n = 12.4yaml文件
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8-seg instance segmentation model. For Usage examples see https://docs.ultralytics.com/tasks/segment
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-seg.yaml' will call yolov8-seg.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
s: [0.33, 0.50, 1024]
m: [0.67, 0.75, 768]
l: [1.00, 1.00, 512]
x: [1.00, 1.25, 512]
# YOLOv8.0s backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 1, QARepNeXt, [128]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0s head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)


















 316
316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









