









ML之LiR&Lasso:基于datasets糖尿病数据集利用LiR和Lasso算法进行(9→1)回归预测(三维图散点图可视化)
目录
基于datasets糖尿病数据集利用LiR和Lasso算法进行(9→1)回归预测(三维图散点图可视化)
相关文章
ML之LiR&Lasso:基于datasets糖尿病数据集利用LiR和Lasso算法进行(9→1)回归预测(三维图散点图可视化)
ML之LiR&Lasso:基于datasets糖尿病数据集利用LiR和Lasso算法进行(9→1)回归预测(三维图散点图可视化)实现
基于datasets糖尿病数据集利用LiR和Lasso算法进行(9→1)回归预测(三维图散点图可视化)
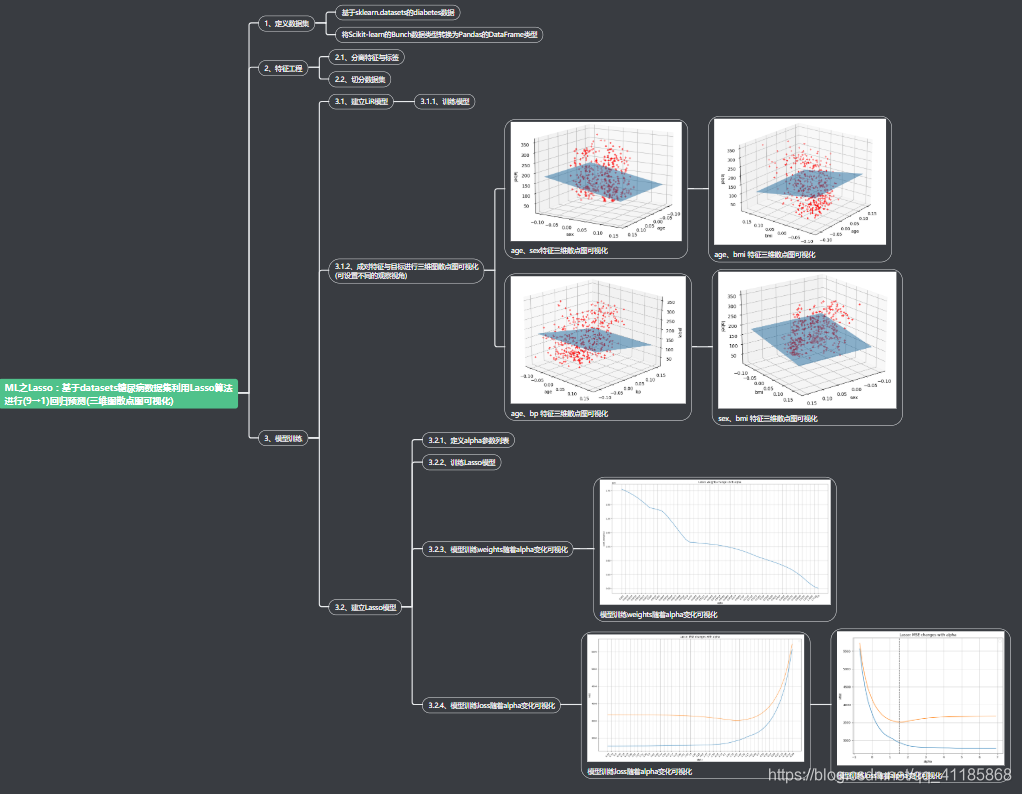
设计思路
输出结果







Lasso核心代码
class Lasso Found at: sklearn.linear_model._coordinate_descent
class Lasso(ElasticNet):
"""Linear Model trained with L1 prior as regularizer (aka the Lasso)
The optimization objective for Lasso is::
(1 / (2 * n_samples)) * ||y - Xw||^2_2 + alpha * ||w||_1
Technically the Lasso model is optimizing the same objective function as
the Elastic Net with ``l1_ratio=1.0`` (no L2 penalty).
Read more in the :ref:`User Guide <lasso>`.
Parameters
----------
alpha : float, default=1.0
Constant that multiplies the L1 term. Defaults to 1.0.
``alpha = 0`` is equivalent to an ordinary least square, solved
by the :class:`LinearRegression` object. For numerical
reasons, using ``alpha = 0`` with the ``Lasso`` object is not advised.
Given this, you should use the :class:`LinearRegression` object.
fit_intercept : bool, default=True
Whether to calculate the intercept for this model. If set
to False, no intercept will be used in calculations
(i.e. data is expected to be centered).
normalize : bool, default=False
This parameter is ignored when ``fit_intercept`` is set to False.
If True, the regressors X will be normalized before regression by
subtracting the mean and dividing by the l2-norm.
If you wish to standardize, please use
:class:`sklearn.preprocessing.StandardScaler` before calling ``fit``
on an estimator with ``normalize=False``.
precompute : 'auto', bool or array-like of shape (n_features, n_features),\
default=False
Whether to use a precomputed Gram matrix to speed up
calculations. If set to ``'auto'`` let us decide. The Gram
matrix can also be passed as argument. For sparse input
this option is always ``True`` to preserve sparsity.
copy_X : bool, default=True
If ``True``, X will be copied; else, it may be overwritten.
max_iter : int, default=1000
The maximum number of iterations
tol : float, default=1e-4
The tolerance for the optimization: if the updates are
smaller than ``tol``, the optimization code checks the
dual gap for optimality and continues until it is smaller
than ``tol``.
warm_start : bool, default=False
When set to True, reuse the solution of the previous call to fit as
initialization, otherwise, just erase the previous solution.
See :term:`the Glossary <warm_start>`.
positive : bool, default=False
When set to ``True``, forces the coefficients to be positive.
random_state : int, RandomState instance, default=None
The seed of the pseudo random number generator that selects a
random
feature to update. Used when ``selection`` == 'random'.
Pass an int for reproducible output across multiple function calls.
See :term:`Glossary <random_state>`.
selection : {'cyclic', 'random'}, default='cyclic'
If set to 'random', a random coefficient is updated every iteration
rather than looping over features sequentially by default. This
(setting to 'random') often leads to significantly faster convergence
especially when tol is higher than 1e-4.
Attributes
----------
coef_ : ndarray of shape (n_features,) or (n_targets, n_features)
parameter vector (w in the cost function formula)
sparse_coef_ : sparse matrix of shape (n_features, 1) or \
(n_targets, n_features)
``sparse_coef_`` is a readonly property derived from ``coef_``
intercept_ : float or ndarray of shape (n_targets,)
independent term in decision function.
n_iter_ : int or list of int
number of iterations run by the coordinate descent solver to reach
the specified tolerance.
Examples
--------
>>> from sklearn import linear_model
>>> clf = linear_model.Lasso(alpha=0.1)
>>> clf.fit([[0,0], [1, 1], [2, 2]], [0, 1, 2])
Lasso(alpha=0.1)
>>> print(clf.coef_)
[0.85 0. ]
>>> print(clf.intercept_)
0.15...
See also
--------
lars_path
lasso_path
LassoLars
LassoCV
LassoLarsCV
sklearn.decomposition.sparse_encode
Notes
-----
The algorithm used to fit the model is coordinate descent.
To avoid unnecessary memory duplication the X argument of the fit
method
should be directly passed as a Fortran-contiguous numpy array.
"""
path = staticmethod(enet_path)
@_deprecate_positional_args
def __init__(self, alpha=1.0, *, fit_intercept=True, normalize=False,
precompute=False, copy_X=True, max_iter=1000,
tol=1e-4, warm_start=False, positive=False,
random_state=None, selection='cyclic'):
super().__init__(alpha=alpha, l1_ratio=1.0, fit_intercept=fit_intercept,
normalize=normalize, precompute=precompute, copy_X=copy_X,
max_iter=max_iter, tol=tol, warm_start=warm_start, positive=positive,
random_state=random_state, selection=selection)
######################################################
#########################
# Functions for CV with paths functions
















 1869
1869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











